







 本文深入探讨机器学习中的神经网络表示与学习方法,包括神经网络的表示、非线性假设、模型结构、代价函数、BP反向传播算法及其在自动驾驶、图像处理等领域的应用。重点介绍了神经网络如何模拟逻辑函数、解决复杂函数拟合问题,以及通过BP算法优化参数,实现高效的学习过程。
本文深入探讨机器学习中的神经网络表示与学习方法,包括神经网络的表示、非线性假设、模型结构、代价函数、BP反向传播算法及其在自动驾驶、图像处理等领域的应用。重点介绍了神经网络如何模拟逻辑函数、解决复杂函数拟合问题,以及通过BP算法优化参数,实现高效的学习过程。
http://blog.csdn.net/pipisorry/article/details/44119187
机器学习Machine Learning - Andrew NG courses学习笔记
Machine Learning - VIII. Neural Networks Representation神经网络的表示 (Week 4)
Machine Learning - IX. Neural Networks Learning神经网络 (Week 5)
lz神经网络主要内容已融合到博客[神经网络 ]
神经网络的表示
非线性假设
房子分类问题:假设你有房子的一些不同的features,想预测房子卖出的可能性。
feature很多的情况下就会产生相当多的features,如果加上所有的二次quadratic项。
linear\logistic regression的缺陷: Including all the quadratic features doesn't seem like it's maybe a good idea, because that is a lot of features and you might up overfitting the training set, and it can also be computationally expensive.

计算机视觉的一个例子:训练car识别模型
To understand why computer vision is hard let's zoom into a small part of the image like that area where the little red rectangle is.
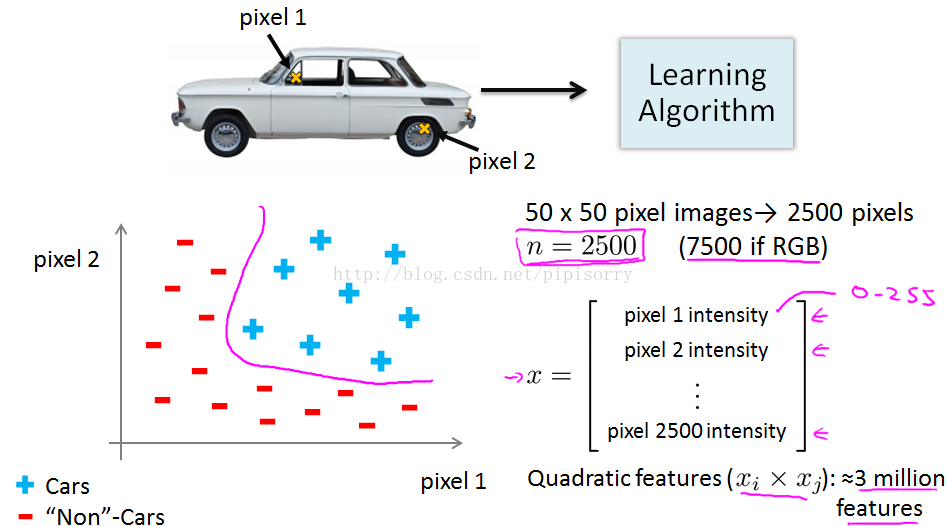
非线性假设带来的features太多而导致computational expensive。
模型表示
人工神经网络的简单模型artificial neural network simple model
模型: model a neuron as just a logistic unit.
输入输出: the neuron gets the number of inputs, x1, x2,x3 and it outputs some value computed like so.
node0 :an extra node x0 is sometimes called the bias unit but because x0 = 1.I won't draw with it just depending on whether there's more the rotationally convenient for that example.
单个和多个神经元的神经网络表示
。。。神经网络表示的计算

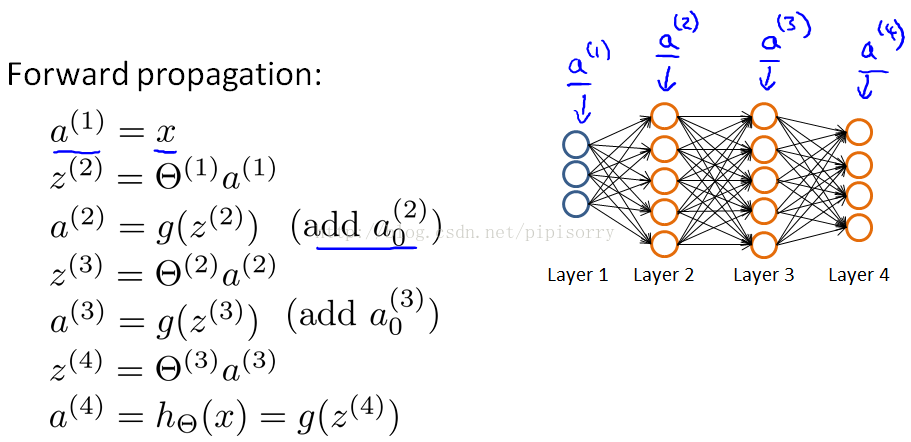
正向传播的向量化表示forward propagation
{前向传播求解每一层的a(l)的公式(绿框),the process of computing h(x)}
computing the activations from the input then the hidden then the output layer

神经网络的代价函数Cost Function(多类分类)
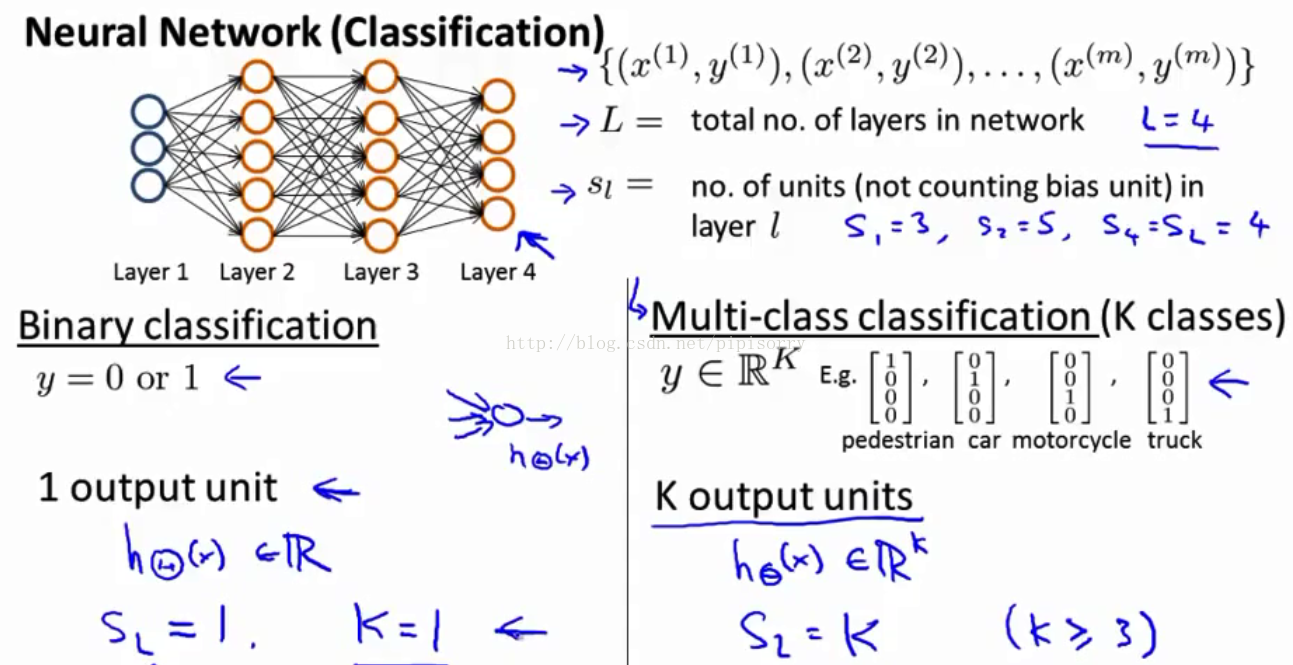
Note: 对于multi-class classfication,要求K>=3,两类分类就没必要使用向量表示了。
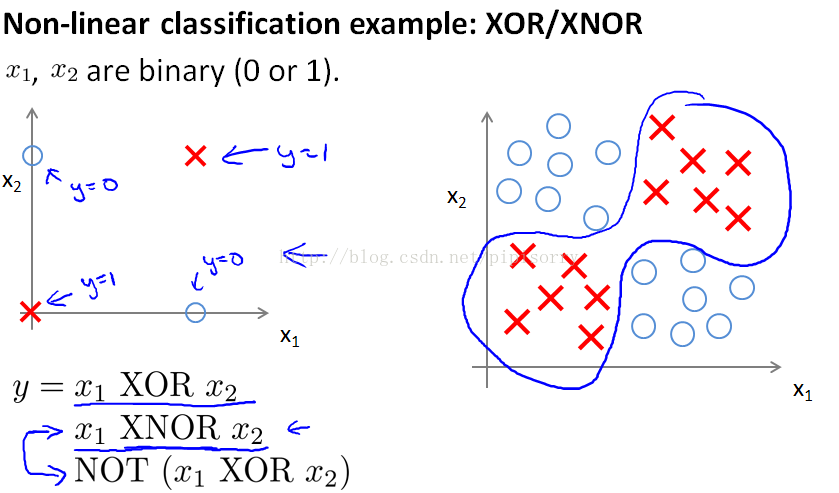
示例和直觉知识Examples and Intuitions
神经网络拟合复杂函数的直觉
{a detailed example, showing how a neural network can compute a complex nonlinear function of the input and be used to learn complex, nonlinear hypotheses.}
y的表达式: a little bit better if we use the XNOR example, instead.
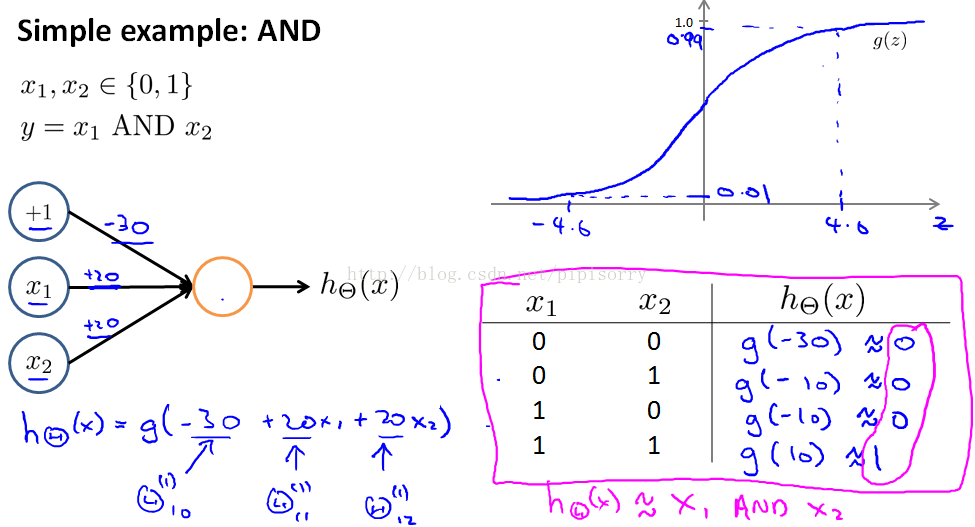
拟合AND函数的网络示例
神经网络是如何模拟逻辑函数的,并且这个逻辑函数是什么。
get a one unit network to compute this logical AND function:
OR函数的网络

Negation("not x1" function)否定网络
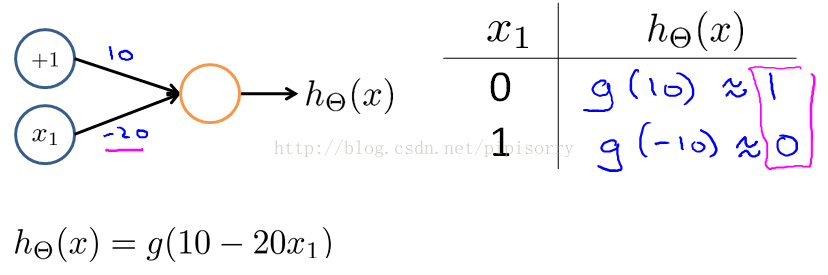
总结:神经网络中的单个神经元single neurons可以用于计算像AND and OR这样的logical functions。
通过融合得到同或函数XNOR
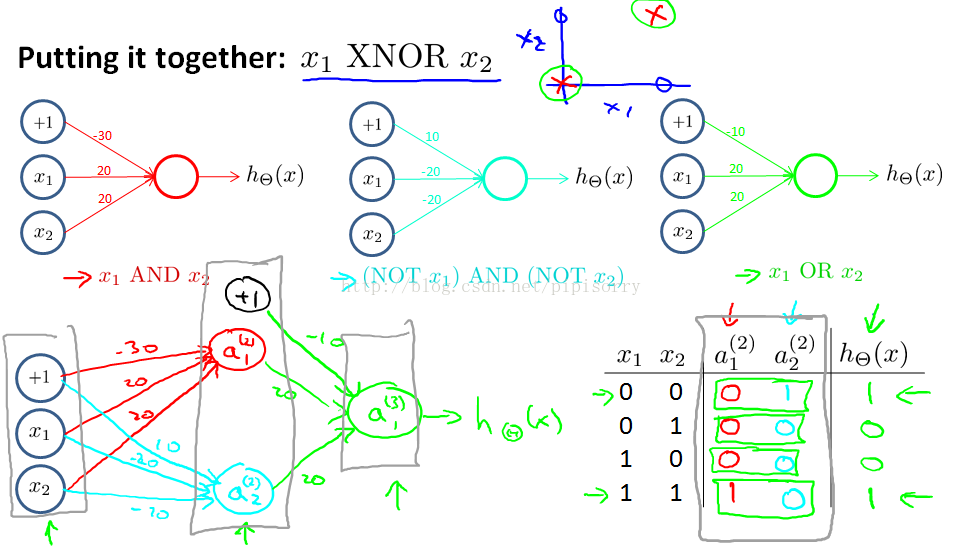
层数越靠后越能学出更复杂的网络。when you have multiple layers,you have relatively simple function of the inputs, and the second layer,but the third layer can build on that to compute even more complex functions and then the layer after that can compute even more complex functions.
Multiclass Classification多类分类
多类分类: The way we do multiclass classification in a neural network is essentially an extension of the one versus all method.

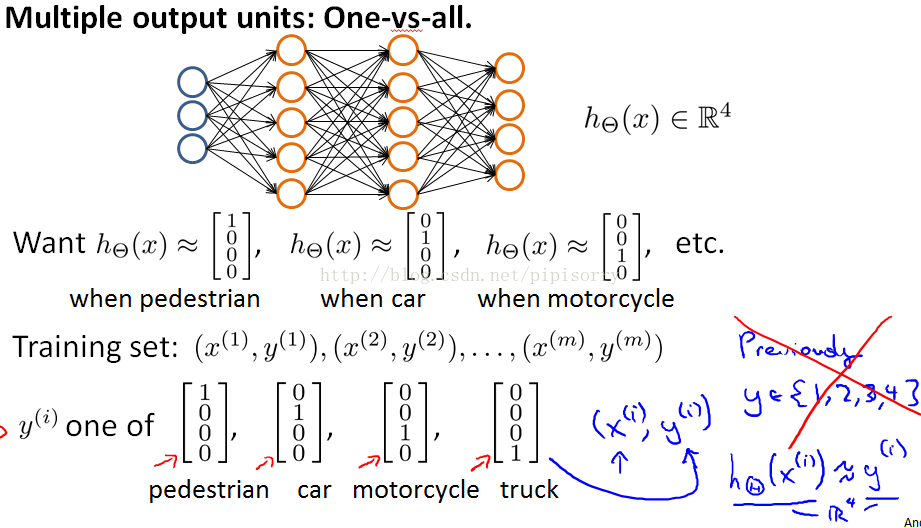
Note: yi不是数字1、2、3、4,而是向量。并且注意,prediction得到的h(xi)是一个概率向量(对应图中最后一层的圆圈),也就是y(i) = [0.04 0.01 0.04 0.99],可以通过[x, ix] = max(h(xi)), y_predict = ix得到数字0 - 9。
Neural Networks Learning 神经网络学习
BP反向传播算法 Back Propagation Algorithm
通过最小化cost fun来求参数θ

In order to use either gradient descent or one of the advance optimization algorithms,主要难点就在于偏导项partial derivative terms,我们使用bp算法来计算导数derivatives.
给定一个训练样本时

Note:
1. this delta term is in some sense going to capture our error in the activation of that neural duo.
2. ignore authorization then the partial derivative terms you want are exactly given by the activations and these delta terms.
给定训练集时

Note:
1 j=0对应的是偏差项bias term,所以忽略了不需要的额外规格化项extra regularization term。
2 BP中求解delta的更高级方法advanced factorization methods where you don't have a four-loop over the m-training examples.
至于δ项为何如此计算并且为何就是J的偏导就没有推导了:these deltas are going to be used as accumulators that will slowly add things in order to compute these partial derivatives. the formal proof of D terms is pretty complicated what you can show is that once you've computed these D terms, that is exactly the partial derivative of the cost function with respect to each of your perimeters and so you can use those in either gradient descent or in one of the advanced authorization.
反向传播Intuition
Back propagation may be unfortunately is a less mathematically clean or less mathematically simple algorithm.
简化:这里只关注单个样本xi,yi,且只关注一个输出单元的情况(yi为一个实数,K=2),并且我们忽略规格化项(λ=0)。

反向传播中δ就是J的偏导(所以可以通过δ更新参数θ)
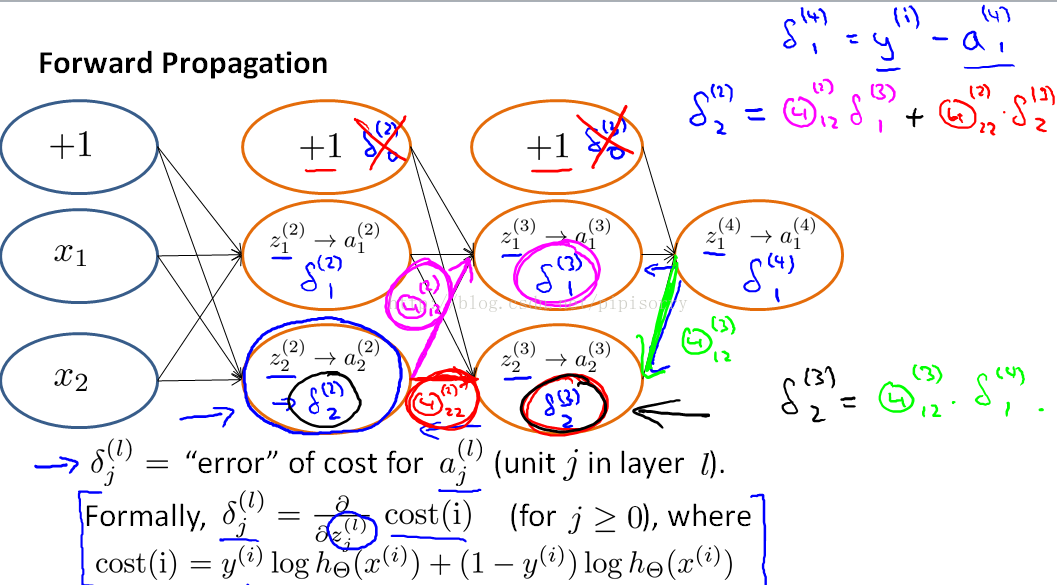
神经网络参数学习示例
{unrolling your parameters(输入的θ不能是矩阵,只能是长向量) from matrices into vectors, which we need in order to use the advanced optimization routines.}
Advanced optimization来求解参数时的用法时的限制

一个例子(矩阵和向量的相互转换)

Note:
1 thetaVec : take all the elements of your three theta matrices,and unroll them and put all the elements into a big long vector.并且thetaVec是一个列向量。
2 reshape: go back from the vector representations to the matrix representations.
3 两种形式各自的优势:
parameters are stored as matrices it's more convenient when you're doing forward propagation and back propagation and it's easier when your parameters are stored as matrices to take advantage of the, sort of, vectorized implementations.
Whereas in contrast the advantage of the vector representation, when you have like thetaVec or DVec is that when you are using the advanced optimization algorithms.
Advanced optimization来求解神经网络参数

神经网络要注意的问题
随机初始化Random Initialization
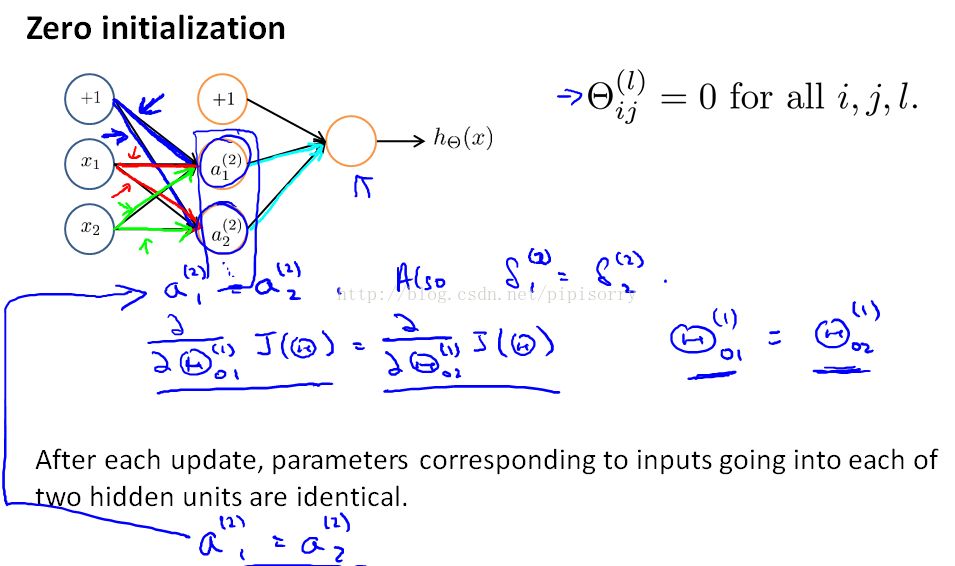
随机初始化

神经网络训练总结Putting It Together
选择神经网络结构
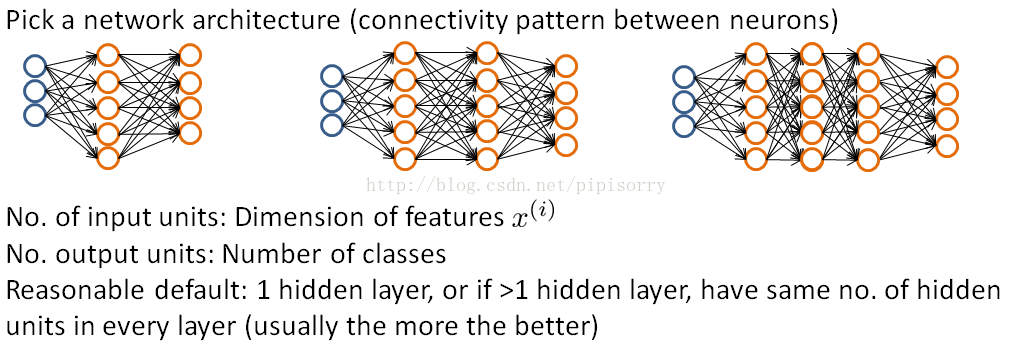
hidden units的数目应该是可比的:也就是与x的维度,features的数目,或者比input features大一点(或者几倍)。Usually the number of hidden units in each layer will be maybe comparable to the dimension of x, comparable to the number of features, or it could be any where from same number of hidden units of input features to maybe so that three or four times of that.You know, several times, or some what bigger than the number of input features is often a useful thing to do.
训练神经网络6步


神经网络的应用
Autonomous Driving自动驾驶
车看到的视图the view seen by the car of what's in front of it
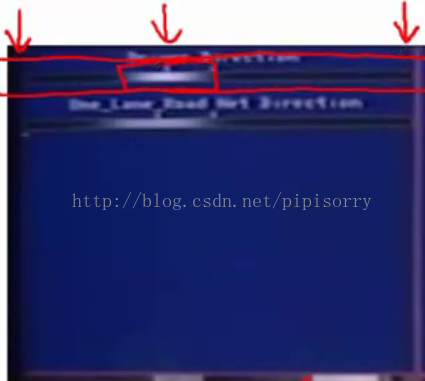
first horizontal bar shows the direction selected by the human driver
the location of this bright white band that shows the steering direction selected by the human driver, where,far to the left corresponds to steering hard left;here corresponds to steering hard to the right; and so this location, which is a little bit left of center, means that the human driver, at this point, was steering slightly to the left.
second part here corresponds to the steering direction selected by the learning algorithm;
But before the neural network starts learning initially, you see that the network outputs a grey band, like a grey uniform, grey band throughout this region, so the uniform grey fuzz corresponds to the neural network having been randomly initialized, and initially having no idea what direction to steer in:

Reviews复习
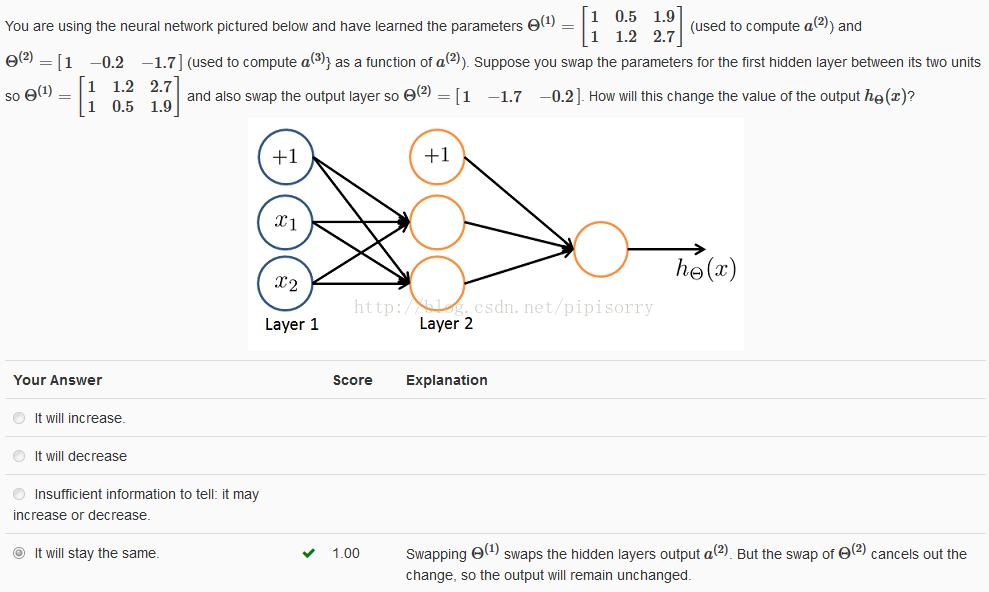

Exercise:(手写字识别)
Note:
1 载入数据时注意:The .mat format means that that the data has been saved in a native Octave/Matlab matrix format, instead of a text (ASCII) format like a csv- le. These matrices can be read directly into your program by using the load command. After loading, matrices of the correct dimensions and values will appear in your program's memory. The matrix will already be named, so you do not need to assign names to them.
% Load saved matrices from file
load('ex3data1.mat');
% The matrices X and y will now be in your Octave environment
% Load the weights into variables Theta1 and Theta2
load('ex3weights.mat');
2 training examples: There are 5000 training examples in ex3data1.mat, where each training example is a 20 pixel by 20 pixel grayscale image of the digit.
X gives us a 5000 by 400 matrix X where every row is a training example for a handwritten digit image.
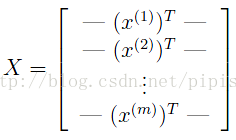
Y The second part of the training set is a 5000-dimensional vector y that contains labels(0-9) for the training set.(a \0" digit is labeled as \10")
3 predect code:
1)vectorized
X = [ones(m, 1) X];
a2 = sigmoid(X*Theta1');
a2 = [ones(m, 1) a2];
a3 = sigmoid(a2*Theta2');
[r,c] = (max(a3,[],2));
p = c;
2)non-vectorized
for i = 1:m
a1 = [1 X(i, :)]';
z2 = Theta1 * a1;
a2 = [1; sigmoid(z2)];
z3 = Theta2 * a2;
a3 = sigmoid(z3);
[r,c] = max(a3);
p(i) = c;
end
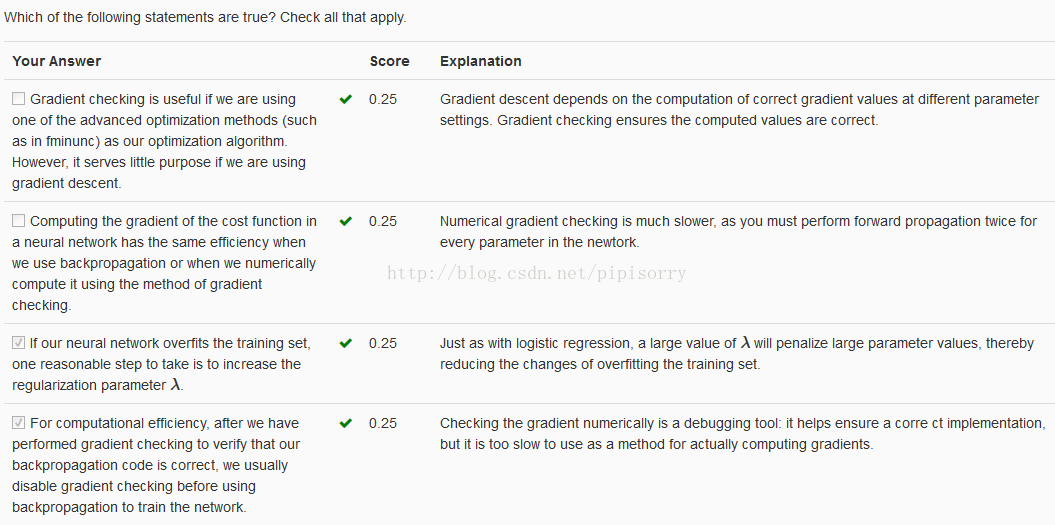
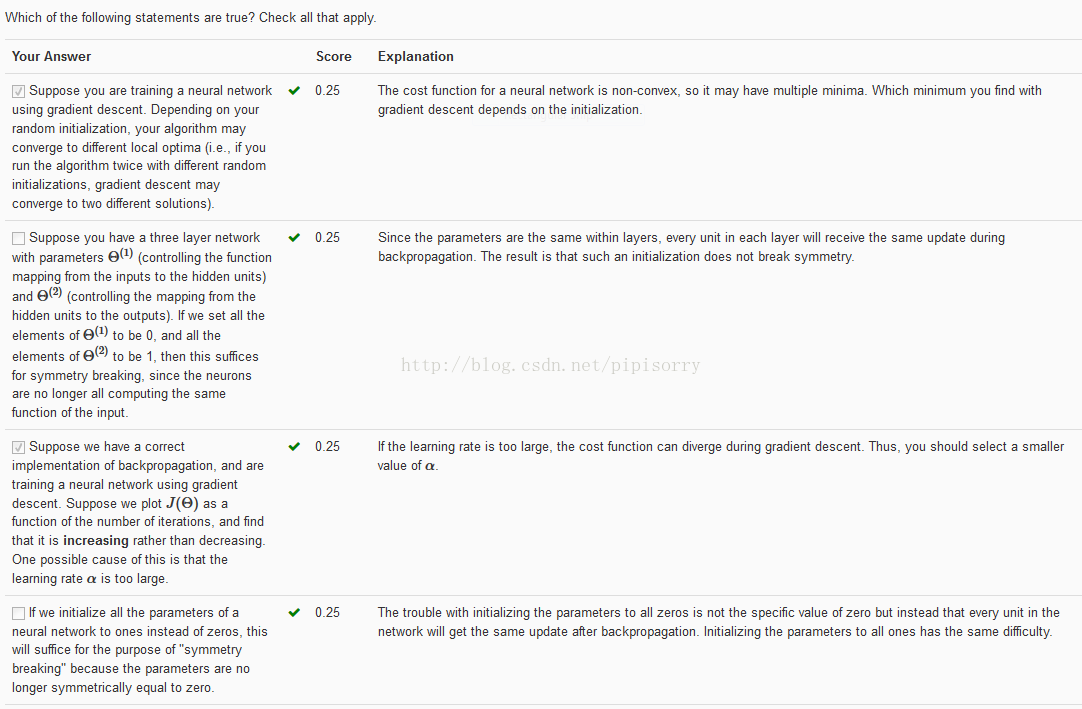
from:http://blog.csdn.net/pipisorry/article/details/44119187
ref:

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









