






按照博客进行模型的微调,遇到的bug记录。
【1】执行
python train_qlora.py --train_args_file train_args/sft/qlora/chatglm3-6b-sft-qlora.json
报错:
libcublas.so.11: undefined symbol: cublasLtGetStatusString, version libcublasLt.so.11
解决方法,详见:这里
中间重新安装pytorch都不行,上面写的 pip uninstall nvidia_cublas_cu11 可以work。
【2】个人使用设备双卡T4,每个卡16G,2张卡32G,qlora方法微调chatglm3-6b。
执行
python train_qlora.py --train_args_file train_args/sft/qlora/chatglm3-6b-sft-qlora.json
之后,跑起来之后OOM,报错如下:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.98 GiB (GPU 0; 14.76 GiB total capacity; 13.16 GiB already allocated; 315.75 MiB free; 13.72 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
但实际上第2张卡显存空间还剩很多:
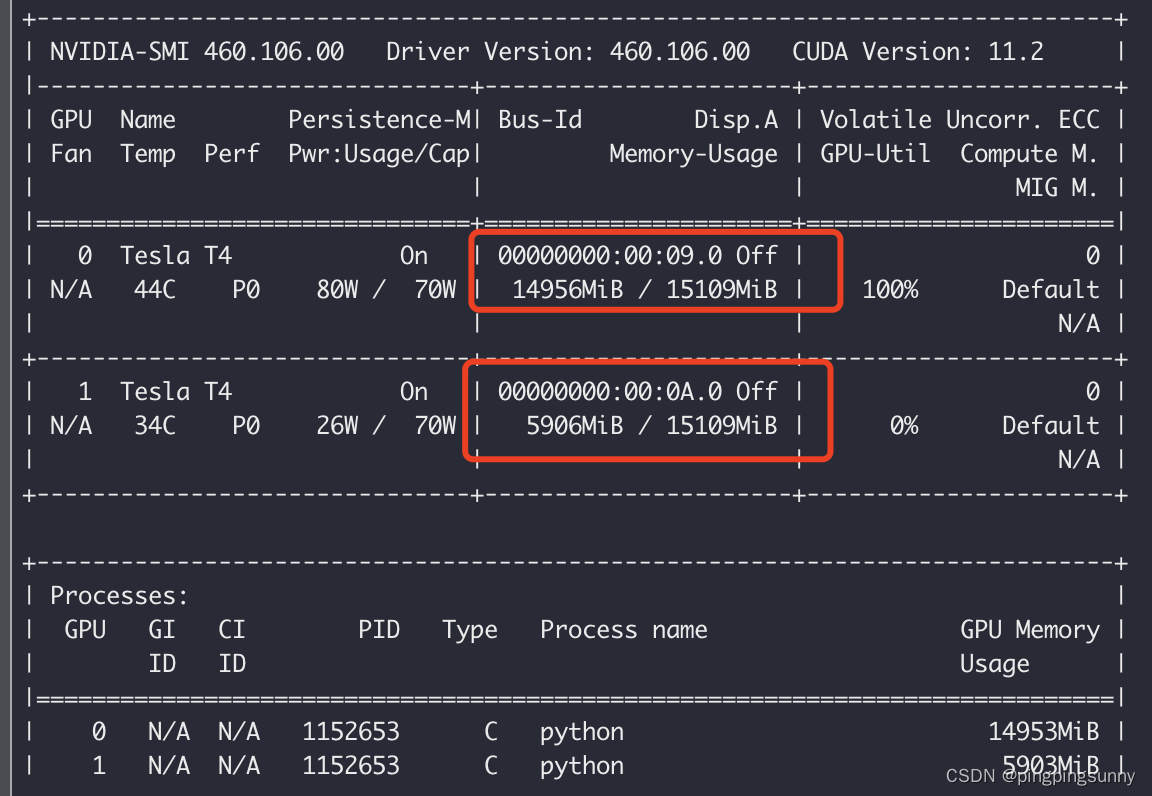
解决方法:查了一些资料,在stackoverflow上看到有人训练别的模型说还是batchsize设置的大了,可以减小一下试试。当我将batch_size=1时,发现OK了。
其他的诸如
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:xxx"
都不work。按道理来说应该当第一张卡不足,使用第二张卡上,但目前不知道原因为什么没弄好,有经验的朋友可以不吝赐教。
补充:
可以使用命令:
torchrun --nproc_per_node=2 train_qlora.py --train_args_file train_args/sft/qlora/chatglm3-6b-sft-qlora.json
这里通过设置--nproc_per_node=2来指定训练的显卡数。global batch = per_device_train_batch_size * gradient_accumulation_steps * num_gpus。
这样时间能减少一半。
【3】使用lora方法微调后合并的模型推理时报错:
AttributeError: can't set attribute 'eos_token'
解决方法:将原来模型的tokenizer_config.json移动到微调模型的下面,详细见GitHub的issue
【4】大模型训练好之后的效果(中文场景)跟哪些因素有关
这一部分还没做实验,但参考北大做的ChatLaw模型(由几个模型的组合,算个解决方案或者系统):参考简介里的说明
a. 大模型本身的文本能力,所以一定选个基座就比较好的,我们做微调的,尤其是训练数据不够,训练机器不行的,一定要选个好的基座;
b. 数据质量:多清洗,多增强,要求严格,少量的精品胜过大量的普通数据;
c. 大参数:一般来说33B好于13B,以此类推;
d. 实际落地:真正能解决业务上的问题,可能单靠一个大模型是不够的,需要配合,知识库是必须的,配合做知识库的模型,比如相似度,embedding模型等都要搞好,这对于落地很重要!
【5】chatGLM预测的时候报错:
错误内容如下:
Input length of input_ids is 8487, but `max_length` is set to 8192. This can lead to unexpected behavior. You should consider increasing `max_new_tokens`
其实就是load模型的时候指定最大长度是8192,但是在实际使用时,输入的数据的长度多于8192,此时有2个方法解决问题:
方法一:缩减输入数据的长度;
方法二:扩大模型能接受的长度(要确保显存能装的下,可接受的输入数据越长,需要的显存越大),一方面在config.json文件中将"seq_length": 8192改长一些,另一方面,在预测时,将model.chat(tokenizer, query, history, max_length=xxxx)设置max_length。
但这个方法也会有一些问题,当长度比较长的时候,感觉后面预测的效果就不太好了,可能也跟训练的数据长度跟预测的数据长度差异较大有关系。

















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









