







眼看着项目即将完成,却被测试人员告知没有通过性能测试,这种情况在开发中屡见不鲜。接下来的工作就是加班加点地找出性能瓶颈,然后进行优化,再进行性能测试,如此这般周而复始直到通过性能测试。尽管丰富的工作经验有助于性能优化,但只有科学地应用工具才能在最短的时间内找出最佳优化粒度的瓶颈代码段,达到事半功倍的效果。
profile、cProfile与hotshot
Python 内置了丰富的性能优化工具来帮助我们定位性能瓶颈,如:profile、cProfile和 hotshot。它们易于使用,而且有完备的支持文档可供参考。下面以最常用的 profile 模块为例来说明它们的使用方法,假定要剖分的脚本文件为 foo.py ,它的内容如下:
def foo():
sum = 0
for i in range(100):
sum += i
return sum
if __name__ == "__main__":
foo()
对 foo.py 进行性能剖分的方法之一是修改 foo.py 里的 if 程序块,引入 profile 模块:
if __name__ == "__main__":
import profile
profile.run("foo()")
然后执行 foo.py 即可完成性能剖分,剖分结果将以文本报表的形式打印到标准输出。
因为上述方法需要修改 foo.py 文件,所以我们通常更倾向于使用无需修改源文件的方法——就是在命令行中用应用 python 的 –m 参数来执行 profile :
python –m profile foo.py
除了可以使用 profile 模块外,还可以使用 cProfile 模块。cProfile由 C 语言实现,是剖分代价更低的剖分器,有和 profile 模块相同的接口,但只能用于2.5或以上版本。Python 另一个内置的剖分器是 hotshot,但是 hotshot 模块已经不再推荐使用,因为将来它可能会被移出标准库。
pstats
无论使用哪个剖分器,它的剖分数据都可以保存到二进制文件,如foo.prof。分析和查看剖分结果文件需要使用 pstats 模块,它极具伸缩性,可以输出形式多样的文本报表,是文本界面下不可或缺的工具。
使用 pstats 分析剖分结果很简单,几行代码就可以了:
import pstats
p = pstats.Stats("foo.prof")
p.sort_stats("time").print_stats()
运行上述脚本将输出结果为按函数内部运行时间(不计调用子函数的时间)长短排序的报表。
sort_stats() 方法是 pstats.Stats 最重要的方法之一,它用以对剖分数据进行排序。sort_stats() 接受一个字符串参数,这个字符串标识了排序的字段,常用的可选的参数及其意义如下:
‘ncalls’
被调用次数
‘cumulative’
函数运行的总时间
‘nfl’
Name/file/line
‘time’
函数内部运行时间(不计调用子函数的时间)
除了 sort_stats() 外, pstats.Stats 还有 print_callees() 和 print_callers() 方法用以输出指定函数所调用的函数和调用过指定函数的函数。
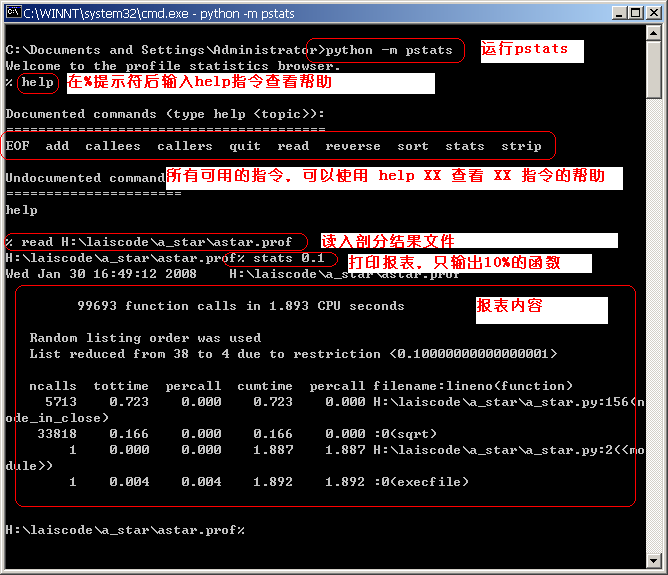
除了编编程接口外,pstats 还提供了友好的命令行交互环境,在命令行执行 python –m pstats 就可以进入交互环境,在交互环境里可以使用 read/add 指令读入/加载剖分结果文件,stats 指令用以查看报表, callees 和 callers 指令用以查看特定函数的被调用者和调用者。下图是 pstats 的截图,标识了它的基本使用方法:















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









