









摘要:前N推荐任务,目标是找到一些特定Item其被认为对用户最有吸引力。普通的方法基于错误矩阵(例如RMSE)不是很自然的适应对于苹果钱N推荐任务。前N抱歉可以直接由基于进度指标的可选择方法度量。
一个广泛的评估显示算法对于最小RMSE优化不必要作为就前N推荐任务的期待项。结果显示在RMSE的提升经常不能转化到精度提升。事实上,一个朴素的非个性化算法可以比一些普通方法表现好并能匹配复杂算法的精度。另一个发现是很少top流行项会偏离前N表现。分析指出当评估推荐系统基于前N推荐任务是,测试集应该仔细选取为了没有偏差精度指标对于非个性化解。最后我们提供实践者新的两个协同过滤算法的变种,不管他们的RMSE,明显优于其他推荐算法在前N推荐任务中,提供额外实践优点。
1 简介
本文通过精度指标评估一些协同过滤算法在前N推荐任务上的表现。
本文贡献在于1)展示错误指标和精度指标没有复杂的关系,2)提出测试集构造对于非偏差的精度指标,3)引入信息的现存方法的变种提高前N表现
2 测试方法
本文采用的测试方法类似于【6】中描述的。对每个数据集,已知的rating被划分到两个子集:训练集合M和测试集合T。测试集T包含只有5星评价。所以我们能说T包含相关于用户的Item
具体过程来产生M和T从Netfix数据集,Netfix中一个训练节数据集包含100M评分。也提供一个验证集,指的是probe set(探针集),包含1.4M评分。在本工作,训练集M是原始的Netfix的训练集,然而测试集T包含所有5星评分(|T| = 384573)。
我们采用一个相似的过程对于Movielens数据集。随机提取1。4%的评分为了生成探针集。
为了衡量召回率和精度,首先在M中训练模型,然后对于每个item i 由用户u打5分的项从探针集T:
i) 随机选择1000个额外项(u用户没有评分),我们假设大多数对于u来说不感兴趣
ii)我们预测对于item i的评分和对于额外1000项的评分
iii)构成一个排序列表通过排序所有1001 项更具他们的预测评分。p表示测试item i的rank值。 最好结果是测试项i比所有随机选择项要好(也就是p = 1)
iv)构成前N推荐列表通过选取前N个排序项。当
p≤N
we have a hit (也就是测试项i 被推荐给用户)。否则have a miss。当N = 1001 总是have a hit。
对任何单个测试案例,我们有单个相关项(测试项i)。通过定义,对于单个测试的召回率可以假设0或1。相似的精度可以假设为0或者1/N值。所有的召回率和精度通过所有测试案例的平均值求得:
|T|为测试评分的个数。假设所有1000随机项是对u是不相关,趋于较低的召回率和精度。
2.1 流形项vs长尾分布
根据已知的打分项应用到许多商业系统的长尾分布,大多数评分聚集到一小部分最流形项中。
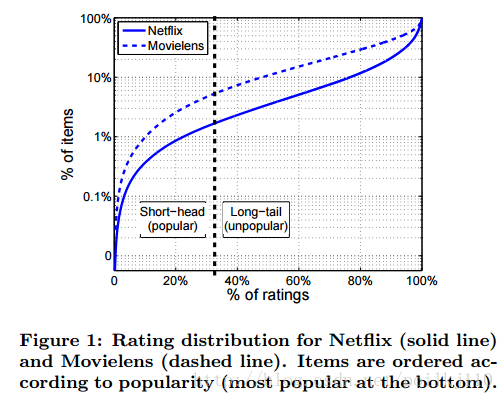
上述图中显示了经验打分分布关于Netfix和Movielens数据集。在垂直轴的项根据其流行度排序,在顶端最流行。我们观察到大约33%的收集到的打分只包含1.7%的最流行项(302项)。我们指这种流形项的小集合为short-head, 对于98%的剩余不流形items。
推荐流行Item是trivial,不会对用户和内容提供者带来好处。推荐很少知道的item增加新颖性和惊喜,但也更加困难。测试集T被划分到两个子集 Thead,Tlong ,在 Thead 中的item是在short-head中, Tlong 项是在长尾分布中。
3 协同算法
大多数推荐系统基于协同过滤(CF),依赖于过去用户行为(这里指的是打分,尽管一些行为包含其他例如购买,点击行为)。对于CF有两个主要的方法:1)近邻方法和2)隐藏因子方法
近邻方法基于用户或者item之间的相似度。隐藏因子方法建模用户和item作为向量在相同的隐藏因子空间。在此空间用户和item通过两相关隐藏因子向量的相似度(内积)来预测rating。
3.1 非个性化模型
非个性化推荐对任何用户呈现一个预定义,固定列表大items, 不管他偏好。这些算法对于更复杂个性化算法作为基线。
一个简单估计法则,Movie Average,推荐具有最高平均评分的前N项。用户u对item i的评分通过在item i所在的社区的平均rating表达。一个相似预测机制表示为Top popular(Top-pop) 推荐前N想具有最高流行度。
3.2 近邻模型
近邻模型基于在相似的用户或item的预测。以用户-用户相似度为中心的算法预测评分,通过一个用户基于由相似用户表达的评分关于此item。 另一方面,以item-item 相似度为中心的算法计算用户对item的偏好基于他在相似item上的评分。后者是经常用的方法,在RMSE项上表现好,更具拓展性。有点在于item的个数比用户的数量要小???另一个item-item优点是推理到特定用户可以解释为就由user之前评分的item。对于以上原因,我们关注在item-item近邻算法。
item i 和item j之间相似度衡量为user对item i 和j 评分的趋势。基于cosine ,调整后的cosine或者Pearson correlation coefficient.
nij
表示普通rates的个数,
sij
表示item i和item j之间相似度,定义一个收缩的相似度
dij=nijnij+λ1sij
λ1
为收缩因此。通常设定为100
近邻模型进一步通过KNN方法增强。预测的评分
rui
,只考虑由u评分的k个items ,u是最相似于i的。我们定义最相似item集合
Dk(u;i)
.KNN方法抛弃了不相关item。
biases包括item的影响其代表了具体tiem趋于得到更高的rating。
看着恶心。。。下一篇Performance of Recommender Algorithms
on Top-N Recommendation Tasks















 4774
4774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









