







 本文介绍了循环神经网络RNN,包括词嵌入模型、t-SNE降维、词的类比、RNN结构及反向传播时间、LSTM解决梯度消失问题,以及LSTM的正则化和Beam Search策略。通过对RNN的学习,探讨了深度学习如何处理文本序列问题。
本文介绍了循环神经网络RNN,包括词嵌入模型、t-SNE降维、词的类比、RNN结构及反向传播时间、LSTM解决梯度消失问题,以及LSTM的正则化和Beam Search策略。通过对RNN的学习,探讨了深度学习如何处理文本序列问题。
循环神经网络RNN(Recurrent Network)
深度学习面临的两个问题:
1. 补偿出现的词通常更有代表意义,更有利于分类,例如“视网膜病变”,这类词很少很少出现。
2. 用不同的词表达相同的意思,例如“cat”和“kitty”,词具有模糊语义。
监督学习需要大量带标注的训练数据,现实中带标注数据不多,所以我们考虑非监督学习。
深度学习一个重要的理念是:相似的文本往往出现在相似的环境中
根据在线课程,我们从以下几个方面来了解RNN。
No.1 词嵌入模型
我们想要学习预测一个词的上下文,例如“The CAT purrs”和“This kitty hunts mice”,因为意思相同,所以希望模型对cat和kitty做相同的处理(CNN讲过的共享权重),就要用到词嵌入模型。
词嵌入就是把词映射到较小的向量,当词义相近时,向量距离较小,反之较大。
词嵌入可以很好的解决稀疏性问题。
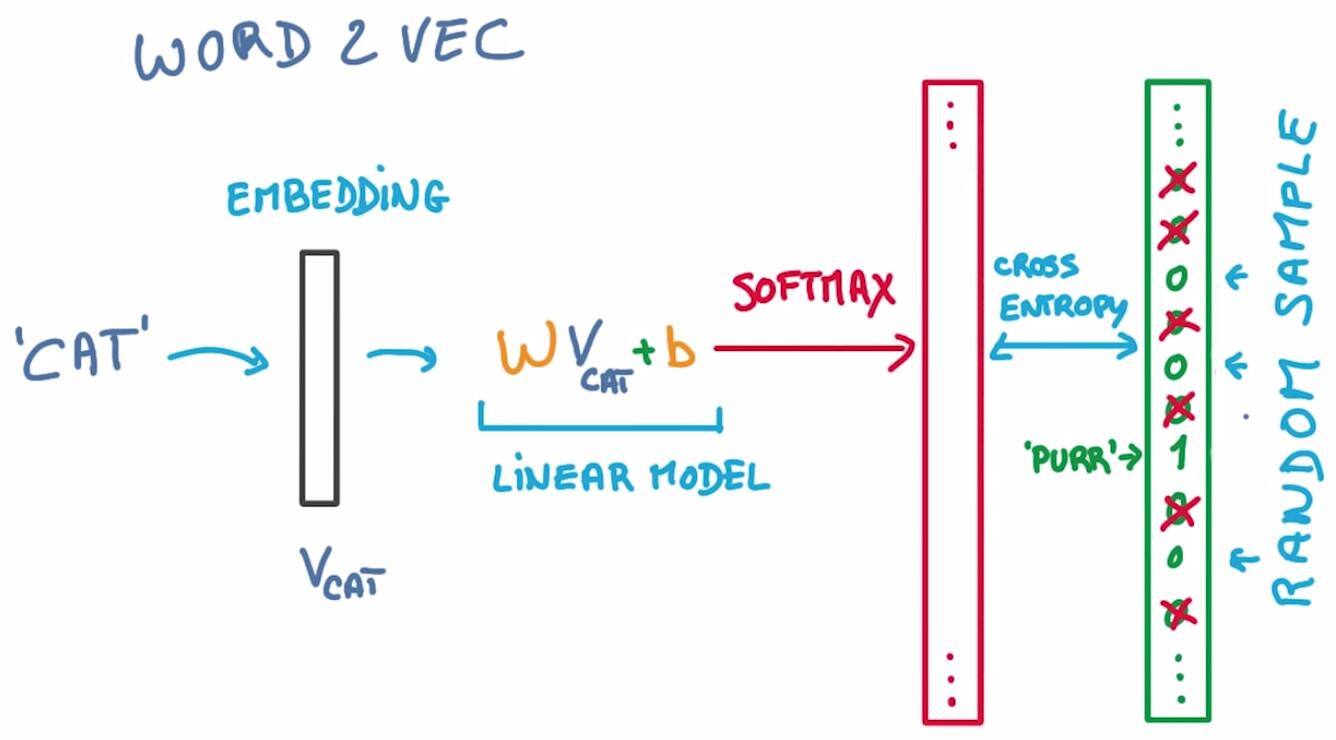
一个比较好的词嵌入模型是word2vec,这里只简单介绍一下,具体对算法的分析移步博客word2vec算法分析
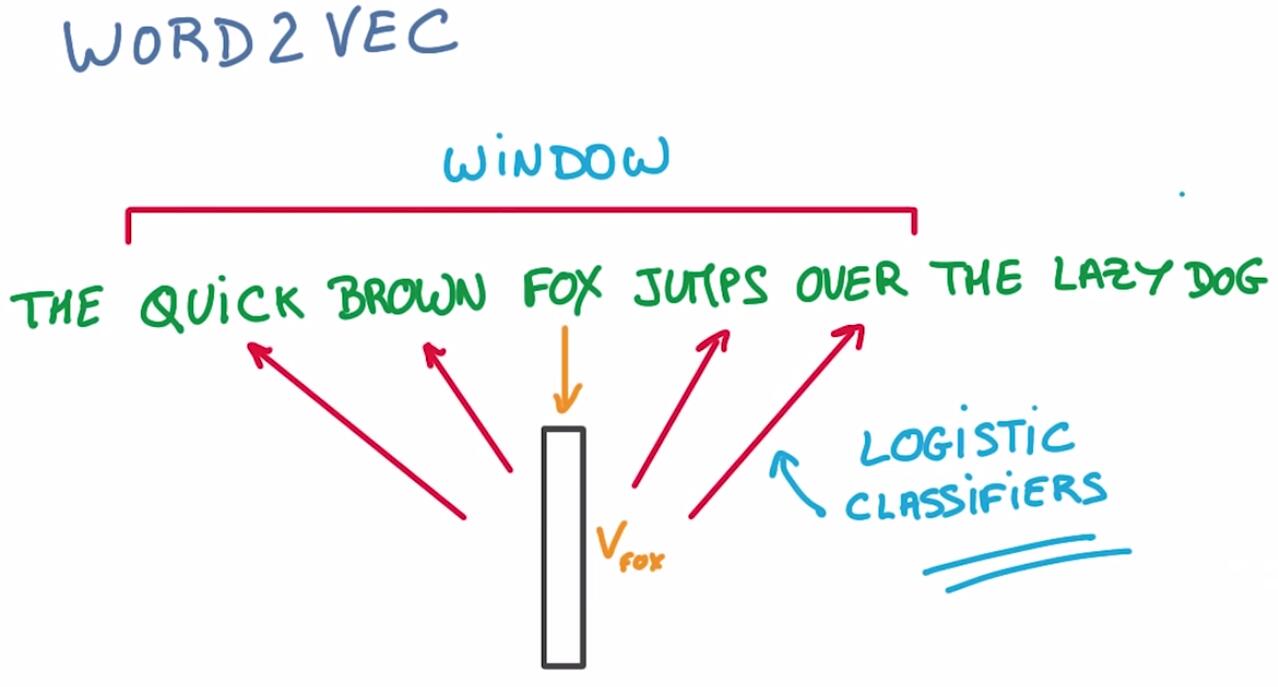
图中例子,想要把词“fox”映射到fox嵌入表示上,然后用此嵌入表示来预测fox的上下文。
用word2vec预测下一个词的时候,非目标词数量非常多(通常是词汇集中的所有词),解决这个问题可以使用Sample Softmax的方法,对非目标词随机采样,既让速度更快,又没有损失性能。
No.2 t-SNE降维
从词嵌入模型得到的词向量使得相似的词可以聚在一起。如何查看呢?
- 一方面可以用词向量计算寻找近邻域的词;
- 另一中方式可以使用降维,将多维词向量降到2维,肉眼客观。
如果使用PCA降维,就会丢失太多信息,尤其是词结构的信息,而t-SNE可以保存邻域结构信息。
t-SNE 是一种非线性、无监督的降维算法,随机邻近嵌入方法。
其他降维方法有:PCA,LDA,MDS,LCE,Isomap,DeepAutoEncoder…
需要注意的一个细节:在衡量相似性的时候,余弦距离比L2效果更好,这是因为词嵌入向量的长度与分类无关,词与词之间的角度决定分类。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4631
4631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









