









rknn的模型转换过程
用的pytorch=1.8.1版本的来训练的.先训练出的pytorch纯权重参数模型,
后经过尝试和失败,纠正一下官方文档, 里面讲的是两步, 实际上是三步.没有讲需要先从pth转成pt, 具体转换方法参考rnkk-toolkit中 example文件夹下面的代码.
权重参数模型pth,-> 带网络结构的模型pt->rknn模型
下面是问题记录.
经过尝试,
权重参数模型pth,-> 带网络结构的模型pt->rknn模型 是通的. 但是把rknn模型复制开发板上运行的时候出现如下错误.
Init runtime environment
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:51)
E RKNNAPI: rknn_init, msg_load_ack fail, ack = 1(ACK_FAIL), expect 0(ACK_SUCC)!
E RKNNAPI: ==============================================
E RKNNAPI: RKNN VERSION:
E RKNNAPI: API: 1.6.1 (f78b668 build: 2021-05-17 16:34:14)
E RKNNAPI: DRV: 1.6.0 (159d2d3 build: 2021-01-12 15:23:09)
E RKNNAPI: ==============================================
E Catch exception when init runtime!
E Traceback (most recent call last):
File “/home/firefly/Desktop/AI3/vvv/lib/python3.7/site-packages/rknnlite/api/rknn_lite.py”, line 155, in init_runtime
self.rknn_runtime.build_graph(self.rknn_data, self.load_model_in_npu)
File “rknnlite/api/rknn_runtime.py”, line 358, in rknnlite.api.rknn_runtime.RKNNRuntime.build_graph
Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID
Init runtime environment failed
官方客服回答是要通过串口才能输出日志. 具体内容. 先将环境变量RKNN_LOG_LEVEL=5 设置一下, 然后通过串口查看输出, 而不是文件. 由于手上暂时没有串口线, 所以就先放着把.
尝试用pth->onnx->rknn的方式来转换, 发现转换不了. pth转onnx还行, 版本要提升成opsetversion=11 . 这样才能成功转成onnx. 但是onnx转rknn就不行了. 提示
GlobalAveragePool 出现除0错误.
mpy_backend.ops.global_average_pool.GlobalAveragePool
没办法打算重新训练模型. 用的torch=1.5.1来训练, 后面再尝试转换模型 pth->pt->rknn 这样可确保.不会因为版本问题导致错误.试试再说.
pytorch的模型一直无法加载
这一步是在模型保存的时候同时产生的.
普通的pytorch 直接保存的是权重参数pth模型,rknn并不能加载和转换.
后来看到sdk中的示例代码才发现需要 torch.jit.trace() 才行. 这一步要求在保存模型的时候同时转换成标准的模型… 代码如下,
torch2jit.py
# -*- coding: utf-8-*-
import argparse
import os
import shutil
import numpy as np
from tqdm import tqdm
from mypath import Path
from dataloaders import make_data_loader
from modeling.sync_batchnorm.replicate import patch_replication_callback
from modeling.deeplab import *
from utils.loss import SegmentationLosses
from utils.calculate_weights import calculate_weigths_labels
from utils.lr_scheduler import LR_Scheduler
from utils.saver import Saver
# from utils.summaries import TensorboardSummary
from utils.metrics import Evaluator
from utils.visualizer import Visualizer
def main():
parser = argparse.ArgumentParser(description="PyTorch ai Training")
parser.add_argument('--aimodeldir', type=str, default='H:\\AIModel\\aimmmmm.pt', help='dataset name or path (default: online_label)')
# parser.add_argument('--aimodel-out-dir', type=str, default='aimodels/', help='AIModel out to this dir ')
# parser.add_argument('--resume', type=str, default='aimodels/bestmodel/deeplabv3model.pt', help='put the path to resuming file if needed')
# parser.add_argument('--out-stride', type=int, default=16, help='network output stride (default: 8)')
args = parser.parse_args()
torch.cuda.empty_cache() # 释放显存
checkpoint = torch.load(args.aimodeldir)
if "num_classes" in checkpoint['state_dict']:
num_classes = checkpoint['state_dict']["num_class"]
else:
print("请修改合适的分类数.num_classes")
num_classes = 26
model = DeepLab(num_classes=int(num_classes))
# if args.cuda:
# model.module.load_state_dict(checkpoint['state_dict'])
# else:
model.load_state_dict(checkpoint['state_dict'])
model.eval()
trace_model = torch.jit.trace(model, torch.Tensor(1,3,1920,1080))
trace_model.save(args.aimodeldir+".jit.pt")
print("转换完成.已生成" + args.aimodeldir+".jit.pt")
torch.cuda.empty_cache() # 释放显存
if __name__ == "__main__":
main()
** torch.jit 的模型转换成rknn模型 **
这一步是在虚拟机里执行的, 因为sdk文档 说是只支持Ubuntu系统. 所以只能在虚拟机里执行, 因为开发板的性能实在是有限. 执行这一步非常耗时, 400MB的模型大概3个小时.才能转换完, 期间要在Ubuntu中开虚拟内存. 开到很大. 如果实际内存够大, 应该会很快. 执行期间整个电脑卡死…
代码参考官网SDK文档.代码
import numpy as np
import cv2
from rknn.api import RKNN
import torchvision.models as models
import torch
model = '/home/roota/Desktop/AI/AIModels/xxxxmodel.pt.jit.pt'
input_size_list = [[3, 1920, 1080]]
# Create RKNN object
rknn = RKNN()
# pre-process config
print('--> Config model')
rknn.config(mean_values=[[123.675, 116.28, 103.53]], std_values=[[58.395, 58.395, 58.395]], reorder_channel='0 1 2')
print('done')
# Load Pytorch model
print('--> Loading model')
ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)
if ret != 0:
print('Load Pytorch model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
# ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
rknn.config(target_platform='rk3399pro')
ret = rknn.build(do_quantization=False,pre_compile=True)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export RKNN model')
ret = rknn.export_rknn('/home/roota/Desktop/AI/AIModels/xxxxmodel1.16.00809.rknn')
if ret != 0:
print('Export deeplabv3model.rknn failed!')
exit(ret)
print('done')
更新RK3399Pro的NPU驱动到1.6.0
参考 https://blog.csdn.net/sinat_37322535/article/details/113867789
sudo apt update
sudo apt install firefly-3399pronpu-driver
执行后自己的测试代码后, 虽然报错, 但是可见驱动已升级到 1.6.0,
–> Init runtime environment
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:51)
E RKNNAPI: rknn_init, msg_load_ack fail, ack = 1(ACK_FAIL), expect 0(ACK_SUCC)!
E RKNNAPI: ==============================================
E RKNNAPI: RKNN VERSION:
E RKNNAPI: API: 1.6.1 (f78b668 build: 2021-05-17 16:34:14)
E RKNNAPI: DRV: 1.6.0 (159d2d3 build: 2021-01-12 15:23:09)
E RKNNAPI: ==============================================
E Catch exception when init runtime!
E Traceback (most recent call last):
File “/home/firefly/Desktop/AI3/vvv/lib/python3.7/site-packages/rknnlite/api/rknn_lite.py”, line 155, in init_runtime
self.rknn_runtime.build_graph(self.rknn_data, self.load_model_in_npu)
File “rknnlite/api/rknn_runtime.py”, line 358, in rknnlite.api.rknn_runtime.RKNNRuntime.build_graph
Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID
Init runtime environment failed
报错.only support ntb mode on ARM64 platform. But can not find device with ntb mod
解答在 http://t.rock-chips.com/forum.php?mod=viewthread&tid=1297
原来是. target = 'rk3399pro' 不能写死, 在开发板上写死就成外挂设备了. 必须是 target = None
# Init runtime environment
print('--> Init runtime environment')
if platform.machine() == 'aarch64':
#target = 'rk3399pro' 当前板子的NPU target是不用写的,写了就变成外接的rk3399pro了
# http://t.rock-chips.com/forum.php?mod=viewthread&tid=1297
target = None
else:
target = 'rk1808'
ret =rknn.init_runtime(target=target)
报错Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID
尝试将API的版本和驱动的版本都改成了 1.6.0 都不行. 降低API版本的方法就是
pip uninstall rknn-toolkit-lite # 卸载已有版本
#下载whl文件
pip install rknn_toolkit_lite-1.6.0-cp37-cp37m-linux_aarch64.whl # 安装新版本

额外插一句, RKNN官方的github中, 1.6.0版本里面没有放 rknn_toolkit_lite-1.6.0-cp37-cp37m.xxxx.whl的whl文件. 可能是忘记了.
但是在百度网盘里放了.
网盘地址
https://eyun.baidu.com/enterprise/share/link?cid=8272257679089781337&uk=2751701137&sid=201910153024123244#sharelink/parent_path=%2FGPU&path=%2FRKNN-Toolkit
驱动升级
由于我采用的是firefly 开发板, 所以. 使用下面的命令可以升级驱动.
解决方法:
sudo apt update
sudo apt install firefly-3399pronpu-driver
Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID
. 最后一个问题. Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID 这个问题中间放了好久,大概有半个多月 后来找到了原因, 在我要打算放弃RK3399pro的时候, 一位网友把他的模型发给我, 我试了一下, 还是不行. 他的模型在他哪里是可以跑的, 而在我这里不行… 看来问题出在我的代码上.
解决方法: 我的是如下的原因导致的

跑我自己的模型却如下错误. unpack_from requires a buffer of at least 8 bytes
D Save log info to: ./runlog.log
*************************
all device(s) with ntb mode:
99acfc273ef5bfec
*************************
--> Init runtime environment
W The perf_debug is not currently supported on RKNN Toolkit Lite.
D target set by user is: None
D Host is RK3399PRO
D Starting ntp or adb, target is None, host is RK3399PRO
D Start ntp...
I npu_transfer_proxy pid: 1792, status: sleeping
W Flag perf_debug has been set, it will affect the performance of inference!
E Catch exception when init runtime!
E Traceback (most recent call last):
File "/home/firefly/Desktop/AI37/vvv/lib/python3.7/site-packages/rknnlite/api/rknn_lite.py", line 154, in init_runtime
self.rknn_runtime.build_graph(self.rknn_data, self.load_model_in_npu)
File "rknnlite/api/rknn_runtime.py", line 364, in rknnlite.api.rknn_runtime.RKNNRuntime.build_graph
File "rknnlite/api/rknn_model.py", line 123, in rknnlite.api.rknn_model.RKNNModel.parse_data
struct.error: unpack_from requires a buffer of at least 8 bytes
解决方法: 应该是模型文件有问题.
** RKNN_ERR_MALLOC_FAIL**
99acfc273ef5bfec
*************************
--> Init runtime environment
W The perf_debug is not currently supported on RKNN Toolkit Lite.
D target set by user is: None
D Host is RK3399PRO
D Starting ntp or adb, target is None, host is RK3399PRO
D Start ntp...
I npu_transfer_proxy pid: 1792, status: sleeping
W Flag perf_debug has been set, it will affect the performance of inference!
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:51)
D NPUTransfer: Transfer spec = local:transfer_proxy
D NPUTransfer: Transfer interface successfully opened, fd = 4
E NPUTransfer: Alloc buffer failed!, size = 165032960
E RKNNAPI: rknn_init2, buf_send(MsgLoad) create fail!
D NPUTransfer: Transfer client closed, fd = 4
E Catch exception when init runtime!
E Traceback (most recent call last):
File "/home/firefly/Desktop/AI37/vvv/lib/python3.7/site-packages/rknnlite/api/rknn_lite.py", line 154, in init_runtime
self.rknn_runtime.build_graph(self.rknn_data, self.load_model_in_npu)
File "rknnlite/api/rknn_runtime.py", line 417, in rknnlite.api.rknn_runtime.RKNNRuntime.build_graph
Exception: RKNN init failed. error code: RKNN_ERR_MALLOC_FAIL
解决方法: 这是内存不足引起的. 关掉一些其它程序或者换个大一点的内存. 我是开了虚拟内存解决的 . 板子上新建了一个swap文件
RKNN_ERR_DEVICE_UNAVAILABLE
Exception: RKNN init failed. error code: RKNN_ERR_DEVICE_UNAVAILABLE
看起来是板子上的npu挂了,你要串口连npu里面看下日志
我跑其它的模型是可以跑的., 能返回结果. 我的模型有160MB.
是不是模型太大了?
解决方法: 经过测试,确实是模型文件太大就会导致不能加载, 我把resnet101改成了resnet18, 整个网络的体积就缩小到了55.7MB. 然后在转rknn的时候开了量化, 需要在dataset.txt里面填一张图片的地址就可以了.
2021-09-03 今天继续更新日记
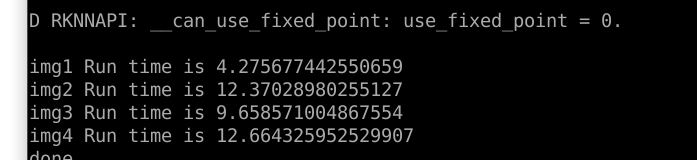
到目前为止基本上模型可以跑了, 但问题是太慢了. resnet18主干, 要跑4.3秒多, 而且重复跑同一张图所需时间差异很大, 非常不稳定.如下图: 问了下其它朋友, 他们有的才600ms…
RKNN_ERR_PARAM_INVALID
Exception: Set inputs failed. error code: RKNN_ERR_PARAM_INVALID
这个错误主要是因为输入图片的大小和转换到rknn时指定的图片大小不一致导致的.














 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









