







Conservative Novelty Synthesizing Network for Malware Recognition in an Open-Set Scenario
摘要:
- 问题背景:我们研究了对已知和新的未知恶意软件家族进行恶意软件识别的挑战性任务,称为恶意软件开放集识别(MOSR)。以前的工作通常假设分类器在密集的情况下知道恶意软件家族,即测试家族是子集或最多与训练家族相同。然而,在现实世界的应用中经常出现新的未知恶意软件家族,因此需要在开放集场景中识别恶意软件实例,即一些未知的家族也包括在测试集中,这在网络安全领域很少被彻底研究。
- 问题:MOSR的一个实际解决方案可以考虑通过一个单一的分类器(如神经网络)从已知家族的预测概率分布的方差来联合分类已知和检测未知的恶意软件家族。然而,传统的训练有素的分类器通常倾向于在输出中获得过高的识别概率,特别是当实例特征分布彼此相似时,例如,未知与已知的恶意软件家族,因此,极大地降低了对新型未知恶意软件家族的识别。
- 方案:为了解决这个问题并构建一个适用的MOSR系统,我们提出了一个新的模型,可以保守地合成恶意软件实例来模仿未知的恶意软件家族,并支持更强大的分类器的训练。更具体地说,我们在生成式对抗网络的基础上,探索并获得接近已知家族的边缘恶意软件实例,同时落入模仿的未知家族,以指导分类器降低和平坦未知家族的识别概率,并相对提高已知家族的识别概率,从而纠正分类和检测的性能。我们进一步构建了一个涉及分类、合成和矫正的合作训练方案,以促进训练并共同提高模型性能。此外,我们还建立了一个新的大型恶意软件数据集,名为MAL-100,以填补缺乏大型开放性恶意软件基准数据集的空白。
- 结果:在两个广泛使用的恶意软件数据集和我们的MAL-100上的实验结果证明了我们的模型与其他代表性方法相比的有效性。
引言:
- 恶意软件识别背景:恶意软件,又称恶意软件,包括计算机病毒、间谍软件、特洛伊木马、蠕虫等,会对各种设备和公共网络造成严重破坏,并导致网络安全的许多问题。近年来,恶意软件的实例不断增加,带来了许多挑战[1],[2]。恶意软件识别的目的是将众多的恶意软件实例分类为不同的家族,即一组具有类似攻击技术的恶意软件实例,然后可以进行进一步的调查和预防措施。以前的恶意软件识别工作通常持有一个相对较强的假设,即所有的恶意软件家族对识别系统来说都是已知的,这意味着测试实例与训练实例在近似的情况下属于同一家族。这种设定是可以部分接受的,因为一方面,恶意软件家族在一定时期内是相对稳定的,另一方面,从整个网络中完全收集所有的恶意软件家族是不可能的。因此,在过去的几年里,封闭式的恶意软件识别已经被广泛研究[3]-[6]。
- 开放集恶意软件识别背景:然而,随着近年来网络应用的普及,越来越多的恶意软件攻击者不断发布属于各种已知家族的恶意软件实例和更多新的未知家族。正如NortonLifeLock(以前称为赛门铁克)[7]所指出的,每年有超过3.17亿个新的恶意软件实例被发现,其中许多不属于我们以前已经知道的任何恶意软件家族。这些新的未知恶意软件家族的实例在一些特征上有所不同,如统计特征、攻击技术等。在这种情况下,传统的恶意软件识别系统无法处理识别任务,不仅需要对已知家族进行分类,还需要同时检测新的未知家族。如图1所示,已知恶意软件家族的实例,如 "Neshta"、"Ramnit "和 "Adposhel",在分类器的训练阶段被使用。在测试或推理过程中,分类器首先要正确区分一个实例是否来自这些已知的家族,然后尽可能准确地将其分类到一个特定的已知家族。这项任务可以被视为恶意软件开放集识别(MOSR),其中 "开放集 "的概念在计算机视觉领域的一些最新作品中被注意到[8]。
- 问题:作为一个重要而实用的现实世界应用,网络安全领域很少对开放场景下的恶意软件识别进行研究,这阻碍了恶意软件识别系统的进一步发展。受计算机视觉领域的一些工作的启发,开放场景的图像识别可以通过单一的分类器(如神经网络)实现,并由网络输出的方差决定。例如,多类分类网络的输出softmax[9]可以代表已知家族上的预测识别概率分布。因此,已知类的分类可以由预测的识别概率的最大维度值决定,而新的未知类的检测可以由与所有维度值比较的阈值概率决定,也就是说,如果一个测试实例的所有维度值都小于阈值概率,那么这个实例就被认为是来自一个新的未知类。这样的识别框架在计算机视觉领域运作良好[10]-[13]。然而,恶意软件实例特征的差异远远小于图像的差异,因此会导致不同恶意软件家族之间的许多重叠。这种差异可能使该框架不适用于MOSR任务,因为对已知和未知恶意软件家族的所有恶意软件实例的预测识别概率可能趋于过高。
- 解决方案:为了处理这些问题并构建一个适用的MOSR系统,我们提出了保守的新颖性合成网络(CNSNet)来协调和支持恶意软件识别系统,以适应开放场景。具体来说,我们利用生成对抗网络(GANs)来合成几个边缘的恶意软件实例,这些实例与已知的家族接近,但不属于任何家族。然后,这些合成的实例被分配为模拟新的未知恶意软件家族,并隐含地修正分类器,使其对已知家族相对更敏感,同时大大抑制对未知家族的敏感性。这种矫正可以通过对合成实例的两个正则器进行约束来实现,这两个正则器分别考虑降低和平坦全局的识别概率(整体未知概率平坦化)和最小化局部的批级识别概率(特定的已知家族排除)。因此,我们的模型能够更好地区分已知和未知的恶意软件家族,提高分类和检测性能。为了在一个统一的框架内共同优化分类、合成和矫正,我们进一步构建了一个合作训练方案,使每个组件相互补充,交替改进。
- 数据与实验结果:此外,为了验证我们的模型在总体上运行良好,我们还付出了巨大的努力,建立并提出了一个新的大规模恶意软件数据集,其中包含100个恶意软件家族的5万多个恶意软件实例,称为MAL-100,以填补在恶意软件识别领域缺乏大型恶意软件开放基准数据集的空白。实验结果验证了我们提出的方法的有效性,并证明了我们提出的大规模恶意软件数据集的灵活性。
- 主要贡献:综上所述,我们的贡献有四个方面。1)我们提出了第一个在开放场景下的恶意软件识别的正式调查。2)我们提出了一个新的MOSR框架,可以保守地合成边缘恶意软件实例,以模仿新的未知家族,并共同提高分类和检测的性能。3)我们提出了一个合作训练方案,客观上统一了系统,促进了训练过程。4)我们提出了一个大规模的恶意软件基准数据集,即MAL-100,以补充开放场景下的恶意软件识别,这可以不断促进未来研究。
相关工作
A. 恶意软件家族识别
传统的恶意软件识别系统旨在将恶意软件实例分为几个已知的家族,主要是基于以静态或动态方式分析实例收集的恶意软件特征[14], [15]。由于恶意软件的动态分析通常很耗时,并且需要对实例进行大量额外的沙盘实验,这使得在现实世界的应用中无法实现实时识别。因此,静态分析更适合大规模的恶意软件识别系统,并被大多数现有工作所采用。静态分析可以涉及实例的几个静态特征,如激活机制、安装方法、携带的恶意有效载荷的性质等[2],[16]。最近先进的密集式恶意软件识别工作通常采用经典机器学习(CML)和深度学习(DL)技术来实现其模型。
- 对于基于CML的方法,Wu等人[17]提出使用k-means和k-nearest neighbor(KNN)算法,根据静态特征,如意图、权限和API调用,对恶意软件应用程序进行分类。Dahl等人[3]应用随机投影对原始输入空间进行降维,并训练几个大规模神经网络系统来识别恶意软件实例。Kong和Yan[4]提出了判别恶意软件距离的指标,评估两个恶意软件程序的属性函数调用图之间的相似性。Arp等人[18]提出实现一个基于支持向量机(SVM)的设备上的识别模型,考虑到网络访问、API调用、权限等。Wang等人[19]使用SVM、随机森林和决策树评估了风险权限对恶意软件识别的作用。Wang等人[20]专注于通过使用线性SVM、逻辑回归、随机森林和决策树对静态分析的特征进行检测恶意应用程序。Fan等人[21]提出利用敏感子图构建五个特征,然后送入几个机器学习算法,如决策树、随机森林、KNN和PART,以二进制方式检测安卓恶意软件搭售的应用程序。Yerima和Sezer[22]提议训练和融合多级分类器,形成最终的强分类器。
- 最近,一些方法在通过DL技术准确识别恶意软件实例方面又迈出了一步。Pascanu等人[5]提出使用回声状态网络和递归神经网络,以更好地从执行的指令、稳健和时间域中提取特征,从而更好地识别恶意软件攻击。Huang和Stokes[6]在二进制恶意软件分类任务上提出了一种新型的多任务DL架构用于恶意软件分类。Ni等人[23]将分解的恶意软件特征转化为灰色图像,并使用卷积神经网络(CNN)来识别恶意软件家族。Vasan等人[24]提出应用组装和微调的CNN架构来捕捉更多基于恶意软件实例图像表示的语义和丰富特征。尽管取得了进展,
然而,传统的恶意软件识别系统通常是在一个封闭的场景下进行的,只能处理已知的恶意软件家族,而缺乏同时处理新型未知恶意软件家族的能力。最近,随着越来越多的新型恶意软件家族被不断发布,在现实世界的应用中迫切需要一个开放的恶意软件识别系统。在这篇文章中,我们着重于正式研究开放集场景下的恶意软件识别问题。
B. 图像开放集识别
开放集识别最早是在计算机视觉领域对图像进行研究的[8],其中的方法大致可以分为三大类,包括基于CML的方法、基于DL的方法和基于极值理论(EVT)的方法。
- 一些早期的工作主要是用几种CML算法实现的,如SVM、最近的邻居、稀疏表示(SR)等。One-versus-set机器[8]和W-SVM[25]应用SVM来实现Openset检测。前者提出从具有线性核的单类或二元SVM的边际距离来雕刻决策空间,后者将SVM与统计EVT的有用特性相结合来校准分类器。SSVM[26]提出要平衡经验风险和未知数的风险,这确保了未知类的有限风险。OSNN[27]将最近的邻居分类器扩展到了一个开放的场景,完全纳入了识别属于训练期间未知类别的样本的能力。随后提出了一种基于广义OSR的分类算法[28],利用广义帕累托极值分布进行开放集图像识别。
- 最近,随着DL技术的快速发展,一些作品采用深度神经网络(DNN)来实现识别模型。其中,OpenMax[10]是通过使用DNN来估计输入来自未知类别的概率的先驱之一。后来,一些基于DL的方法也将开放集识别与GANs相结合。例如,G-OpenMax[11]通过用GANs从已知类数据中生成未知图像样本来扩展OpenMax的训练集。与G-OpenMax稍有不同的是,Neal等人[12]提议生成与训练集接近但不属于任何训练类的图像样本来进行增强。OLTR[13]考虑了长尾分布和开放分布,并提出在这样的性质下实现开放集识别,这使得该模型能够在一个综合算法中处理不平衡分类、少数人学习和开放集识别。
- 此外, 基于EVT的方法是源于统计学的一个特殊类别, 可以处理统计极值的建模问题[29]. 其中,EVM[30]是最具代表性的方法,它解决了其他开放集识别方法之间的差距,其中大多数方法几乎没有考虑到数据的分布信息,并且缺乏强大的理论基础。由于在计算机视觉领域的成功,现有的图像开放集识别模型在理论上可以通过调整恶意软件的特征来模仿图像特征,转移到开放集场景下的恶意软件识别。
然而,与计算机视觉领域相比,各种恶意软件实例特征的差异远远小于图像,这也可能导致对新的未知恶意软件家族的识别概率过高,无法与已知家族区分开。
C. 基于GANs的恶意软件识别模型
近年来,随着GANs的日益普及,它涉及到两个神经网络在零和游戏框架下的相互竞争,一些恶意软件研究者也遵循这一框架来实现他们的恶意软件识别系统。
- 例如,tGAN[31]提出用自动编码器结构对GAN进行预训练,根据少量的恶意软件数据合成恶意软件实例,增加训练量。此外,分类器也从训练好的GANs的判别器中转移出来,以充分利用GANs的特性。
- tDCGAN[32]遵循这样的自动编码器预训练框架,并将tGAN[31]扩展到深度卷积GANs,以更好地生成和检测恶意软件实例。
- 不同的是,Lu和Li[33]应用深度卷积GANs,没有预训练过程,以合成恶意软件实例并增加训练量。一个ResNet-18被进一步训练为恶意软件识别的分类器。
- 最近,Chen等人[34]提出使用GANs为小型恶意软件家族合成安卓恶意软件实例,并缓解了实例不平衡的恶意软件识别问题。
我们的方法也是用GANs合成恶意软件实例来实现识别系统,同时与现有的基于GANs的恶意软件识别模型有三个方面的不同,包括。
- 1)与大多数专注于增加已知家族的训练数据的方法不同,我们选择合成接近已知家族而不属于任何家族的边缘恶意软件实例来模仿未知家族,因此,我们可以通过特定的正则器抑制分类器对未知家族的敏感性。
- 2)我们的合成过程在合成目标方面更加保守,没有对未知家族做出强烈的假设或先验;
- 3)我们的方法侧重于正式研究MOSR系统,该系统可以通过单一的矫正分类器处理已知和未知的恶意软件家族,其中合成网络主要作为补充。
提出方法
在本节中,我们首先给出MOSR的正式问题定义。接下来,我们将详细介绍我们提出的方法和配方。更具体地说,如图3所示,基于GANs的合成器被训练来合成几个边缘的恶意软件实例,以模仿新的未知恶意软件家族并支持分类器的训练。分类器的条件是降低和拉平未知家族的识别概率,相对提高已知家族的识别概率,以纠正分类和检测的性能。综合网络和分类网络被联合优化,以交替地改善彼此。
A.问题定义:一个可以同时对已知类和未知类进行分类的分类器
B.方法
- 分类器:应该指出的是,(3)的(ii)和(iii)项之间似乎有冲突,因为前者将平面识别概率规范化为均匀分布,而后者则将少数概率规范化为最小。然而,在我们的方法中,第(ii)项主要作为一个全局条件进行优化,以使分类器不将合成的恶意软件实例归入任何已知的家庭。而条款(iii)作为一个局部条件,例如在局部小批处理期间,要进行优化,以使分类器确切地将这些实例排除在几个特定的已知家族之外。这两个术语共同发挥作用,使分类器对检测新的未知恶意软件家族更加敏感。
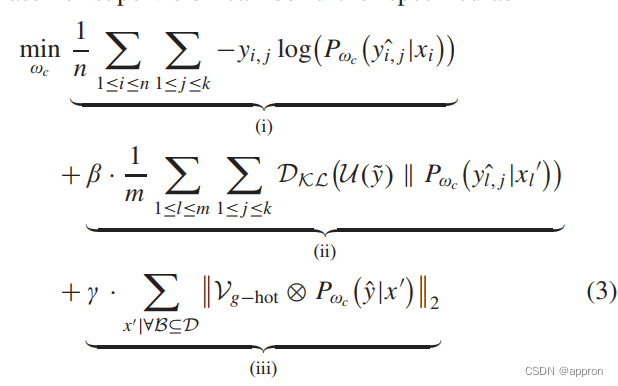
2.合成网络。与几个生成模型不同的是,在传统的分类问题中,合成模拟实例以增加数据,或在零/少量学习问题中合成未见过的类的实例[36],[37],前者只需要在已知的类上进行合成,后者可以提供一些未知类的辅助信息(例如,可见和未见过的类共享的语义描述),合成新型未知恶意软件系列的条件相对有限。首先,没有未知恶意软件家族的额外辅助信息,这使得合成过程没有监督。其次,合成的新型未知恶意软件家族应该与已知的不同,但同时又不能太不同。从理论上讲,任何与已知家族分布不同的实例都可以被视为来自新型未知家族。因此,一个直接的规则是,从与已知分布不同的实例中取样。然而,这条规则并不实用,因为我们不可能对实例特征空间中的每一个不同的分布进行采样。进一步受到SVM的支持向量[38],[39]的启发,边缘实例通常具有更好的辨别特性,我们可以有一个更保守的策略,合成几个边缘的恶意软件实例,接近已知的家庭,而不属于任何家庭,作为模仿的新的未知恶意软件家庭。受GANs[40]的启发,涉及到两个神经网络在零和游戏框架中相互竞争,以实现数据生成的能力,而不明确地对概率密度进行建模。我们还应用GANs框架来合成新的未知家族的边缘恶意软件实例。在GANs网络中,生成器G被用来从先验分布(如高斯N)中抽取潜变量z作为输入,并生成输出G(z)。同时,一个判别器D被训练来区分输入x是否来自目标数据分布,方法是将x映射到[0,1]的概率范围。生成器的目的是在冻结D时尽可能准确地合成模拟实例。
我们提出的方法中包括两个主要部分。1)分类网络,旨在为已知的恶意软件家族产生准确的概率分布,为未知的恶意软件家族产生平坦和低的概率分布;2)新奇性合成网络,旨在合成已知家族的边缘恶意软件实例。一方面,训练有素的分类网络可以帮助迫使新奇性合成网络将恶意软件实例从与已知家族的相似性合成为不同,因此,可以调整天真的GANs属性。另一方面,训练有素的新奇性合成网络也可以支持分类网络的训练,合成的恶意软件实例可以模仿新的未知恶意软件家族。因此,这两个组件可以相互补充,提高整体性能。为了利用这些特性并促进训练,我们构建了一个合作训练方案,将系统目标统一为
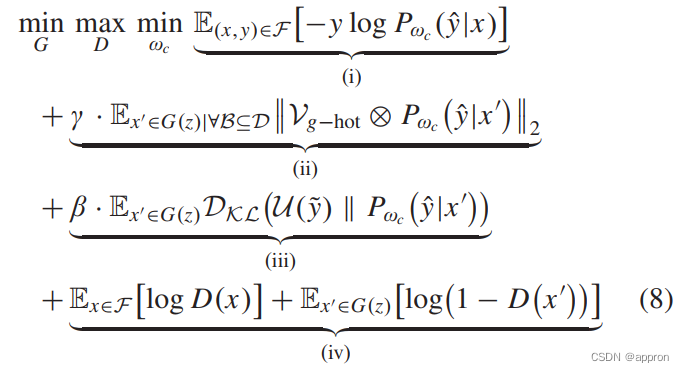
其中,术语(i)-(iii)构成分类网络的监督,术语(iii)和(iv)构成新颖性综合网络的监督。术语(ii)和(iii)是分类网络和综合网络共同使用的整顿规范器。为了合作优化(8),我们构建了一个备用的更新算法。具体来说,我们维护一个参数集{ωd, ωg, ωc},该参数集对应于分类器网络和新异性合成网络的判别器D和生成器G。与GANs的训练过程类似,我们依次更新每个参数,同时冻结其他两个参数。详细的训练过程在算法1中展示。

3.检测方法

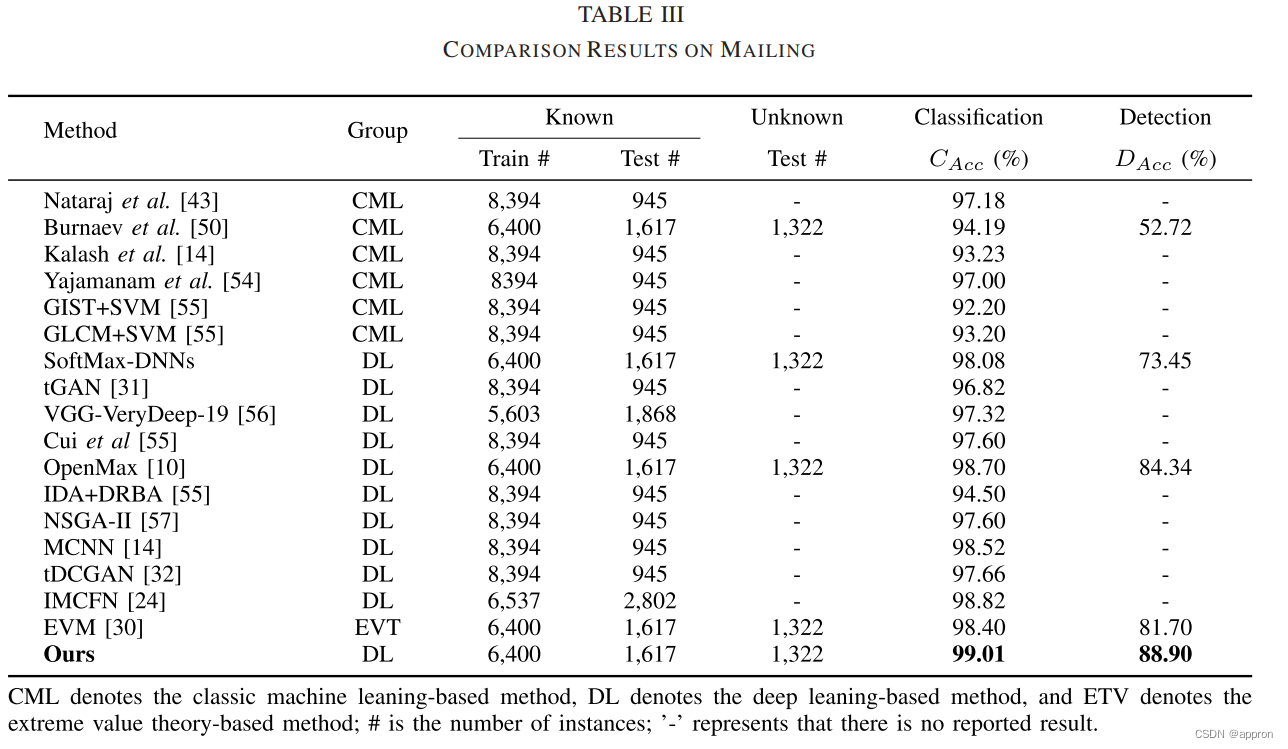
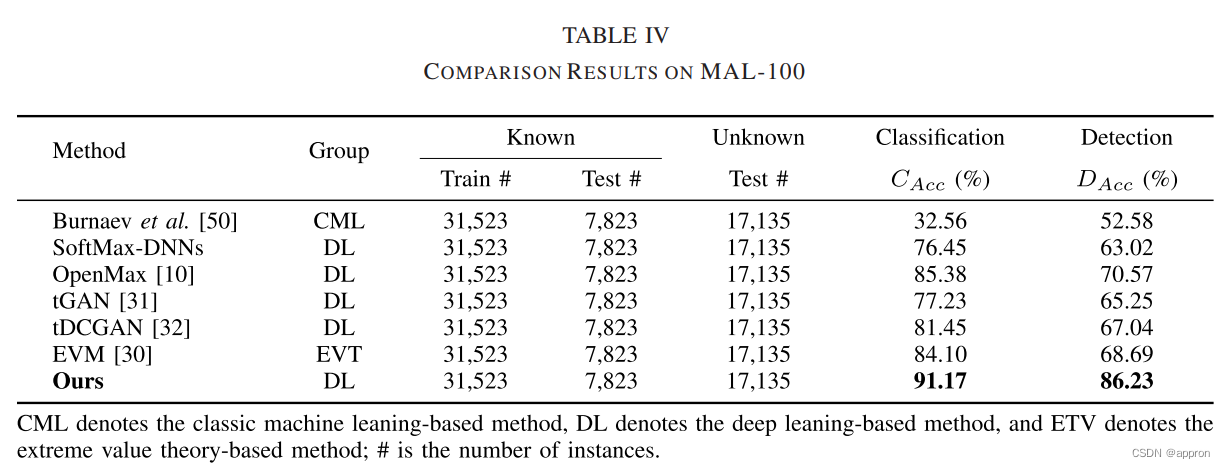
实验结果
















 3500
3500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









