







4 后续训练
我们通过应用多轮后续训练来生成与齐 Llama 3 模型。这些后续训练基于预训练的检查点,并结合人类反馈进行模型对齐(Ouyang 等人,2022;Rafailov 等人,2024)。每轮后续训练都包括监督微调 (SFT),之后是直接偏好优化 (DPO; Rafailov 等人,2024),使用通过人工标注或合成生成的示例进行。我们在第 4.1 节和第 4.2 节分别描述了我们的后续训练建模和数据方法。此外,我们将在第 4.3 节进一步详细介绍定制的数据整理策略,以提高模型的推理能力、编程能力、事实性、多语言支持、工具使用、长上下文以及精确指令遵循等方面。
下载全文PDF(7.4万字):https://www.aisharenet.com/llama-3yigeduoa/
4.1 建模
我们后训练策略的基础是奖励模型和语言模型。我们首先使用人类标注的偏好数据(见第4.1.2节)在预训练检查点之上训练一个奖励模型。然后,我们用监督微调(SFT;见第4.1.3节)微调预训练检查点,并进一步用直接偏好优化(DPO;见第4.1.4节)与检查点对齐。这个过程如图7所示。除非另有说明,否则我们的建模过程适用于Llama 3 405B,为简便起见,我们将Llama 3 405B称为Llama 3。
4.1.1 聊天对话格式
为了调整大型语言模型(LLM)以实现人机交互,我们需要定义一个聊天对话协议,让模型能够理解人类指令并执行对话任务。与前身相比,Llama 3 具有新的功能,例如工具使用(第4.3.5节),这可能需要在单个对话回合中生成多条消息并将它们发送到不同的位置(例如,用户、ipython)。为了支持这一点,我们设计了一种新的多消息聊天协议,该协议使用各种特殊的头部和终止标记。头部标记用于指示对话中每条消息的来源和目标。同样,终止标记也指示何时轮到人类和AI交替发言。
4.1.2 奖励模型
我们训练了一个覆盖不同能力的奖励模型 (RM),并将其构建在预训练检查点之上。训练目标与 Llama 2 相同,但我们移除了损失函数中的边际项,因为我们在数据规模扩大后观察到改进效果减小。与 Llama 2 一样,我们在过滤掉具有相似响应的样本后,使用所有偏好数据进行奖励建模。
除了标准的 (被选择, 被拒绝) 响应偏好对之外,标注还为一些提示创建了第三个“编辑后的响应”,其中从该对中选择的响应会被进一步编辑以改进 (请参见第 4.2.1 节)。因此,每个偏好排序样本具有两个或三个响应,排名明确(编辑版 > 选择版 > 拒绝版)。在训练过程中,我们将提示和多个响应连接成一行,并随机排列响应。这是一种将响应放在单独的行中计算分数的标准场景的近似,但在我们的消融实验中,这种方法提高了训练效率,而不会损失精度。
4.1.3 监督微调
首先使用奖励模型对人类标注提示进行拒绝采样,详细方法将在第4.2节中描述。我们结合这些拒绝采样的数据和其他数据源(包括合成数据),使用标准交叉熵损失对预训练语言模型进行微调,目标是预测目标标记(同时屏蔽提示标记的损失)。有关数据混合的更多详细信息请参见第 4.2 节。尽管许多训练目标都是模型生成的,我们仍将此阶段称为监督微调(SFT;Wei 等人,2022a;Sanh 等人,2022;Wang 等人,2022b)。
我们的最大模型在 8.5K 至 9K 步内以 1e-5 的学习率进行微调。我们发现这些超参数设置适用于不同轮次和数据混合。
4.1.4 直接偏好优化
我们进一步使用直接偏好优化(DPO;Rafailov 等人,2024)训练我们的 SFT 模型,以实现人类偏好对齐。在训练中,我们主要使用上一轮对齐中表现最佳的模型收集到的最新偏好数据批次。结果,我们的训练数据更符合每一轮优化的策略模型分布。我们也探索了策略算法,例如 PPO(Schulman 等人,2017),但发现 DPO 在大规模模型上需要更少的计算量,并且表现更好,尤其是在指令遵循基准测试中,如 IFEval(Zhou 等人,2023)。
对于 Llama 3,我们使用 1e-5 的学习率,并将 β 超参数设置为 0.1。此外,我们还对 DPO 应用了以下算法修改:
在 DPO 损失中屏蔽格式标记: 我们将特殊格式标记(包括第 4.1.1 节中描述的头部和终止标记)从选定的和拒绝的响应中屏蔽掉,以稳定 DPO 训练。我们注意到,这些标记参与损失可能会导致不希望的模型行为,例如尾部重复或突然生成终止标记。我们假设这是由于 DPO 损失的对比性质——在选定和拒绝的响应中都存在共同标记会导致相互冲突的学习目标,因为模型需要同时增加和减少这些标记的可能性。
使用 NLL 损失进行正则化: 我们对选定的序列添加了一个额外的负对数似然(NLL)损失项,其缩放系数为 0.2,类似于 Pang 等人(2024)。这有助于进一步稳定 DPO 训练,通过保持生成所需的格式并防止选定响应的对数概率降低(Pang 等人,2024;Pal 等人,2024)。
4.1.5 模型平均
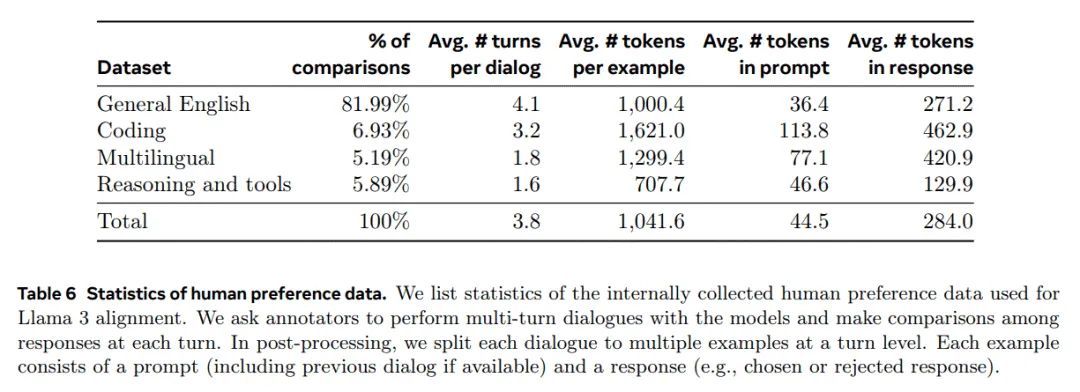
最后,我们在每个 RM、SFT 或 DPO 阶段使用各种数据版本或超参数的实验中获得的模型进行平均(Izmailov 等人,2019;Wortsman 等人,2022;Li 等人,2022)。我们列出了用于 Llama 3 调节的内部收集的人类偏好数据的统计信息。我们请评价者与模型进行多轮对话,并比较每轮的回复。在后处理过程中,我们将每个对话拆分成多个示例,每个示例包含一个提示(包括如果有的话前一次对话)和一个回复(例如,被选择或拒绝的回复)。
4.1.6 迭代轮次
继Llama 2之后,我们应用上述方法进行了六轮迭代。在每个循环中,我们收集新的偏好标注和微调(SFT)数据,并从最新的模型中采样合成数据。
4.2 训练后数据
后训练数据的组成对语言模型的实用性和行为起着至关重要的作用。在本节中,我们将讨论我们的注释程序和偏好数据收集(第 4.2.1 节)、SFT 数据的组成(第 4.2.2 节)以及数据质量控制和清洗的方法(第 4.2.3 节)。
4.2.1 偏好数据
我们的偏好数据标注过程与 Llama 2 相似。在每一轮之后,我们部署多个模型进行标注,并为每个用户提示采样两个来自不同模型的响应。这些模型可以使用不同的数据混合和对齐方案训练,从而具有不同的能力强度(例如,代码专业知识)和增加数据多样性。我们要求标注者根据其偏好程度将偏好评分分类为四个级别之一:显著更好、更好、略好或略微更好。
我们还在偏好排序之后加入了一个编辑步骤,以鼓励标注者进一步改进首选响应。标注者可以直接编辑所选响应,或者用反馈提示模型以细化其自身响应。因此,部分偏好数据具有三个排序的响应(编辑 > 选择 > 拒绝)。
表 6 中报告了我们用于 Llama 3 训练的偏好注释统计数据。通用英语涵盖多个子类别,例如基于知识的问答或精确的指令遵循,这些都超出了特定能力的范围。与 Llama 2 相比,我们观察到提示和响应的平均长度增加了,这表明我们正在更复杂的任务上训练 Llama 3。此外,我们实施了质量分析和人工评估流程来严格评估收集的数据,使我们能够完善提示并为标注者提供系统、可行的反馈。例如,随着 Llama 3 在每一轮后都得到改进,我们将相应地增加提示的复杂性以针对模型落后的领域。
在每一轮后期训练中,我们会使用当时所有可用的偏好数据进行奖励建模,而只使用来自各种能力的最新批次进行 DPO 训练。对于奖励建模和 DPO,我们使用标记为“选择响应显著更好或更好”的样本进行训练,并将具有相似响应的样本丢弃。
4.2.2 SFT 数据
我们的微调数据主要来自于以下来源:
来自我们的人工标注收集中的提示及其拒绝采样响应
针对特定能力的合成数据(详情见第 4.3 节)
少量人工标注的数据(详情见第 4.3 节)
随着我们后训练周期的进行,我们开发出更强大的 Llama 3 变体,并使用这些变体收集更大的数据集,以覆盖广泛的复杂能力范围。在本节中,我们将讨论拒绝采样过程和最终 SFT 数据混合的总体构成的细节。
拒绝采样。在拒绝采样 (RS) 中,对于我们在人工标注期间收集的每个提示(第 4.2.1 节),我们从最新的聊天模型策略中采样 K 个输出(通常是前一个后训练迭代中的最佳执行检查点,或者特定能力的最佳执行检查点)并且使用我们的奖励模型来选择最佳候选者,与 Bai 等人 (2022) 一致。在后训练的后期阶段,我们会引入系统提示来引导 RS 响应符合期望的语气、风格或格式,这对于不同的能力可能会有所不同。
为了提高拒绝采样的效率,我们采用了 PagedAttention(Kwon 等人,2023)。PagedAttention 通过动态键值缓存分配来提高内存效率。它通过根据当前缓存容量动态调度请求来支持任意输出长度。不幸的是,这会带来内存耗尽时的交换风险。为了消除这种交换开销,我们定义了一个最大输出长度,并且只有在有足够的内存可以容纳该长度的输出时才执行请求。PagedAttention 还使我们可以跨所有相应输出共享提示的键值缓存页面。总而言之,这导致拒绝采样过程中的吞吐量提高了 2 倍以上。
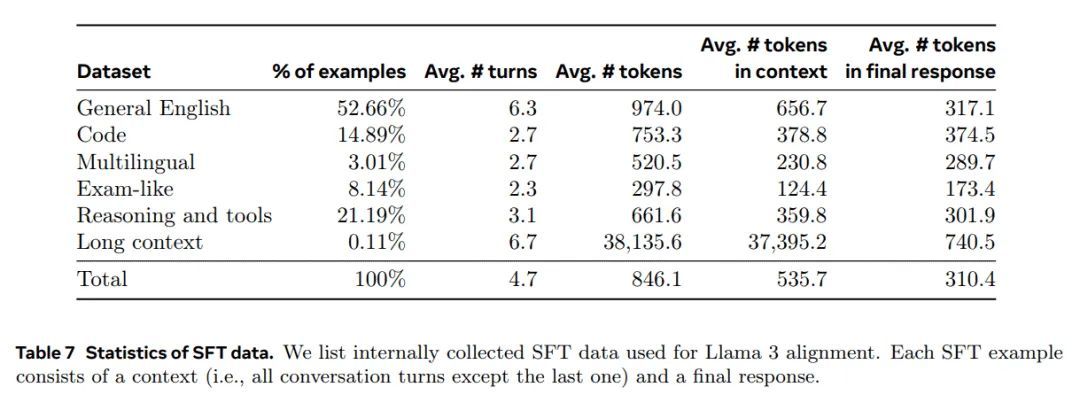
总体数据组成。表 7 显示了我们“有用性”混合每个广泛类别的数据统计信息。虽然 SFT 和偏好数据包含重叠的领域,但它们的策划方式不同,导致不同的计数统计量。在第 4.2.3 节中,我们将描述用于分类我们的数据样本的主题、复杂性和质量的技术。在每一轮后训练中,我们都会仔细调整我们总体的数据混合,以在多个轴上调整性能,以适应广泛的基准测试。我们的最终数据混合会对某些高质量来源进行多次迭代,并将其他来源进行降采样。
4.2.3 数据处理与质量控制
考虑到我们的大部分训练数据都是模型生成的,因此需要仔细清洗和质量控制。
数据清洗: 在早期阶段,我们观察到数据中存在许多不希望出现的模式,例如过量使用表情符号或感叹号。因此,我们实施了一系列基于规则的数据删除和修改策略来过滤或清除有问题的數據。例如,为了减轻过度道歉的语调问题,我们将识别过度使用的短语(例如“对不起”或“我道歉”),并仔细平衡数据集中此类样本的比例。
数据修剪: 我们还应用了一系列基于模型的技术来删除低质量的训练样本并提高整体模型性能:
主题分类: 我们首先将 Llama 3 8B 微调成一个主题分类器,并对所有数据进行推理以将其分类为粗粒度类别(“数学推理”)和细粒度类别(“几何与三角函数”)。
质量评分: 我们使用奖励模型和基于 Llama 的信号来获得每个样本的质量分数。对于基于 RM 的得分,我们将得分处于最高四分位数的数据视为高质量数据。对于基于 Llama 的得分,我们提示 Llama 3 检查点以三个等级(准确性、指令遵循性和语气/呈现)对通用英语数据进行评分,并以两个等级(错误识别和用户意图)对代码数据进行评分,并将获得最高分的样本视为高质量数据。RM 和基于 Llama 的分数的冲突率很高,我们发现将这些信号结合起来可以获得最佳的内部测试集召回率。最终,我们选择那些被 RM 或基于 Llama 过滤器标记为高质量的示例。
难度评分: 由于我们还对优先考虑更复杂的模型示例感兴趣,我们使用两个难度度量来评分数据:Instag (Lu et al., 2023) 和基于 Llama 的评分。对于 Instag,我们提示 Llama 3 70B 对 SFT 提示执行意图标记,其中更多的意图意味着更高的复杂性。我们还提示 Llama 3 以三个等级(Liu et al., 2024c)测量对话的难度。
语义去重: 最后,我们执行语义去重 (Abbas et al., 2023; Liu et al., 2024c)。我们首先使用 RoBERTa (Liu et al., 2019b) 对完整的对话进行聚类,并在每个聚类中按质量分数 × 难度分数排序。然后,我们通过迭代所有排序示例进行贪婪选择,只保留与到目前为止在聚类中看到的示例的最大余弦相似度小于阈值的示例。
4.3 能力
我们特别强调了一些为了提升特定能力所做的努力,例如代码处理(第4.3.1节)、多语言性(第4.3.2节)、数学和推理能力(第4.3.3节)、长上下文处理能力(第4.3.4节)、工具使用(第4.3.5节)、事实性(第4.3.6节)以及可控性(第4.3.7节)。
4.3.1 代码
自从 Copilot 和 Codex (Chen 等人,2021 年) 发布以来,用于代码的 LLM 已受到广泛关注。开发人员现在广泛使用这些模型来生成代码片段、调试、自动化任务和提高代码质量。对于 Llama 3,我们的目标是改进并评估以下优先级编程语言的代码生成、文档、调试和审查功能:Python、Java、JavaScript、C/C++、TypeScript、Rust、PHP、HTML/CSS、SQL、bash/shell。在这里,我们介绍了通过训练代码专家、为 SFT 生成合成数据、通过系统提示转向改进格式以及创建质量过滤器以从训练数据中删除不良样本来改进这些编码功能的工作。
专家训练。我们训练了一个代码专家,并在随后的多轮后训练中使用它来收集高质量的人类代码注释。这是通过分支主要预训练运行并继续对主要 (>85%) 为代码数据的 1T 令牌混合进行预训练来实现的。已证明在特定领域持续进行领域特定数据预训练可以有效地提高性能 (Gururangan 等人,2020 年)。我们遵循与 CodeLlama (Rozière 等人,2023 年) 相似的配方。在训练的最后几千步中,我们在高质量的仓库级别代码数据混合上执行长上下文微调 (LCFT),将专家的上下文长度扩展到 16K 令牌。最后,我们遵循第 4.1 节中描述的类似的后训练建模配方来对齐该模型,但使用主要针对代码的 SFT 和 DPO 数据混合。该模型也用于编码提示的拒绝采样 (第 4.2.2 节)。
合成数据生成。在开发过程中,我们发现代码生成存在关键问题,包括难以遵循指令、代码语法错误、代码生成不正确以及难以修复错误。尽管理论上密集的人类注释可以解决这些问题,但合成数据生成提供了一种补充方法,成本更低,规模更大,不受标注人员专业水平的限制。
因此,我们使用 Llama 3 和代码专家来生成大量合成的 SFT 对话。我们描述了生成合成代码数据的三个高级方法。总的来说,我们在 SFT 期间使用了超过 270 万个合成示例。
1. 合成数据生成:执行反馈。8B 和 70B 模型在由更大的、更能胜任的模型生成的训练数据上表现出显著的性能改进。然而,我们的初步实验表明,仅用 Llama 3 405B 训练其自身生成的數據没有帮助(甚至会降低性能)。为了解决这一限制,我们引入了执行反馈作为真理之源,使模型能够从错误中学习并保持在正轨上。特别是,我们使用以下过程生成大约一百万个合成的代码对话数据集:
问题描述生成:首先,我们生成了一大批涵盖各种主题(包括长尾分布)的编程问题描述。为了实现这种多样性,我们从各种来源随机采样代码片段并提示模型根据这些示例生成编程问题。这使我们能够利用广泛的主题并创建一个全面的问题描述集 (Wei 等人,2024 年)。
解决方案生成:然后,我们提示 Llama 3 用给定的编程语言解决每个问题。我们观察到在提示中添加良好的编程规则可以提高生成的解决方案质量。此外,我们发现要求模型用注释解释其思维过程也很有帮助。
正确性分析: 在生成解决方案后,识别其正确性并非保证,并将不正确的解决方案包含在微调数据集可能会损害模型的质量至关重要。虽然我们不能确保完全正确,但我们开发了近似正确性的方法。为此,我们将提取的源代码从生成的解决方案中,并应用静态和动态分析技术组合进行测试其正确性,包括:
静态分析: 我们将所有生成的代码都通过解析器和代码检查工具运行,以确保语法正确性,捕捉语法错误、未初始化变量或未导入函数的使用、代码风格问题、类型错误等。
单元测试生成和执行: 对于每个问题和解决方案,我们提示模型生成单元测试,并在容器化环境中与解决方案一起执行,捕获运行时执行错误和一些语义错误。
错误反馈和迭代自我校正: 当解决方案在任何步骤都失败时,我们将提示模型对其进行修改。提示包含原始问题描述、错误解决方案以及来自解析器/代码检查工具/测试程序的反馈(标准输出、标准错误和返回码)。单元测试执行失败后,模型可以修复代码以通过现有的测试,或者修改其单元测试以适应生成的代码。只有通过所有检查的对话才会被包含在最终的数据集中,用于监督式微调(SFT)。值得注意的是,我们观察到大约 20% 的解决方案最初不正确但进行了自我校正,这表明模型从执行反馈中学习并提高了其性能。
微调和迭代改进: 微调过程会进行多轮,每轮都建立在之前的轮子上。每次微调后,模型都会得到改进,为下一轮生成更高质量的合成数据。这个迭代过程允许对模型性能进行逐步细化和增强。
2. 合成数据生成:编程语言翻译。 我们观察到主要编程语言(例如 Python/C++)和不太常见的编程语言(例如 Typescript/PHP)之间存在性能差距。这并不奇怪,因为我们对于不太常见的编程语言拥有更少训练数据。为了缓解这种情况,我们将通过将常见编程语言的数据翻译成不太常见的语言来补充现有数据(类似于 Chen 等人 (2023) 在推理领域)。这是通过提示 Llama 3 并通过语法解析、编译和执行来确保质量实现的。图 8 展示了从 Python 翻译的合成 PHP 代码示例。这显著提高了 MultiPL-E (Cassano 等人,2023) 基准测量的不太常见语言的性能。
3. 合成数据生成:反向翻译。 为了改进某些编码能力(例如文档、解释),在执行反馈的信息量不足以确定质量的情况下,我们采用另一种多步骤方法。使用此过程,我们生成了约 120 万个与代码解释、生成、文档和调试相关的合成对话。从预训练数据中各种语言的代码片段开始:

生成: 我们提示 Llama 3 生成代表目标能力的数据(例如,为代码片段添加注释和文档字符串,或者要求模型解释一段代码)。
反向翻译: 我们会提示模型将合成生成的数据“反向翻译”回原始代码(例如,我们提示模型仅从其文档中生成代码,或者让我们询问模型仅从其解释中生成代码)。
过滤: 使用原始代码作为参考,我们提示 Llama 3 确定输出的质量(例如,我们询问模型反向翻译后的代码与原始代码的忠实度如何)。然后,我们在 SFT 中使用具有最高自我验证分数的生成的示例。
系统提示引导,用于拒绝采样。 在拒绝采样过程中,我们使用代码特定的系统提示来改进代码的可读性、文档、完整性和具体性。回忆第 7 节中提到的内容,这些数据用于微调语言模型。图 9 显示了系统提示如何帮助提高生成代码质量的示例 - 它添加了必要的注释,使用了更具信息量的变量名,节省内存等。
使用执行和模型作为评判标准过滤训练数据。 如第 4.2.3 节所述,我们偶尔会在拒绝采样的数据中遇到质量问题,例如包含错误的代码块。检测拒绝采样数据中的这些问题不像检测我们的合成代码数据那样简单,因为拒绝采样的响应通常包含自然语言和代码的混合体,而这些代码可能并不总是可执行的。(例如,用户提示可能会明确要求伪代码或仅对可执行程序的非常小的片段进行编辑。) 为了解决这个问题,我们利用“模型作为评判者”方法,其中更早版本的 Llama 3 会根据两个标准评估并分配二进制(0/1)分数:代码正确性和代码风格。我们只保留获得 2 分满分的样本。最初,这种严格的过滤导致了下游基准性能下降,主要是因为它不成比例地删除了具有挑战性提示的示例。为了抵消这一点,我们将一些分类为最具挑战性的编码数据的响应进行战略性修改,直到它们满足基于 Llama 的“模型作为评判者”标准。通过改进这些具有挑战性的问题,编码数据在质量和难度之间取得了平衡,从而实现了最佳的下游性能。
4.3.2 多语言能力
本节描述了我们如何改进 Llama 3 的多语言能力,包括:训练一个在更多多语言数据上专业化的专家模型;为德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语采购并生成高质量的多语言指令微调数据;以及解决多语言语言引导的具体挑战,以提高我们模型的整体性能。
专家训练。我们的 Llama 3 预训练数据混合包含的英语标记远远多于非英语标记。为了收集更高质量的非英语人工注释,我们通过分支预训练运行并继续在包含 90% 多语言标记的数据混合上进行预训练来训练一个多语言专家模型。然后,我们在第 4.1 节中按照说明对该专家模型进行后训练。然后,该专家模型用于收集更高质量的非英语人工注释,直到预训练完全完成。
多语言数据收集。我们的多语言 SFT 数据主要来自以下来源。总体分布为:2.4% 人工注释、44.2% 来自其他 NLP 任务的数据、18.8% 拒绝采样数据和 34.6% 翻译推理数据。
人工注释:我们从语言学家和母语人士那里收集高质量的、手动标注的数据。这些注释主要由开放式提示组成,它们代表了现实世界的用例。
来自其他 NLP 任务的数据:为了进一步增强,我们使用来自其他任务的多语言训练数据并将它们改写成对话格式。例如,我们使用了 exams-qa(Hardalov 等人,2020 年)和 Conic10k(Wu 等人,2023 年)的数据。为了改进语言对齐,我们还使用了 GlobalVoices(Prokopidis 等人,2016 年)和 Wikimedia(Tiedemann,2012 年)的并行文本。我们使用基于 LID 的过滤和 Blaser2.0(Seamless Communication 等人,2023 年)来删除低质量数据。对于并行文本数据,我们没有直接使用双文本对,而是应用了一个受 Wei 等人 (2022a) 启发的多语言模板,以更好地模拟翻译和语言学习场景中的真实对话。
拒绝采样数据:我们将拒绝采样应用于人类注释的提示,以生成高质量的样本用于微调,与英语数据的处理过程相比进行了很少的修改:
生成:我们在后训练的早期轮次中探索了随机选择温度超参数的范围为 0.2 -1,以实现多样化的生成。使用高温度时,多语言提示的响应可能会变得富有创意和鼓舞人心,但也会容易出现不必要的或不自然的代码切换。在后训练的最后阶段,我们使用 0.6 的恒定值来平衡这一权衡。此外,我们还使用了专门的系统提示来改进响应格式、结构和一般可读性。
选择:在基于奖励模型的选择之前,我们实施了多语言特定的检查,以确保提示和回复之间的语言匹配率很高(例如,罗马化印地语提示不应期望使用印地语梵文脚本进行回复)。
翻译数据:我们试图避免使用机器翻译数据来微调模型,以防止出现翻译式英语(Bizzoni 等人,2020 年;Muennighoff 等人,2023 年)或可能出现的姓名偏见(Wang 等人,2022a)、性别偏见(Savoldi 等人,2021 年)或文化偏见(Ji 等人,2023 年)。此外,我们旨在防止模型仅接触根植于英语文化背景的任务,这些任务可能无法代表我们旨在捕捉的语言和文化多样性。我们对此做了一个例外,并将合成的定量推理数据(有关详细信息,请参见第 4.3.3 节)翻译成非英语,以提高非英语语言中的定量推理性能。由于这些数学问题的语言本质简单,因此发现翻译后的样本几乎没有质量问题。我们观察到从添加此翻译数据的 MGSM(Shi 等人,2022 年)获得了显著的收益。
4.3.3 数学与推理
我们定义推理为执行多步计算并得出正确最终答案的能力。
几个挑战指导了我们训练擅长数学推理模型的方法:
缺乏提示: 随着问题复杂度的增加,用于监督微调 (SFT) 的有效提示或问题的数量减少。这种稀缺性使得创建多样化且具有代表性的训练数据集来教授模型各种数学技能变得困难(Yu 等人,2023;Yue 等人,2023;Luo 等人,2023;Mitra 等人,2024;Shao 等人,2024;Yue 等人,2024b)。
缺乏真实推理过程: 有效的推理需要逐步解决方案来促进推理过程(Wei 等人,2022c)。然而,通常缺少真实推理过程,这些过程对于指导模型如何逐步分解问题并得出最终答案至关重要(Zelikman 等人,2022)。
错误的中间步骤: 使用模型生成的推理链时,中间步骤可能并不总是正确(Cobbe 等人,2021;Uesato 等人,2022;Lightman 等人,2023;Wang 等人,2023a)。这种不准确性会导致最终答案错误,需要解决。
训练模型使用外部工具: 增强模型以利用外部工具(如代码解释器)的能力,使其可以通过交织代码和文本进行推理(Gao 等人,2023;Chen 等人,2022;Gou 等人,2023)。这种能力可以显着提高他们的问题解决能力。
训练和推理之间的差异: 模型在训练期间进行微调的方式通常与在推理期间使用的方式存在差异。在推理过程中,经过微调的模型可能会与人类或其他模型互动,需要通过反馈来改进其推理能力。确保训练和实际应用之间的一致性对于维持推理性能至关重要。
为了解决这些挑战,我们应用以下方法:
解决提示缺乏问题: 我们从数学上下文中获取相关预训练数据,并将其转换为问题-答案格式,可用于监督微调。此外,我们会识别模型表现不佳的数学技能,并积极地从人类那里收集提示以教授模型这些技能。为了促进这一过程,我们创建了一个数学技能分类法(Didolkar 等人,2024),并要求人类提供相应的提示/问题。
用逐步推理步骤增强训练数据: 我们使用 Llama 3 为一组提示生成逐步解决方案。对于每个提示,模型都会产生可变数量的生成结果。然后根据正确答案过滤这些生成结果(Li 等人,2024a)。我们还进行自我验证,其中 Llama 3 用于验证特定逐步解决方案是否对给定的问题有效。这个过程通过消除模型不产生有效推理轨迹的实例来提高微调数据的质量。
过滤错误的推理步骤: 我们训练结果和逐步奖励模型(Lightman 等人,2023;Wang 等人,2023a)来过滤中间推理步骤不正确的训练数据。这些奖励模型用于消除具有无效逐步推理的数据,确保微调得到高质量的数据。对于更具挑战性的提示,我们使用带有学习逐步奖励模型的蒙特卡罗树搜索 (MCTS) 来生成有效的推理轨迹,从而进一步增强高质量推理数据的收集(Xie 等人,2024)。
交织代码和文本推理: 我们提示 Llama 3 通过文本推理及其关联 Python 代码组合来解决推理问题(Gou 等人,2023)。代码执行用作反馈信号,以消除推理链无效的情况,确保推理过程的正确性。
从反馈和错误中学习: 为了模拟人类反馈,我们利用错误的生成结果(即导致错误推理轨迹的生成结果),并通过提示 Llama 3 生成正确的生成结果来进行错误更正(An 等人,2023b;Welleck 等人,2022;Madaan 等人,2024a)。使用错误尝试的反馈并纠正它们的自迭代过程有助于提高模型准确推理的能力并从错误中学习。
4.3.4 长上下文
在最后的预训练阶段,我们将Llama 3的上下文长度从8K个标记扩展到128K个标记(有关详细信息请参见第3.4节)。与预训练类似,我们发现在微调过程中,必须仔细调整配方以平衡短上下文和长上下文能力。
SFT 和合成数据生成。 简单地应用我们的现有 SFT 配方,只使用短上下文数据导致预训练中的长上下文能力显著下降,突出了在 SFT 数据组合中纳入长上下文数据的必要性。然而,实际上,让人工标注这些示例大部分是不切实际的,因为阅读冗长的上下文非常繁琐且耗时,因此我们主要依赖合成数据来弥补这一差距。我们使用早期版本的 Llama 3 生成合成数据,基于关键的长上下文用例:(可能为多轮)问答、长文档摘要以及代码库上的推理,并在下面更详细地描述这些用例。
问答: 我们从预训练数据集中仔细挑选了一组长文档。我们将这些文档拆分成8K个标记的块,并提示早期版本的 Llama 3 模型在随机选择的块上生成 QA 对。在训练过程中,整个文档都被用作上下文。
摘要: 我们通过首先使用我们最强的 Llama 3 8K 上下文模型对 8K 输入长度的块进行层次化摘要来应用长上下文文档的层次化摘要。然后对这些摘要进行汇总。在训练中,我们提供完整文档并提示模型总结文档,同时保留所有重要细节。我们还基于文档的摘要生成 QA 对,并用需要对整个长文档全局理解的问题提示模型。
长上下文代码推理: 我们解析 Python 文件以识别导入语句并确定它们的依赖关系。从这里开始,我们选择最常用的文件,特别是那些被至少其他五个文件引用的文件。我们从存储库中删除这些关键文件中的一个,并提示模型识别依赖于缺少的文件,并生成必要的缺失代码。
我们进一步根据序列长度(16K、32K、64K 和 128K)对这些合成生成的样本进行分类,以实现更精细的输入长度定位。
通过仔细的消融实验,我们观察到将 0.1% 的合成生成的长上下文数据与原始短上下文数据混合可以优化短上下文和长上下文基准测试的性能。
DPO。 我们注意到在 DPO 中仅使用短上下文训练数据不会对长上下文性能产生负面影响,只要 SFT 模型对长上下文任务效果良好。我们怀疑这是因为我们的 DPO 配方比 SFT 的优化器步骤更少。考虑到这一发现,我们在长上下文 SFT 检查点之上保留标准的短上下文 DPO 配方。
4.3.5 工具使用
教导大型语言模型(LLM)使用诸如搜索引擎或代码解释器之类的工具,可以大大扩展它们能够解决的任务范围,将它们从纯粹的聊天模型转变为更通用的助手(Nakano 等人,2021 年;Thoppilan 等人,2022 年;Parisi 等人,2022 年;Gao 等人,2023 年;Mialon 等人,2023a;Schick 等人,2024 年)。我们训练 Llama 3 与以下工具进行交互:
搜索引擎。Llama 3 被训练使用 Brave Search7 来回答关于其知识截止日期之后的近期事件的问题,或者需要从网络中检索特定信息的请求。
Python 解释器。Llama 3 可以生成并执行代码以执行复杂的计算,读取用户上传的文件并根据这些文件解决任务,例如问答、摘要、数据分析或可视化。
数学计算引擎。Llama 3 可以使用 Wolfram Alpha API8 更准确地解决数学和科学问题,或者从 Wolfram 的数据库中检索准确信息。
生成的模型能够在聊天设置中使用这些工具来解决用户的查询,包括多回合对话。如果查询需要多次调用工具,该模型可以编写逐步计划,依次调用工具,并在每次工具调用后进行推理。
我们还提高了 Llama 3 的零样本工具使用能力——给定上下文环境下可能未见过的工具定义和用户查询,我们训练模型生成正确的工具调用。
实现。我们将核心工具实施为具有不同方法的 Python 对象。零样本工具可以作为带有描述、文档(即如何使用它们的示例)的 Python 函数来实现,模型只需要函数签名和 docstring 作为上下文即可生成适当的调用。
我们还将函数定义和调用转换为 JSON 格式,例如用于 Web API 调用。所有工具调用都由 Python 解释器执行,Python 解释器必须在 Llama 3 系统提示中启用。可以在系统提示中单独启用或禁用核心工具。
数据收集。与 Schick 等人 (2024) 不同,我们依靠人类标注和偏好来教 Llama 3 使用工具。这与 Llama 3 中通常使用的后训练管道存在两个主要区别:
关于工具,对话常常包含不止一条助理消息(例如,调用工具并对工具输出进行推理)。因此,我们进行消息级别的标注以收集详细的反馈:标注者在相同上下文下提供两条助理消息的偏好,或者如果两者都存在主要问题,则编辑其中一条消息。然后将被选择或修改的消息添加到上下文中,对话继续进行。这为助理调用工具和推理工具输出的能力提供了人类反馈。标注者不能对工具输出进行排名或编辑。
我们没有执行拒绝采样,因为在我们的工具基准测试中没有观察到收益。
为了加速标注过程,我们首先通过微调来自之前 Llama 3 检查点的合成数据来引导基本的工具使用能力。这样一来,标注者就需要进行较少的编辑操作。类似地,随着 Llama 3 在开发过程中逐渐改进,我们会逐步复杂化我们的人类标注协议:我们从单回合的工具使用标注开始,然后转向对话中的工具使用,最后注释多步骤工具使用和数据分析。
工具数据集。为了创建用于工具使用应用程序的数据,我们采用以下步骤:
单步工具使用: 我们首先进行少量样本生成合成用户提示,这些提示通过构造需要调用我们的核心工具之一(例如,超过我们知识截止日期的问题)。然后,仍然依靠少量样本生成,我们为这些提示生成适当的工具调用,执行它们,并将输出添加到模型的上下文中。最后,我们再次提示模型以根据工具输出生成对用户查询的最终答案。我们最终得到以下形式的轨迹:系统提示、用户提示、工具调用、工具输出、最终答案。我们还过滤掉了大约 30% 的数据集,以删除无法执行的工具调用或其他格式问题。
多步骤工具使用: 我们遵循类似的协议,首先生成合成数据来教授模型基本的 다단계 工具使用能力。为此,我们首先提示 Llama 3 生成至少需要两次工具调用的用户提示(可以是来自我们的核心集中的相同工具或不同工具)。然后,根据这些提示,我们进行少量样本提示 Llama 3 生成一个解决方案,该解决方案由交织的推理步骤和工具调用组成,类似于 ReAct (Yao 等人,2022)。请参见图 10,以了解 Llama 3 执行涉及多步骤工具使用任务的示例。
文件上传: 我们针对以下文件类型进行标注:.txt, .docx, .pdf, .pptx, .xlsx, .csv, .tsv, .py, .json, .jsonl, .html, .xml。我们的提示基于提供文件,并要求总结文件内容、查找和修复错误、优化代码段、执行数据分析或可视化。图 11 显示了 Llama 3 执行涉及文件上传任务的示例。

在对此合成数据进行微调后,我们收集了来自各种场景的人类标注,包括多轮交互、超过三步的工具使用以及工具调用无法产生令人满意的答案的情况。我们用不同的系统提示增强合成数据,以教导模型仅在被激活时才使用工具。为了训练模型避免对简单查询进行工具调用,我们还添加了来自易于计算或问答数据集(Berant 等人,2013;Koncel-Kedziorski 等人,2016;Joshi 等人,2017;Amini 等人,2019)的查询及其响应,这些响应不使用工具,但在系统提示中激活了工具。
零样本工具使用数据: 我们通过对大量且多样的部分合成(函数定义、用户查询、相应调用)元组进行微调,从而改善 Llama 3 的零样本工具使用能力(也称为功能调用)。我们在未见过工具的集合上评估我们的模型。
单一、嵌套和并行函数调用: 调用可以是简单的、嵌套的(即我们将函数调用作为另一个函数的参数传递)或平行的(即模型返回一个独立函数调用的列表)。生成各种函数、查询和真实结果可能具有挑战性(Mekala 等人,2024),我们依靠挖掘 Stack(Kocetkov 等人,2022)来将我们的合成用户查询基于真实的函数。更准确地说,我们提取函数调用及其定义,清理和过滤它们(例如,缺少文档字符串或不可执行的函数),并使用 Llama 3 生成与函数调用相对应的自然语言查询。
多回合函数调用: 我们还为包含函数调用的多回合对话生成合成数据,遵循类似于 Li 等人(2023b)中提出的协议。我们使用多个代理来生成域、API、用户查询、API 调用和响应,同时确保生成的數據涵盖了一系列不同的领域和真实的 API。所有代理都是 Llama 3 的变体,其提示方式取决于它们的职责,并且以逐步的方式进行协作。
4.3.6 事实性
虚幻仍然是大型语言模型面临的主要挑战。模型往往过于自信,即使在它们缺乏知识的领域也是如此。尽管存在这些缺点,但它们经常被用作知识库,这可能导致危险的结果,例如误信息的传播。虽然我们认识到真实性超越了虚幻,但我们在这里采取了一种以虚幻为先的方法。
图 11 文件上传处理。示例展示了 Llama 3 对上传文件进行分析和可视化的过程。
我们遵循这样的原则:后训练应该使模型与“知道它知道什么”保持一致,而不是添加知识(Gekhman 等人,2024;Mielke 等人,2020)。我们的主要方法涉及生成将模型生成与预训练数据中存在的真实数据子集对齐的数据。为此,我们开发了一种利用 Llama 3 上下文能力的知识探测技术。这个数据生成过程包括以下步骤:
从预训练数据中提取一个数据片段。
通过提示 Llama 3 生成关于这些片段(上下文)的事实性问题。
从 Llama 3 中采样对该问题的回答。
使用原始上下文作为参考,并使用 Llama 3 作为评判者来评分生成的正确性。
使用 Llama 3 作为评判者来评分生成的丰富度。
为那些在多次生成中始终信息丰富且不正确的回答生成拒绝理由,并使用 Llama 3
我们使用从知识探测中生成的数据来鼓励模型只回答它知道的问题,并拒绝回答它不确定的问题。此外,预训练数据并不总是事实一致或正确的。因此,我们还收集了一组有限的标记真实性数据,这些数据处理了敏感话题,其中存在许多与事实相矛盾或不正确的陈述。
4.3.7 可控性
可控性是指能够将模型的行为和结果引导至满足开发者和用户需求的能力。由于Llama 3是一个通用的基础模型,因此应该能够轻松地将其引导至不同的下游用例。为了提高Llama 3的可控性,我们专注于通过系统提示(使用自然语言指令)来增强其可控性,特别是关于响应长度、格式、语气和角色/人物设定方面。
数据收集: 我们通过要求标注者为Llama 3设计不同的系统提示,在通用英语类别中收集可控性偏好样本。然后,标注者与模型进行对话,以评估模型在整个对话过程中是否能够始终如一地遵循系统提示中定义的指令。以下是用于增强可控性的定制系统提示示例:
“你是一个乐于助人且充满活力的 AI 聊天机器人,担任忙碌家庭的膳食计划助手。工作日餐食应该快速便捷。早餐和午餐应优先选择方便食品,例如谷物、英式松饼配预先煮熟的培根和其他快速易做的食物。这个家庭很忙。请务必询问他们手边是否有必需品和喜欢的饮品,例如咖啡或能量饮料,以免他们忘记购买。除非是特殊场合,否则请记住节约预算。”
建模: 收集偏好数据后,我们将这些数据用于奖励建模、拒绝采样、SFT(持续精细调整)和DPO(数据驱动的参数优化),以增强Llama 3的可控性。
5 结果
我们对 Llama 3 进行了一系列广泛的评估,调查了以下方面的性能:(1) 预训练语言模型,(2) 后训练语言模型,以及 (3) Llama 3 的安全特性。我们在下面的独立子节中展示这些评估的结果。
5.1 预训练语言模型
在本节中,我们将报告预训练 Llama 3 (第三部分) 的评估结果,并将其与其他可比规模的模型进行比较。我们会尽可能重现竞品模型的结果。对于非 Llama 模型,我们将报告在公开报道的结果中或(在可能的情况下)我们自己重现的结果中的最佳分数。这些评估的具体细节,包括射数、指标和其他相关的超参数和设置等配置,可以在我们的 Github 仓库中获得:[在此插入链接]。此外,我们还会发布作为公开基准评估的一部分生成的数据,这些数据可以在这里找到:[在此插入链接]。
我们将根据标准基准 (第五部分 5.1.1) 对模型质量进行评估,测试多项选择题设置变化的鲁棒性 (第五部分 5.1.2),以及进行对抗性评估 (第五部分 5.1.3)。我们还将进行污染分析,以估计训练数据污染对我们评估的影响程度 (第五部分 5.1.4)。
5.1.1 标准基准
为了将我们的模型与当前最先进的水平进行比较,我们对 Llama 3 在大量标准基准测试中进行了评估,这些测试如下所示:
(1) 常识推理;(2) 知识;(3) 阅读理解;(4) 数学、推理和问题解决;(5) 长上下文;(6) 代码;(7) 对抗性评估;以及 (8) 总体评估。
实验设置。对于每个基准测试,我们计算 Llama 3 的分数以及其他具有可比尺寸的预训练模型的分数。在可能的情况下,我们将使用自己的管道重新计算其他模型的数据。为了确保公平比较,我们然后选择我们在计算的数据和该模型报告的数字(使用相同或更保守的设置)之间的最佳分数。您可以在此处找到有关我们的评估设置的更多详细信息。对于某些模型,例如由于未发布预训练模型或API不提供对数概率访问权限,无法重新计算基准测试值。这尤其适用于与 Llama 3 405B 可比的所有模型。因此,我们没有报告 Llama 3 405B 的类别平均值,因为需要所有基准测试的数字都可用。
显著性值。在计算基准测试分数时,由于有几种方差来源会导致对基准测试旨在测量的模型性能产生不精确的估计,例如少量演示、随机种子和批量大小。这使得理解一个模型是否在统计上显著优于另一个模型变得具有挑战性。因此,我们将分数与 95% 置信区间 (CI) 一起报告,以反映基准数据选择带来的方差。我们使用公式(Madaan 等人,2024b)分析地计算 95% CI:
CI_analytic(S) = 1.96 * sqrt(S * (1 - S) / N)
其中 S 是首选的基准分数,N 是基准的样本量。我们注意到,由于基准数据中的方差不是唯一的方差来源,因此这些 95% CI 是实际能力估计方差的下限。对于不是简单平均值的指标,将省略 CI。
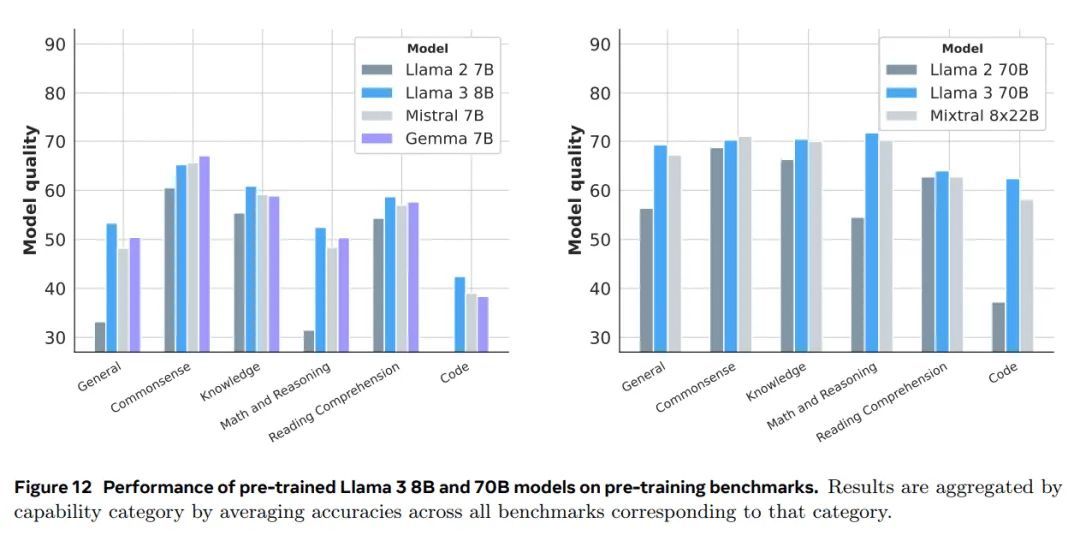
Llama 3 8B 和 70B 模型的结果。图 12 显示了 Llama 3 8B 和 70B 在常识推理、知识、阅读理解、数学和推理以及代码基准测试上的平均性能。结果表明,Llama 3 8B 在几乎所有类别中都优于竞争模型,无论是按类别胜率还是按类别平均性能而言。我们还发现, Llama 3 70B 在大多数基准测试上都比其前身 Llama 2 70B 大幅提高了性能,除了可能已饱和的常识基准测试之外。Llama 3 70B 也优于 Mixtral 8x22B。
8B和70B模型的结果。图12显示了Llama 3 8B和70B在常识推理、知识、阅读理解、数学与推理以及代码基准测试中的平均表现。结果表明,Llama 3 8B在几乎每个类别中都超越了竞争模型,无论是按类别的胜率还是平均每类别的表现。我们还发现,Llama 3 70B在大多数基准测试中比其前代产品Llama 2 70B有了很大的提升,除了可能已达到饱和的常识基准测试之外。Llama 3 70B还超越了Mixtral 8x22B。
所有模型的详细结果。表9、10、11、12、13和14展示了预训练的Llama 3 8B、70B和405B模型在阅读理解任务、编码任务、常识理解任务、数学推理任务和常规任务中的基准测试表现。这些表格将Llama 3的表现与同类大小的模型进行了比较。结果显示,Llama 3 405B在其类别中具有竞争力,尤其在很大程度上超越了先前的开源模型。关于长上下文的测试,我们在第5.2节中提供了更全面的结果(包括针在大海捞针等探测任务)。
5.1.2 模型稳健性(Model Robustness)
除了基准测试性能之外,稳健性也是预训练语言模型质量的重要因素。我们研究了预训练语言模型在多项选择题 (MCQ) 设置中的设计选择稳健性。先前的研究表明,模型性能可能对这些设置中看似任意的设计选择很敏感,例如,模型得分甚至排名可能会随着上下文示例的顺序和标签而改变(Lu 等人,2022;Zhao 等人,2021;Robinson 和 Wingate,2023;Liang 等人,2022;Gupta 等人,2024),提示的确切格式(Weber 等人,2023b;Mishra 等人,2022) 或答案选项的格式和顺序(Alzahrani 等人,2024;Wang 等人,2024a;Zheng 等人,2023)。受此工作启发,我们使用 MMLU 基准来评估预训练模型对以下方面的稳健性:(1)少数镜头标签偏差,(2)标签变体,(3)答案顺序,以及(4)提示格式:
少数镜头标签偏差。 遵循 Zheng 等人(2023),...(此处省略实验细节和结果描述)。
标签变体。 我们还研究了模型对不同选择标记集的响应。我们考虑了 Alzahrani 等人(2024)提出的两个标记集:即一组常见语言无关标记($ & # @)和一组不具有任何隐含相对顺序的稀有标记(oe § з ü)。我们还考虑了规范标签的两种版本(A. B. C. D. 和 A) B) C) D)) 和一个数字列表(1. 2. 3. 4.)。
答案顺序。 遵循 Wang 等人(2024a),我们计算结果在不同答案顺序下的稳定性。为此,我们将数据集中的所有答案根据固定的排列重新映射。例如,对于排列 A B C D,所有标记为 A 和 B 的答案选项保持其标签,而标记为 C 的所有答案选项获取标签 D,反之亦然。
提示格式。 我们评估了五种任务提示的性能差异,这些提示的信息量不同:一种提示简单地要求模型回答问题,而其他提示则断言模型的专业知识或应该选择最佳答案。
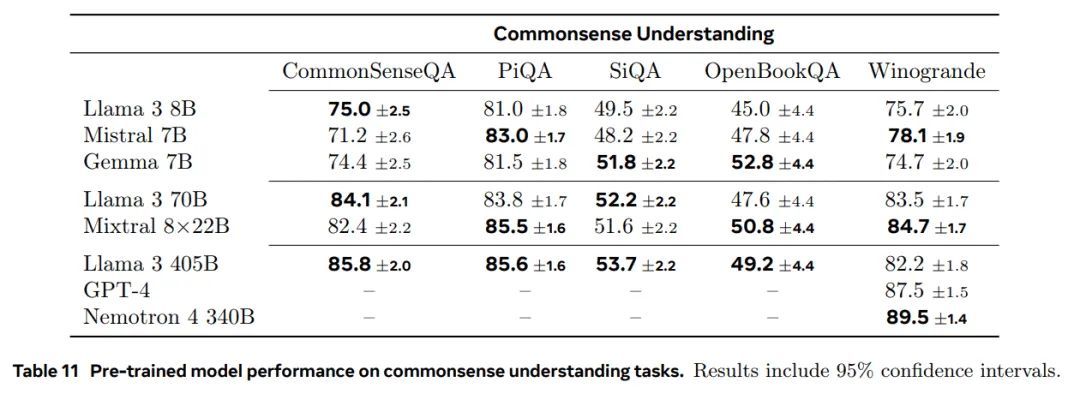
表 11 预训练模型在常识理解任务上的性能。结果包括 95% 置信区间。
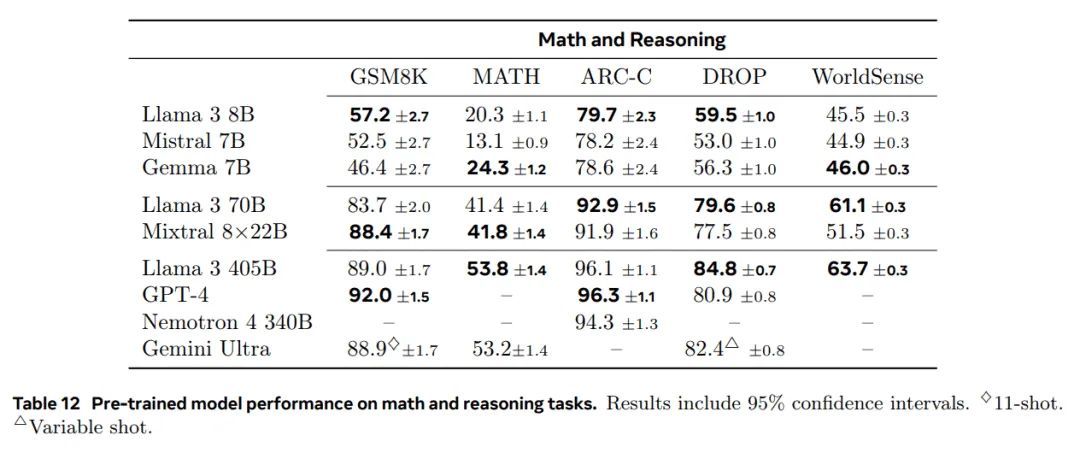
表 12 预训练模型在数学和推理任务上的性能。结果包括 95% 置信区间。11 次射击。
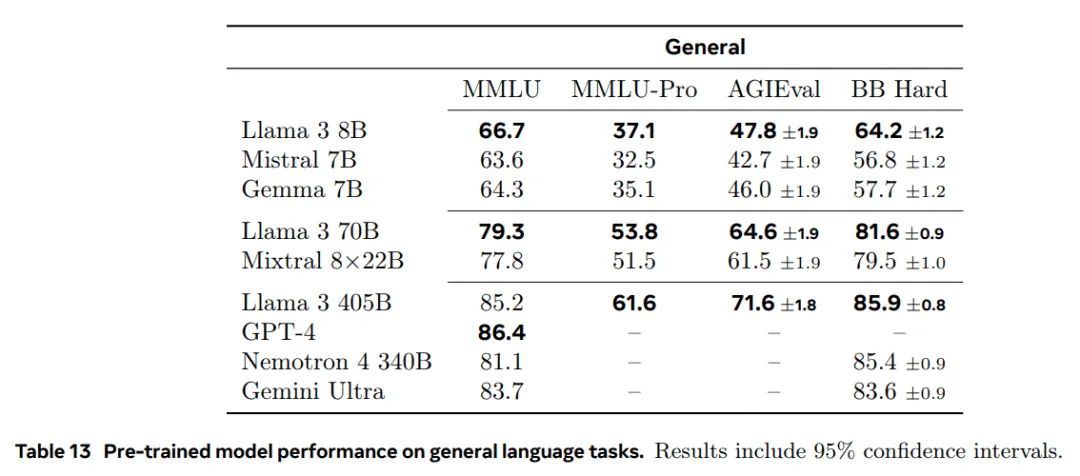
表 13 预训练模型在通用语言任务上的性能。结果包括 95% 置信区间。
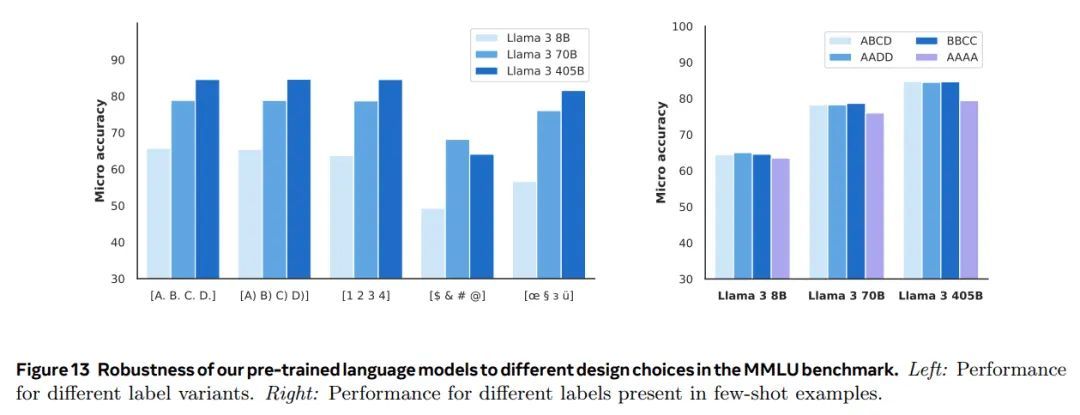
图 13 我们预训练语言模型在 MMLU 基准测试中对不同设计选择的鲁棒性。左侧:不同标签变体的性能。右侧:少样本示例中存在不同标签的性能。
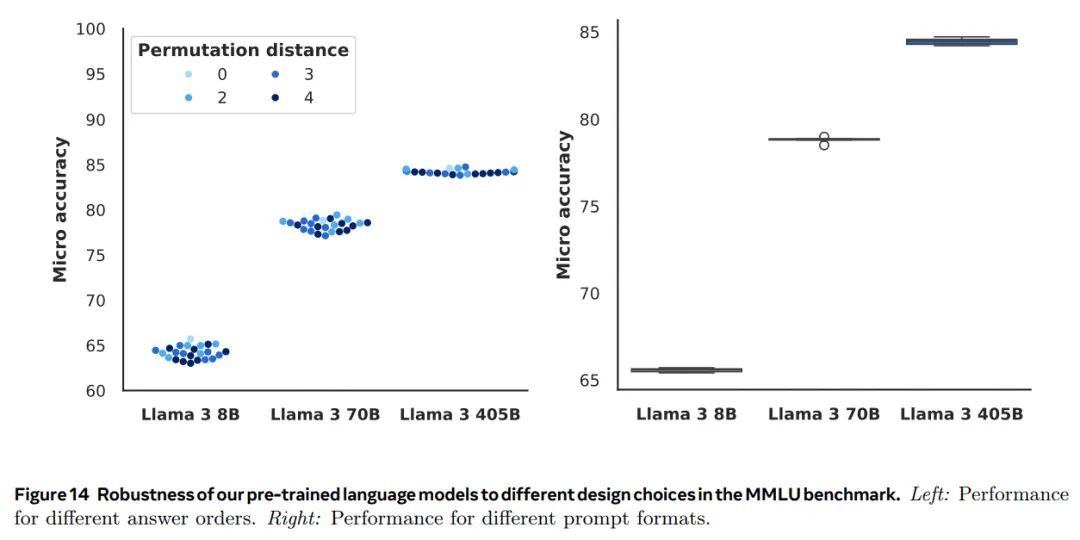
图 14 我们预训练语言模型在 MMLU 基准测试中对不同设计选择的鲁棒性。左侧:不同答案顺序的性能。右侧:不同提示格式的性能。
图 13 展示了我们研究标签变体(左)和少数镜头标签偏差(右)模型性能稳健性的实验结果。结果表明,我们的预训练语言模型对 MCQ 标签的变化以及少数镜头提示标签的结构都非常稳健。这种稳健性对于 405B 参数模型尤其明显。
图 14 展示了我们对答案顺序和提示格式稳健性研究的结果。这些结果进一步强调了我们预训练语言模型性能的稳健性,特别是 Llama 3 405B 的稳健性。
5.1.3 对抗性基准测试
除了上面提到的基准测试外,我们还对三个领域的几个对抗性基准进行了评估:问答、数学推理和句式改写检测。这些测试旨在探测模型在专门设计成具有挑战性的任务上的能力,并可能指出模型在基准测试上的过度拟合问题。
问答方面,我们使用了Adversarial SQuAD (Jia 和 Liang, 2017) 和 Dynabench SQuAD (Kiela 等人, 2021)。
数学推理方面,我们使用了 GSM-Plus (Li 等人, 2024c)。
句式改写检测方面,我们使用了 PAWS (Zhang 等人, 2019)。
图 15 展示了 Llama 3 8B、70B 和 405B 在对抗性基准测试上的得分,作为其在非对抗性基准测试上的性能的函数。我们使用的非对抗性基准测试是:用于问答的 SQuAD (Rajpurkar 等人, 2016)、用于数学推理的 GSM8K 和用于句式改写检测的 QQP (Wang 等人, 2017)。每个数据点代表一个对抗性数据集和非对抗性数据集对(例如 QQP 与 PAWS 配对),我们展示了类别内的所有可能配对。对角线上的黑色线表示对抗性和非对抗性数据集之间的平价——在该线上表示模型无论对抗性与否都具有类似的性能。
在句式改写检测方面,无论是预训练模型还是后训练模型,似乎都没有受到 PAWS 所构建的对立性的影响,这代表了相对于上一代模型的巨大进步。这一结果证实了 Weber 等人 (2023a) 的发现,他们也发现大型语言模型对几个对抗性数据集中的虚假相关性更少敏感。然而,对于数学推理和问答,对抗性表现明显低于非对抗性表现。这种模式适用于预训练模型和后训练模型。
5.1.4 污染分析
我们进行了一项污染分析,以估计基准分数可能受到预训练语料库中评估数据污染影响的程度。先前的一些工作使用了多种不同的污染方法和超参数——我们参考了 Singh 等人的研究(2024)。结果表明,我们的预训练语言模型对多项选择题标签的变化以及少样本提示标签结构变化非常稳健(2024 年概述)。任何这些方法都可能出现假阳性和假阴性,如何最佳地进行污染分析目前仍然是一个开放的研究领域。在这里,我们主要遵循 Singh 等人的建议(2024)。
方法:具体来说,Singh 等人 (2024) 建议根据哪种方法导致“干净”数据集和整个数据集之间的最大差异来经验选择污染检测方法,他们将其称为估计的性能增益。对于所有评估数据集,我们基于 8-gram 重叠进行评分,Singh 等人 (2024) 发现这种方法对许多数据集都是准确的。我们将数据集 D 的一个示例视为受污染的,如果其标记 TD 中的一个比例至少在预训练语料库中出现一次。我们针对每个数据集单独选择 TD,根据哪个值显示最大显著估计性能增益(跨三个模型大小)。
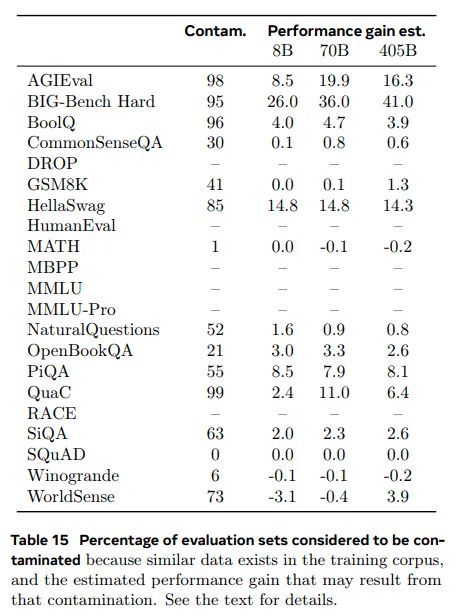
结果:表 15 显示了如上所述,所有主要基准的评估数据中被认为受污染的百分比,以获得最大的估计性能增益。从该表中,我们排除了结果不显着的基准数字,例如由于干净或受污染的集合样本太少,或者观察到的性能增益估计显示出极其不稳定行为。
在表 15 中,我们可以看到,对于一些数据集,污染具有很大影响,而对其他数据集则没有。例如,对于 PiQA 和 HellaSwag,污染估计和性能增益估计都较高。另一方面,对于 Natural Questions,估计的 52% 污染似乎对性能几乎没有影响。对于 SQuAD 和 MATH,低阈值会导致高水平的污染,但不会带来性能提升。这表明污染可能对这些数据集没有帮助,或者需要更大的 n 来获得更好的估计。最后,对于 MBPP、HumanEval、MMLU 和 MMLU-Pro,可能需要其他污染检测方法:即使使用更高的阈值,8-gram 重叠也会给出如此高的污染分数,以至于无法获得良好的性能增益估计。
5.2 微调语言模型
我们展示了在不同能力的基准测试上训练后的Llama 3模型的结果。与预训练类似,我们将作为评估的一部分生成的数据发布到公共可用的基准测试中,这些基准测试可以在Huggingface上找到(此处插入链接)。有关我们评估设置的更多详细信息,请参见此处(此处插入链接)。
基准测试和指标。表16概述了所有基准测试,按能力分类。我们将通过与每个基准测试中的提示进行精确匹配来对后训练数据进行去污染处理。除了标准的学术基准测试外,我们还进行了广泛的人工评估不同能力的测试。详细信息请参见第5.3节。
实验设置。我们采用与预训练阶段类似的实验设置,并对Llama 3与其他具有可比尺寸和能力的模型进行比较分析。在可能的情况下,我们将自己评估其他模型的性能并将其结果与报告数字进行比较,选择最佳分数。有关我们评估设置的更多详细信息,请参见此处(此处插入链接)。
表16 按类别列出的后训练基准测试。我们用来评估训练后的Llama 3模型的所有基准测试的概述,按能力排序。
5.2.1 通用知识和指令遵循基准测试
我们使用表 2 中列出的基准测试来评估 Llama 3 在通用知识和指令遵循方面的能力。
通用知识: 我们利用 MMLU (Hendrycks et al., 2021a) 和 MMLU-Pro (Wang et al., 2024b) 来评估 Llama 3 在基于知识的问答能力上的表现。对于 MMLU,我们在没有 CoT 的 5 次示例标准设置下报告子任务准确率的宏观平均值。MMLU-Pro 是 MMLU 的扩展版本,包含更具挑战性的、以推理为重点的问题,消除了噪声问题,并将选择范围从四个选项扩展到十个选项。考虑到它侧重于复杂推理,我们报告了 MMLU-Pro 的 5 次示例 CoT。所有任务都格式化为生成任务,类似于 simple-evals (OpenAI, 2024)。
如表 2 所示,我们的 8B 和 70B Llama 3 变体在两个通用知识任务上都优于其他相似规模的模型。我们的 405B 模型优于 GPT-4 和 Nemotron 4 340B,Claude 3.5 Sonnet 在更大模型中领先。
指令遵循: 我们使用 IFEval (Zhou et al., 2023) 来评估 Llama 3 和其他模型遵循自然语言指令的能力。IFEval 包括大约 500 个“可验证指令”,例如“用超过 400 个字写” ,这些指令可以使用启发式方法进行验证。我们在表 2 中报告了严格和宽松约束下的提示级和指令级准确率的平均值。请注意,所有 Llama 3 变体在 IFEval 上都优于可比较的模型。
5.2.2 能力考试
接下来,我们将在最初设计用于测试人类的一系列能力测试上评估我们的模型。我们从公开可用的官方来源获取这些考试;对于某些考试,我们将不同考试集的平均分数报告为每个能力测试的结果。具体来说,我们平均:
GRE:教育测试服务提供的官方 GRE 实践考试 1 和 2;
LSAT:官方预测试 71、73、80 和 93;
SAT:来自《官方 SAT 学习指南》2018 版的 8 个考试;
AP:每个学科一个官方练习考试;
GMAT:官方 GMAT 在线考试。
这些考试中的问题包含了多项选择题和生成式问题。我们将排除任何附带图像的问题。对于包含多个正确选项的 GRE 题目,只有当模型选择了所有正确选项时,我们才将输出限定为正确。在有超过一个考试集的情况下,我们会使用少量提示进行评估。我们将分数调整到 130-170 的范围内(用于 GRE),并报告其他所有考试的准确率。
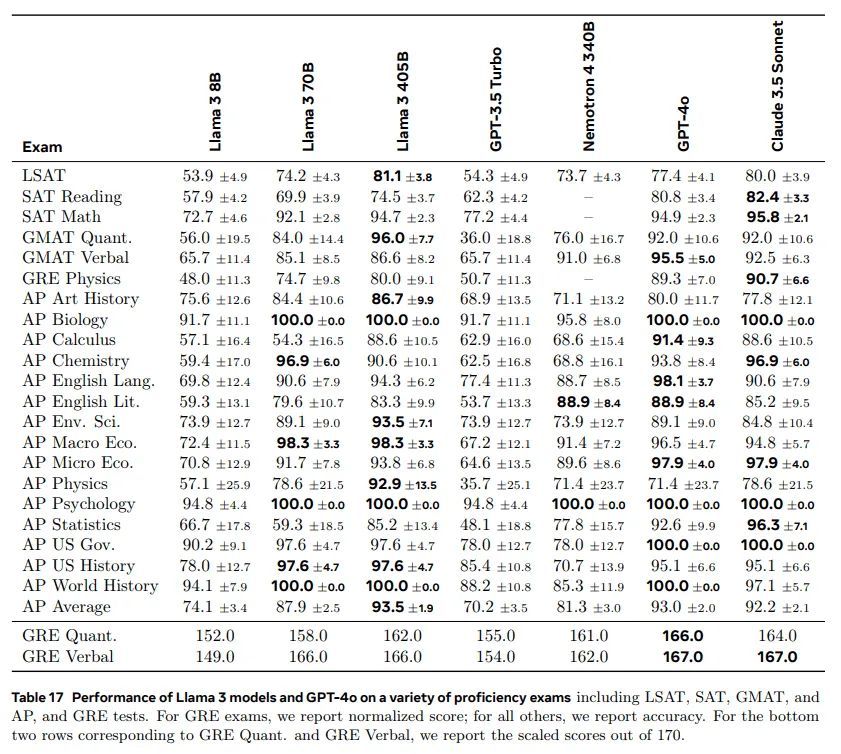
我们的结果见表 17。我们发现我们的 Llama 3 405B 模型的表现与 Claude 3.5 Sonnet 和 GPT-4 4o 非常相似。而我们的 70B 模型则展现出更为令人印象深刻的表现。它比 GPT-3.5 Turbo 显著更好,并在许多测试中超过了 Nemotron 4 340B。
5.2.3 编码基准
我们在多个流行的 Python 和多语言编程基准上评估 Llama 3 的代码生成能力。为了衡量模型生成功能正确代码的有效性,我们使用 pass@N 指标,该指标评估 N 个生成中的一组单元测试通过率。我们报告 pass@1 的结果。
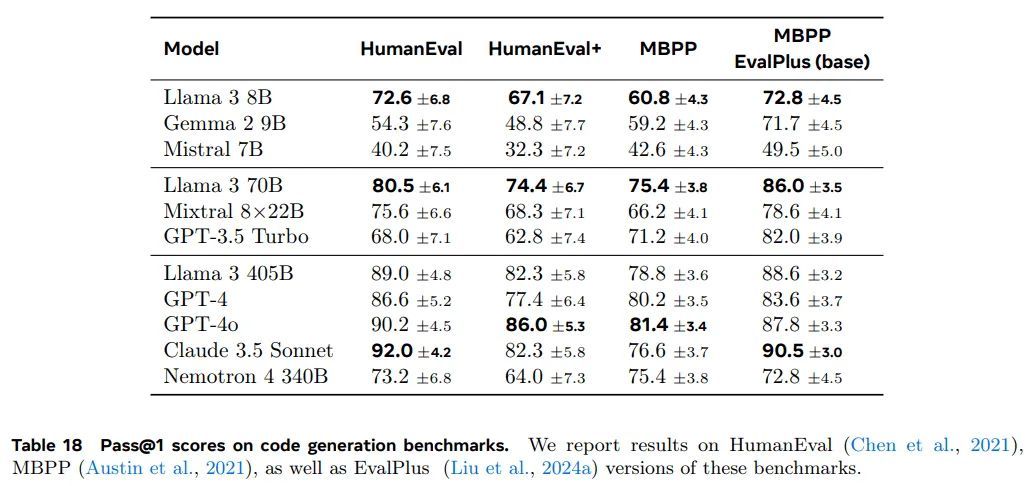
Python 代码生成。 HumanEval(Chen 等人,2021)和 MBPP(Austin 等人,2021)是流行的 Python 代码生成基准测试,它们侧重于相对简单、自包含的功能。HumanEval+(Liu 等人,2024a)是 HumanEval 的增强版本,其中生成了更多测试用例以避免假阳性。MBPP EvalPlus 基准版本 (v0.2.0) 是从原始 MBPP(训练和测试)数据集中的 974 个初始问题中选出的 378 个良好格式的问题(Liu 等人,2024a)。这些基准测试的结果如表 18 所示。在这些 Python 变体的基准测试中,Llama 3 8B 和 70B 表现优于相同规模的模型表现相似。对于最大的模型,Llama 3 405B、Claude 3.5 Sonnet 和 GPT-4o 表现类似,其中 GPT-4o 的结果最强。
模型: 我们将 Llama 3 与其他类似规模的模型进行了比较。对于最大模型 Llama 3 405B,Claude 3.5 Sonnet 和 GPT-4o 的表现相似,其中 GPT-4o 显示出最佳结果。
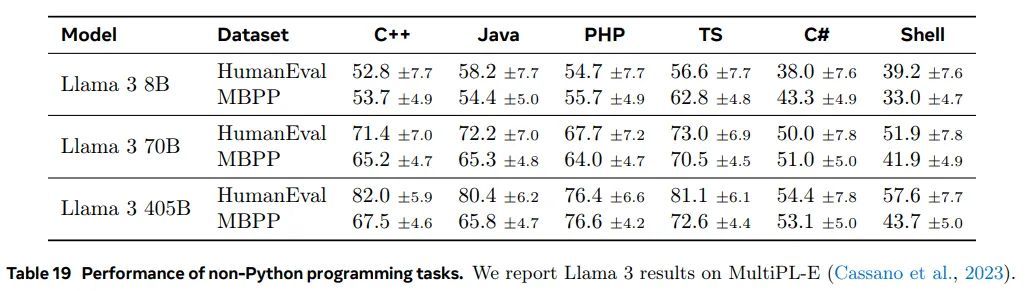
多编程语言代码生成: 为评估除 Python 之外的代码生成能力,我们报告了基于 HumanEval 和 MBPP 问题翻译的 MultiPL-E(Cassano 等人,2023)基准测试的结果。表 19 显示了一部分流行编程语言的结果。
请注意,与表 18 中的 Python 对应项相比,性能有显著下降。
5.2.4 多语言基准测试
Llama 3 支持 8 种语言 - 英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,尽管基础模型的训练使用了更广泛的语言集合。在 表20中 显示了我们在多语言 MMLU (Hendrycks 等人, 2021a) 和多语言小学数学 (MGSM) (Shi 等人, 2022) 基准测试上对 Llama 3 进行评估的结果。
多语言 MMLU: 我们使用 Google 翻译将 MMLU 的问题、少例示例和答案翻译成不同语言。我们将任务说明保留为英语,并在 5-shot 设置下进行评估。
MGSM (Shi 等人, 2022):对于我们的 Llama 3 模型,我们报告了 MGSM 的 0-shot CoT 结果。多语言 MMLU 是一个内部基准测试,其中包含将 MMLU (Hendrycks 等人, 2021a) 的问题和答案翻译成 7 种语言——我们报告的 5-shot 结果是跨这些语言的平均值。
对于 MGSM (Shi 等人, 2022),我们使用与 simple-evals (OpenAI, 2024) 中相同的原生提示来测试我们的模型,并将其置于 0-shot CoT 环境中。在表 20 中,我们报告了 MGSM 基准测试中包含的所有语言的平均结果。
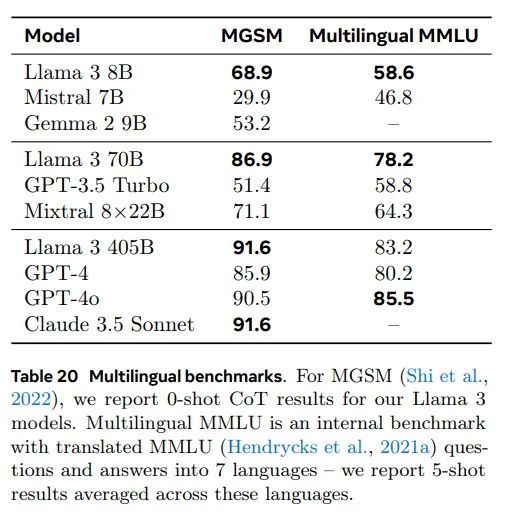
我们发现 Llama 3 405B 在 MGSM 上优于大多数其他模型,平均得分达到 91.6%。在 MMLU 上,与上述英语 MMLU 结果一致,Llama 3 405B 落后于 GPT-4o 2%。另一方面,Llama 3 的 70B 和 8B 模型都表现出色,在两个任务上均以较大优势领先于竞争对手。
5.2.5 数学和推理基准
我们的数学和推理基准测试结果如表2所示。Llama 3 8B模型在GSM8K、MATH和GPQA上都优于其他同等规模的模型。我们的70B模型在所有基准测试中均表现出显著优于同类模型的性能。最后,Llama 3 405B模型在其类别中是GSM8K和ARC-C最佳模型,而在MATH上,它是第二好的模型。在GPQA上,它与GPT-4 4o竞争激烈,而Claude 3.5 Sonnet以显著优势位列榜首。
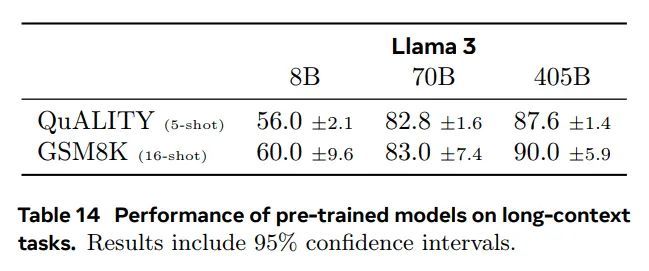
5.2.6 长上下文基准测试
我们考虑了一系列跨越不同领域和文本类型任务。在下面的基准测试中,我们专注于使用无偏评估协议的子任务,即基于准确性的指标而不是n-gram重叠指标。我们还优先考虑发现方差较低的任务。
Needle-in-a-Haystack (Kamradt, 2023) 衡量模型检索隐藏在长文档随机部分信息的能力。我们的Llama 3模型表现出完美的针检索性能,成功地在所有文档深度和上下文长度下检索到100%的“针”。我们还测量了Multi-needle(表 21)性能,这是一个Needle-in-a-Haystack的变化,其中我们将四根“针”插入上下文并测试模型是否可以检索其中的两根。我们的Llama 3模型实现了接近完美的检索结果。
ZeroSCROLLS (Shaham et al., 2023)是一个针对长文本自然语言理解的零样本基准测试。由于真实答案未公开提供,我们报告了验证集上的数字。我们的Llama 3 405B和70B模型在该基准测试的各种任务上与其他模型持平或超越它们。
InfiniteBench (Zhang et al., 2024) 要求模型理解上下文窗口中的长距离依赖关系。我们在En.QA(小说上的问答)和En.MC(小说上的多项选择问答)上评估Llama 3,其中我们的405B模型优于所有其他模型。增益在En.QA上尤为显着。
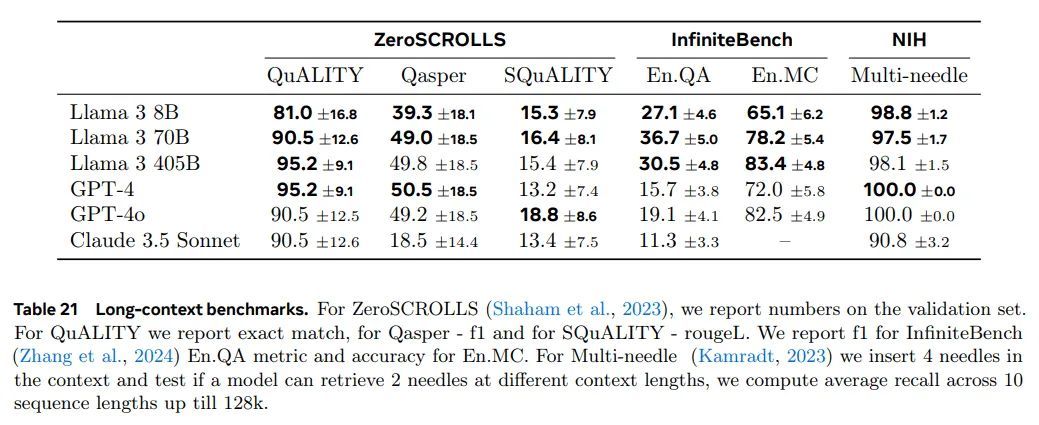
表 21 长文本基准测试。对于 ZeroSCROLLS(Shaham 等人,2023),我们报告的是验证集上的结果。对于 QuALITY 我们报告精确匹配,对于 Qasper - f1,对于 SQuALITY - rougeL。我们为 InfiniteBench(张等,2024)En.QA 指标报告 f1,并为 En.MC 报告准确率。对于 Multi-needle(Kamradt,2023),我们在上下文中插入 4 个针头,测试模型是否能够检索不同上下文长度的 2 个针头,我们计算最多 128k 的 10 个序列长度的平均召回率。
5.2.7 工具使用性能
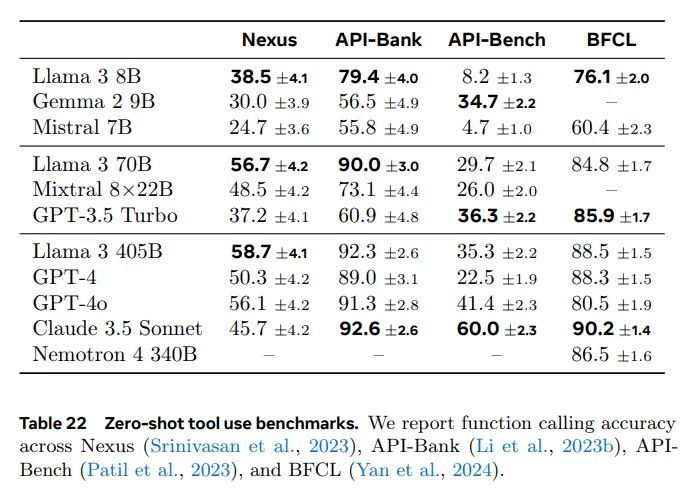
我们利用一系列零样本工具使用(即函数调用)基准测试评估了我们的模型:Nexus (Srinivasan 等人,2023)、API-Bank (Li 等人,2023b)、Gorilla API-Bench (Patil 等人,2023) 和 Berkeley 函数调用排行榜 (BFCL) (Yan 等人,2024)。结果如表 22 所示。
在 Nexus 上,我们的 Llama 3 变体表现最佳,优于其他同类模型。在 API-Bank 上,我们的 Llama 3 8B 和 70B 模型在相应类别中显着超越其他模型。405B 模型仅落后于 Claude 3.5 Sonnet 0.6%。最后,我们的 405B 和 70B 模型在 BFCL 上表现优异,并且在各自的规模类别中排名第二。Llama 3 8B 在其类别中表现最佳。
我们还进行人工评估以测试模型的工具使用能力,重点关注代码执行任务。我们收集了 2000 个与代码执行(不包括绘图或文件上传)相关的用户提示、绘图生成和文件上传。这些提示来自 LMSys 数据集 (Chiang 等人,2024)、GAIA 基准测试 (Mialon 等人,2023b)、人工标注者以及合成生成。我们将 Llama 3 405B 与 GPT-4o 进行比较,使用 OpenAI 的 Assistants API10 。结果如图 16 所示。在仅限文本的代码执行任务和绘图生成方面,Llama 3 405B 明显优于 GPT-4o。然而,在文件上传用例上,它落后于 GPT-4o。
5.3 人工评估
除了在标准基准数据集上的评估外,我们还进行了一系列人类评估。这些评估使我们能够测量和优化模型性能的更细微方面,例如模型的语气、冗长程度以及对细微差别和文化背景的理解。精心设计的 rengren 评估与用户体验密切相关,提供了有关模型在现实世界中表现的见解。
https://platform.openai.com/docs/assistants/overview
对于多轮人类评估,每个提示中的轮数在 2 到 11 之间。我们评估模型在最后一轮的响应。
提示收集。我们收集了高质量的提示,涵盖范围广泛的类别和难度。为此,我们首先开发了一个分类法,其中包含尽可能多模型能力的类别和子类别。我们使用这个分类法收集了约 7,000 个提示,涵盖六个单次能力(英语、推理、编码、印地语、西班牙语和葡萄牙语)和三个多轮能力11 (英语、推理和编码)。我们确保在每个类别中,提示在子类别之间均匀分布。我们还将每个提示分类为三个难度级别之一,并确保我们的提示集合包含大约 10% 的简单提示、30% 的中等难度提示和 60% 的困难提示。所有的人类评估图 16 Llama 3 405B 与 GPT-4o 在代码执行任务(包括绘图和文件上传)上的人类评估结果。Llama 3 405B 在代码执行(不包括绘图或文件上传)以及情节生成方面都优于 GPT-4o,但在文件上传用例方面落后。
提示集都经过了严格的质量保证流程。建模团队无法访问我们的人类评估提示,以防止意外污染或对测试集过度拟合。
评估过程。为了对两个模型进行成对的人类评估,我们会询问人类标注员他们更喜欢哪两个模型响应(由不同的模型产生)。标注员使用 7 分制评分,使他们能够表明一个模型响应是否比另一个模型响应好得多、更好、略好或大致相同。当标注员表示一个模型响应比另一个模型响应更好或好得多时,我们就会将其视为该模型的“胜利”。我们将对模型进行成对比较,并在提示集中报告每个能力的获胜率。
结果。我们使用人类评估过程将 Llama 3 405B 与 GPT-4(0125 API 版本)、GPT-4o(API 版本)和 Claude 3.5 Sonnet(API 版本)进行比较。这些评估的结果如图 17 所示。我们观察到 Llama 3 405B 的表现与 GPT-4 的 0125 API 版本大致相当,而与 GPT-4o 和 Claude 3.5 Sonnet 相比,结果参差不齐(一些胜利和一些失败)。在几乎所有能力上,Llama 3 和 GPT-4 的获胜率都在误差范围内。在多轮推理和编码任务中,Llama 3 405B 的性能优于 GPT-4,但在多语言(印地语、西班牙语和葡萄牙语)提示方面则不如 GPT-4。Llama 3 在英语提示上的表现与 GPT-4 相当,在多语言提示上与 Claude 3.5 Sonnet 相当,并在单轮和多轮英语提示上优于 Claude 3.5 Sonnet。然而,它在编码和推理等方面不及 Claude 3.5 Sonnet。从质上讲,我们发现模型在人类评估中的性能受到语气、响应结构和冗长程度等细微因素的很大影响——这些都是我们在后训练过程中正在优化的因素。总体而言,我们的人类评估结果与标准基准评估的结果一致:Llama 3 405B 与领先的行业模型竞争非常激烈,使其成为表现最佳的公开可用模型。
局限性。所有的人类评估结果都经过了严格的数据质量保证流程。然而,由于定义模型响应客观标准很困难,人类评估仍然可能会受到人类标注员的个人偏见、背景和偏好的影响,这可能导致不一致或不可靠的结果。
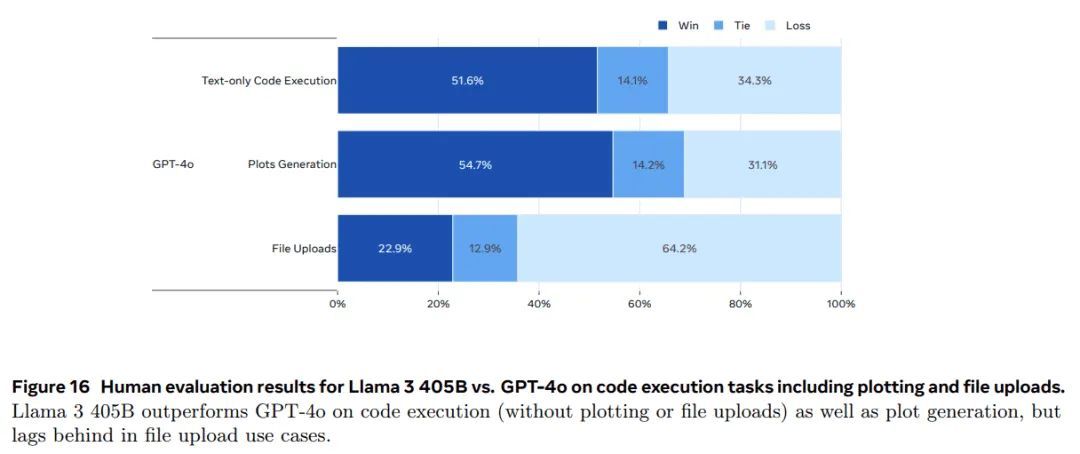
图 16 Llama 3 405B 与 GPT-4o 在代码执行任务(包括绘图和文件上传)上的人类评估结果。Llama 3 405B 在代码执行(不包括绘图和文件上传)以及绘图生成方面优于 GPT-4o,但在文件上传用例方面落后。
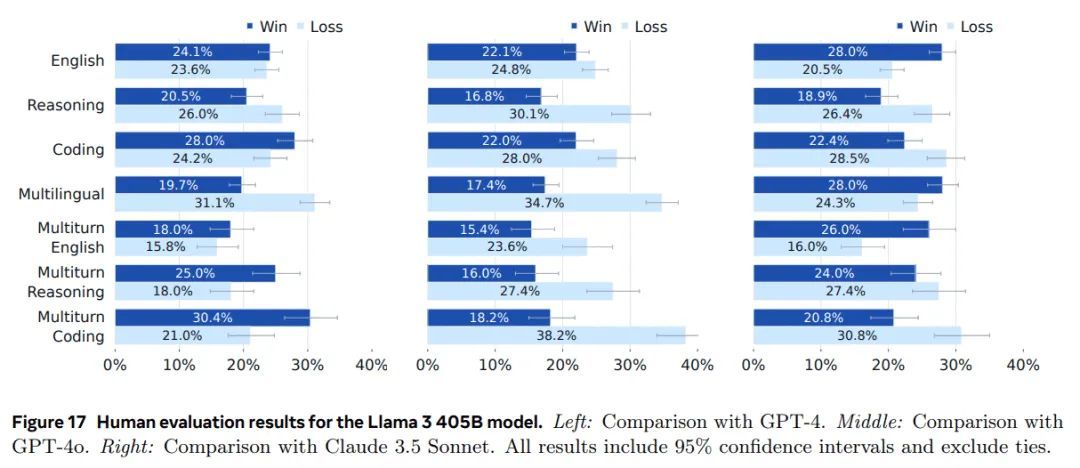
图 17 Llama 3 405B 模型的人工评估结果。左:与 GPT-4 的比较。中:与 GPT-4o 的比较。右:与 Claude 3.5 Sonnet 的比较。所有结果均包含 95% 置信区间,并排除平局。
5.4 安全性
涉及敏感词,下载全文PDF(7.4万字):https://www.aisharenet.com/llama-3yigeduoa/















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









