







目录
一.显存碎片化与CUDA OOM解决
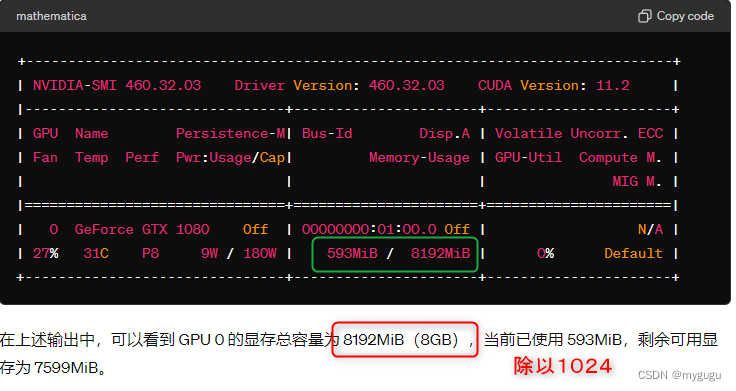
1.查看显卡内存容量
2.显存碎片化
有时候遇到cuda OOM问题,可以通过限制显存分配减轻碎片化
(1)如何理解显存中“已分配”和“未分配”的内存块?
已分配的内存块:
定义:已分配的内存块是指显存中已经被程序占用的内存区域。这些区域被用来存储数据、模型参数、纹理等,供 GPU 使用。
用途:这些内存块包含了当前正在使用的数据,例如
目录
有时候遇到cuda OOM问题,可以通过限制显存分配减轻碎片化
已分配的内存块:
定义:已分配的内存块是指显存中已经被程序占用的内存区域。这些区域被用来存储数据、模型参数、纹理等,供 GPU 使用。
用途:这些内存块包含了当前正在使用的数据,例如

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 88
88





