






转载:https://blog.csdn.net/Swocky/article/details/106438795
标题:PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
链接:http://xxx.itp.ac.cn/pdf/2004.00452v1.pdf
摘要
基于图像的3D人体估计已经在深度神经网络的帮助下取得了重大的进展。即使现在很多的方法已经证明在真实世界应用的潜力,它们仍然难以产生输入图呈现出的细节。作者认为这来自于两个冲突的需求:精确的预测需要更多的上下文,但是精确的预测需要高分辨率。由于硬件的内存限制,之前的很多方法把低分辨率图作为输入以涵盖更多的上下文,然后产生较低准确率的3D估计。作者通过形成一个多层次的端对端可循了结构来解决这个问题。粗略的层次在较低的分辨率下观察整个图像,并侧重于整体推理。这为通过观察高分辨率图像估计细致的几何结构提供了上下文信息。作者证明了他们的方法在该领域已经超过了SOTA。
1、介绍
高保真的人体数字化是大多数从医学影像到虚拟现实的关键。尽管测量准确和精确的人体重建现在通过多场景系统已经成为了可能,但是对于大多数人来讲由于它依赖于专业的采集设备还是很难去使用。越来越多的人们开始使用高容量深度学习模型,然后效果比起转业的采集设备还是有很大的差距。
作者工作的目标是实现从单张图对着衣人体进行重建,实现一个足以分辨出手指、面部特征和衣褶的分辨率。作者认为现在的很多方法没有充分利用高分辨率,尽管分辨率1k及以上的图像现在通过手机就能很容易的获取。这是因为之前的工作更加依赖整体的推断在2D外观和3D形状之间进行映射,由于内存要求过高,使用了低采样图像。尽管现在的图像有很多能够进行精细的3D重建的细节,但是由于图形硬件内存的限制也很少使用。
着力于解决这个限制的可以被认为是两个阵营之一。第一个阵营,问题被分解为一个由粗到细的方法,在低保真度表面上压印高频细节。这种方法中,低图像分辨率被用于去获取粗略外形,然后细节通过例如Shape From Shading或神经网络中的合成的方式进行添加。第二个阵营使用人体的高保真模型来产生合理的细节。尽管两种方法都使重建更加细致,但是细节并非是原图中的细节。
本文提出的方法是一个端到端的多层次框架,不需要后处理。不同于从粗到细的方法,作者的方法没有明确的几何结构表示被加强,相反,隐式编码的几何上下文被传播到更高的层次,而不必对几何体的过早性做出明确的决定。作者们基于最近提出的像素对齐隐式函数(Pixel-Aligned Implicit Function, PIFu)表示法。该表示的像素对齐特性使我们能够以一种原则性的方式将从粗糙推理中学习到的整体嵌入与从高分辨率输入中学习到的图像特征无缝融合。每一级增量地包含在粗略级别中丢失的附加信息,最终确定的几何图形仅在最高级别中进行。
最后,为了完整的重建,系统需要恢复背面,在图像中并没有给出的信息。随着低分辨率输入,失去一些不可预测的信息是难免的,会造成总体的平滑与模糊。作者通过利用image-to-image转换网络产生背部信息来克服这个问题。
本文工作的主要贡献如下:
- 实现了一个端到端可训练的从粗到细的框架来实现1k分辨率图像的重建
- 提出了一个能够有效处理不确定区域的方法,能够实现精细的完整重建
2、相关工作
Single-View 3D Human Digitization
单视图三维人体重建是一个不适定问题,其主要原因是摄像机光线的深度模糊。为了克服这种模糊性,参数化三维模型通常被用于将估计限制在一组小的模型参数上,将解空间限制在特定选择的参数化实体模型上。然而,结果模型的表达能力受限于使用单个模板网格以及在其上构建模型的数据(通常主要由衣着简陋的人组成)。虽然使用单独的参数化模型可以缓解有限的形状变化,但对于这些形状表示,大变形和拓扑变化仍然是不容易处理的。
当然也有不适用参数化模型的方法,而是直接从单个视图回归“自由形式”的三维人体几何。这些方法基于根据使用的输入输出表示不同而改变。有些方法通过volumetric representation表示输出,离散体素表示所要求的例题内存要求,仅仅通过简单地缩放输入分辨率就无法获得高分辨率。另一种方法是在参数模型空间上考虑附加的自由变形,还有多种方法可以预测目标人物的深度图作为输出。
最近提出的 Pixel-Aligned Implicit Function(PIFu)方法效果比较好,作者也采用了这个方法。
High-Resolution Synthesis in Texture Space
很多现在的放到都通过纹理映射表示来重建高质量的3D纹理或几何结构。Tex2Shape方法通过回归展开的UV空间来重建高质量的3D集合结构。然后这种方法受限于模板网格的拓扑结构(表示不同的拓扑结构,例如不同的发型或裙子)和UV参数选择的拓扑(例如在纹理接缝处可见的接缝伪影)。
作者的方法也关于产生高质量和高分辨率的合成人类图片,现在考虑产生高质量合成脸来克服原生GAN方法局限。类似的权衡在语义分割中也有。
3、具体方法
作者的方法基于最近提出的Pixelaligned Implicit Function (PIFu) 框架,能够输入512 × 512 的图片产生低分辨率的特征embeddings(128 × 128)。为了实现高分辨率的输出,作者在框架的顶部加入了一个额外的像素对其预测模块,另一个模块把高分辨率特征embeddings和3D embeddings来预测occupancy
probability field。为了进一步重建的质量和保真度,作者首次预测图片空间中前后面的正则映射,并将这些信息作为额外输入传入模型。
Pixel-Aligned Implicit Function
下面简单介绍下PIFu的基础,组成了作者方法的粗层面。3D 人体数字化的目标可以通过估计密集3D体积的占用实现(这里不太懂),决定3D空间中的点是否在人体内。相对于之前的方法目标3D空间被离散化并且算法显示地关注每个体素,PIFu的目标是建模一个能够预测每个在连续的相机空间中给的3D位置binary occupancy value的函数。
既然没有训练过程中显式的3D容量被存储在内存中,这个方法能够比较节约内存。更重要的是,对于目标3D容量并不需要离散化,这对于获取目标人体高保真的的3D几何结构是很重要的。 PIFu通过一个神经网络结构来拟合这个函数,使用端到端的方法训练。
另外,函数f最初从映射的2维位置提出一个图像特征embedding,通过φ(x, I)表示。正交投影被用于特征提取变换π中,因此x = π(X) = (Xx, Xy),然后估计3D点的occupancy情况。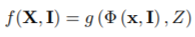
这里这个Z是通过2D投影x沿着射线定义的深度。注意所有沿着一个射线来自一个投影位置x的3D点有一样的图像特征φ(x, I),,所以g应该关注深度Z。其中φ是一个CNN,g是一个MLP。
f使用大量的合成高质量3D人体网格模型来训练,不同于基于体素的方法,PIFu不产生离散的容量作为输出,因此训练可以通过采样3D点和计算occupancy loss在实现,不需要产生3D网格。推断过程中,3D空间非正式的采样来推断occupancy并且最后的等值面使用marching cubes根据阈值0.5来提取。
Limitations
现存PIFu的输入图像尺寸被限制在最大512 × 512或128 × 128,主要由于硬件设备的限制。很重要的一点是,网络需要被设计它的感受野能够覆盖整个图像,从而可以被部署到整体的推理。因此一个重复的自底向上和自顶向下的方法在鲁棒的三维重建中发挥了重要的作用。这防止了该方法将高分辨率图像作为输入并将分辨率保持在特征嵌入中,即使这可能允许网络利用仅在这些高分辨率下存在的关于细节的提示。(这句没看懂,强行翻译了一波)作者发现尽管在理论上PIFu连续的表示可以代表任意的方式的3D几何,但在实际情况下受限于特征分辨率。因此,需要一个更有效地方式平衡全局观察的鲁棒性和高层特征嵌入分辨率的表达。
Multi-Level Pixel-Aligned Implicit Function

这张图还是能很好地描述基本的架构,输入图像在PIFu中计算一个低分辨率的情况,卷积后通过mlp,mlp中还需要加入深度信息,然后得到的结果一个通过mlp输出,一个与下面前后估计通过cnn后的结果合并,然后通过mlp得到一个高分辨率的情况。
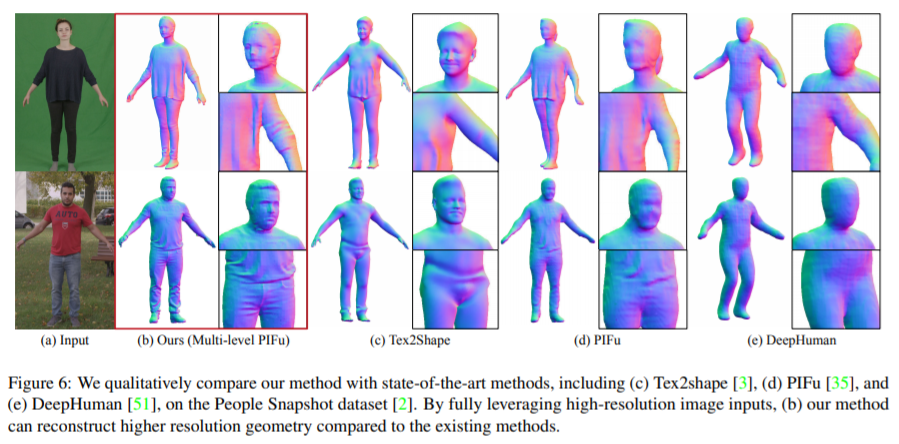
文中提出的模型以1024 × 1024分辨率的图像作为输入,采用了多层次方法来实现高保真的3D人体数字化。作者的方法由两个层次的PIFu模块组成,一个类似PIFu的粗略层次,注重通过下采样的512 × 512作为输入合并几何信息,并产生128 × 128的主干图像,另一个细层次的通过原来1024×1024的图像作为输入产生细节,产生512×512分辨率的图像特征。值得注意的是,细层面的模型将从出层面而不是绝对深度值提取出3D embedding特征。作者的粗层面模型被定义的很类似于PIFu,但是作为一个改良版,它还接受预测的正面和背面normal maps: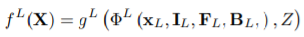
IL是低分辨率输入,FL和BL是预测的normal map
细层次的表示如下:
其实IH, FH和BH分别是输入图像、正面normal map和背面normal map
因为细层面从第一个像素对齐的MLP提取特征作为一个3D embedding,全局重建质量不应该退化,并且如果设计的网络能够被合理的利用还会提升图像的分辨率和网络容量。另外,细层面的网络不应该处理正则化因此不需要看到整个图片,从而使作者能够通过输入层面的裁剪区域作为输入。因此可以使用某一区域更加高分辨率的图像输入。
精确地预测人背部的集合是一个难以解决的问题,因为它无法从图像中看到。背面应该因此由MLP预测,由于问题的歧义和多模态的本质,三维重建趋向于平滑以及没有太多特征。部分原因是占用损失有利于不确定条件下的平均重建,但也因为最终的MLP层需要学习复杂的预测函数。
作者发现如果转换推断问题为特征提取阶段,那么网络可以产生更加不平滑的重建几何结构,为了实现这个,作者为图像中的3D几何结构预测normal maps作为代理,并且将其作为像素对齐预测期的特征。从而三维重建就由这些map来引导推断一个特定的3D集合结构,使MLP能够更容易地产生细节。作者使用pix2pix网络来预测前后的normals,从RGB图像映射到normal maps。类似于最近的一些方法,作者发现这个能在问题域限制下为看不见的背面产生合理的输出。
Loss Functions and Surface Sampling
代价函数的设计对于模型的学习效果有重要的作用,作者并没有使用L1或L2 loss,而是使用了BCE loss。公式如下: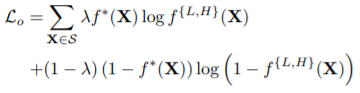
作者使用了uniform volume sample和在表面通过uniformly sampled表面的点使用高斯摄动进行importance sampling。作者发现该方法比采样点与距离曲面的倒数成比例得到更锐化的结果。事实上,在表面使用混合高斯球得到一个更好的有着高曲率的采样密度,从而也能增强细节。
//翻译的很烂,确实很多术语没怎么看懂
4、实验结果
// 使用的数据集和数据处理方式还是有很多值得学习的地方,时间关系暂时略过,具体可以看原论文

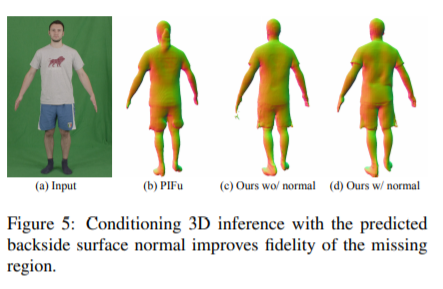

总结
作者提出了一个多层次的框架,能够将总体躯干信息与具体的细节合并,来实现一个从单张图片中的高分辨率着衣人体三维重建,不需要任何后处理方法。作者通过作为隐式三维嵌入的比例金字塔增量传播全局上下文来实现多层次Pixel-Aligned Implicit Function,防止在先验不足的情况下进行明确的几何预测。
由于多层方法依赖于先前阶段提取三维嵌入的成功,因此提高基线模型的稳健性将直接提高整体重建精度。未来的工作可能包括合并特定于人类的先验知识(例如,语义分割、姿势和参数化三维人脸模型)和添加隐式曲面的二维监督,以进一步支持wild输入。
总的来说,作者通过两条分支,分别得到粗层次和细层次的信息,这样躯干需要更大区域,而细节需要更大分辨率的问题就得以解决,然后将两者合并起来,得到最后的三维重建结果,这个多层次、分别处理的思想解决了人体三维重建精度的一个矛盾。然后,跟进比较新的技术,作者使用Pixel-Aligned Implicit Function、pix2pixHD网络实现分支的具体计算,并设计了很清晰的数学表示。除了使用BCE loss,比较重要技巧还有合适的采样模式,有利于整体三维重建的效果。
最后,尽管读的很吃力,很多细节来不及挖掘,但是对人体重建的还是有了一点了解,后面有时间尽量对里面用到的一些技术与之前的一些工作进行学习,进一步接触这个领域。就本文而言,最大的贡献可能就是提出了这个多层次的网络,妥善地解决了总体信息与细节的问题,但是这个类似confusion的思想在语义分割也是很常见的,所以够想并不是特别的难,关键在于发现这个影响精度的问题。















 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









