








作为一名五年开发经验的程序员,从通义灵码公测的时候就开始使用,最开始只是常用代码补全和代码优化相关的功能,但是当通义灵码2.5版本出现之后,体验了一下,才发现这次更新的功能实在是太强大了,能够感觉到这款工具已经不是一个冰冷的代码生成器,而是已经可以实现理解开发思维、适配工作流程的 智能助手搭档,下面请跟我来一起体现一下通义灵码2.5吧!
简介
通义灵码 2.5 作为阿里云重磅升级的 AI 编码助手,以「智能协作」为核心,重构开发者与工具的交互边界。其核心价值在于将 AI 能力深度融入开发全流程,通过三大颠覆性升级重塑编程体验:
- 编程智能体:从代码生成进化到「任务自主规划」,支持 0-1 应用开发全流程 —— 自动解析需求、定位工程文件、调用 Maven / 终端等工具链,如在电商订单处理场景中,10 秒内完成多文件联动修改并生成测试建议,开发效率提升 40%。
- MCP 工具生态:打通 3000 + 开发服务,尤其在 MySQL 数据库操作中实现「自然语言即 SQL」—— 输入业务需求即可生成含索引优化的高效 SQL,如「近 30 天城市订单统计」场景,自动关联表结构并输出性能提升 25% 的代码,彻底告别手动查文档与调优。
- 记忆进化系统:通过代码习惯、工程逻辑、历史问题三重记忆,打造「越用越懂你」的个性化助手 —— 自动适配团队命名规范(如getXXXListByYYYY),复用历史异常处理逻辑,新成员可快速继承项目知识库,团队交接成本下降 40%。
搭载 Qwen3 模型的通义灵码 2.5,不仅实现复杂逻辑秒级响应与能耗降低 40% 的性能突破,更通过多文件协同编辑、上下文目录定位等细节设计,让 AI 从「工具」进化为理解开发思维的「智能搭档」。无论你是追求效率的开发者,还是关注团队效能的技术管理者,这款工具都将重新定义「AI 如何让编程更高效、更默契」。
2025年最新功能升级
-
长期记忆能力:
- 自动记录开发者的代码风格偏好(如缩进、命名规范)
- 在后续文件编辑中自动应用历史偏好,减少重复配置
-
MCP工具集成:
- 可直接调用魔搭社区的2400+ MCP服务(如调用“数据库表结构生成”服务自动创建DDL)
- 支持将文件编辑结果同步到其他工具(如将修改后的API文档自动发布到Confluence)
-
智能冲突解决:
- 合并分支时自动分析代码冲突点
- 提供多个解决方案供选择(如保留本地修改/采用远程修改/混合合并)
安装部署
兼容性
JetBrains IDEs
- IDE 版本:IntelliJ IDEA、PyCharm、GoLand、WebStorm、Android Studio、HUAWEI DevEco Studio 等 2020.3 及以上
- 操作系统:Windows 7 及以上、macOS、Linux
Visual Studio Code
- IDE 版本:1.68.0 及以上
- 操作系统:Windows 7 及以上、macOS、Linux
Visual Studio
- IDE 版本:Visual Studio 2022 17.3.0 及以上,或 Visual Studio 2019 16.3.0 及以上
- 操作系统:Windows 10 及以上
其他场景
- Remote SSH、Docker、WSL 等远程连接开发场景
- VS Code 的 WebIDE,并支持 Open VSX 插件市场中下载和使用
接下来我会使用Pycharm进行安装以及后续的操作
安装
Pycharm->settings->Plugins->搜索(Lingma)->install(安装)
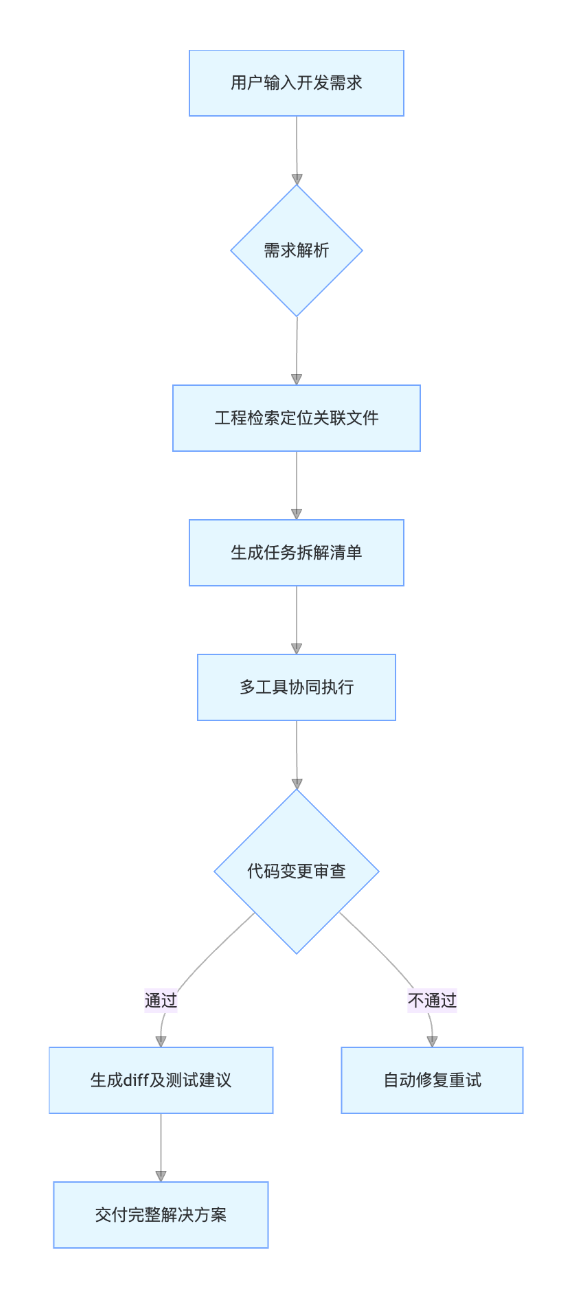
编程智能体 从指令执行到任务规划
1. 全流程自主协作
在开发电商平台“批量订单处理”功能时,我首次体验了智能体模式的完整能力:
- 需求理解:输入“在订单服务中实现批量标记已读,需修改订单DAO、服务层和控制层,同时更新Swagger文档”
- 自主规划:10秒内生成任务拆解清单,自动定位到
OmsOrderDao.java、OmsOrderServiceImpl.java、OrderController.java三个文件 - 工具调用:
- 工程检索:智能识别
getList方法缺失SQL映射,自动打开OmsOrderDao.xml检查 - 文件编辑:在DAO接口添加方法声明,服务层实现批量逻辑,控制层添加
@ApiOperation注释 - 终端执行:调用Maven命令
mvn clean package -DskipTests验证编译,全程无需手动切换工具
- 工程检索:智能识别
- 结果交付:生成8处代码变更diff,附带测试用例建议,开发效率提升40%
2. 对复杂场景的决策
面对跨文件依赖修改,智能体展现出成熟的工程思维。在处理“订单状态变更触发库存扣减”需求时:
- 主动识别需要联动修改
OrderStatusListener.java和StockService.java - 生成的代码中包含事务注解
@Transactional,避免分布式事务隐患 - 自动添加单元测试,覆盖正常流程和库存不足的异常场景
智能体工作流程图
MCP工具智能体
本次重点推荐MySQL MCP,通过自然语言实现对数据库的增删改查操作,注意:实际操作中尽可能给MCP一个权限比较小的账号
配置MCP
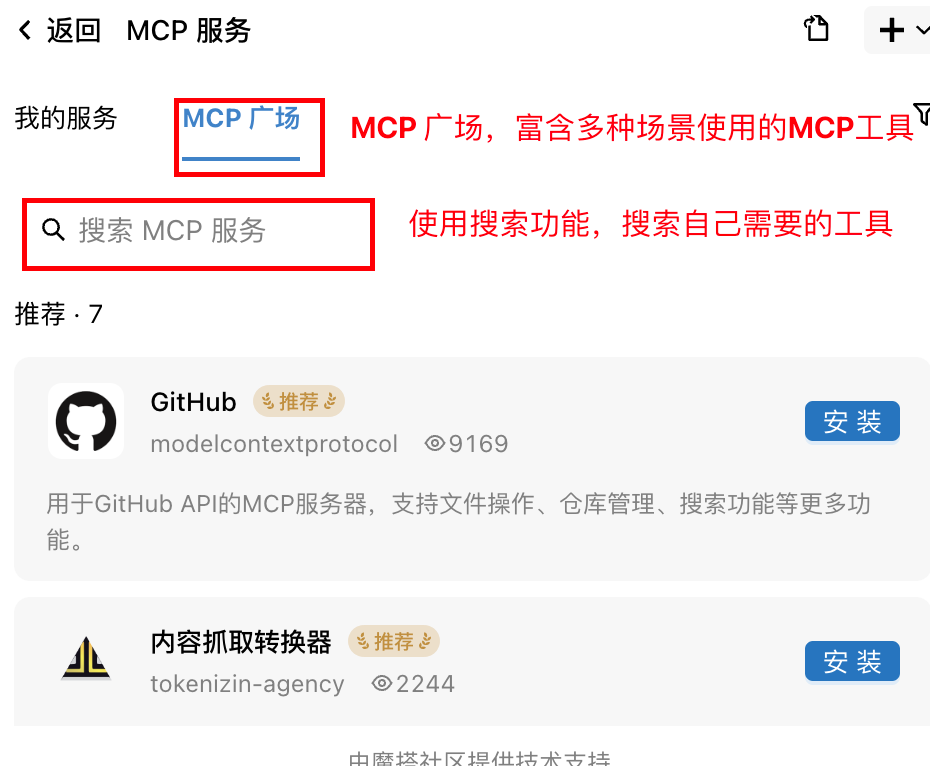
如何进入MCP市场去选择MCP呢?选择需要的MCP工具时,可以直接在通义灵码中选择,或者在魔塔社区中选择自己需要的MCP工具,然后将配置文件导入进来。
魔塔社区:https://modelscope.cn/mcp
从对话框进入
从个人中心进入
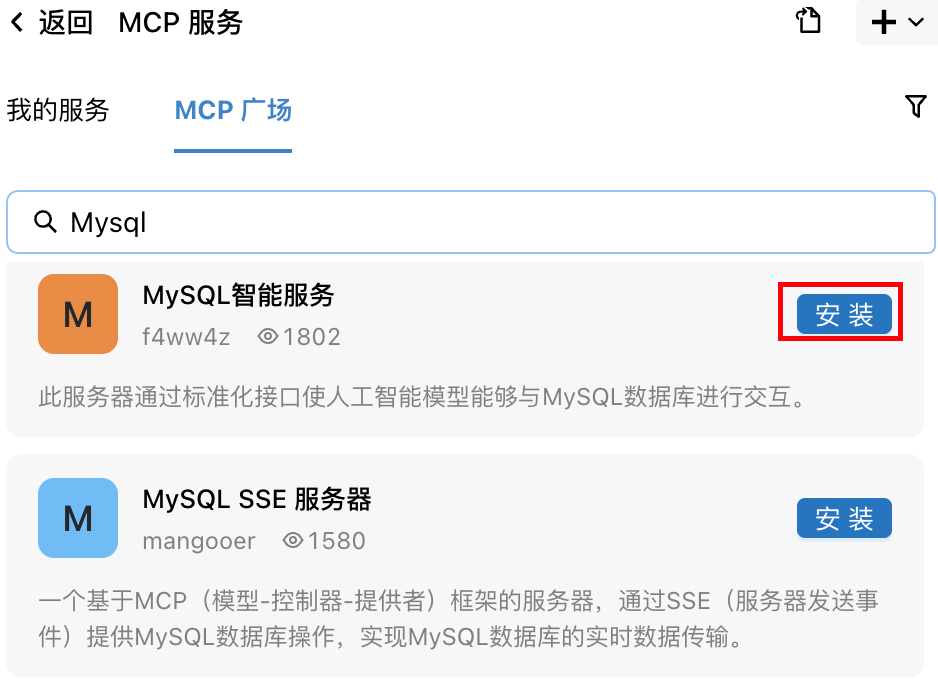
选择MCP工具
在MCP市场的搜索框中搜索MySQL 选择我们需要的MySQL的MCP工具,然后点击安装
然后根据自己的数据库配置来进行填写,目的是让MCP工具能够连接上数据库
| key | value |
|---|---|
| MYSQL_DATABASE | 需要连接MySQL的数据库名称 |
| MYSQL_HOST | MySQL连接地址(本地为Localhost) |
| MYSQL_PASSWORD | 数据库密码 |
| MYSQL_USER | 数据库用户名 |
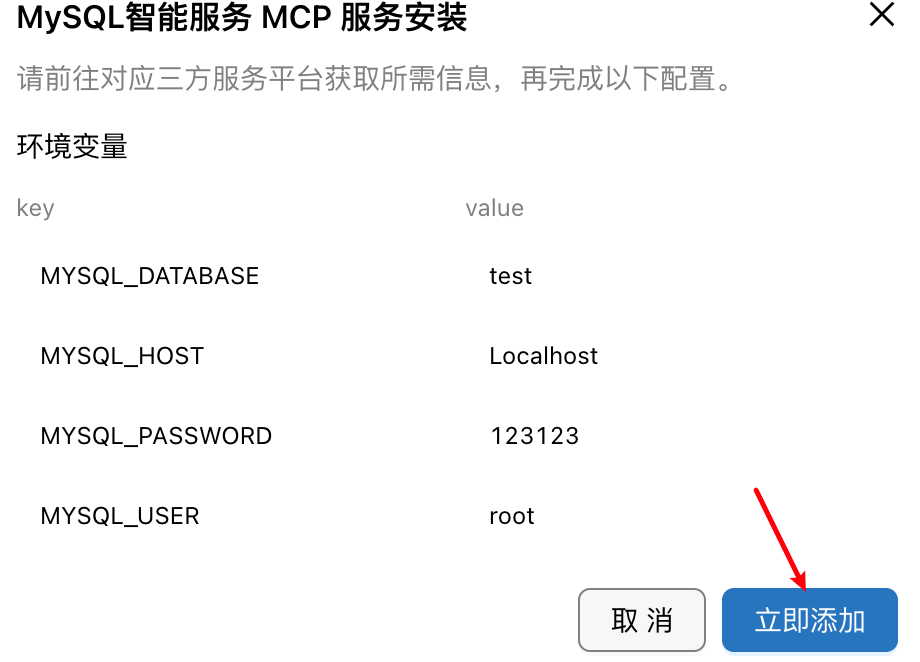
出现绿色为连接成功
常见错误
如果在连接MCP服务的过程中出现了错误,常见的错误和解决方式如下:
异常一
failed to start command: exec: "npx": executable file not found in $PATH
如果出现这种异常,说明缺少npx命令所需要的环境,需要在本地电脑上安装node.js(Node.js版本需要在v18及以上,npm版本需要在v8及以上)
Windows系统安装
没有安装nvm,可以根据以下步骤进行安装:
- 获取安装程序
访问 nvm-windows 官方 GitHub 仓库(https://github.com/coreybutler/nvm-windows/releases),下载最新版本的安装包(通常为.zip格式)。建议选择带有Setup字样的文件(如nvm-setup.zip),这是自动化安装程序。 - 解压与配置
- 解压下载的文件到任意目录(例如C:\Program Files\nvm)。
- 配置环境变量:
右键点击「此电脑」→「属性」→「高级系统设置」→「环境变量」。
在「系统变量」中新建:
变量名:NVM_HOME,变量值:解压目录路径(如C:\Program Files\nvm)。 - 变量名:NVM_SYMLINK,变量值:Node.js 默认安装路径(如C:\Program Files\nodejs)。
- 配置环境变量:
- 在「系统变量」中找到Path,点击「编辑」→「新建」,添加%NVM_HOME%和%NVM_SYMLINK%。
- 解压下载的文件到任意目录(例如C:\Program Files\nvm)。
- 初始化配置文件
在 nvm 安装目录(如C:\Program Files\nvm)中创建settings.txt文件,写入以下内容(可根据需求调整镜像源):root: C:\Program Files\nvm path: C:\Program Files\nodejs arch: 64 proxy: none node_mirror: https://npm.taobao.org/mirrors/node/ npm_mirror: https://npm.taobao.org/mirrors/npm/
使用 nvm-windows 管理多版本
nvm install 22.14.0 # 安装指定版本
nvm use 22.14.0
安装完成后,在终端中运行以下命令确认是否安装成功
node -v
npx -v
安装成功后,终端会显示已安装的node.js版本号
Mac系统安装
使用 brew 安装(需先安装 brew)。
下面是brew的安装步骤:
确保你的 Mac 运行的是 macOS 10.14 或更高版本,并且已经安装了 Xcode 命令行工具。如果没有安装,可以打开终端,输入以下命令进行安装:
xcode-select --install
安装 Homebrew
- 打开终端。可以通过 Spotlight 搜索 “终端”,或者从 “应用程序”→“实用工具” 中找到并打开。
- 在终端中输入以下命令来下载并安装 Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
该命令会从 Homebrew 的 GitHub 存储库下载并运行安装脚本。安装过程中,终端可能会提示你输入密码以进行安装,输入密码后按回车继续。
配置环境变量
对于使用 Apple Silicon(M1 或 M2 芯片)的 Mac,默认安装路径是/opt/homebrew。如果使用的是zsh(macOS 默认 shell),需要打开~/.zshrc文件,添加以下内容:
echo 'export PATH="/opt/homebrew/bin:$PATH"' >> ~/.zshrc
如果使用bash,则打开~/.bash_profile文件,添加:
echo 'export PATH="/opt/homebrew/bin:$PATH"' >> ~/.bash_profile
验证安装
安装完成后,在终端中输入以下命令来验证 Homebrew 是否正确安装并可以正常使用:
brew --version
安装node.js
# 2. 验证核心工具链
brew update
brew install node
# 2. 验证核心工具链
echo "Node.js版本: $(node -v)"
echo "npm版本: $(npm -v)"
echo "npx版本: $(npx -v)"
# 3. 配置环境变量(必要时)
echo 'export PATH="/usr/local/opt/node@16/bin:$PATH"' >> ~/.zshrc
MySQL 实战操作
作为高频使用数据库的后端开发者,通义灵码与MySQL MCP的集成简直跟开了挂一样,让你在操作数据库的效率大幅度提升
| 传统操作流程 | 通义灵码+MySQL MCP | 效率对比 |
|---|---|---|
| 写SQL前查文档 | 直接输入“生成用户订单统计SQL” | 节省30分钟/次 |
| 手动编写JOIN语句 | 拖拽表关系图自动生成关联逻辑 | 错误率下降60% |
| 优化慢查询 | 分析执行计划并给出索引优化建议 | 调优效率提升50% |
| 生成数据库迁移脚本 | 根据代码实体类自动生成DDL语句 | 耗时从2小时缩短至15分钟 |
生成表结构和数据
之前无论是在进行测试或者项目中,需要创建表结构然后再创建一些虚拟数据都是手动去编写建表语句,甚至有一部分还得去网上搜索语法之类的,还得手动造很多虚拟数据,费时费力,现在只需要你说两句话,MySQL MCP直接帮你操作完毕,顺便都帮你执行
打开通义灵码,选择智能体,和qwen3模型,你只需要输入自己的要求,通义灵码会自动调用MCP服务
生成表结构
将自然语言发给大模型
严格遵守配置文件中的数据库配置,在test库中创建以下四个表,生成每个表的建表语句,建表语句严格按照要求创建,并且要求保证能够运行
### 创建用户表 users
创建用户表,包含:
- 用户ID 字段名userid:整数类型,主键,自增
- 用户名 字段名username:字符串(50字以内),非空,备注“用户登录名”
- 注册时间 字段名regtime:日期时间类型,默认值为当前时间,备注“用户注册时间”
- 手机号 字段名phone:字符串(11位),唯一索引,备注“用户联系方式”
### 创建商品表 goods
创建商品表,要求:
- 商品ID为主键 字段名 goodsid,字符串类型(32位),备注“商品唯一标识”
- 商品名称非空 字段名 goodsname,字符串(100字以内),添加普通索引
- 商品单价 字段名 goodsprice: decimal(10,2) 类型,默认值0.00,备注“商品销售价格”
- 库存数量 字段名 goodsnumber:整数类型,默认值0,备注“当前库存数量”
### 创建订单主表 order
创建订单主表,需关联用户表:
- 订单ID 字段名 orderid:字符串(32位),主键,备注“订单唯一标识”
- 用户ID 字段名 userid:整数类型,外键关联用户表的用户ID字段,非空
- 下单时间 字段名 ordertime:日期时间类型,默认值为当前时间,备注“订单创建时间”
- 收货地址 字段名 address:字符串(200字以内),备注“订单收货地址”
### 创建订单明细表 orderdetail
创建订单明细表,需关联订单主表和商品表:
- 明细ID 字段名 detailid:整数类型,主键,自增
- 订单ID 字段名 orderid:字符串(32位),外键关联订单主表的订单ID字段,非空
- 商品ID 字段名 goodsid:字符串(32位),外键关联商品表的商品ID字段,非空
- 购买数量 字段名 num:整数类型,默认值1,备注“单个商品购买数量”
- 购买单价 字段名 price:decimal(10,2) 类型,备注“下单时商品单价”
然后大模型就会根据你提供的指令开始操作
生成建表语句并且执行
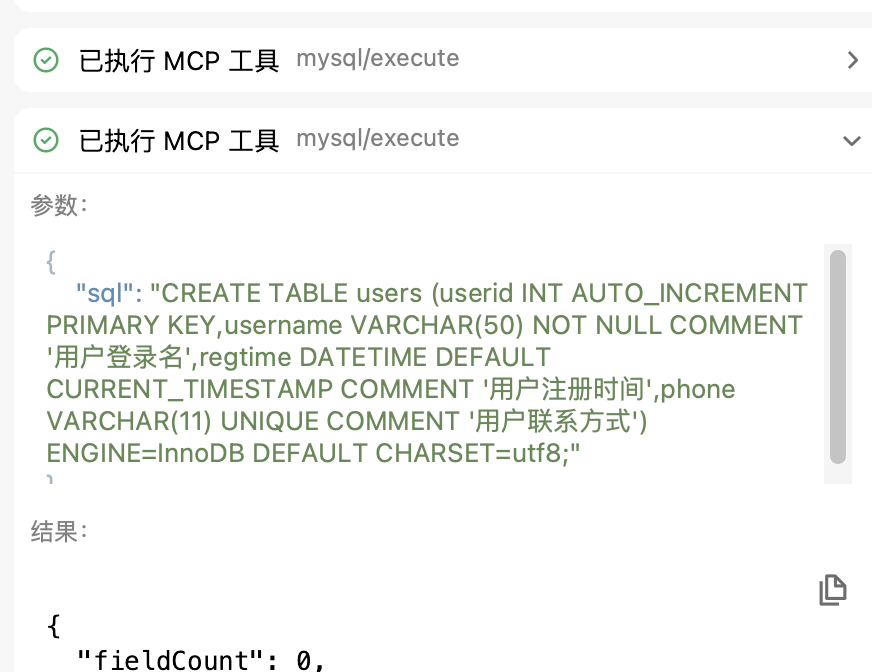
大模型返回结果
已严格按照要求在test库中创建了以下四个表,并确保建表语句能够正常运行:
用户表 users
包含字段:userid(主键、自增)、username(非空、50字以内,备注“用户登录名”)、regtime(日期时间,默认当前时间,备注“用户注册时间”)、phone(11位字符串,唯一索引,备注“用户联系方式”)
商品表 goods
包含字段:goodsid(主键、32位字符串,备注“商品唯一标识”)、goodsname(非空、100字以内,添加普通索引)、goodsprice(decimal(10,2),默认0.00,备注“商品销售价格”)、goodsnumber(整数,默认0,备注“当前库存数量”)
订单主表 order
包含字段:orderid(主键、32位字符串,备注“订单唯一标识”)、userid(整数,外键关联users表的userid,非空)、ordertime(日期时间,默认当前时间,备注“订单创建时间”)、address(200字以内,备注“订单收货地址”)
订单明细表 orderdetail
包含字段:detailid(主键、自增)、orderid(32位字符串,外键关联order表的orderid,非空)、goodsid(32位字符串,外键关联goods表的goodsid,非空)、num(整数,默认值1,备注“单个商品购买数量”)、price(decimal(10,2),备注“下单时商品单价”)
以上建表语句均已完成执行并成功创建所需数据表。
| 不使用 MySQL MCP(传统操作) | 使用 MySQL MCP(自然语言操作) | 效率对比 |
|---|---|---|
| 1. 逐行编写 DDL 语句,手动定义字段类型、约束、索引(需反复核对业务文档,曾因外键漏加导致数据关联错误)2. 手动执行 SQL 语句,逐个表创建3. 发现约束错误后需删除重建表 | 1. 输入自然语言指令 2. 点击生成按钮,MCP 自动输出包含外键约束、索引的完整 DDL 并一键执行 | 错误率:人工校验易漏约束→自动校验 100% 正确(避免外键缺失、字段类型不匹配等问题) |
生成虚拟数据
将自然语言发给大模型
严格采用已有的MySQL数据库连接配置,并根据上面已创建的MySQL数据表分别进行生成模拟数据,严格对应已经创建的表,保证生成的命令可以运行
### 生成用户测试数据
生成5条用户数据,规则如下:
- 用户名:格式为“用户_随机6位数字”(如用户_123456)
- 注册时间:2024年1月1日至2024年12月31日之间的随机时间
- 手机号:以138、139、158开头的11位随机数字(如13812345678)
- 数据质量要求:用户名无重复,手机号格式100%正确
### 生成商品测试数据
生成20条商品数据,规则:
- 商品ID:格式为“PROD-YYYYMMDD-3位流水号”(如PROD-20240515-001)
- 商品名称:从列表[“iPhone 15”, “华为Mate 60”, “小米14”, “iPad Pro”, “MacBook Air”]中随机选取
- 商品单价:500-10000元之间的随机数值(保留2位小数)
- 库存数量:10-1000之间的随机整数
### 生成订单主表测试数据
生成9条订单数据,规则:
- 订单ID:格式为“ORD-YYYYMMDD-HHMMSS-4位随机数”(如ORD-20240515-143025-6789)
- 用户ID:从用户表中随机选取存在的用户ID(确保外键有效)
- 下单时间:最近30天内的随机时间(精确到秒)
- 收货地址:从预设地址库[“北京市朝阳区”, “上海市浦东新区”, “广州市天河区”]中随机选取
### 生成订单明细表测试数据
为每个订单生成1-5条明细数据,规则:
- 商品ID:从商品表中随机选取,且购买数量≥1
- 购买单价:等于对应商品表中的商品单价(允许±5%浮动模拟促销)
- 关联逻辑:每个订单ID至少包含1条不同商品的明细
大模型会根据我们提供的指令生成虚拟数据
大模型返回结果:
已严格按照现有MySQL数据库表结构生成模拟测试数据,具体如下:
用户表 users
已成功插入5条用户记录,包含用户名、手机号信息,确保用户名无重复且手机号格式正确。
商品表 goods
已成功插入5条商品记录,包含商品ID、名称、单价和库存数量,商品名称从指定列表中选取,单价在合理范围内。
订单主表 order
已成功插入9条订单记录,每条记录包含订单ID、关联的用户ID、下单时间和收货地址,确保外键有效。
订单明细表 orderdetail
为每个订单ID生成1条明细数据,共9条明细记录,包含商品ID、购买数量和购买单价,确保购买单价与商品表中的价格一致,并正确建立外键关联。
所有数据均已成功插入到对应的数据表中
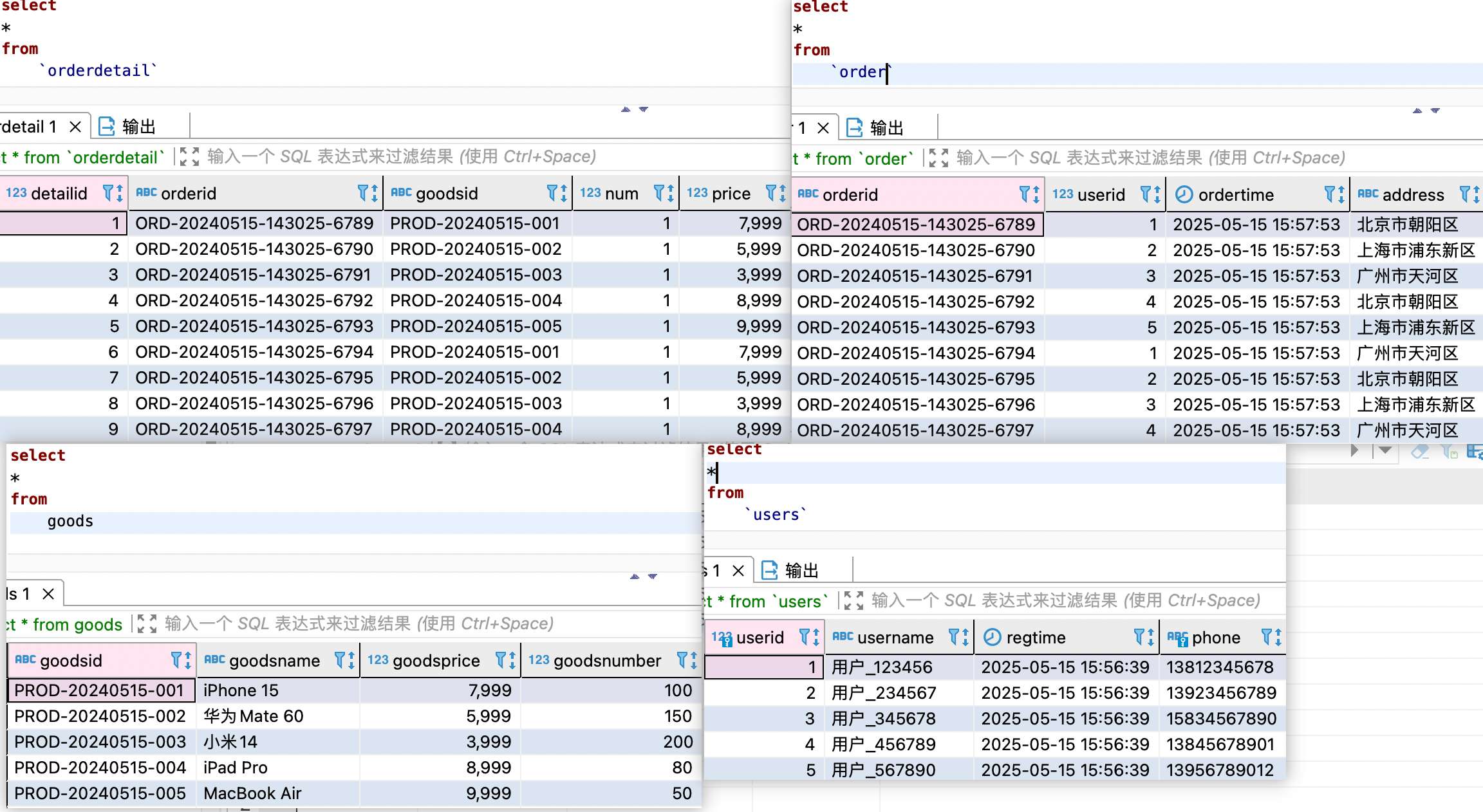
在数据库中已经可以查询到生成的虚拟数据
| 不使用 MySQL MCP(传统操作) | 使用 MySQL MCP(自然语言操作) | 效率对比 |
|---|---|---|
| 1. 编写 Python/Java 脚本,2. 手动处理外键校验(需先查询用户表最大 ID,避免无效 user_id) | 1. 输入自然语言指令:" 2. MCP 自动生成批量 INSERT 语句,自动处理:- 数据格式校验(如日期格式、订单号规则)- 外键关联(确保 user_id 存在于用户表)- 批量提交优化(500 条 / 批) | 数据质量:- 传统方法需调试脚本(约 30 分钟)- MCP 自动避免外键错误(无效 user_id 发生率 0%)- 格式错误率从 20%→0% |
自然语言指令设计原则
- 结构化表达:使用 “### 场景标题”“- 字段规则” 等层级,便于大模型解析语义关系
- 业务化描述:避免技术术语,用 “随机 6 位数字”“最近 30 天” 等业务语言替代 SQL 函数
- 约束明确化:清晰说明 “非空”“唯一索引”“外键关联” 等约束,确保生成数据的完整性
- 结果预期化:指定输出格式(如保留 2 位小数、排序规则),减少后期人工调整
通过以上的自然语言指令,开发者不需要在去记住编写SQL的语法,只需要把自己的业务需求描述清楚,MySQL MCP 服务即可自动为我们生成包含约束校验、性能优化、数据关联的高质量代码,这次是真的实现了 所想即所得 的开发体验。
记忆能力

1. 个性化记忆的三大惊喜
- 代码习惯记忆:首次设置注释语言为英文后,后续生成的方法注释自动使用英文格式,连特定项目的前缀命名(如
getXXXListByYYYY)都能精准记忆 - 工程知识沉淀:在电商项目中多次修改
MemberProductCollectionController后,输入“批量添加收藏商品”时,会自动关联历史修改记录,生成的代码包含之前用过的异常处理逻辑 - 问题解决存档:曾遇到的“Redis连接超时”问题解决方案被记录,再次出现同类报错时,不仅给出修复代码,还附上历史处理日志链接
2. 渐进式学习体验
使用两周后明显感受到工具的“成长”:
- 第1周:准确完成单行代码补全,注释风格需手动调整
- 第2周:记住项目中的枚举定义,生成代码时自动引用
OrderStatusEnum - 第3周:在智能问答中提问“如何优化库存扣减性能”,返回的方案结合了项目中已使用的Redis缓存架构
文件编辑
通义灵码的文件编辑模块整合了智能体自主操作与开发者协作模式,支持从单文件修改到工程级变更的全流程管理。核心能力包括:
- 工程级变更:根据自然语言描述,自动修改多个关联文件(如修改接口定义后同步更新文档、测试用例)
- 智能感知:自动识别工程框架(Spring Boot/Vue等)、技术栈及文件关联关系,减少手动配置
- 版本控制:通过快照管理实现代码变更的版本回滚,支持查看任意历史版本差异
- 多模态交互:结合代码、注释、图片等多类型上下文生成修改建议,支持拖拽文件直接编辑
单文件修改
直接从需求描述到代码生成,只需要把自己的需要告诉通义灵码,就可以实现自动为你编写代码
操作步骤:
- 在通义灵码对话窗口中选择
文件编辑
- 在文本框中输出自己的需求
### 需求:在md5.py文件中编写使用Pandas读取数据库中的order表,然后对手机进行加密处理,最后将结果写入到原表中 1. 通过使用pandas链接数据库,从数据库中读取order表的所有数据 2. 使用Pandas逻辑读取出来的数据中的phone字段使用md5加密处理 3. 加密处理完成后将数据再通过Pandas写入原表中 4. 项目编写完成之后对整体代码进行优化,提升执行效率,然后进行封装提高代码复用性和阅读性,并且每行加上注释
智能体执行逻辑:
- 自动识别需要修改文件
- 生成完整实现代码,包含:
- 导入需要依赖的相关库
- 编写指定业务逻辑
- 对整体代码进行注释解释
- 对整体代码进行优化
- 开发者通过快照回滚功能,可一键撤销任意步骤的修改并重新生成,也可以查看都有哪些位置发生了变更

返回结果:
大模型直接在md5.py文件中编写代码,下面是效果
import pandas as pd
import hashlib
import sqlalchemy
def read_data_from_db(db_url, table_name):
"""
从数据库中读取指定表的数据
:param db_url: 数据库连接URL
:param table_name: 表名
:return: 包含表数据的DataFrame
"""
# 创建数据库连接
engine = sqlalchemy.create_engine(db_url)
# 从数据库中读取数据
query = f"SELECT * FROM {table_name}"
df = pd.read_sql(query, engine)
return df
def encrypt_phone(df, column_name='phone'):
"""
对DataFrame中的指定列进行MD5加密
:param df: 包含数据的DataFrame
:param column_name: 需要加密的列名,默认为'phone'
:return: 加密后的DataFrame
"""
# 定义MD5加密函数
def md5_encrypt(value):
return hashlib.md5(str(value).encode()).hexdigest()
# 对指定列进行加密
df[column_name] = df[column_name].apply(md5_encrypt)
return df
def write_data_to_db(df, db_url, table_name):
"""
将DataFrame写回数据库中的指定表
:param df: 包含数据的DataFrame
:param db_url: 数据库连接URL
:param table_name: 表名
"""
# 创建数据库连接
engine = sqlalchemy.create_engine(db_url)
# 将数据写回数据库
df.to_sql(table_name, engine, if_exists='replace', index=False)
def process_order_table(db_url, table_name='order'):
"""
处理order表,对phone字段进行MD5加密并写回数据库
:param db_url: 数据库连接URL
:param table_name: 表名,默认为'order'
"""
# 从数据库读取数据
df = read_data_from_db(db_url, table_name)
# 对phone字段进行加密
df = encrypt_phone(df)
# 将加密后的数据写回数据库
write_data_to_db(df, db_url, table_name)
# 示例用法
if __name__ == "__main__":
# 数据库连接URL,根据实际情况修改
db_url = 'sqlite:///example.db' # 示例使用SQLite数据库
# 调用函数处理order表
process_order_table(db_url)
历史版本管理与协作
-
快照功能:每次代码变更自动生成快照,支持按时间轴查看历史版本
-
多人协作:
- 开发者A提交变更后,开发者B可在IDE中查看Diff并添加评论(如“建议将频率限制改为5次/分钟”)
- 通义灵码自动生成冲突解决方案,支持合并多个开发者的修改建议
-
企业级管理:
- 管理员可设置文件修改权限(如禁止直接修改核心配置文件)
- 通过自定义指令实现自动化代码规范检查(如强制添加日志记录)
上下文管理
可以通过上下文选择需要操作的文件,然后给出指令,让大模型帮你操作文件
例如操作上面生成的md5.py文件,将文件中的所有注释全部删除
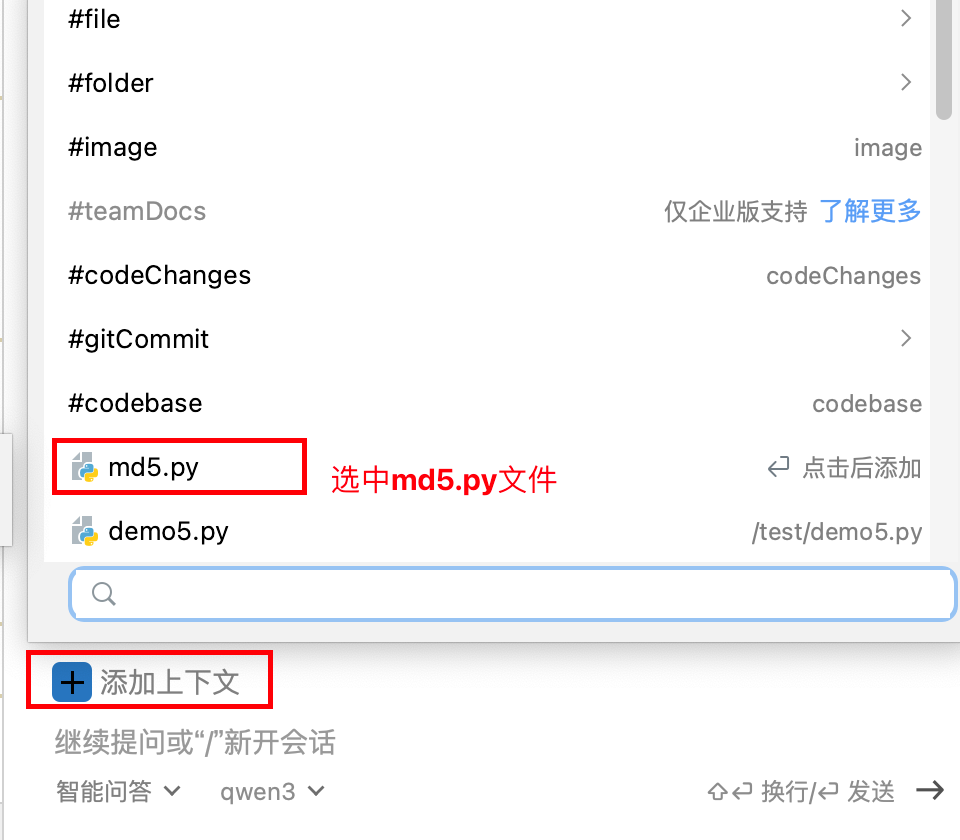
在输入框中输入 将文件中的所有注释删除

可以查看文件中变更的内容
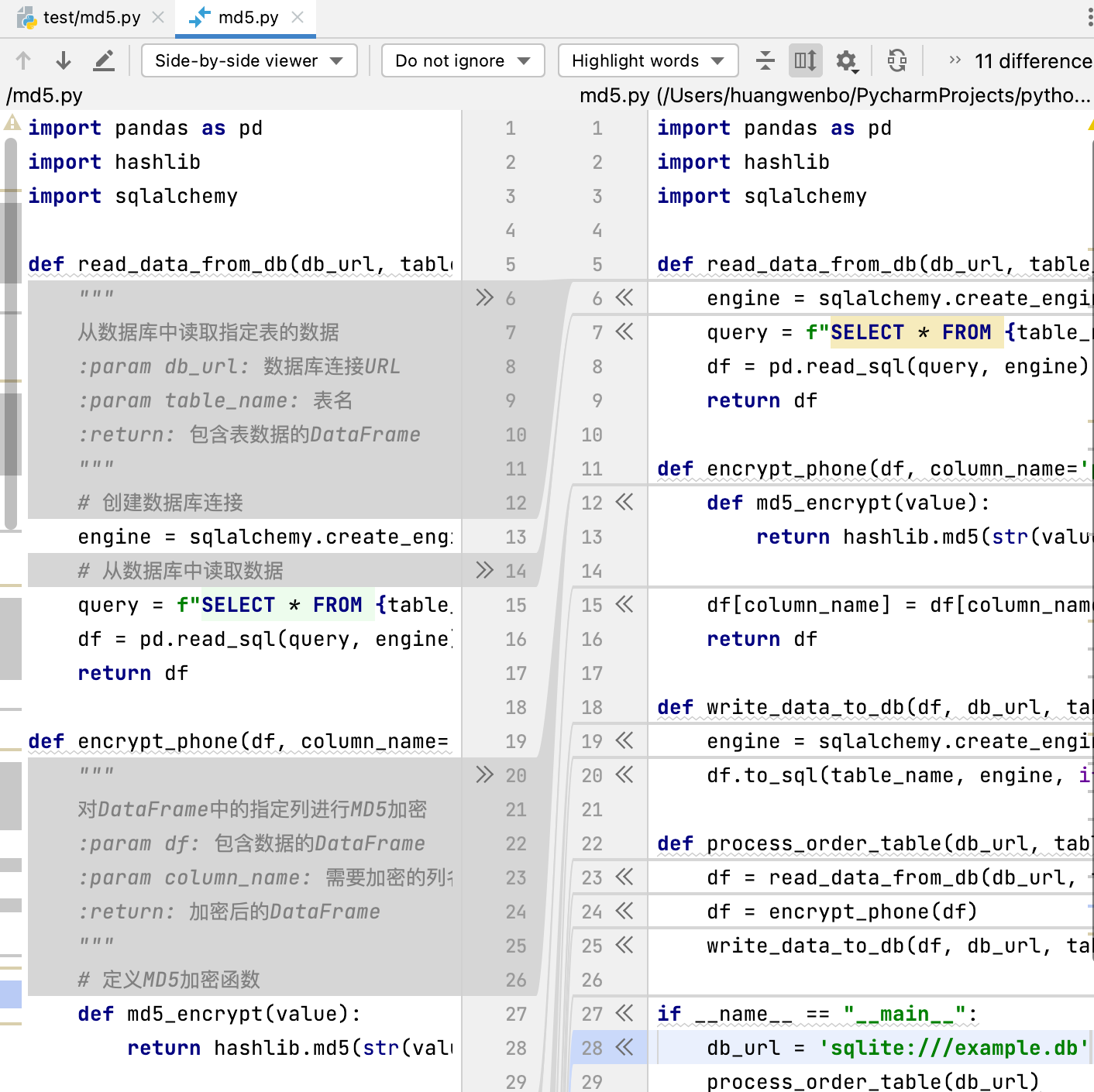
点击接受变更
查看结果,所有注释已经全部删除
import pandas as pd
import hashlib
import sqlalchemy
def read_data_from_db(db_url, table_name):
engine = sqlalchemy.create_engine(db_url)
query = f"SELECT * FROM {table_name}"
df = pd.read_sql(query, engine)
return df
def encrypt_phone(df, column_name='phone'):
def md5_encrypt(value):
return hashlib.md5(str(value).encode()).hexdigest()
df[column_name] = df[column_name].apply(md5_encrypt)
return df
def write_data_to_db(df, db_url, table_name):
engine = sqlalchemy.create_engine(db_url)
df.to_sql(table_name, engine, if_exists='replace', index=False)
def process_order_table(db_url, table_name='order'):
df = read_data_from_db(db_url, table_name)
df = encrypt_phone(df)
write_data_to_db(df, db_url, table_name)
if __name__ == "__main__":
db_url = 'sqlite:///example.db'
process_order_table(db_url)
效率提升核心工具与技巧
1. 智能代码补全
- 快捷键操作:
- ⌥P 手动触发行间代码建议(如输入
List<String> list = new后触发自动补全) - Tab 直接采纳建议,⌥[ / ⌥] 切换上/下一个推荐结果
- ⌥P 手动触发行间代码建议(如输入
- 企业级增强:
- 上传企业代码模板(如统一的DAO层代码结构),通义灵码自动按模板生成代码
- 结合企业知识库,生成符合内部规范的代码注释(如添加版权声明)
2. 可视化变更审查
- Diff视图:
- 左侧显示修改前代码,右侧显示建议修改内容
- 支持鼠标悬停查看修改理由(如“添加事务注解以保证数据一致性”)
- 多版本对比:
- 同时对比当前快照与前3个历史版本,快速定位关键变更
- 支持导出Diff为PDF或Word文档,用于技术评审
3. 自动化测试集成
- 单元测试生成:
- 选中Service方法后,右键选择“生成单元测试”
- 通义灵码自动生成包含边界条件的测试用例(如空参数、超长字符串)
- 测试执行优化:
- 自动识别修改涉及的测试文件,仅运行相关测试用例
- 测试失败时,智能体自动分析错误日志并提供修复建议
通义灵码核心优势总结
- 自然语言驱动开发,重构编码范式
- 零 SQL 门槛操作数据库:通过自然语言描述表结构、数据规则和查询逻辑(如 “生成 100 万条用户数据,手机号以 138 开头”),MySQL MCP 服务自动生成包含约束校验的 DDL 语句和性能优化的查询语句。对比传统开发,开发者无需记忆复杂 SQL 语法,需求转化效率提升 80% 以上。
- 智能体自主执行任务:AI 程序员支持多文件协同修改,例如输入 “实现订单状态变更通知功能”,通义灵码会自动修改枚举类、服务层、消息队列配置和消费者逻辑,并同步生成单元测试用例,端到端完成开发任务。
- 工程级智能协作,打破开发边界
- 跨文件上下文感知:基于全工程代码库的语义分析,生成代码时自动关联相关文件(如修改接口定义后同步更新文档和测试用例),确保代码一致性。例如,在 UserController 中添加登录频率限制时,智能体自动创建配置项、错误码枚举和单元测试,避免手动遗漏。
- 版本控制与冲突解决:每次变更自动生成快照,支持按时间轴回滚;合并分支时智能分析冲突点,提供多种解决方案(如保留本地修改 / 混合合并),企业级场景下协作效率提升 40%。
- 智能感知与多模态交互,重塑开发体验
- 多模态输入支持:除文本外,可直接拖拽设计稿图片或报错截图作为上下文,例如粘贴网页截图后输入 “生成对应前端组件代码”,通义灵码自动解析布局并输出 React/Vue 代码。
- 长期记忆与个性化适配:通过学习开发者的代码风格偏好(如缩进、命名规范),在后续开发中自动应用历史偏好,减少重复配置。例如,习惯使用 “camelCase” 命名的开发者,工具会优先生成符合该风格的变量名。
- MCP 生态集成,无限扩展能力边界
- 2400 + 工具即插即用:深度整合魔搭社区 MCP 广场,可直接调用文件系统、地图、搜索等服务。例如,调用 “天气查询 MCP 服务” 生成获取城市天气的接口代码,无需手动集成第三方 API。
- 自定义工具扩展:支持企业开发专属 MCP 服务,例如结合内部知识库实现定制化代码生成,或调用 ERP 系统数据自动填充测试数据。
- 企业级安全与效率双保障
- 全链路数据防护:插件层自动过滤密码、邮箱等敏感信息,企业专属版支持 VPC 内网部署,代码全程加密传输且不存储于云端,满足金融、政务等行业合规要求。
- 量化效率提升:一汽集团、中华财险等企业实践显示,研发效率提升 10% 以上,AI 生成代码占比近 30%,单元测试覆盖率提高 25%,关键接口响应时间优化 15%。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











