






 本文详细介绍了如何使用Xtuner进行大语言模型的微调,包括理论讲解(微调必要性、范式及适用场景)、XTuner的实战操作、多模态升级方法以及显存优化技术。重点讨论了全参数微调、LoRA和QLoRA微调方案,以及如何在8GB显存下有效利用资源。
本文详细介绍了如何使用Xtuner进行大语言模型的微调,包括理论讲解(微调必要性、范式及适用场景)、XTuner的实战操作、多模态升级方法以及显存优化技术。重点讨论了全参数微调、LoRA和QLoRA微调方案,以及如何在8GB显存下有效利用资源。
本次课程包括理论和实践两大部分,学习如何使用Xtuner微调大语言模型(LLM),比如1.8B参数的模型,以及为什么要微调大语言模型,微调模型的基本流程。
首先,理论部分解释了微调的必要性、两种微调范式(增量预训练和指令微调)以及它们的适用场景。实战部分手把手教大家如何使用Xtuner工具,从创建配置文件、准备数据到启动训练。我们了解到LAURA和QLAURA微调方案对于减少显存开销的重要性。课程还介绍了如何将单模态语言模型升级为多模态,通过添加图像识别功能,使得模型能理解并回应与图片相关的对话内容。最后,通过实战操作,展示了微调前后的模型在回答问题上的显著差异。
一、为什么要微调?
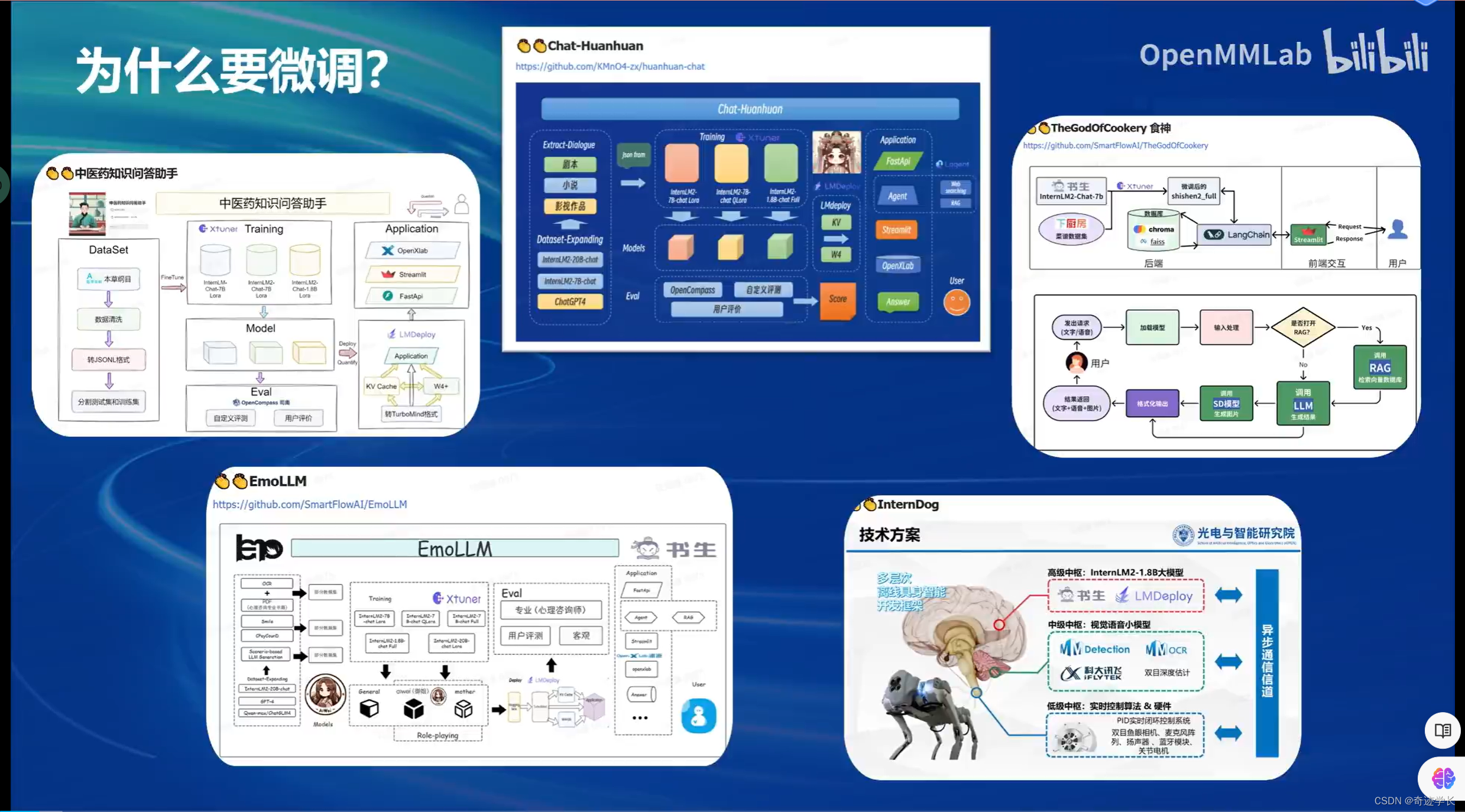
1. 适应特定任务或领域:虽然预训练的模型通常具有广泛的知识和理解能力,但它们可能不完全适应特定任务的需求。通过在特定的数据集上微调模型,可以使模型更好地理解和处理与特定任务或领域相关的数据。
2. 提高性能:微调可以帮助模型在特定任务上表现得更好,如通过调整模型参数以更精确地对任务特有的特征进行建模,从而提高分类准确率、生成的质量或其他性能指标。
3. 节省资源:微调一个已经训练好的模型通常只需要较少的数据和训练周期。
4. 减少数据需求:微调通常需要的数据量比全新训练模型少得多。这对于数据较少的应用场景特别有用,因为即使是小规模的数据集也可能足以通过微调达到良好的效果。
5. 转移学习:微调是一种有效的转移学习策略,允许模型将在一个任务上学到的知识应用到其他类似任务上。这种策略在多任务学习和跨领域应用中尤其重要。
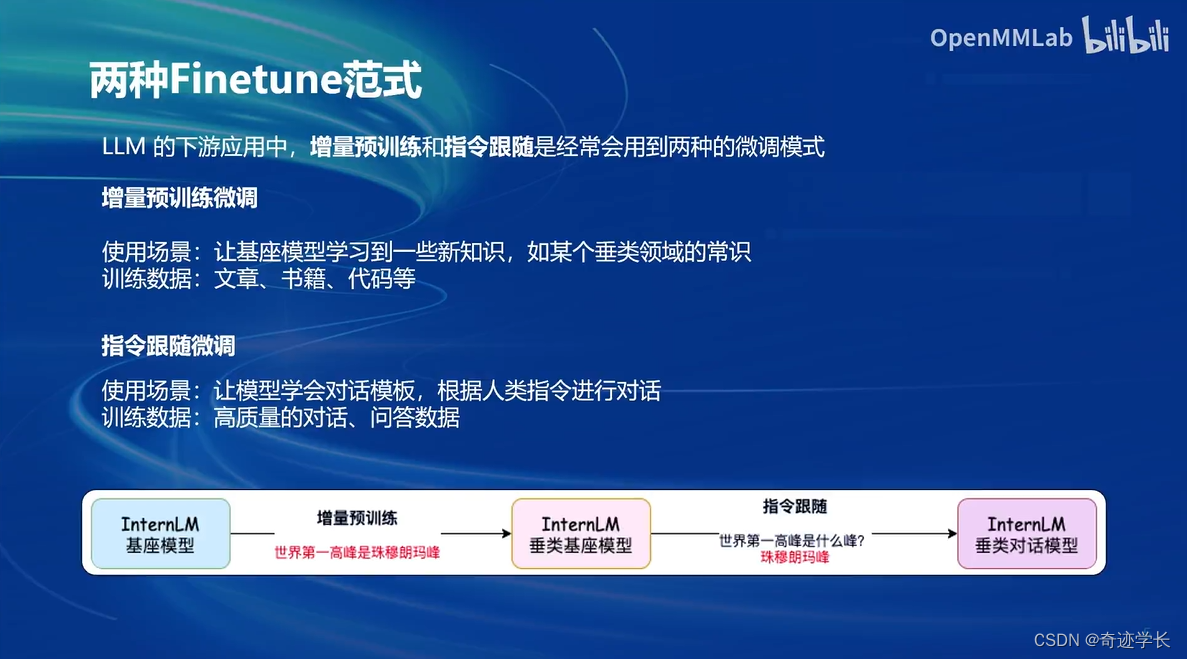
1,Finetune简介
- 两种Finetune范式
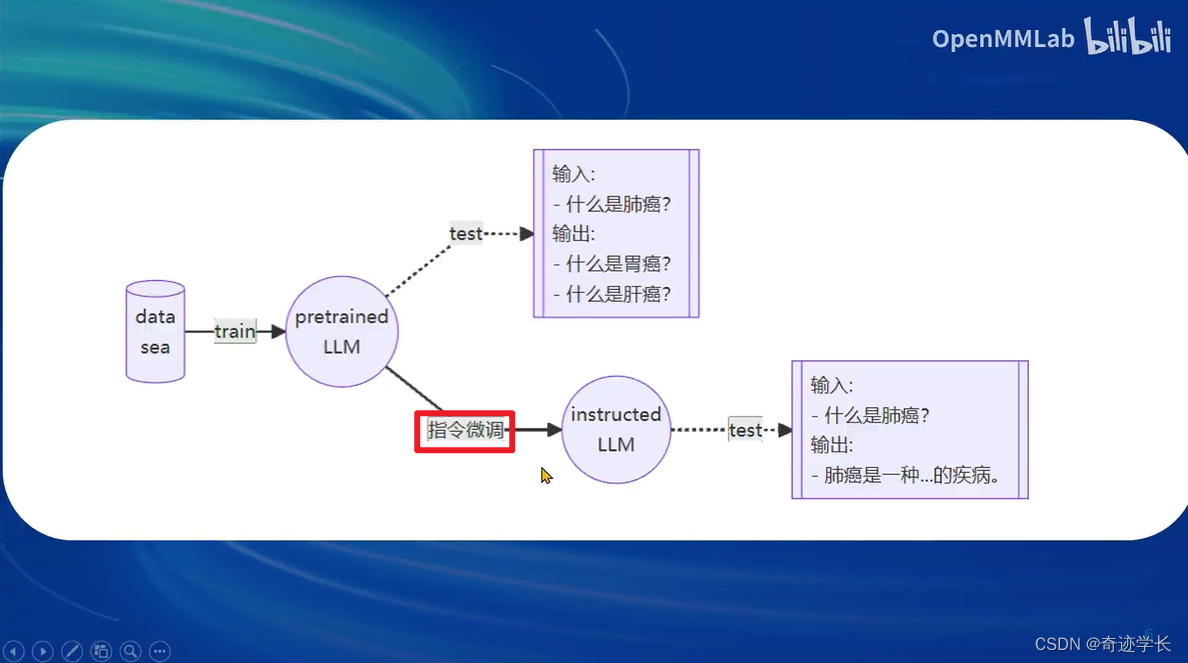
- 一条数据的一生
- 增量预训练微调
- 指令跟随微调

微调方案
基座模型不变
在基座模型上微调一个LoRA模型。
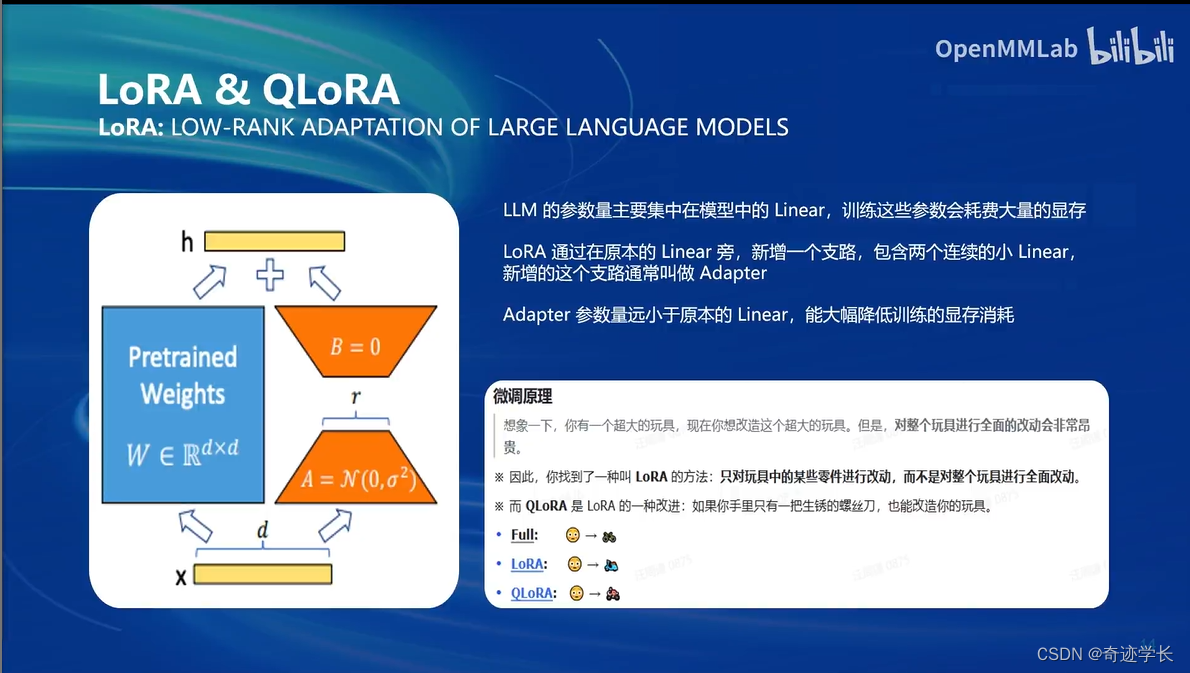
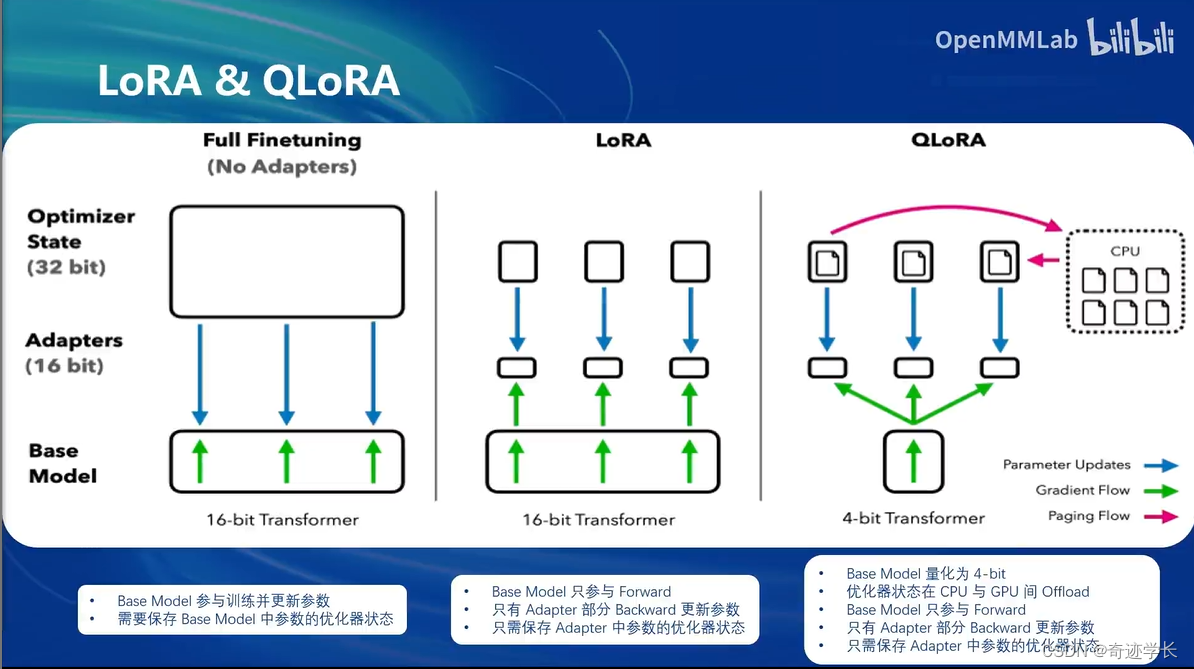
Full Finetuning 全参数微调:整个模型加载到显存中。所有模型参数的优化器,也要加载到显存中。
LoRA 微调:整个模型加载到显存中,对于参数优化器,我们保留LoRA部分的参数优化器
QLoRA 微调:模型本身加载到显存中的时候,就已经使用4bit量化的方式,不那么精确的方式加载。
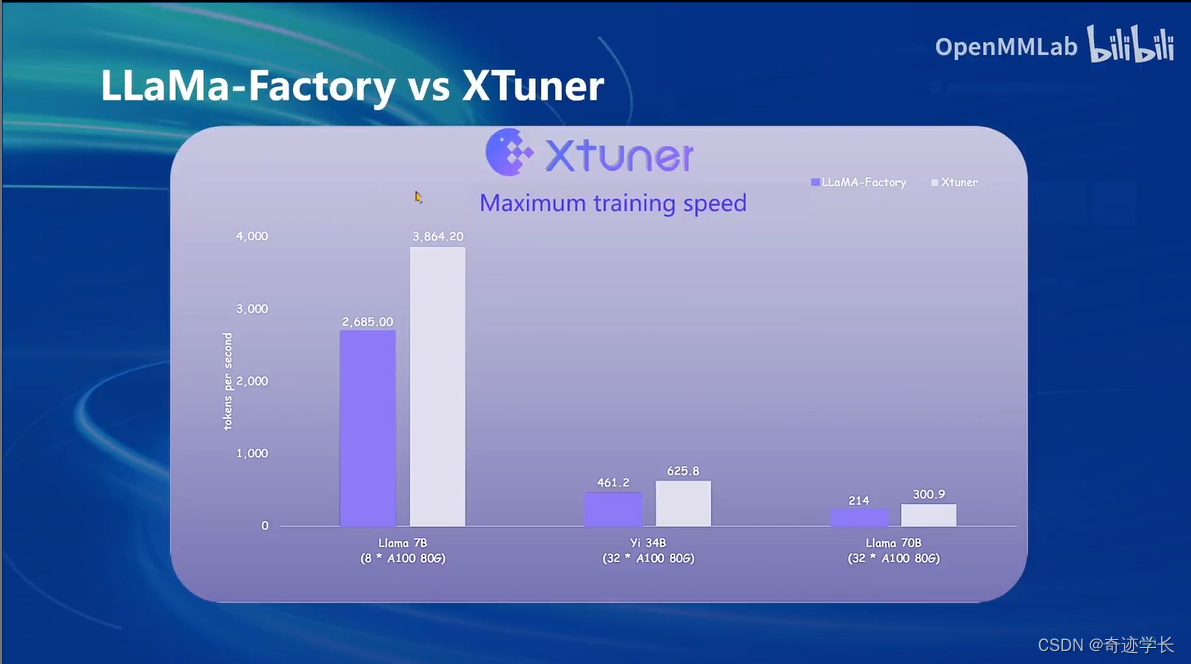
二、XTuner


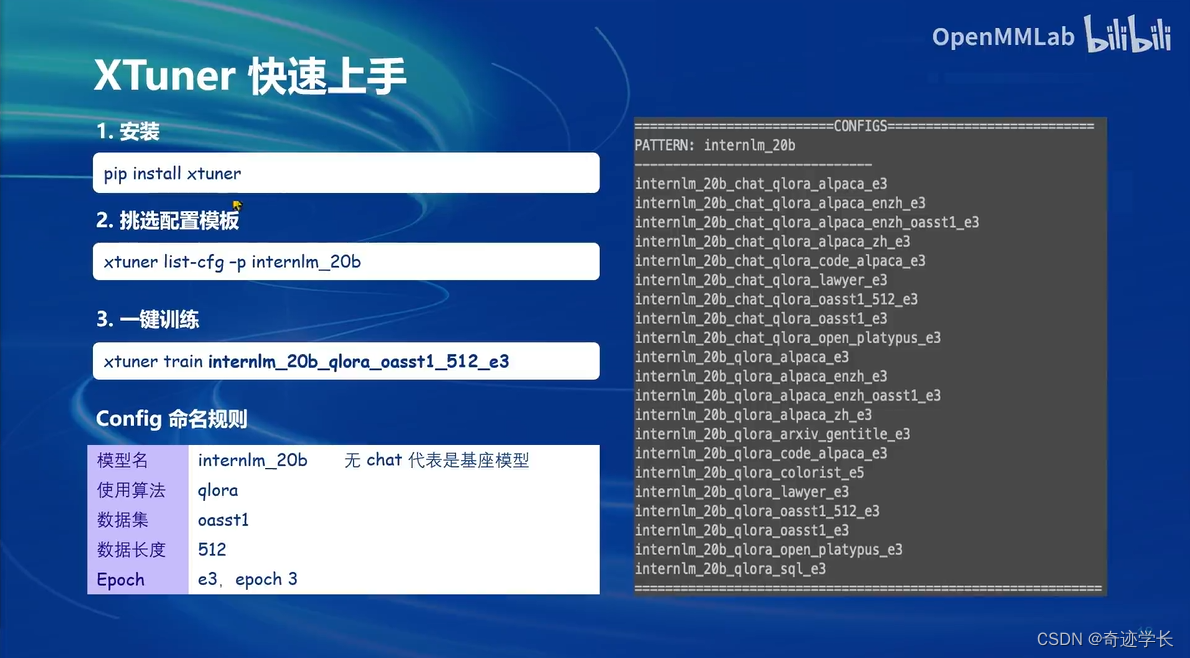
具体操作:XTuner快速上手

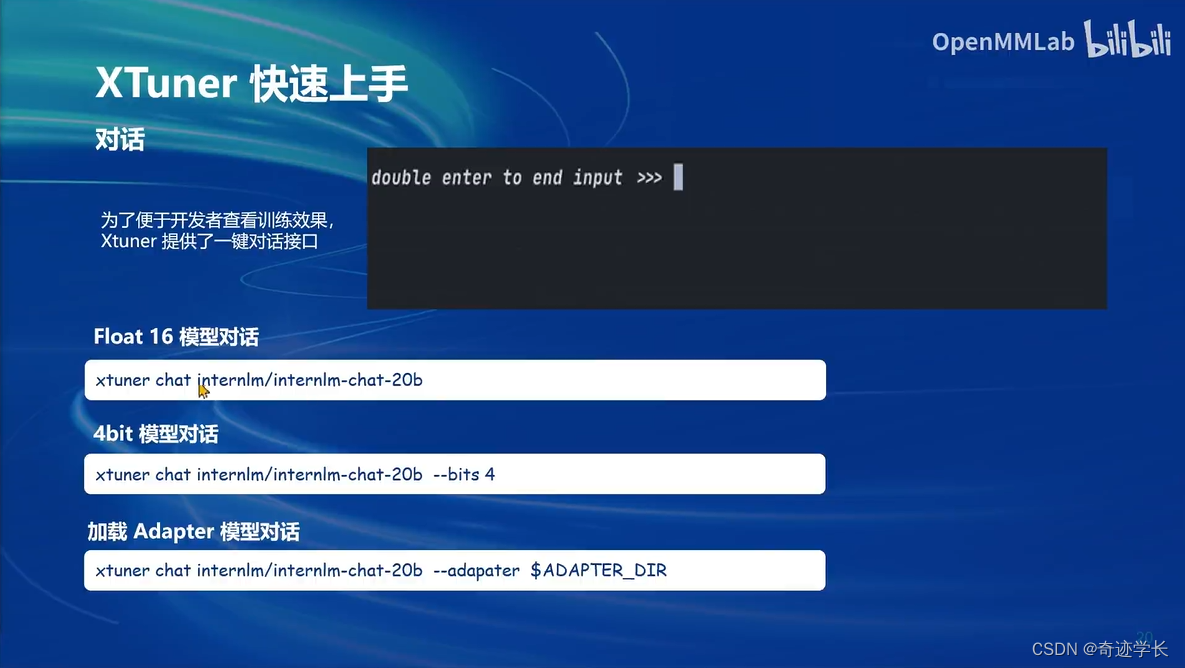
工具类模型的对话

XTuner数据引擎


多数据样本拼接,增加并行性,充分利用gpu资源
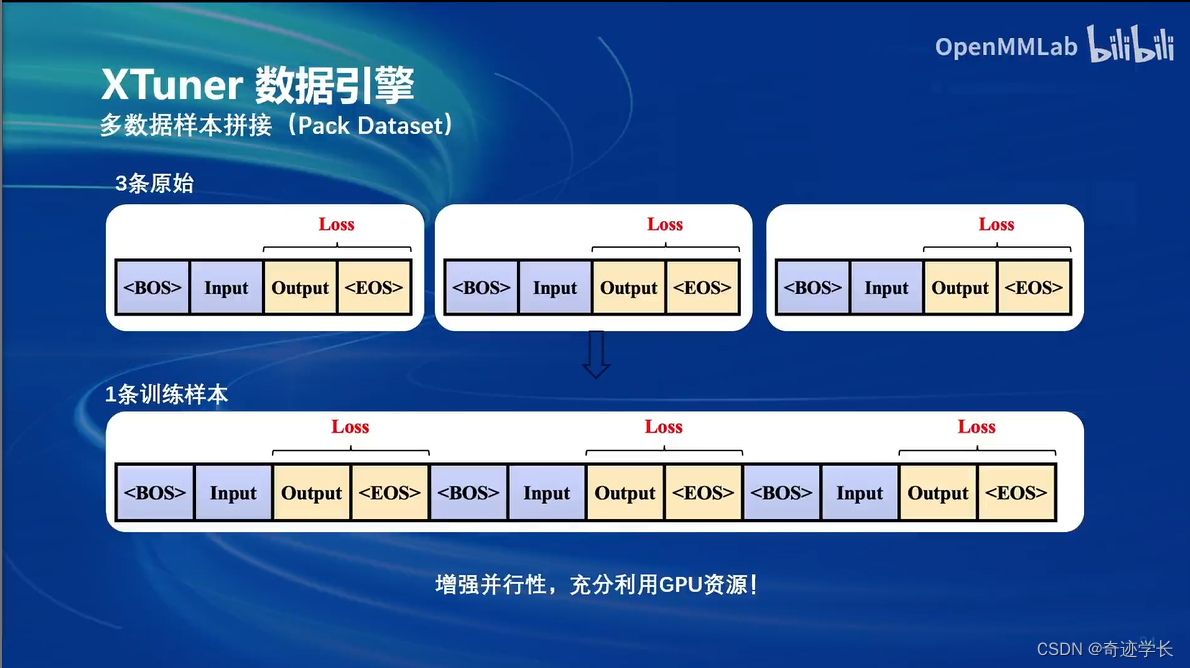
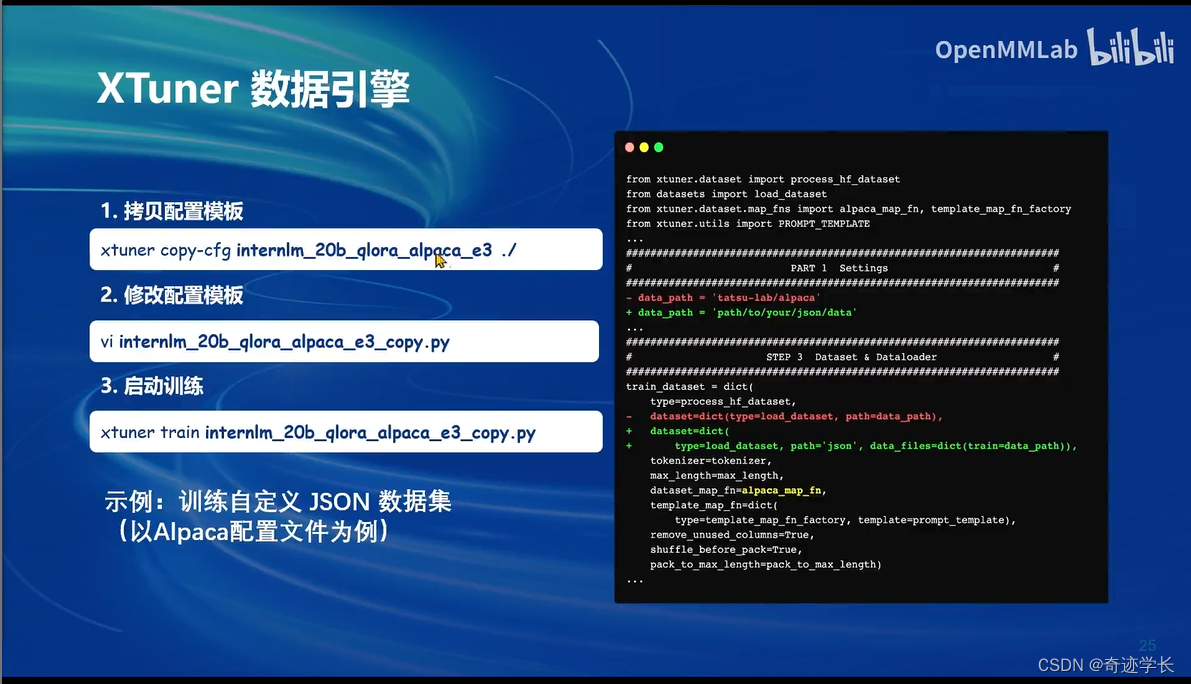
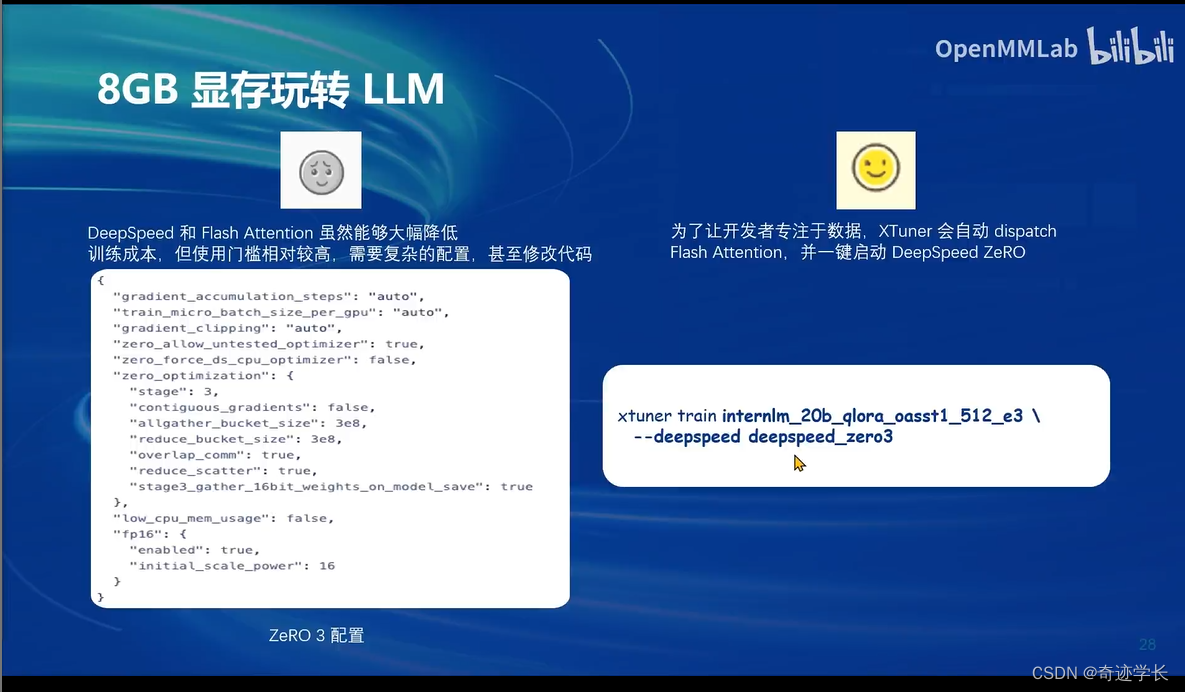
三、8GB显存玩转LLM
XTuner中内置的两种加速方式:
1、Flash Attention (已自动开启,无视即可)
2、DeepSpeed ZeRO

优化前 vs 优化后:
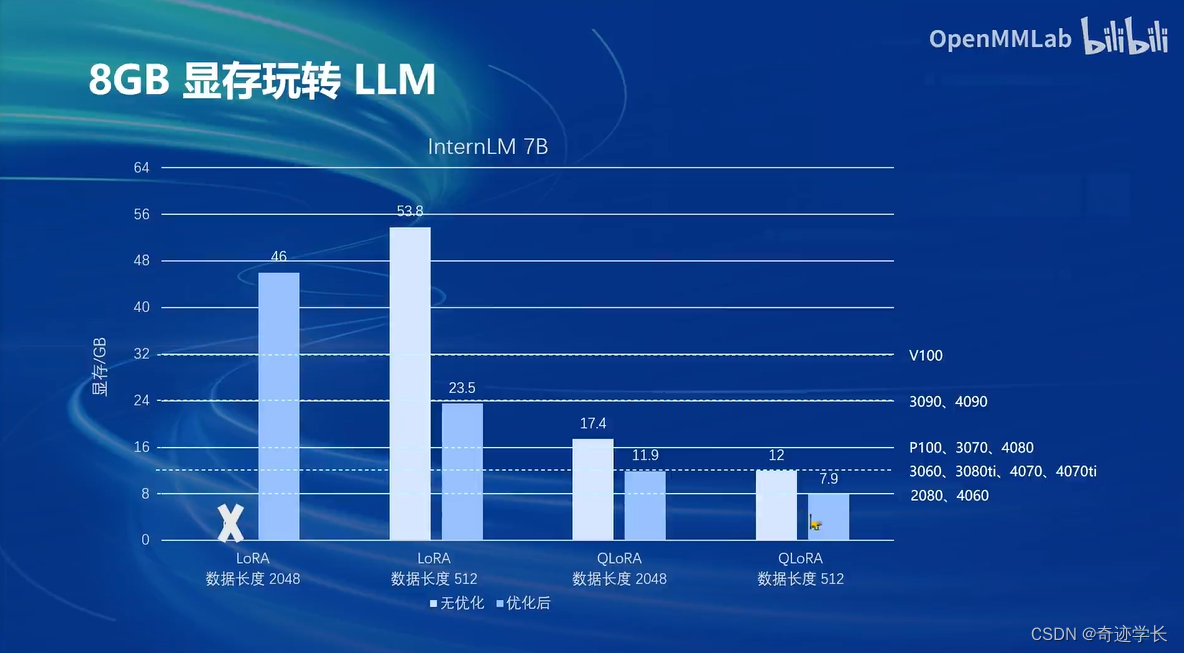
InternLM2 1.8B 模型

五、多模态LLM

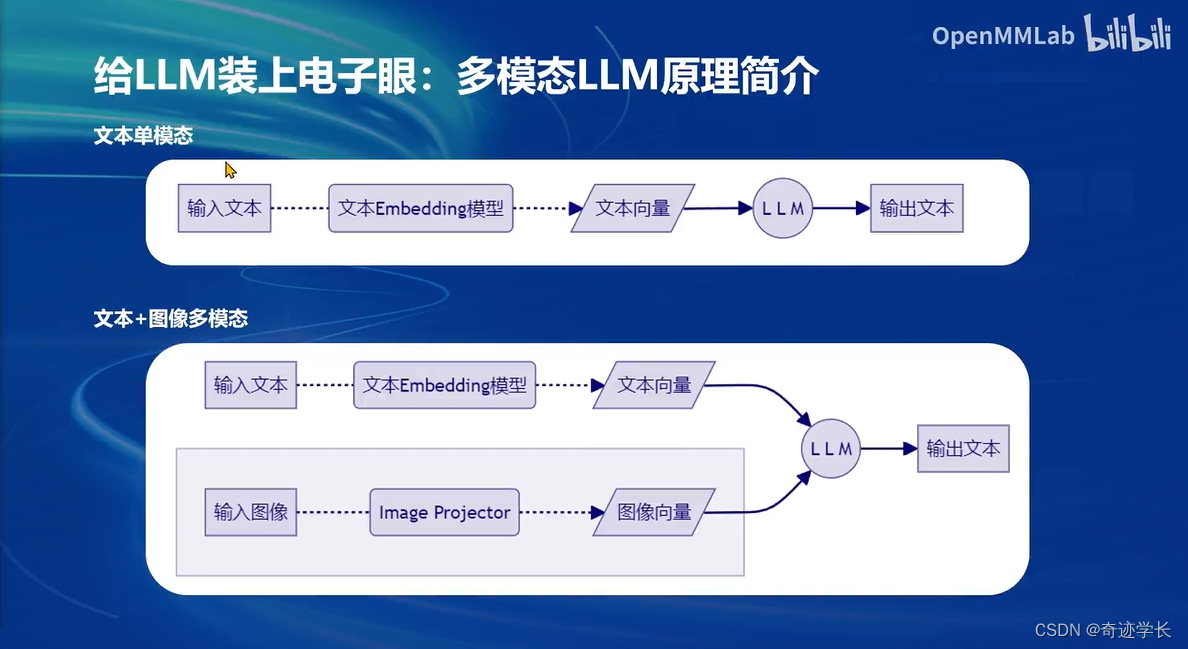
文本单模态:首先使用文本Embedding模型对用户的输入文本,转化为文本向量,将文本向量预测输出文本。
文本+图像多模态:其他部分和文本但模态一致。在输出部分增加了对图像的输入和处理。Image Projector 对输入图像进行 图像向量化。文本向量、图像向量同时进行输入,预测出输出文本。从文本单模态模型 微调-> 文本+图像多模态模型的过程,实际上就是训练Image Projector的过程
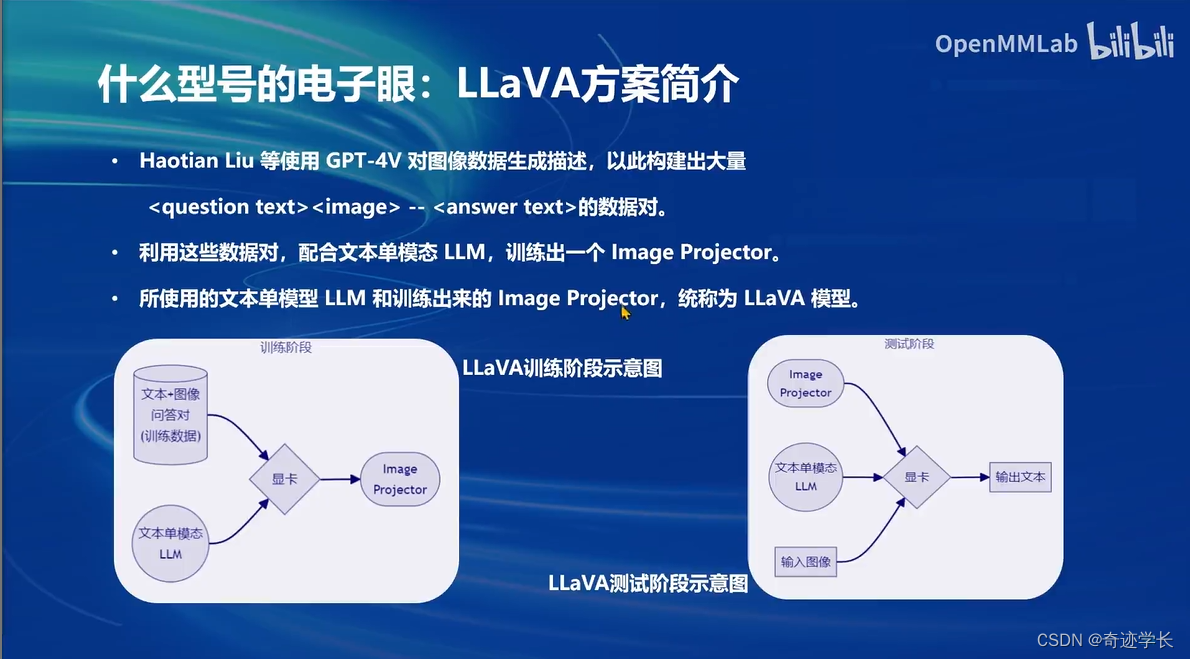
吗
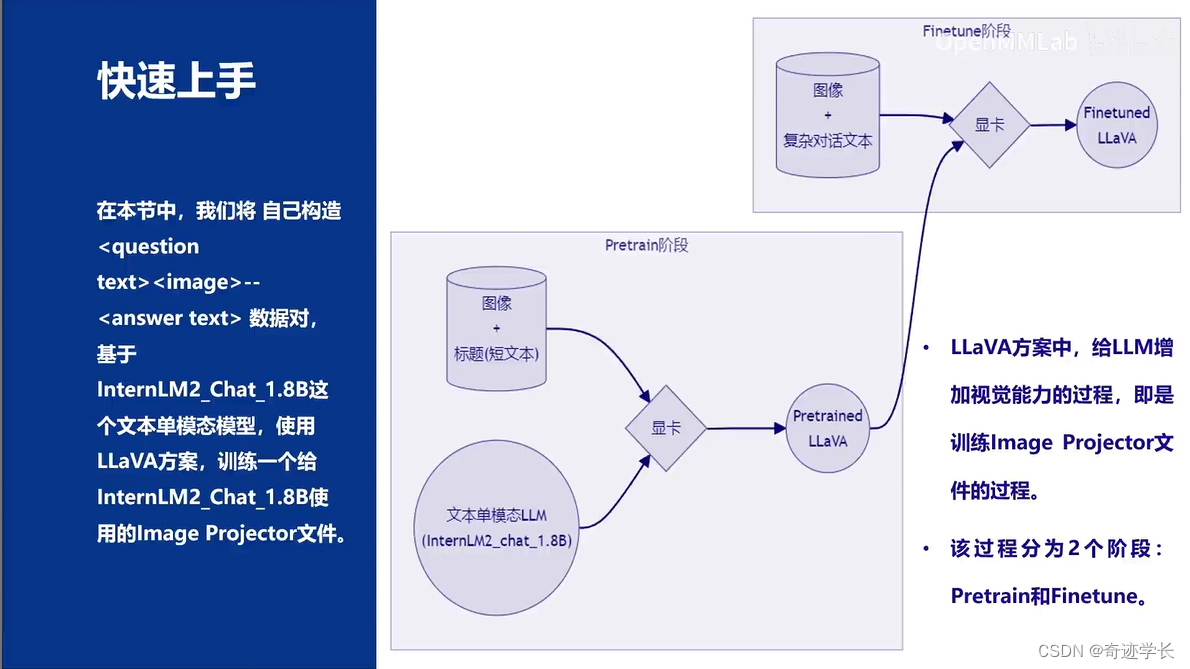
Pretrain阶段的数据如下:

Finetune阶段的数据如下:

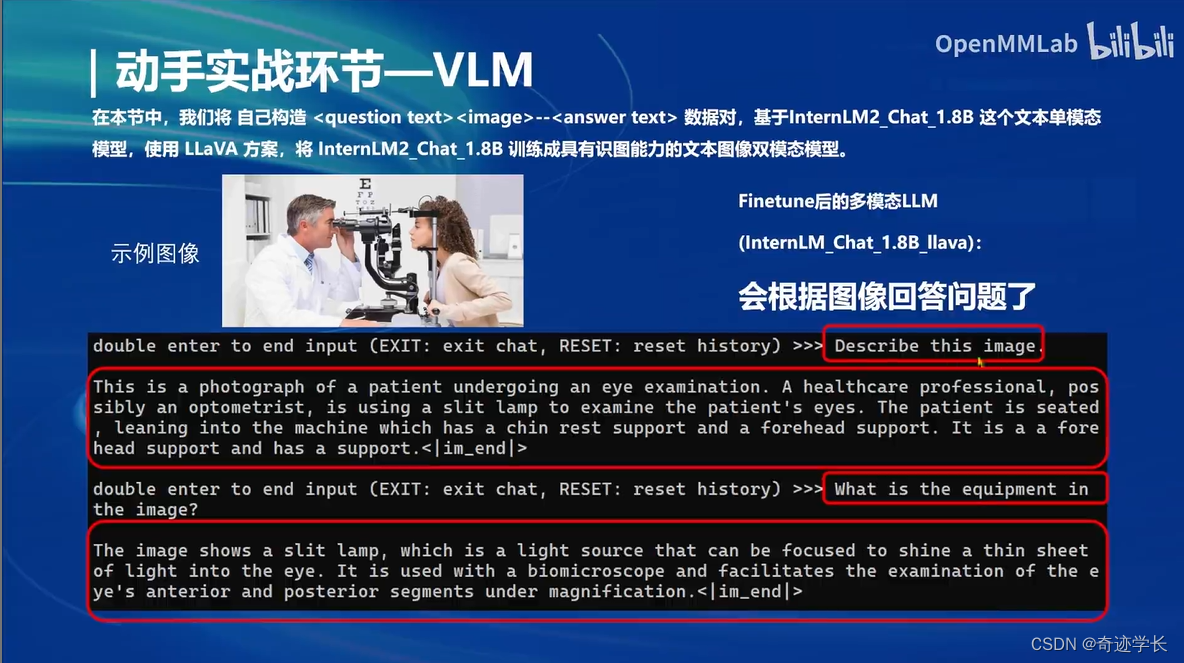
微调前后效果如下:

只Pretrain 未 Finetune,只会给图像打标题

经过Finetune之后















 1529
1529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









