




 本文探讨了词嵌入的概念及应用,包括One-hot编码、低维embedding的实现方法及其在TensorFlow中的应用。此外还介绍了词嵌入的多种方法如word2vec,并讨论了句子embedding的不同方式。
本文探讨了词嵌入的概念及应用,包括One-hot编码、低维embedding的实现方法及其在TensorFlow中的应用。此外还介绍了词嵌入的多种方法如word2vec,并讨论了句子embedding的不同方式。
http://blog.csdn.net/pipisorry/article/details/76095118
词嵌入
词嵌入其实就是将数据的原始表示表示成模型可处理的或者是更dense的低维表示(lz)。
One-hot Embedding
假设一共有 个物体,每个物体有自己唯一的id,那么从物体的集合到
个物体,每个物体有自己唯一的id,那么从物体的集合到 有一个trivial的嵌入,就是把它映射到中的标准基,这种嵌入叫做One-hot embedding/encoding.
有一个trivial的嵌入,就是把它映射到中的标准基,这种嵌入叫做One-hot embedding/encoding.
[数据预处理:独热编码(One-Hot Encoding)]
一般使用的低维embedding
应用中一般将物体嵌入到一个低维空间
 ,只需要再compose上一个从到的线性映射就好了。每一个
,只需要再compose上一个从到的线性映射就好了。每一个 的矩阵
的矩阵 都定义了到的一个线性映射:
都定义了到的一个线性映射:  。当
。当 是一个标准基向量的时候,
是一个标准基向量的时候,对应矩阵
中的一列,这就是对应id的向量表示。
这个概念用神经网络图来表示如下:
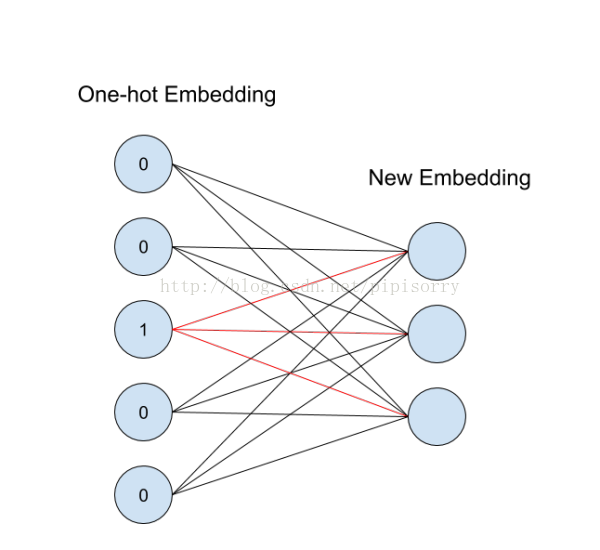
从id(索引)找到对应的One-hot encoding,然后红色的weight就直接对应了输出节点的值(注意这里没有activation function),也就是对应的embedding向量。
Note:
1 M随机初始化并且是可训练的,查找x对应的embedding表示其实 等价于 找x在下面这个网络中的权重,而这些权重是可训练的,且对应于矩阵M。
2 关于嵌入维度数量(New Embedding维度)的一般经验法则:
embedding_dimensions = number_of_categories**0.25
也就是说,嵌入矢量维数应该是类别数量的 4 次方根。如词汇量为 81,建议维数为 3。
低维向量嵌入在tensorflow中的实现:tf.nn.embedding_lookup()
embedding_map = tf.get_variable( # 默认参数trainable = True,可训练
name="embedding_map",
shape=[self.config.vocab_size, self.config.embedding_size],
initializer=self.initializer)
seq_embeddings = tf.nn.embedding_lookup(embedding_map, self.input_seqs)和下面类似:
matrix = np.random.random([1024, 64]) # 64-dimensional embeddings
ids = np.array([0, 5, 17, 33])
print matrix[ids] # prints a matrix of shape [4, 64] 从id类特征(category类)使用embedding_lookup的角度来讲:
1、onehot编码神经网络处理不来。embedding_lookup虽然是随机化地映射成向量,看起来信息量相同,但其实却更加超平面可分。
2、embedding_lookup不是简单的查表,id对应的向量是可以训练的(带有label信息),训练参数个数应该是 category num*embedding size,也就是说lookup是一种全连接层。详见 brain of mat kelcey
3、word embedding其实是有了一个距离的定义,即出现在同一上下文的词的词向量距离应该小,这样生成向量比较容易理解。autoencode、pca等做一组基变换,也是假设原始特征值越接近越相似。但id值的embedding应该是没有距离可以定义,没有物理意义,只是一种特殊的全连接层。
4、用embedding_lookup做id类特征embedding由google的deep&wide提出。阿里 第七章 人工智能,7.6 DNN在搜索场景中的应用(作者:仁重) 中提下了面对的困难,主要是参数数量过多(引入紫色编码层)和要使用针对稀疏编码特别优化过的全连接层( Sparse Inner Product Layer )等。
5、在分类模型中用这种id类特征,主要是希望模型把这个商品记住。但id类特征维度太高,同一个商品的数据量也不大,因此也常常用i2i算法产出的item embedding来替代id特征。
[求通俗讲解下tensorflow的embedding_lookup接口的意思?]
[what-does-tf-nn-embedding-lookup-function-do]
词嵌入有其它很多方法如word2vec,bert等,embedding lookup只是其中一种。我们可以只使用简单的embedding lookup让模型自己去训练;也可以将embedding lookup中的矩阵先通过word2vec训练好进行初始化,再通过embedding lookup训练;或者只使用vord2vec进行初始化后,embedding lookup设置成不训练。
Word2vec
其它的Word Representation


Word level representation from characters embeddings Bidirectional LSTM on top of word representation to extract contextual representation of each word
右图中的context应该是指句子的上下文。
[Sequence Tagging with Tensorflow]
句子embedding
1 词向量直接求平均或者最大值:对句子中所有单词直接求平均, 每个单词的权重相同, 得到sentence embedding。
2 使用每个词的TF-IDF值为权重, 加权平均, 得到sentence embedding。
3 sif sentence embedding使用预训练好的词向量, 使用加权平均的方法, 对句子中所有词对应的词向量进行计算, 得到整个句子的embedding向量:模型的输入是一个已有的word embedding,然后通过加权求平均的方法求得sentence的embedding,最后使用主成分分析去掉一些special direction,即在完成词加权平均之后,移除所有行为向量的公共主成分:v_s -= u*u^t*v_s。
其中v_s表示加权平均之后的结果,u表示所有句子向量进行特征分解之后,最大特征值对应的特征向量,相当于所有句子向量的最大主成分,这样就把所有行为链路中彼此相关的一部分去除,只保留反应序列特性的成分。
[论文阅读 A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SEN- TENCE EMBEDDINGS]
[A simple but tough-to-beat baseline for sentence embedding]
词向量维度的选择
On the Dimensionality of Word Embedding
词向量集合的距离度量:PIP loss,基于此可以选择最优词向量维度
文章分析了LSA, Word2vec, Glove对于不同任务的最优维度

[On the Dimensionality of Word Embedding]
from: http://blog.csdn.net/pipisorry/article/details/76095118
ref: [tensorflow对嵌入概念的解释]
[深度学习、NLP 和表示法(Chris Olah 的博客)]
[TensorFlow Embedding Projector]

















 1491
1491










 到【灌水乐园】发言
到【灌水乐园】发言







