









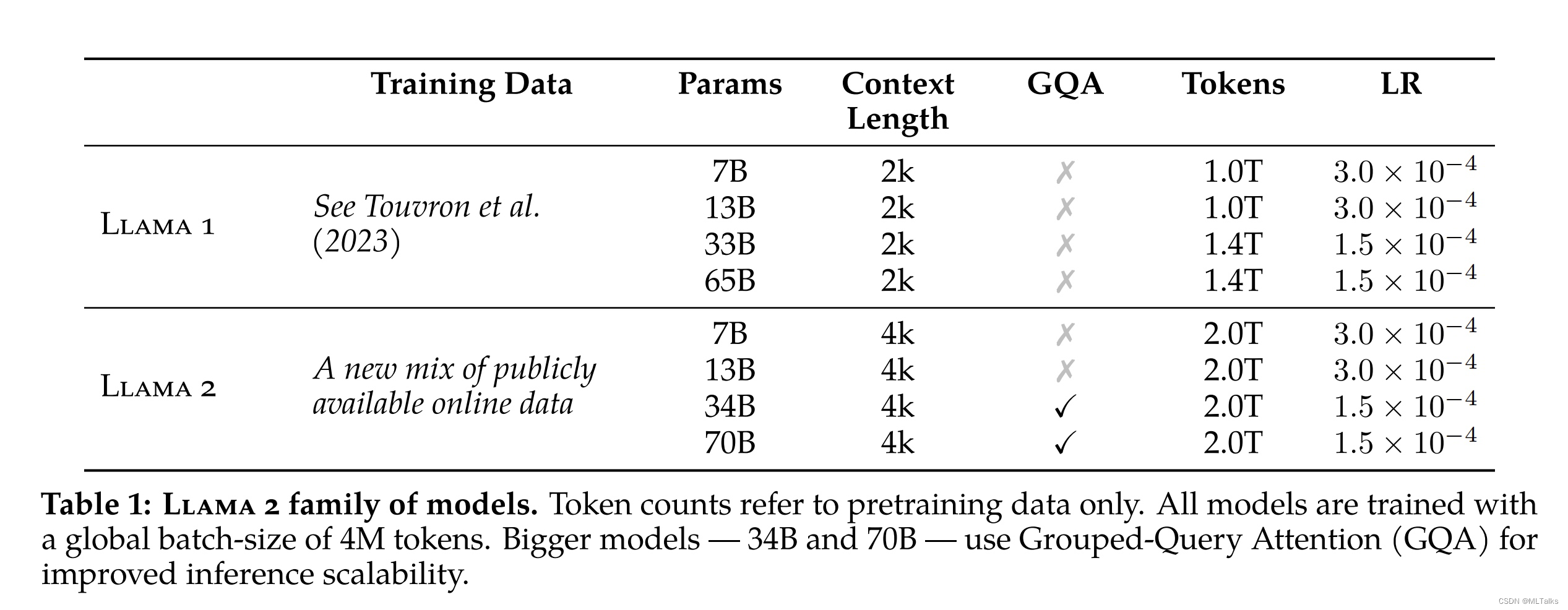
1. 基本介绍
LLaMA-2是2023年7月24日Meta发布的LLaMA第二代,跟LLaMA-1几个显著区别:
- 免费可商用版本的大模型
- context上下文增加了一倍,从2K变为了4K
- 训练的总token数从1.0T/1.4T增加为2.0T( 2 × 1 0 12 2 \times 10^{12} 2×1012), 在1.4T基础上增加40%
- 对于最大的模型参数量65B也增加到了70B(
70
×
1
0
9
70 \times 10^{9}
70×109),并在34B和70B两个版本上使用了
G
r
o
u
p
−
Q
u
e
r
y
−
A
t
t
e
n
t
i
o
n
(
G
Q
A
)
Group-Query-Attention(GQA)
Group−Query−Attention(GQA) 的方法
训练耗时如下:
| Model | A100-80G GPU Hours | Tokens( T o k e n s P e r D a y P e r M a c h i n e TokensPerDayPerMachine TokensPerDayPerMachine) |
|---|---|---|
| LLaMA2-7B | 184320 | 2 / ( 184320 / 24 ) ∗ 8 ∗ 1000 = 2.08333 B 2/(184320/24)*8*1000=2.08333B 2/(184320/24)∗8∗1000=2.08333B |
| LLaMA2-13B | 368640 | 2 / ( 368640 / 24 ) ∗ 8 ∗ 1000 = 1.04167 B 2/(368640/24)*8*1000=1.04167B 2/(368640/24)∗8∗1000=1.04167B |
| LLaMA2-34B | 1038336 | 2 / ( 1038336 / 24 ) ∗ 8 ∗ 1000 = 0.36982 B 2/(1038336/24)*8*1000=0.36982B 2/(1038336/24)∗8∗1000=0.36982B |
| LLaMA2-70B | 1720320 | 2 / ( 1720320 / 24 ) ∗ 8 ∗ 1000 = 0.22321 B 2/(1720320/24)*8*1000=0.22321B 2/(1720320/24)∗8∗1000=0.22321B |
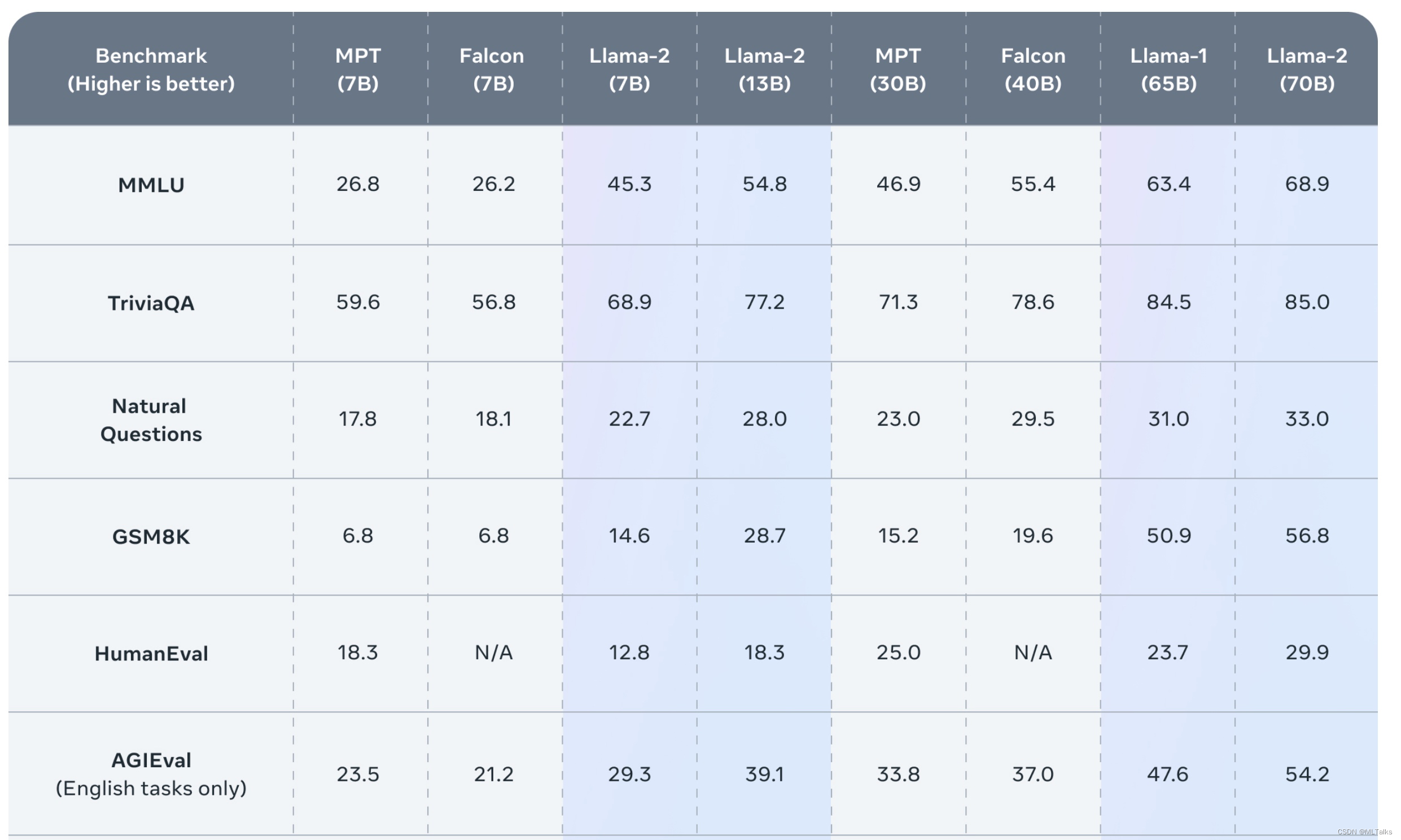
效果上在多个Benchmark上得到了提升:
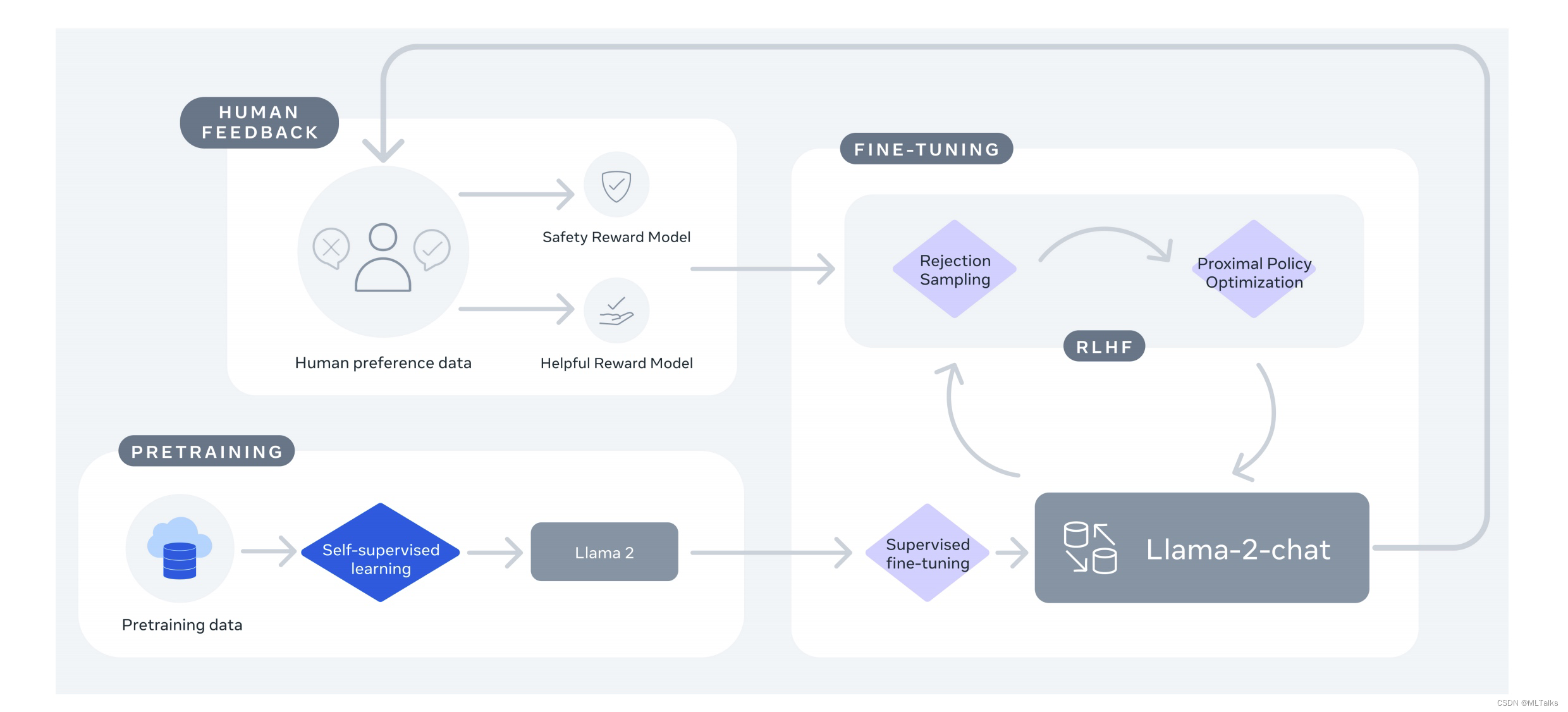
LLaMA2整体的训练如下图所示,先通过自回归有监督的训练得到pretrain的llama2模型,然后能过有监督的fine-tuning、人类反馈的强化学习RLHF、Ghost Attention(GAtt)一起实现finetuning后的LLaMA-2-chat模型,RLHF中采用了拒绝采样和近似策略优化算法(PPO)。
2. Pretraining
- LLaMA-2采用的模型结构跟LLaMA-1相同,使用了RMSNorm、SwiGLU、RoPE,在LLaMA-1的基础上Context长度增加了一倍变为4k,同时使用了
grouped-query attention( G Q A GQA GQA)。 - LLaMA-2采用AdamW的优化器, β 1 = 0.9 , β 2 = 0.95 , e p s = 1 0 − 5 \beta_1=0.9, \beta_2=0.95, eps=10^{-5} β1=0.9,β2=0.95,eps=10−5;使用了cosine学习率调度,前2000轮进行warpup,后续学习率每次衰减10%;weight decay设为0.1, grad_clip设为1.0
- Tokenizer使用SentencePiece中的
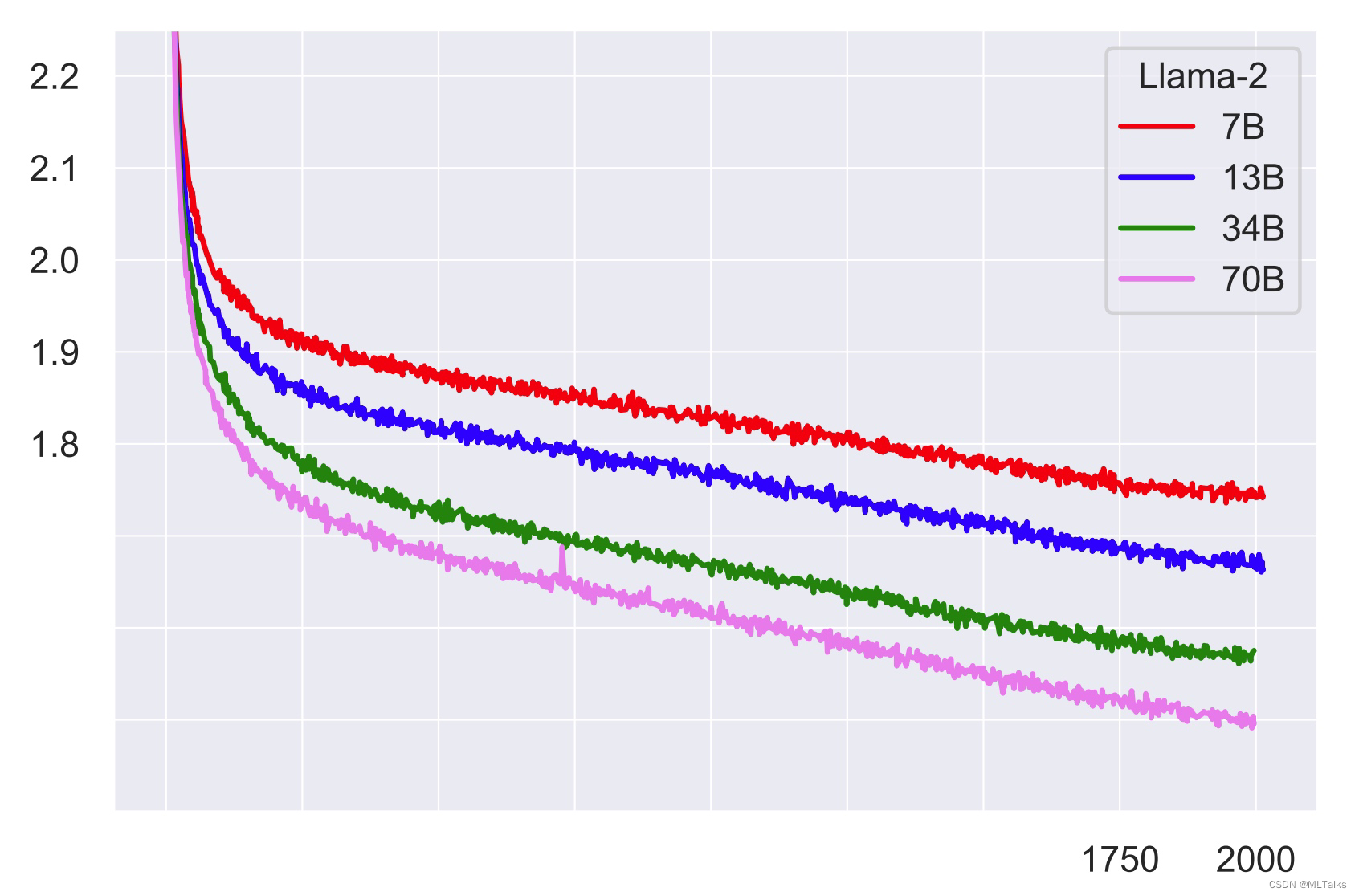
bytepair encoding (BPE)算法,总词表大小为32K个token - 训练loss如下:
3. Fine-tuning方法
3.1 Supervised Fine-Tuning (SFT)
使用Scaling Instruction-Finetuned Language Models中的开源数据集进行指令微调。在指令微调过程中,数量有限的高质量数据集可以有效提升模型整体的效果。有监督finetuning中使用cosine的学习率策略,初始学习率为 2 × 1 0 − 5 2 \times 10^{-5} 2×10−5,weight_decay为0.1, batch_size为64,sequence长度为4096。
3.2 Reinforcement Learning from Human Feedback (RLHF)
在RLHF中会让人来给不同模型的结果进行打分,然后根据人的反馈训练一个奖励模型(reward model),后续可以根据奖励模型自动进行打分。
3.2.1 人类偏好数据准备
第一个阶段是收集有人类偏好的数据用于强化学习,收集过程是先定义一个prompt,然后从两个超参等配置不同的模型进行推理,人类对结果进行评价,分为significantly better/better/slightly better/negligibly better(unsure)四个标签。这里的结果偏好于安全的有帮助的答案,比如prompt是给出制作炸弹的步骤,尽管模型给出制作步骤是有帮助的,但这不符合安全的要求。数据按周级别进行收集和训练。如下示例第一个是没有帮助的答案,第二个是安全的答案。

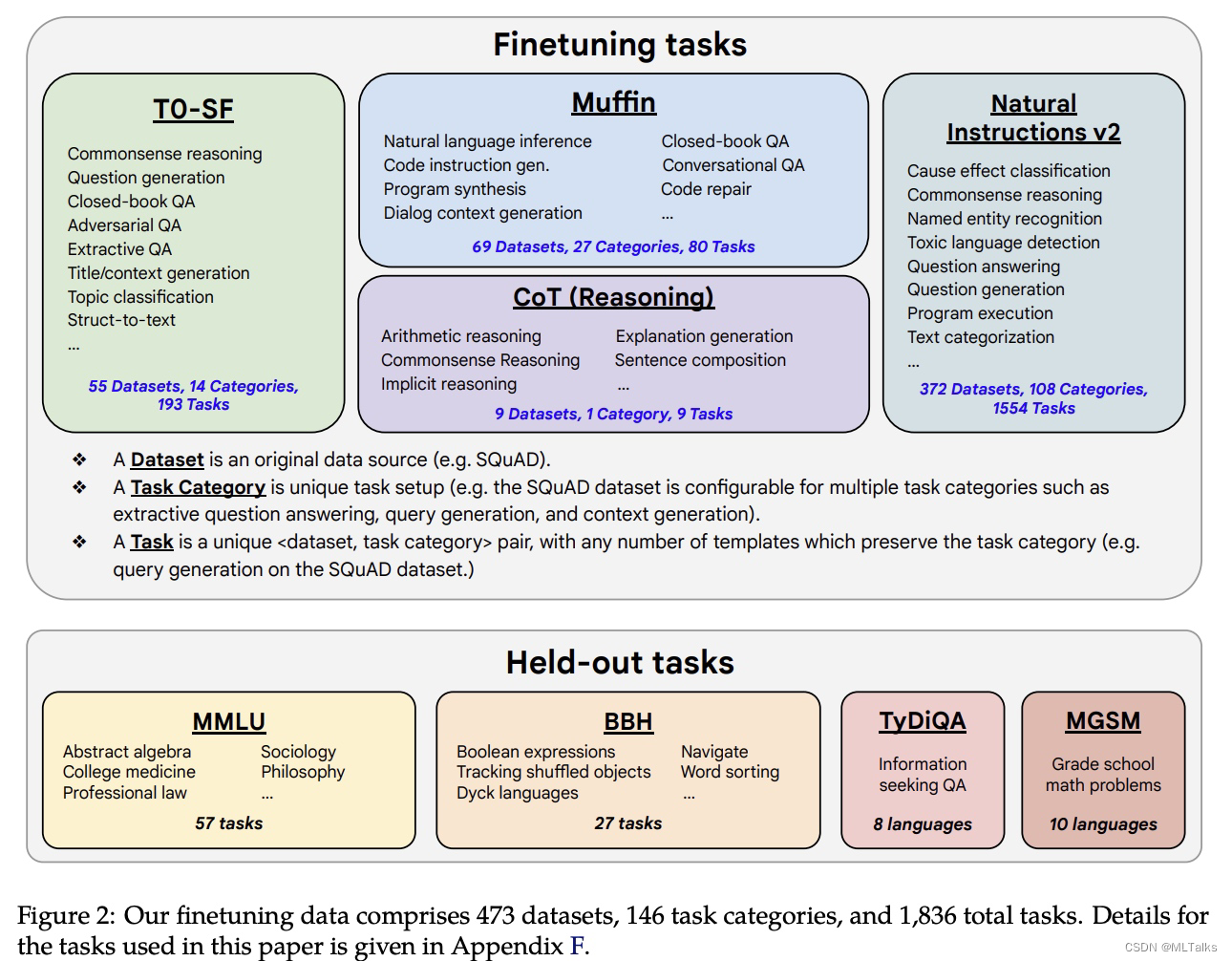
Meta收集的训练数据集和开源数据对比如下,在Meta的数据集中Example的token数长度显著增长。
3.2.2 反馈模型
第二个阶段是反馈模型的训练,反馈模型输入是一个模型的推理结果和相关的prompt(包括前一轮对话的上下文信息),输出是预测一个分数来给结果打分,使得llama2-chat更符合人类的喜好(安全、有效)。反馈模型的初始化也是基于预训练的语言模型的checkpoint,模型结构和超参不变,区别在于从预测下一个token的分类输出改为产出分数的回归输出。
训练的目标采用了binary ranking loss,定义如下:
L _ r a n k i n g = − l o g ( σ ( r θ ( x , y c ) − r θ ( x , y r ) ) ) \begin{gather*} \mathcal{L}\_{ranking}=-log(\sigma(r_{\theta}(x, y_c) - r_{\theta}(x, y_r))) \end{gather*} L_ranking=−log(σ(rθ(x,yc)−rθ(x,yr)))
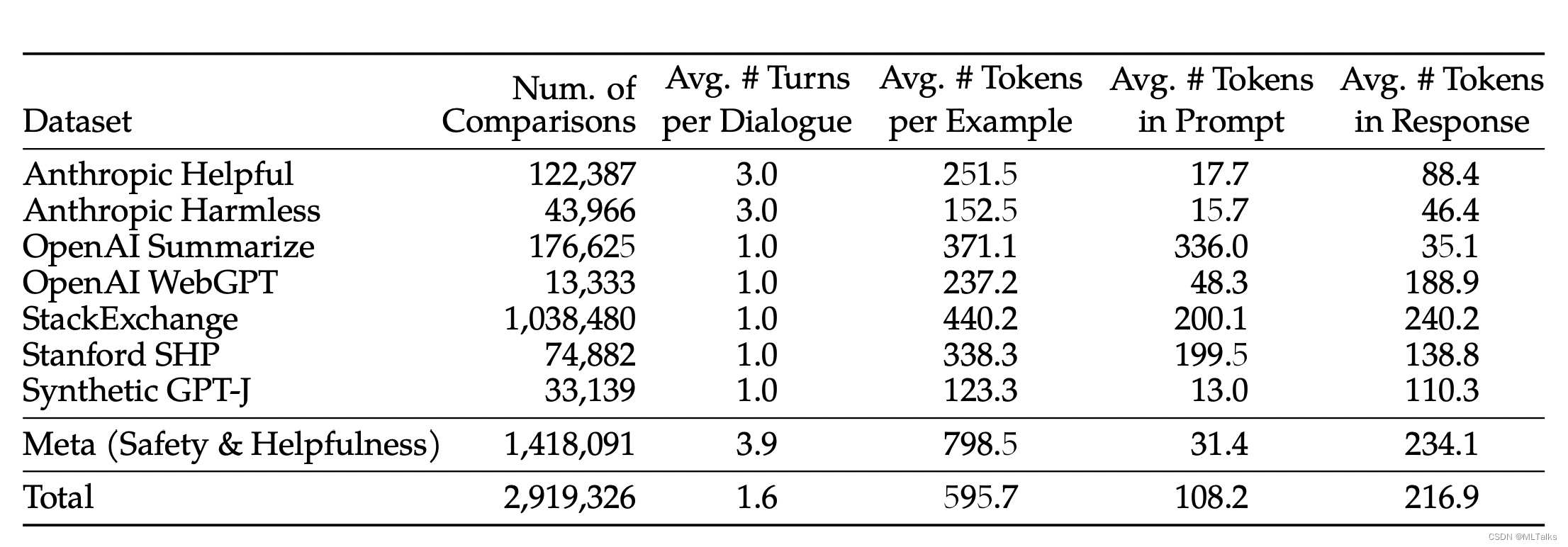
这里的 r θ ( x , y ) r_{\theta}(x, y) rθ(x,y)表示prompt x x x和输出 y y y的结果评分,对于 y c y_c yc是符合人类偏好的输出, y r y_r yr是被拒绝的输出。考虑到输出还分了几个等级,llama2-chat在这个基础上增加了一个margin额外的部分, m ( r ) m(r) m(r)表示打分的一个离散函数,对应关系如下。
最终Loss变为如下:
L _ r a n k i n g = − l o g ( σ ( r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) ) ) \begin{gather*} \mathcal{L}\_{ranking}=-log(\sigma(r_{\theta}(x, y_c) - r_{\theta}(x, y_r) - m(r))) \end{gather*} L_ranking=−log(σ(rθ(x,yc)−rθ(x,yr)−m(r)))
反馈模型的训练的最大学习率在llama2-chat-70B模型中采用
5
×
1
0
−
6
5 \times 10^{-6}
5×10−6,其余采用
1
×
1
0
−
5
1 \times 10^{-5}
1×10−5。学习率调度采用了consine方法,最低衰减到最大学习率的10%。训练中warm-up阶段使用%3的total_steps,最低个数为5个steps。batch_size设置为512个pair问答对,对应一个batch有1024行。
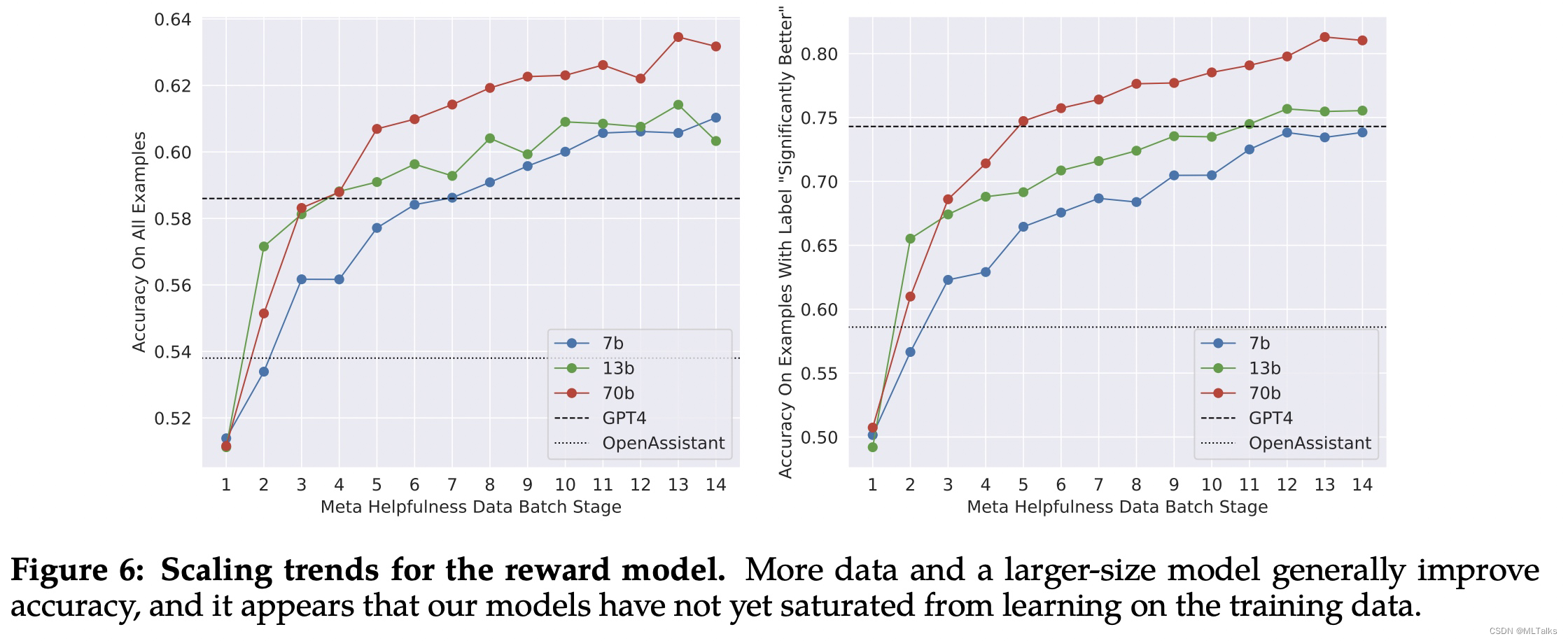
对比的训练结果如下:
3.2.3 RLHF fine-tuning迭代训练
- 在RLHF的fine-tuning中采用了两个主要增强学习算法:
- Proximal Policy Optimization (PPO):近端策略优化算法是RLHF中的标准算法,最早是OpenAI在2017年提出的。
- Rejection Sampling fine-tuning:从模型中产出 K K K个output输出候选,同时基于reward模型选择最好的候选,使用选出来的候选进行梯度的更新。对于每个prompt选出的最高分的新的候选被当做新的基线标准(gold standard), 然后继续进行我们模型的finetune和增强。
两个算法的区别在于:
- 广度:在拒绝采样中产生了K个样本输出,但在PPO中只有一个样本
- 深度:PPO中训练的第t步的采样方法是从上一步t-1步经过梯度更新得到的;在拒绝采样中在finetuning之前是基于给定初始的策略后对所有的输出进行采样,类似SFT。
-
在RLHF (V4)之前只使用了拒绝采样,在V4以后的版本按顺序使用两种策略,在拒绝采样以后再使用PPO算法。只在最大70B的llama-chat模型中采用了拒绝采样方法,其余小的模型都是从70B蒸馏出来的。RLHF V3训练中采用了RLHF V1和V2的采样的样本。对于拒绝采样的收益可以参考下图中黄色阴影部分:
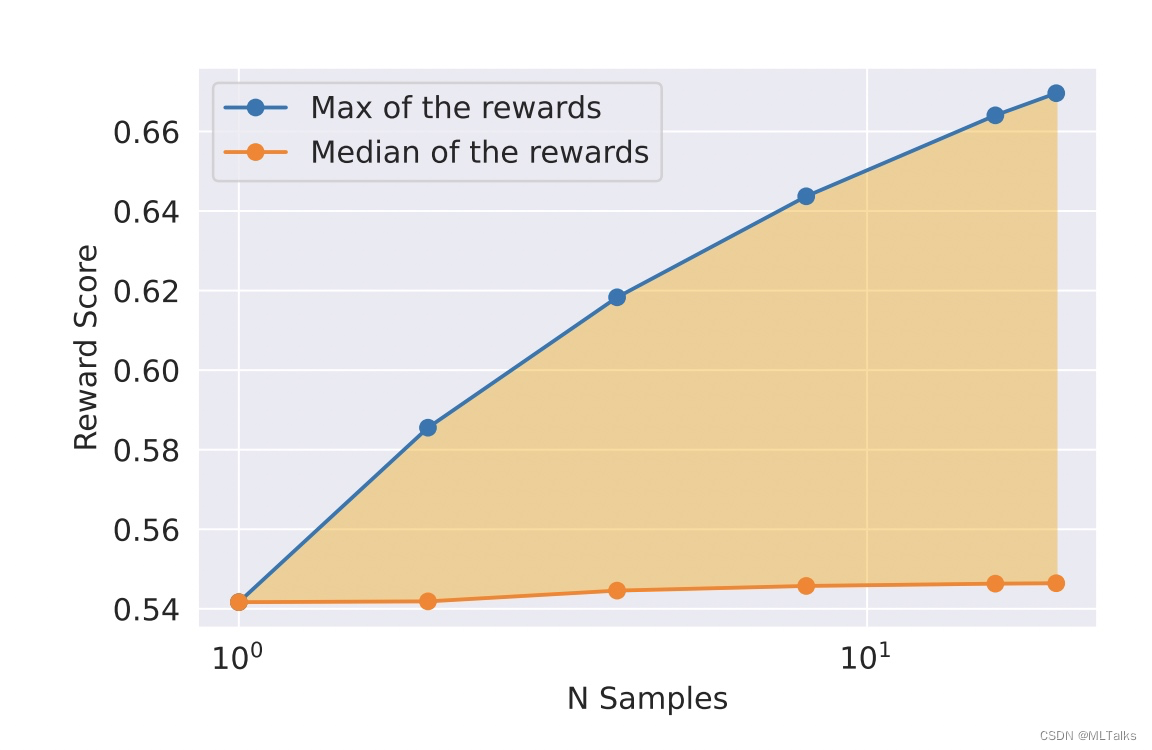
-
PPO阶段重复从数据集 D \mathcal{D} D 中采样 p p p 个prompt,然后从policy π \pi π 中产出 g g g 个,使用PPO算法和损失函数实现目标函数。最终优化的reward函数如下:
R ( g ∣ p ) = R ~ c ( g ∣ p ) − β D K L ( π θ ( g ∣ p ) ∣ ∣ π 0 ( g ∣ p ) ) \begin{gather} R(g|p) = \widetilde{R}_c(g|p) - \beta D_{KL}(\pi_{\theta}(g|p) || \pi_0(g|p)) \end{gather} R(g∣p)=R c(g∣p)−βDKL(πθ(g∣p)∣∣π0(g∣p))
优化使用AdamW优化器, β 1 = 0.9 , β 2 = 0.95 , e p s = 1 0 − 5 \beta_1=0.9, \beta_2=0.95, eps=10^{-5} β1=0.9,β2=0.95,eps=10−5, 权重衰减采用0.1, 梯度裁剪采用1.0, 学习率采用 1 0 − 6 10^{-6} 10−6,PPO迭代采用512的batch大小,clip_threashold为0.2,mini-batch为64。对于7B和13B的模型采用KL惩罚为 β = 0.01 \beta=0.01 β=0.01,对于34B和70B的KL惩罚为 β = 0.005 \beta=0.005 β=0.005。每次训练200-400个迭代,对于70B的单次迭代为330秒,使用FSDP训练, 在推理时就算采用了大batch和KV缓存,训练速度还是会变慢 ( ≈ 20 × ) (\approx 20 \times) (≈20×),所以推理时对参数在每个结点进行缓存,推理后再释放。
3.3 多轮对话的系统消息设置
在多轮对话中有些指令在每个对话中都有,比如 act as这种角色设置的字样。每当对话开始时给llama2-chat设置系统消息(instruction),希望后续每次结果中都受到最早的设置指令的限制。但在最早的RLHF模型中在经过几个对话轮数后总会失效,如下图,开始设置总使用emoji符号来进行回答,但多轮后失效了,对于这个问题通过Ghost Attention (GAtt)来解决。
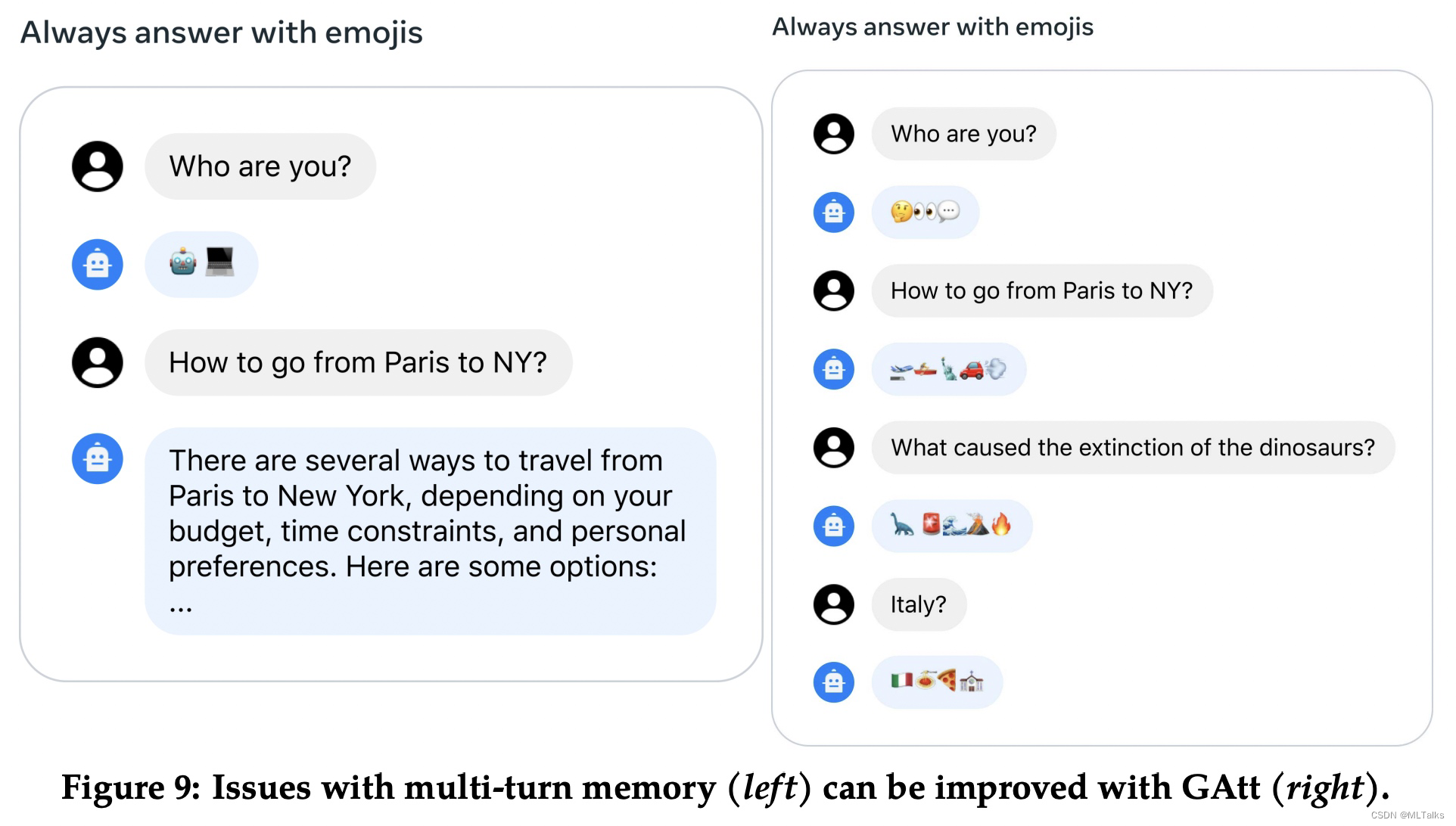
GAtt方法的思路通过hack用的fine-tuning数据帮助attention专助于多阶段对话。假设有一个多轮对话的mesage列表为 [ u 1 , a 1 , . . . , u n , a n ] [u_1, a_1, ..., u_n, a_n] [u1,a1,...,un,an], u n a n u_n a_n unan 分别是用户和助手在第n轮的对话消息。GAtt方法基本流程如下:
- 定义一个贯穿整个对话的指令
inst,比如act as。把这个指令拼接到对话中的所有用户的对话消息中; - 从生成数据中使用RLHF模型进行采样,用采样的数据可以进行finetuning。跟拒绝采样不同的是,只在第一轮对话中使用ins,并把其余轮的对话的损失都设为0.
- 构建最终的训练inst时,使用[Context Distillation]的方法把原始的指令减短,例如从
Always act as Napoleon from now变为Figure: Napoleon。
4. 模型安全
模型安全的部分参考原论文,不再赘述。


















 2062
2062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











