







论文笔记--Llama3 report
1. 文章简介
- 标题:Llama3 Report
- 作者:Meta
- 日期:2024.04
2. 性能升级
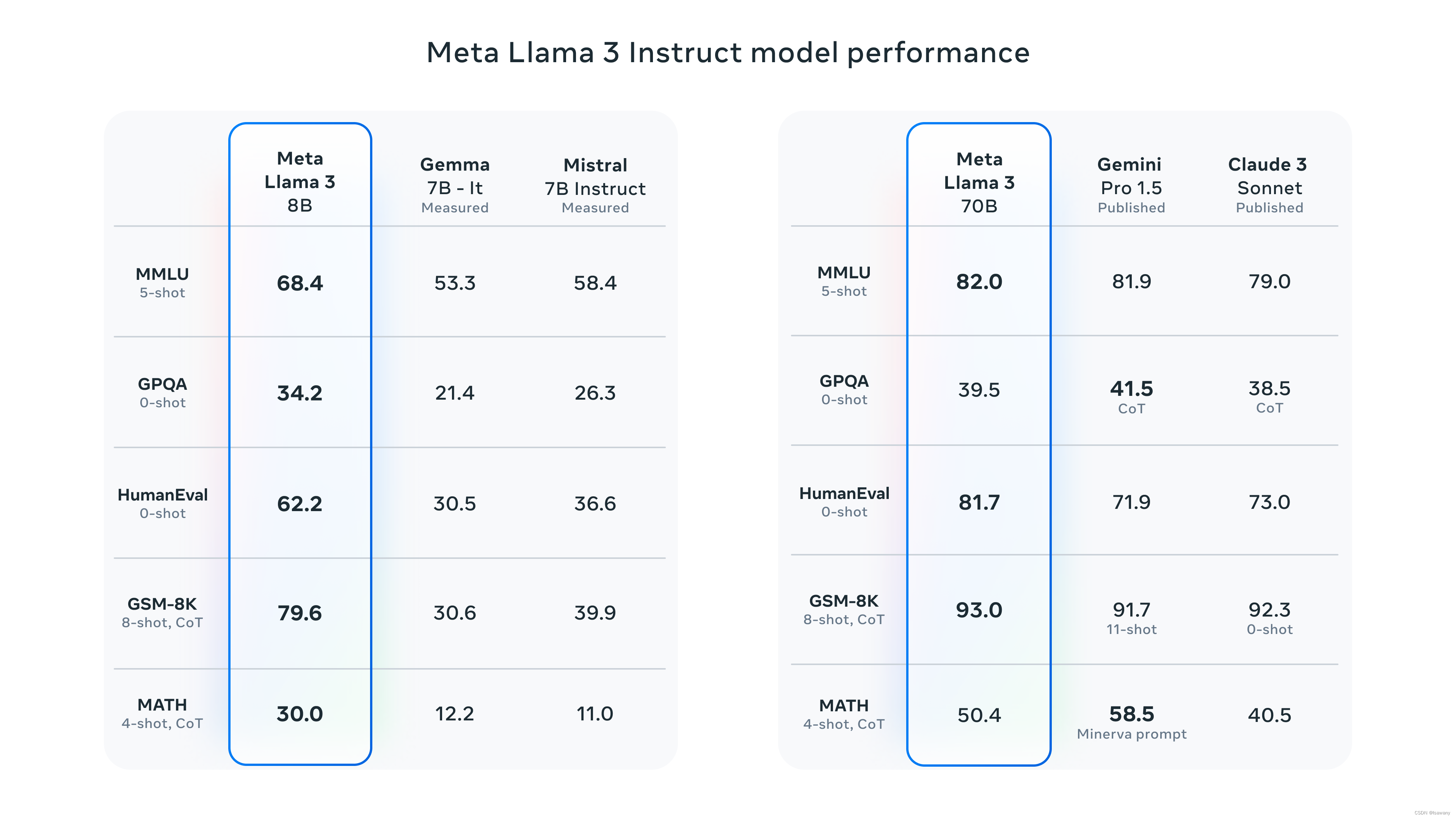
Llama3系列本次开源了8B和70B模型,在多个benchmarks上取得了SOTA表现。具体评估细节可以参见github
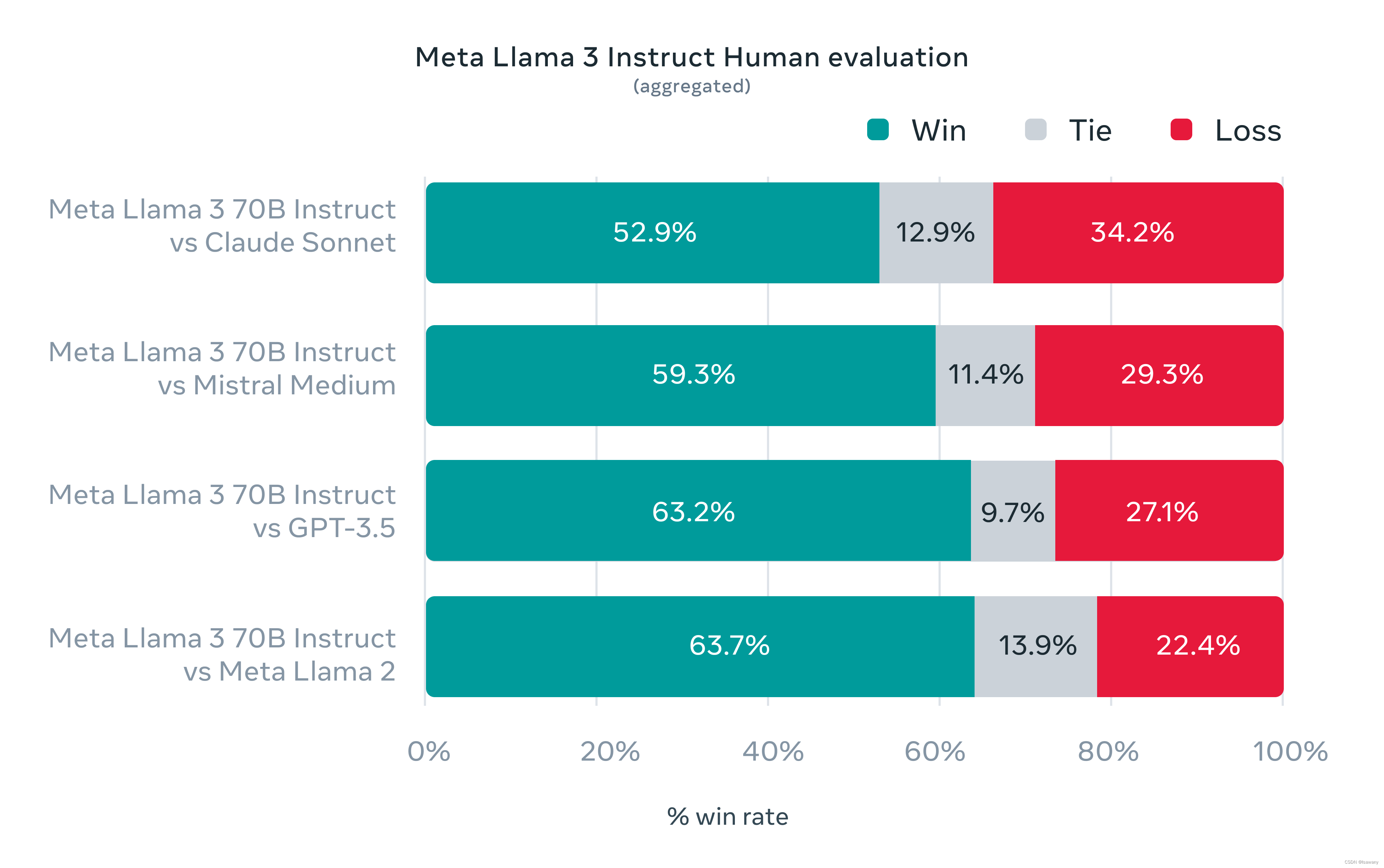
本次验证增加了高质量的人工评估集,涵盖12种场景(寻求建议、头脑风暴、分类、闭源QA、编码、创意写作、信息抽取、角色扮演、开放QA、推理、重写、摘要)共计1800个prompts。Llama3在这些prompts上表现超过GPT-3.5等模型:
3. 模型升级
3.1 模型架构升级
相比于Llama2[1],Llama3在模型架构上没有明显改变,仍采用transformer的decoder架构,模型架构升级如下
- 词表大小由32K升级为128K
- 采用GQA编码(Llama2也采用了GQA)
- 上下文长度从4K增加为8k(8192)个t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









