






1、下载PaddleOCR release2.3
2、整理数据集
标签文本中的路径和标签值中间是一个tab
读取标签文件的时候,是把标签文件中的路径和上面数据集的路径合在一起,然后指向图片。
3、训练模型和配置文件config相对应,
比如说用的模型是ch_PP-OCRv2_rec,那么对应的配置文件也是ch_PP-OCRv2_rec.yml
4、训练及测试的代码
python tools/train.py -c configs/rec/20220511_ch_PP-OCRv2_rec.yml
python tools/infer_rec.py -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml评估及生成export模型,以及详细参数的测试
python tools/eval.py -c configs/rec/20220511_ch_PP-OCRv2_rec.yml -o Global.checkpoints="./output/rec/202205121/best_accuracy"
python tools/export_model.py -c configs/rec/20220511_ch_PP-OCRv2_rec.yml -o Global.checkpoints="./output/rec/202205121/best_accuracy" Global.save_inference_dir="./output/rec/202205121/export_model"
python tools/infer_rec.py -c configs/rec/20220511_ch_PP-OCRv2_rec.yml -o Global.checkpoints="./output/rec/202205160436/best_accuracy" Global.load_static_weights=false Global.infer_img="./train_data/test_20220429/"5、测试的时候出现一个问题
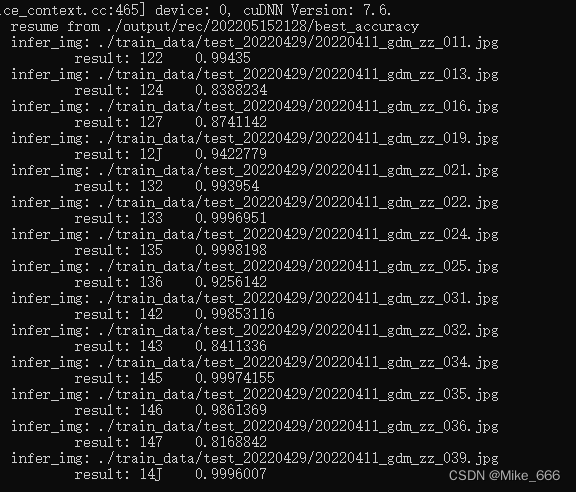
准确率很高,但是每个图片的识别结果都比原来大111
反复试验了几次,觉得训练过程应该没有问题,应该是哪个细节没整对,导致出现了这个偏差,
然后就去看字典,下面是我的字典


然后就看了一下icar15的字典
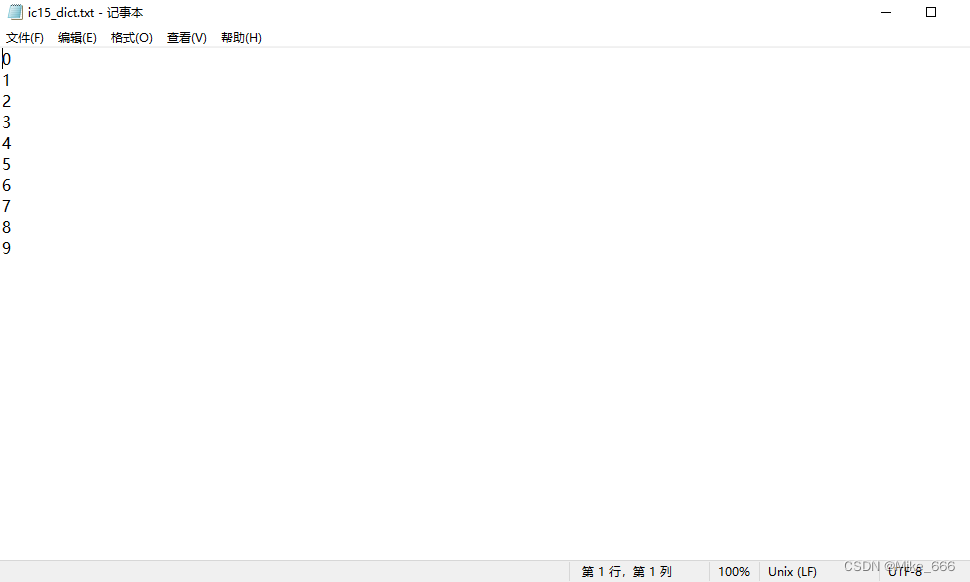
发现没有指向字符0,而是把字符1当成了字符0,把字符2当成了字符1,依次往下错了一位。
带BOM的UTF-8, UTF-8
Windows(CRLF), Unix(LF)
然后就搜了一下Windows(CRLF)和Unix(LF)的区别

根据以上线索,我重建了一个字典,然后用NotePad++把在Windows系统下建的txt文件格式改为Unix(LF)。编辑——》文档格式转换——》转为Unix(LF)
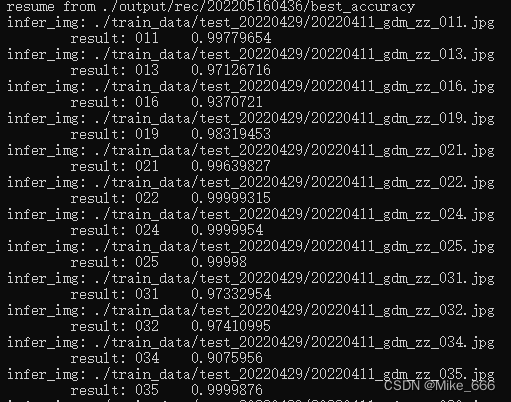
重新训练,结果正常















 5876
5876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









