







作者:heiyeluren
博客:http://blog.csdn.net/heiyeshuwu
时间:2007-11-18
【 前言 】
网 站在Web 2.0时代,时常面临迅速增加的访问量(这是好事情),但是我们的应用如何满足用户的访问需求,而且基本上我们看到的情况都是性能瓶颈都是在数据库上,这 个不怪数据库,毕竟要满足很大访问量确实对于任何一款数据库都是很大的压力,不论是商业数据库Oracle、MS sql Server、DB2之类,还是开源的MySQL、PostgreSQL,都是很大的挑战,解决的方法很简单,就是把数据分散在不同的数据库上(可以是硬 件上的,也可以是逻辑上的),本文就是主要讨论如何数据库分散存储的的问题。
目前主要分布存储的方式都是按照一定的方式进行切分,主要是垂直切分(纵向)和水平切分(横向)两种方式,当然,也有两种结合的方式,达到更到的切分粒度。
1. 垂直切分(纵向)数据是数据库切分按照网站业务、产品进行切分,比如用户数据、博客文章数据、照片数据、标签数据、群组数据等等每个业务一个独立的数据库或者数据库服务器。
2. 水平切分(横向)数据是把所有数据当作一个大产品,但是把所有的平面数据按照某些Key(比如用户名)分散在不同数据库或者数据库服务器上,分散对数据访问的压力,这种方式也是本文主要要探讨的。
本 文主要针对的的 MySQL/PostgreSQL 类的开源数据库,同时平台是在 linux/FreeBSD,使用 php/Perl/Ruby/Python 等脚本语言,搭配 Apache/Lighttpd 等Web服务器 的平台下面的Web应用,不讨论静态文件的存储,比如视频、图片、CSS、JS,那是另外一个话题。
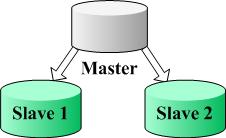
说明:下面将会反复提到的一个名次“节点”(Node),指的是一个数据库节点,可能是物理的一台数据库服务器,也可能是一个数据库,一般情况是指一台数据库服务器,并且是具有 Master/Slave 结构的数据库服务器,我们查看一下图片,了解这样节点的架构:
 (图1)
(图1)
【 一、基于散列的分布方式 】
1. 散列方式介绍
基 于散列(Hash)的分布存储方式,主要是依赖主要Key和散列算法,比如以用户为主的应用主要的角色就是用户,那么做Key的就可以是用户ID或者是用 户名、邮件地址之类(该值必须在站点中随处传递),使用这个唯一值作为Key,通过对这个Key进行散列算法,把不同的用户数据分散在不同的数据库节点 (Node)上。
我们通过简单的实例来描述这个问题:比如有一个应用,Key是用户ID,拥有10个数据库节点,最简单的散列算法是我们 用户ID数模以我们所有节点数,余数就是对应的节点机器,算法:所在节点 = 用户ID % 总节点数,那么,用户ID为125的用户所在节点:125 % 10 = 5,那么应该在名字为5的节点上。同样的,可以构造更为强大合理的Hash算法来更均匀的分配用户到不同的节点上。
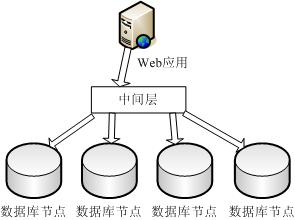
我们查看一下采用散列分布方式的数据结构图:
 (图2)
(图2)
2. 散列分布存储方式的扩容
我们知道既然定义了一个散列算法,那么这些Key就会按部就班的分散到指定节点上,但是如果目前的所有节点不够满足要求怎么办?这就存在一个扩容的问题,扩容首当其冲的就是要修改散列算法,同时数据也要根据散列算法进修迁移或者修改。
(1) 迁移方式扩容:修 改散列算法以后,比如之前是10个节点,现在增加到20个节点,那么Hash算法就是[模20],相应的存在一个以前的节点被分配的数据会比较多,但是新 加入的节点数据少的不平衡的状态,那么可以考虑使用把以前数据中的数据按照Key使用新的Hash算法进行运算出新节点,把数据迁移到新节点,缺点但是这 个成本相应比较大,不稳定性增加;好处是数据比较均匀,并且能够充分利用新旧节点。
(2) 充分利用新节点:增 加新节点以后,Hash算法把新加入的数据全部Hash到新节点上,不再往旧节点上分配数据,这样不存在迁移数据的成本。优点是只需要修改Hash算法, 无须迁移数据就能够简单的增加节点,但是在查询数据的时候,必须使用考虑到旧Key使用旧Hash算法,新增加的Key使用新的Hash算法,不然无法查 找到数据所在节点。缺点很明显,一个是Hash算法复杂度增加,如果频繁的增加新节点,算法将非常复杂,无法维护,另外一个方面是旧节点无法充分利用资源 了,因为旧节点只是单纯的保留旧Key数据,当然了,这个也有合适的解决方案。
总结来说,散列方式分布数据,要新增节点比较困难和繁琐,但是也有很多适合的场合,特别适合能够预计到未来数据量大小的应用,但是普遍 Web2.0 网站都无法预计到数据量。
【 二、基于全局节点分配方式 】
1. 全局节点分配方式介绍
就是把所有Key信息与数据库节点之间的映射关系记录下来,保存到全局表中,当需要访问某个节点的时候,首先去全局表中查找,找到以后再定位到相应节点。全局表的存储方式一般两种:
(1) 采用节点数据库本身(MySQL/PostgreSQL)存储节点信息,能够远程访问,为了保证性能,同时配合使用 Heap(MEMORY) 内存表,或者是使用 Memcached 缓存方式来缓存,加速节点查找
(2) 采用 BDB(BerkeleyDB)、DBM/GDBM/NDBM 这类本地文件数据库,基于 key=>value 哈希数据库,查找性能比较高,同时结合 APC、Memcached 之类的缓存加速。
第 一种存储方式是容易查询(包括远程查询),缺点是性能不太好(这个是所有关系型数据库的通病);第二种方式的有点是本地查询速度很快(特别是hash型数 据库,时间复杂度是O(1),比较快),缺点是无法远程使用,并且无法在多台机器中间同步共享数据,存在数据一致的情况。
我们来描述实施 大概结构:假如我们有10个数据库节点,一个全局数据库用于存储Key到节点的映射信息,假设全局数据库有一个表叫做 AllNode ,包含两个字段,Key 和 NodeID,假设我们继续按照上面的案例,用户ID是Key,并且有一个用户ID为125的用户,它对应的节点,我们查询表获得:
可以确认这个用户ID为125的用户,所在的节点是6,那么就可以迅速定位到该节点,进行数据的处理。
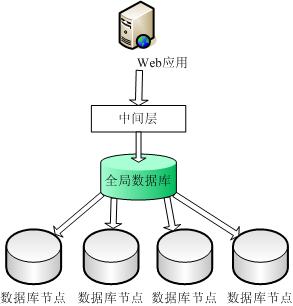
我们来查看一下分布存储结构图:
 (图3)
(图3)
2. 全局节点分布方式的扩容
全局节点分配方式同样存在扩容的问题,不过它早就考虑到这个问题,并且这么设计就是为了便于扩容,主要的扩容方式是两种:
(1) 通过节点自然增加来分配Key到节点的映射扩容
这 种是最典型、最简单、最节约机器资源的扩容方式,大致就是按照每个节点分配指定的数据量,比如一个节点存储10万用户数据,第一个节点存储0-10w用户 数据,第二个节点存储10w-20w用户数据,第三个节点存储20w-30w用户信息,依此类推,用户增加到一定数据量就增加节点服务器,同时把Key分 配到新增加的节点上,映射关系记录到全局表中,这样可以无限的增加节点。存在的问题是,如果早期的节点用户访问频率比较低,而后期增加的节点用户访问频率 比较高,则存在节点服务器负载不均衡的现象,这个也是可以想方案解决的。
(2) 通过概率算法来映射Key到节点的的扩容
这种方式是在既然有的节点基础上,给每个节点设定一个被分配到Key的概率,然后分配Key的时候,按照每个节点被指定的概率进行分配,如果每个节点平均的数据容量超过了指定的百分比,比如50%,那么这时候就考虑增加新节点,那么新节点增加Key的概率要大于旧节点。
一般情况下,对于节点的被分配的概率也是记录在数据库中的,比如我们把所有的概率为100,共有10个节点,那么设定每个节点被分配的数据的概率为10,我们查看数据表结构:
现在新加入了一个 节点,新加入的节点,被分配Key的几率要大于旧节点,那么就必须对这个新加入的节点进行概率计算,计算公式:10х+у=100, у>х,得出:у{10...90},х{1...9},x是单个旧节点的概率,旧节点的每个节点的概率是一样的,y是新节点的概率,按照这个计算 公式,推算出新节点y的概率的范围,具体按照具体不同应用的概率公式进行计算。
【 三、存在的问题 】
现在我们来分析和解决一下我们上面两种分布存储方式的存在的问题,便于在实际考虑架构的时候能够避免或者是融合一些问题和缺点。
1. 散列和全局分配方式都存在问题
(1) 散列方式扩容不是很方便,必须修改散列算法,同时可能还需要对数据进行迁移,它的优点是从Key定位一个节点非常快,O(1)的时间复杂度,而且基本不需要查询数据库,节约响应时间。
(2) 全局分配方式存在的问题最明显的是单点故障,全局数据库down掉将影响所有应用。另外一个问题是查询量大,对每个Key节点的操作都必须经过全局数据库,压力很大,优点是扩容方便,增加节点简单。
2. 分布存储带来的搜索和统计问题
(1) 一般搜索或统计都是对所有数据进行处理,但因为拆分以后,数据分散在不同节点机器上,无法进行全局查找和统计。解决方案一是对主要的基础数据存储在全局表中,便于查找和统计,但这类数据不宜太多,部分核心数据。
(2) 采用站内搜索引擎来索引和记录全部数据,比如采用 Lucene 等开源索引系统进行所有数据的索引,便于搜索。 对于统计操作可以采用后台非实时统计,可采用遍历所有节点的方式,但效率低下。
3. 性能优化问题
(1) 散列算法,节点概率和分配等为了提高性能都可以使用编译语言开发,做成lib或者是所有php扩展形式。
(2) 对于采用 MySQL 的情况,可以采用自定义的数据库连接池,采用 Apache Module 形式加载,能够自由定制的采用各种连接方式。
(3) 对于全局数据或都频繁访问的数据,可以采用APC、Memcache、DBM、BDB、共享内存、文件系统等各种方式进行缓存,减少数据库的访问压力。
(4) 采用数据本身的强大处理机制,比如 MySQL5 的表分区或者是 MySQL5 的Cluster 。另外建议在实际架构中采用InnoDB表引擎作为主要存储引擎,MyISAM作为一些日志、统计数据等场合,不论在安全、可靠性、速度都有保障。
【 总结 】
本 文泛泛的分析了在网站项目(特别是Web2.0)中关于数据库分布存储的一些方式方法,基本上上面提到的两种分布方案笔者都经过实验或者是使用过类似成型 的项目,所以在实践性方面是有保障的,至于在具体实施过程中,可以按照具体的应用和项目进行选择性处理,这样,让你的网站速度飞快,用户体验一流。同时本 文有些概念和描述不一定准确,如果有不足之处,请谅解并且提出来,不胜感谢。另外,如果有更好的方案或者更完善的解决方式,非常希望能够分享一下,本文更 希望起到抛砖引玉的作用。(转载本文,敬请注明出处为:http://blog.csdn.net/heiyeshuwu,谢谢! :-) )
博客:http://blog.csdn.net/heiyeshuwu
时间:2007-11-18
【 前言 】
网 站在Web 2.0时代,时常面临迅速增加的访问量(这是好事情),但是我们的应用如何满足用户的访问需求,而且基本上我们看到的情况都是性能瓶颈都是在数据库上,这 个不怪数据库,毕竟要满足很大访问量确实对于任何一款数据库都是很大的压力,不论是商业数据库Oracle、MS sql Server、DB2之类,还是开源的MySQL、PostgreSQL,都是很大的挑战,解决的方法很简单,就是把数据分散在不同的数据库上(可以是硬 件上的,也可以是逻辑上的),本文就是主要讨论如何数据库分散存储的的问题。
目前主要分布存储的方式都是按照一定的方式进行切分,主要是垂直切分(纵向)和水平切分(横向)两种方式,当然,也有两种结合的方式,达到更到的切分粒度。
1. 垂直切分(纵向)数据是数据库切分按照网站业务、产品进行切分,比如用户数据、博客文章数据、照片数据、标签数据、群组数据等等每个业务一个独立的数据库或者数据库服务器。
2. 水平切分(横向)数据是把所有数据当作一个大产品,但是把所有的平面数据按照某些Key(比如用户名)分散在不同数据库或者数据库服务器上,分散对数据访问的压力,这种方式也是本文主要要探讨的。
本 文主要针对的的 MySQL/PostgreSQL 类的开源数据库,同时平台是在 linux/FreeBSD,使用 php/Perl/Ruby/Python 等脚本语言,搭配 Apache/Lighttpd 等Web服务器 的平台下面的Web应用,不讨论静态文件的存储,比如视频、图片、CSS、JS,那是另外一个话题。
说明:下面将会反复提到的一个名次“节点”(Node),指的是一个数据库节点,可能是物理的一台数据库服务器,也可能是一个数据库,一般情况是指一台数据库服务器,并且是具有 Master/Slave 结构的数据库服务器,我们查看一下图片,了解这样节点的架构:
(图1)
【 一、基于散列的分布方式 】
1. 散列方式介绍
基 于散列(Hash)的分布存储方式,主要是依赖主要Key和散列算法,比如以用户为主的应用主要的角色就是用户,那么做Key的就可以是用户ID或者是用 户名、邮件地址之类(该值必须在站点中随处传递),使用这个唯一值作为Key,通过对这个Key进行散列算法,把不同的用户数据分散在不同的数据库节点 (Node)上。
我们通过简单的实例来描述这个问题:比如有一个应用,Key是用户ID,拥有10个数据库节点,最简单的散列算法是我们 用户ID数模以我们所有节点数,余数就是对应的节点机器,算法:所在节点 = 用户ID % 总节点数,那么,用户ID为125的用户所在节点:125 % 10 = 5,那么应该在名字为5的节点上。同样的,可以构造更为强大合理的Hash算法来更均匀的分配用户到不同的节点上。
我们查看一下采用散列分布方式的数据结构图:
(图2)
2. 散列分布存储方式的扩容
我们知道既然定义了一个散列算法,那么这些Key就会按部就班的分散到指定节点上,但是如果目前的所有节点不够满足要求怎么办?这就存在一个扩容的问题,扩容首当其冲的就是要修改散列算法,同时数据也要根据散列算法进修迁移或者修改。
(1) 迁移方式扩容:修 改散列算法以后,比如之前是10个节点,现在增加到20个节点,那么Hash算法就是[模20],相应的存在一个以前的节点被分配的数据会比较多,但是新 加入的节点数据少的不平衡的状态,那么可以考虑使用把以前数据中的数据按照Key使用新的Hash算法进行运算出新节点,把数据迁移到新节点,缺点但是这 个成本相应比较大,不稳定性增加;好处是数据比较均匀,并且能够充分利用新旧节点。
(2) 充分利用新节点:增 加新节点以后,Hash算法把新加入的数据全部Hash到新节点上,不再往旧节点上分配数据,这样不存在迁移数据的成本。优点是只需要修改Hash算法, 无须迁移数据就能够简单的增加节点,但是在查询数据的时候,必须使用考虑到旧Key使用旧Hash算法,新增加的Key使用新的Hash算法,不然无法查 找到数据所在节点。缺点很明显,一个是Hash算法复杂度增加,如果频繁的增加新节点,算法将非常复杂,无法维护,另外一个方面是旧节点无法充分利用资源 了,因为旧节点只是单纯的保留旧Key数据,当然了,这个也有合适的解决方案。
总结来说,散列方式分布数据,要新增节点比较困难和繁琐,但是也有很多适合的场合,特别适合能够预计到未来数据量大小的应用,但是普遍 Web2.0 网站都无法预计到数据量。
【 二、基于全局节点分配方式 】
1. 全局节点分配方式介绍
就是把所有Key信息与数据库节点之间的映射关系记录下来,保存到全局表中,当需要访问某个节点的时候,首先去全局表中查找,找到以后再定位到相应节点。全局表的存储方式一般两种:
(1) 采用节点数据库本身(MySQL/PostgreSQL)存储节点信息,能够远程访问,为了保证性能,同时配合使用 Heap(MEMORY) 内存表,或者是使用 Memcached 缓存方式来缓存,加速节点查找
(2) 采用 BDB(BerkeleyDB)、DBM/GDBM/NDBM 这类本地文件数据库,基于 key=>value 哈希数据库,查找性能比较高,同时结合 APC、Memcached 之类的缓存加速。
第 一种存储方式是容易查询(包括远程查询),缺点是性能不太好(这个是所有关系型数据库的通病);第二种方式的有点是本地查询速度很快(特别是hash型数 据库,时间复杂度是O(1),比较快),缺点是无法远程使用,并且无法在多台机器中间同步共享数据,存在数据一致的情况。
我们来描述实施 大概结构:假如我们有10个数据库节点,一个全局数据库用于存储Key到节点的映射信息,假设全局数据库有一个表叫做 AllNode ,包含两个字段,Key 和 NodeID,假设我们继续按照上面的案例,用户ID是Key,并且有一个用户ID为125的用户,它对应的节点,我们查询表获得:
| Key | NodeID |
| 13 | 2 |
| 148 | 5 |
| 22 | 9 |
| 125 | 6 |
可以确认这个用户ID为125的用户,所在的节点是6,那么就可以迅速定位到该节点,进行数据的处理。
我们来查看一下分布存储结构图:
(图3)
2. 全局节点分布方式的扩容
全局节点分配方式同样存在扩容的问题,不过它早就考虑到这个问题,并且这么设计就是为了便于扩容,主要的扩容方式是两种:
(1) 通过节点自然增加来分配Key到节点的映射扩容
这 种是最典型、最简单、最节约机器资源的扩容方式,大致就是按照每个节点分配指定的数据量,比如一个节点存储10万用户数据,第一个节点存储0-10w用户 数据,第二个节点存储10w-20w用户数据,第三个节点存储20w-30w用户信息,依此类推,用户增加到一定数据量就增加节点服务器,同时把Key分 配到新增加的节点上,映射关系记录到全局表中,这样可以无限的增加节点。存在的问题是,如果早期的节点用户访问频率比较低,而后期增加的节点用户访问频率 比较高,则存在节点服务器负载不均衡的现象,这个也是可以想方案解决的。
(2) 通过概率算法来映射Key到节点的的扩容
这种方式是在既然有的节点基础上,给每个节点设定一个被分配到Key的概率,然后分配Key的时候,按照每个节点被指定的概率进行分配,如果每个节点平均的数据容量超过了指定的百分比,比如50%,那么这时候就考虑增加新节点,那么新节点增加Key的概率要大于旧节点。
一般情况下,对于节点的被分配的概率也是记录在数据库中的,比如我们把所有的概率为100,共有10个节点,那么设定每个节点被分配的数据的概率为10,我们查看数据表结构:
| NodeID | Weight |
| 1 | 10 |
| 2 | 10 |
| 3 | 10 |
现在新加入了一个 节点,新加入的节点,被分配Key的几率要大于旧节点,那么就必须对这个新加入的节点进行概率计算,计算公式:10х+у=100, у>х,得出:у{10...90},х{1...9},x是单个旧节点的概率,旧节点的每个节点的概率是一样的,y是新节点的概率,按照这个计算 公式,推算出新节点y的概率的范围,具体按照具体不同应用的概率公式进行计算。
【 三、存在的问题 】
现在我们来分析和解决一下我们上面两种分布存储方式的存在的问题,便于在实际考虑架构的时候能够避免或者是融合一些问题和缺点。
1. 散列和全局分配方式都存在问题
(1) 散列方式扩容不是很方便,必须修改散列算法,同时可能还需要对数据进行迁移,它的优点是从Key定位一个节点非常快,O(1)的时间复杂度,而且基本不需要查询数据库,节约响应时间。
(2) 全局分配方式存在的问题最明显的是单点故障,全局数据库down掉将影响所有应用。另外一个问题是查询量大,对每个Key节点的操作都必须经过全局数据库,压力很大,优点是扩容方便,增加节点简单。
2. 分布存储带来的搜索和统计问题
(1) 一般搜索或统计都是对所有数据进行处理,但因为拆分以后,数据分散在不同节点机器上,无法进行全局查找和统计。解决方案一是对主要的基础数据存储在全局表中,便于查找和统计,但这类数据不宜太多,部分核心数据。
(2) 采用站内搜索引擎来索引和记录全部数据,比如采用 Lucene 等开源索引系统进行所有数据的索引,便于搜索。 对于统计操作可以采用后台非实时统计,可采用遍历所有节点的方式,但效率低下。
3. 性能优化问题
(1) 散列算法,节点概率和分配等为了提高性能都可以使用编译语言开发,做成lib或者是所有php扩展形式。
(2) 对于采用 MySQL 的情况,可以采用自定义的数据库连接池,采用 Apache Module 形式加载,能够自由定制的采用各种连接方式。
(3) 对于全局数据或都频繁访问的数据,可以采用APC、Memcache、DBM、BDB、共享内存、文件系统等各种方式进行缓存,减少数据库的访问压力。
(4) 采用数据本身的强大处理机制,比如 MySQL5 的表分区或者是 MySQL5 的Cluster 。另外建议在实际架构中采用InnoDB表引擎作为主要存储引擎,MyISAM作为一些日志、统计数据等场合,不论在安全、可靠性、速度都有保障。
【 总结 】
本 文泛泛的分析了在网站项目(特别是Web2.0)中关于数据库分布存储的一些方式方法,基本上上面提到的两种分布方案笔者都经过实验或者是使用过类似成型 的项目,所以在实践性方面是有保障的,至于在具体实施过程中,可以按照具体的应用和项目进行选择性处理,这样,让你的网站速度飞快,用户体验一流。同时本 文有些概念和描述不一定准确,如果有不足之处,请谅解并且提出来,不胜感谢。另外,如果有更好的方案或者更完善的解决方式,非常希望能够分享一下,本文更 希望起到抛砖引玉的作用。(转载本文,敬请注明出处为:http://blog.csdn.net/heiyeshuwu,谢谢! :-) )















 3159
3159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









