







Dataset的几种生成方式
Note: 很多方法构建的Dataset也会有OutOfRange的异常出现,需要恰当地进行捕捉并处理,否则直接报错:OutOfRangeError End of sequence。如果是使用tf.train.MonitoredTrainingSession这种session,会通过while not mon_sess.should_stop()自动捕捉。
Dataset.from_generator
Dataset.from_generator可以使用普通编程语言编写的外部子函数生成Dataset,这样几乎不受tensorflow编程不便的影响。[Tensorflow Dataset.from_generator使用]
读入的seq长度无法确定,所以shapes = (([None], ()), [None])。
如果固定会出错:ValueError: `generator` yielded an element of shape (15,) where an element of shape (200,) was expected.
Dataset.from_tensor_slices
dataset = Dataset.from_tensor_slices((df_features.values, df_labels.values)) [使用 tf.data 加载 pandas dataframes]
from_tensor_slices读取后的数据类型跟随df的数据类型。
shape的信息
<TensorSliceDataset shapes: ((133,), (1,)), types: (tf.float32, tf.float32)>
示例:读取dataframe中的数据
user_features = df.loc[:, cols_dict['user_dense_cols'] + cols_dict['user_sparse_cols']]
goods_features = df.loc[:, cols_dict['goods_dense_cols'] + cols_dict['goods_sparse_cols']]
labels = df.loc[:, cols_dict['label_cols']]
dataset = Dataset.from_tensor_slices((user_features.values, goods_features.values, labels.values))
tf.decode_csv
tf.io.decode_csv(records, record_defaults, field_delim=',', use_quote_delim=True, name=None, na_value='', select_cols=None)
参数use_quote_delim ,看原始代码的解释为:use_quote_delim: An optional bool. Defaults to True. If false, treats double quotation marks as regular characters inside of the string fields (ignoring RFC 4180, Section 2, Bullet 5). 默认设置为True,会把双引号当成引用,在使用tf.decode_csv读取文件的时候如果某一行有双引号会报错,如果设置为False会把双引号当做为一个普通的字符串变量。
调用出错:InvalidArgumentError: Unquoted fields cannot have quotes/CRLFs inside
[[Node: DecodeCSV = DecodeCSV[OUT_TYPE=[DT_STRING, DT_INT32], field_delim="\t", na_value="", use_quote_delim=true,
sentences, labels = tf.decode_csv(values, [[''], [1]], field_delim=field_delim) 。。。
其中CRLF是Carriage-Return Line-Feed的缩写,意思是回车换行,就是回车(CR, ASCII 13, \r) 换行(LF, ASCII 10, \n)。
解决:use_quote_delim=False或者数据中去除"。
[tf.decode_csv() error: “Unquoted fields cannot have quotes/CRLFs inside]
dataset数据操作
dataset.shuffle.repeat.batch三个函数式解释
dataset = dataset.shuffle(self.shuffer_buffer).repeat(self.epochs)
dataset.shuffle作用是将数据进行打乱操作,传入参数为buffer_size,改参数为设置“打乱缓存区大小”,也就是说程序会维持一个buffer_size大小的缓存,每次都会随机在这个缓存区抽取一定数量的数据。buffer_size设定多少参考下:考虑性能的话用 10 * batch_size 。太小的话,就跟顺序取差不多,起不到 shuffle 的作用。太大的话,貌似也没有啥影响。[数据集shuffle方法中buffer_size的理解]
dataset.repeat作用就是将数据重复使用多少epoch
dataset.batch作用是将数据打包成batch_size
先看结果:
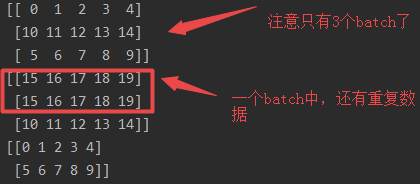
解释:相当于把所有数据先打乱,再把所有数据重复两个epoch,然后将重复两个epoch的数据放在一起,最后打包成batch_size输出
特点:1.因为把数据复制两份,还进行打乱,因此某个batch数据可能会重复,而且出现重复数据的batch只会是两个batch交叉的位置;2.最后一个batch的尺寸小于等于batch_size
不同的顺序也是有区别的:[tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解],链接也可以看下dataset迭代输出的格式。
dataset.padded_batch
需要pad齐数据时使用,一般文本处理时。
padded_batch(
batch_size,
padded_shapes,
padding_values=None,
drop_remainder=False
) 其中参数drop_remainder: (Optional.) A tf.bool scalar tf.Tensor, representing whether the last batch should be dropped in the case it has fewer than batch_size elements; the default behavior is not to drop the smaller batch. 只有这个参数为True时,输出的batch_size维度显示的才是batch_size而不是?。因为这个参数为False,所有最后一个batch_size可能<参数batch_size,即显示成?。一般不需要看batch_size时,这个就默认为False不要动。debug时还是可以设成True看看的,比如看后面tensor的shape变化。
函数仍返回dataset。
dataset.prefetch
tf.data API 通过 tf.data.Dataset.prefetch 转换提供了一种软件流水线机制,该机制可用于将生成数据的时间和使用数据的时间分离开。具体而言,该转换使用后台线程和内部缓冲区,以便在请求元素之前从输入数据集中预取这些元素。因此,为了实现上图所示的流水线效果,您可以将 prefetch(1) 作为最终转换添加到数据集流水线中(如果单步训练使用 n 个元素,则添加 prefetch(n))。
Note: batch().prefetch(1),通过print(dataset)可以看出是以batch为单位取的。Like other Dataset methods, prefetch operates on the elements of the input dataset. It has no concept of examples vs. batches. examples.prefetch(2) will prefetch two elements (2 examples), while examples.batch(20).prefetch(2) will prefetch 2 elements (2 batches, of 20 examples each).[https://www.tensorflow.org/api_docs/python/tf/data/Dataset#prefetch]
一个问题
输出的shape为(batch_size,?)不能直接输入到dense layer中,否则报错:flatten dense ValueError: The last dimension of the inputs to `Dense` should be defined. Found `None`.
这是因为经过rnn后直接使用了所有hidden的flatten,而不是最后一个或者平均。即如果要使用经过rnn后直接使用了所有hidden的flatten,上面代码中padded_batch输入的shape中的seq_len需要直接设置成固定值max_seq_len200,而不是None,但是这样可以会截断长seq。要注意的是dnn本身的输入维度需要是固定的,不可能变长。
[tf.data.Dataset]
数据输入主参考[数据输入流水线性能]
take操作
take(count)
Creates a Dataset with at most count elements from this dataset.
按特定值过滤tf.data.Dataset
示例:过滤掉user_feature、goods_feature、label向量中有任何NAN的行。
def filter_nan(line):
return tf.logical_not(tf.logical_or(
tf.logical_or(tf.reduce_any(tf.is_nan(line['user_feature'])),
tf.reduce_any(tf.is_nan(line['goods_feature']))),
tf.reduce_any(tf.is_nan(line['label'])))
)
dataset = dataset.filter(filter_nan)
Note:
1 这里是通过tf.data.TFRecordDataset读取的数据,其中line['user_feature']都是k维的tensor。
2 过滤全0的尝试改用reduce_all。reduce_any的用法和numpy的any类似[numpy教程:逻辑函数Logic functions]。
3 filter_nan = lambda x, y: not tf.reduce_any(tf.math.is_nan(x)) and not tf.math.is_nan(y) 使用这种方式的应该是executor模式,不需要跑session run,构图一次run一次。
[Tensorflow how to check if a tensor row is only zeroes?]
[Filter NaN values in Tensorflow dataset]
[python - 如何按特定值过滤tf.data.Dataset?]
迭代dataset
Dataset 是数据集,Iterator 是对应的数据集迭代器。
tf.data.Iterator(iterator_resource, initializer, output_types, output_shapes, output_classes)
如果 Dataset 是一个水池的话,那么它其中的数据就好比是水池中的水,Iterator 你可以把它当成是一根水管。在 Tensorflow 的程序代码中,正是通过 Iterator 这根水管,才可以源源不断地从 Dataset 中取出数据。但为了应付多变的环境,水管也需要变化,Iterator 也有许多种类。
单次 Iterator
make_one_shot_iterator()
这个方法会返回一个 Iterator 对象,调用 iterator 的 get_next() 就可以轻松地取出数据了。
示例
import tensorflow as tf
dataset = tf.data.Dataset.range(5)
iterator = dataset.make_one_shot_iterator()
with tf.Session() as sess:
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break

可以定制的水管,可初始化的 Iterator
跟单次 Iterator 的代码只有 2 处不同。
1、创建的方式不同,iterator.make_initialnizer()。
2、每次重新初始化的时候,都要调用sess.run(iterator.initializer)
你可以这样理解,Dataset 这个水池连续装了 2 次水,每次水量不一样,但可初始化的 Iterator 很好地处理了这件事情,但需要注意的是,这个时候 Iterator 还是面对同一个 Dataset。
示例
def initialable_test():
numbers = tf.placeholder(tf.int64,shape=[])
dataset = tf.data.Dataset.range(numbers)
# iterator = dataset.make_one_shot_iterator()
iterator = dataset.make_initializable_iterator()
with tf.Session() as sess:
sess.run(iterator.initializer,feed_dict={numbers:5})
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
sess.run(iterator.initializer,feed_dict={numbers:6})
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
make_initializable_iterator和make_one_shot_iterator的区别:假设您想使用相同的代码来进行培训和验证。您可能希望使用相同的迭代器,但已初始化为指向不同的数据集。使用一次性迭代器,您不能像这样重新初始化它。
[在make_initializable_iterator和make_one_shot_iterator之间的tensorflow数据集API差异]
能够接不同水池的水管,可重新初始化的 Iterator
def reinitialable_iterator_test():
training_data = tf.data.Dataset.range(10)
validation_data = tf.data.Dataset.range(5)
iterator = tf.data.Iterator.from_structure(training_data.output_types,
training_data.output_shapes)
train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data)
next_element = iterator.get_next()
with tf.Session() as sess:
for _ in range(3):
sess.run(train_op)
for _ in range(3):
print(sess.run(next_element))
print('===========')
sess.run(validation_op)
for _ in range(2):
print(sess.run(next_element))
print('===========')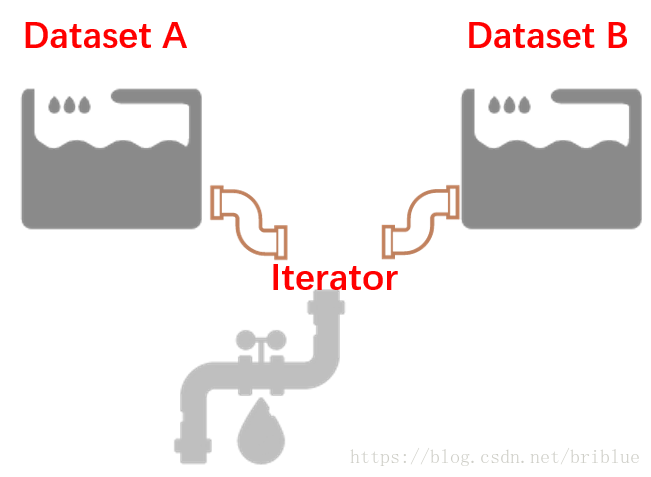
其它更复杂的iterator参考[【Tensorflow】Dataset 中的 Iterator]
[TensorFlow数据读取方式:Dataset API,以及如何查看dataset:DatasetV1Adapter的方法]
查看dataset信息
假设读取
dataset = Dataset.from_tensor_slices((df_features.values, df_labels.values))
则直接print(dataset)显示含shape的信息
<TensorSliceDataset shapes: ((133,), (1,)), types: (tf.float32, tf.float32)>
dataset = dataset.shuffle(self.shuffer_buffer).repeat(self.epochs)
<RepeatDataset shapes: ((133,), (1,)), types: (tf.float32, tf.float32)>
dataset = dataset.batch(self.batch_size).prefetch(1)
<PrefetchDataset shapes: ((?, 133), (?, 1)), types: (tf.float32, tf.float32)>
dataset = dataset.batch(self.batch_size, drop_remainder=args.drop_remainder).prefetch(1)
<PrefetchDataset shapes: ((32, 133), (32, 1)), types: (tf.float32, tf.float32)>
Dataset获取数据集大小:未尝试
[tf.data.Dataset:如何获取数据集大小(一个元素的元素数量)?]
示例
示例1:文本数据读取和处理
DEBUG = True
mlb = MultiLabelBinarizer()
with open(os.path.join(DATADIR, 'vocab.tags.txt'), 'r', encoding='utf-8') as f:
mlb.fit([[l.strip() for l in f.readlines()]])
print('{0}\nmlb.classes_: \n{1}\n{0}'.format('*' * 50, mlb.classes_))
def parse_fn(line_words, line_labels):
# Encode in Bytes for TF
words = [w.encode('utf-8') for w in line_words.strip().split()] # 不转换也会在model_fn前在某个地方自动完成
# labels = [t.encode('utf-8') for t in line_labels.strip().split()]
labels = [t for t in line_labels.strip().split()]
labels = mlb.transform([labels])[0]
# print((words, len(words)), labels)
return (words, len(words)), labels
def generator_fn(words, labels):
with open(words, 'r', encoding='utf-8') as f_words, open(labels, 'r', encoding='utf-8') as f_labels:
for line_words, line_labels in zip(f_words, f_labels):
result = parse_fn(line_words, line_labels)
if result:
yield result
else:
continue
def input_fn(words, labels, params=None, shuffle_and_repeat=False):
params = params if params is not None else {}
if DEBUG:
shapes = (([None], ()), [None])
shapes2 = (([200], ()), [11])
else:
shapes = shapes2 = (([None], ()), [None])
types = ((tf.string, tf.int32), tf.float32)
defaults = (('<pad>', 0), 0.0) # (words, len(words)), MultiLabelBinary
dataset = tf.data.Dataset.from_generator(
functools.partial(generator_fn, words, labels),
output_shapes=shapes, output_types=types)
if shuffle_and_repeat: # only for training
dataset = dataset.shuffle(params['buffer']).repeat(params['epochs'])
if DEBUG:
dataset = dataset.padded_batch(params.get('batch_size', 20), shapes2, defaults, drop_remainder=True).prefetch(1)
else:
dataset = dataset.padded_batch(params.get('batch_size', 20), shapes2, defaults).prefetch(1)
# print(dataset)
return dataset
示例2:
raw_dataset = tf.data.TFRecordDataset(self.input_file_names,buffer_size=args.tfrecord_bufsize)
print("raw_dataset shape:{}\n".format(raw_dataset))
dataset = raw_dataset.map(functools.partial(_parse_function, is_test=args.is_test))
if self.shuffle_and_repeat: # only for training
dataset = dataset.shuffle(self.shuffer_buffer).repeat(self.num_epochs)
dataset = dataset.batch(self.batch_size, drop_remainder=args.drop_remainder).prefetch(1)
self.dataset_iterator = dataset.make_initializable_iterator()
input = self.dataset_iterator.get_next()
self.features = (input['user_feature'], input['goods_feature'])
self.label = input['label']
from: -柚子皮-
ref:

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









