









 本文介绍了在深度学习任务中获取GPU显存状态的不同方法,包括PyTorch的cudaAPI、nvidia-smi工具、PyCUDA和gpustat,讨论了它们的准确性及原理,并强调了torch.cuda.memory_allocated()和cuda.mem_get_info()在实际应用中的差异。
本文介绍了在深度学习任务中获取GPU显存状态的不同方法,包括PyTorch的cudaAPI、nvidia-smi工具、PyCUDA和gpustat,讨论了它们的准确性及原理,并强调了torch.cuda.memory_allocated()和cuda.mem_get_info()在实际应用中的差异。
\TOC@[ ]
显存状态的获取对于深度学习任务至关重要,特别是在使用 GPU 进行模型训练和推理时。了解当前显存的使用情况可以帮助我们优化算法、调整超参数,以及有效地管理计算资源。在本文中,我们将讨论多种获取当前显存状态的方法,并探讨它们的准确性和原理。
获取显存开销的方式:
- pytorch的cuda相关api
- pytroch分析工具
- nvidia-smi
- pycuda
nvidia-smi
首先来看最简单的,官方工具:nvidia-smi。最简单,并且只要安装了驱动,就一定可用。显示内容也很丰富,包括占用进程、显存、风扇等。
nvidia-smi 是基于 NVIDIA 驱动程序提供的接口实现的。这些接口允许用户查询在 GPU 内部的寄存器中各种指标数据,如 GPU 温度、GPU 使用率、显存使用情况等。
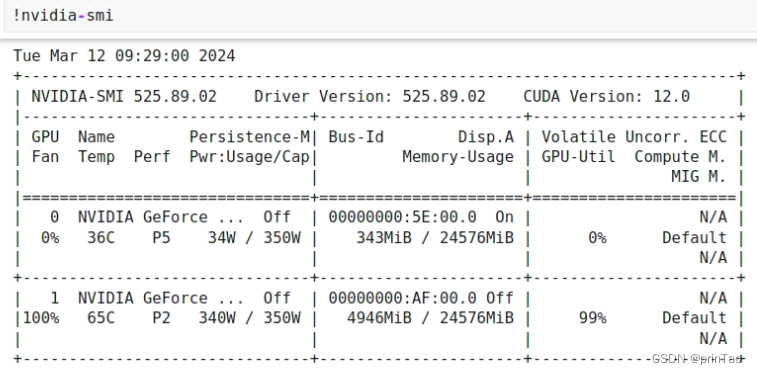
可以使用kill -9 PID号来杀掉未关闭的程序
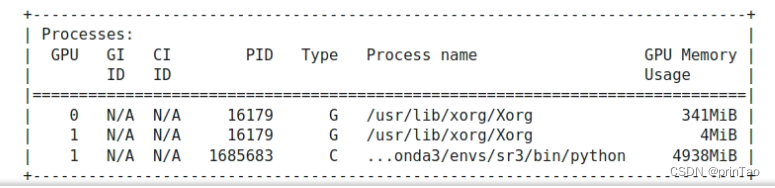
可以在linux使用:
watch -n 1 nvidia-smi
或者在wondws使用
nvidia-smi -l 5
来持续获取显存
Pytorch
在 PyTorch 中,可以使用 torch.cuda.memory_allocated() 和 torch.cuda.memory_reserved() 函数来查询当前 GPU 显存的使用情况。这两个函数提供了获取已分配显存和已保留显存的功能,但并不直接获取当前实际的显存使用情况。
两个函数可能导致与实际显存不一致。例如下面的情况:
import torch
# 检查CUDA是否可用
if torch.cuda.is_available():
# 获取CUDA设备数量
device_count = torch.cuda.device_count()
print("CUDA可用,共有 {} 个CUDA设备可用:".format(device_count))
for i in range(device_count):
device = torch.device("cuda:{}".format(i))
print("CUDA 设备 {}: {}".format(i, torch.cuda.get_device_name(i)))
# 获取当前设备的显存使用情况
total_memory = torch.cuda.get_device_properties(device).total_memory
allocated_memory = torch.cuda.memory_allocated(device) # 已分配的显存
reserved_memory = torch.cuda.memory_reserved(device) # 已保留的显存
free_memory = total_memory - allocated_memory - reserved_memory # 剩余可用显存
print(" - 总显存: {:.2f} GB".format(total_memory / (1024 ** 3)))
print(" - 已分配的显存: {:.2f} GB".format(allocated_memory / (1024 ** 3)))
print(" - 已保留的显存: {:.2f} GB".format(reserved_memory / (1024 ** 3)))
print(" - 剩余可用显存: {:.2f} GB".format(free_memory / (1024 ** 3)))
else:
print("CUDA 不可用")
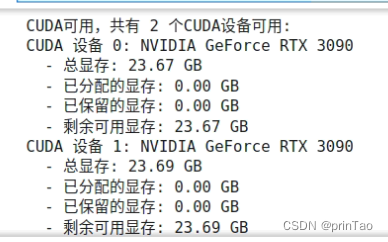
torch.cuda.memory_allocated(): 函数返回已经由 PyTorch 分配但尚未释放的显存字节数。它只能反映出 PyTorch 所管理的显存使用情况,即已被张量、模型参数等数据占用的显存量。
torch.cuda.memory_reserved(): 函数返回由 PyTorch 预先保留但尚未实际分配的显存字节数。PyTorch 在启动时会预留一定数量的显存作为缓冲区,以便在需要时快速分配。这部分显存并不会直接被占用,因此不计入已分配显存。
需要注意的是,如果你使用不同的python环境,例如Docker、Conda,这样的命令无法获取其他python进程的显存开销。是不准确的。
PyCUDA
PyCUDA 是 CUDA 的 Python 接口,它通过调用 CUDA 库中的函数来实现显存的管理和操作。cuda.mem_get_info() 函数实际上是调用了 CUDA 库中的相应函数来获取显存使用情况的信息。
在 PyCUDA 中,要查看 GPU 显存的使用情况,可以使用 cuda.mem_get_info() 函数。这个函数返回一个元组,其中包含两个元素:可用显存的字节数和已分配显存的字节数。
cuda.mem_get_info() 函数: 这个函数用于查询当前 GPU 设备的显存使用情况。它会返回一个包含两个元素的元组,分别表示当前可用的显存字节数和已分配的显存字节数。
用户调用 cuda.mem_get_info() 函数时,PyCUDA 会通过调用 CUDA 库中的相应函数来访问 GPU 设备的监控数据。CUDA 库会通过 PCI 总线访问 GPU 设备,并读取相应的寄存器中的数据。
import pycuda.driver as cuda
# 初始化 PyCUDA
cuda.init()
# 获取 GPU 数量
device_count = cuda.Device.count()
print("GPU 可用,共有 {} 个 GPU 设备可用:".format(device_count))
for i in range(device_count):
# 获取 GPU 设备
device = cuda.Device(i)
print("GPU 设备 {}: {}".format(i, device.name()))
# 创建上下文
context = device.make_context()
# 查询显存使用情况
total_memory = device.total_memory()
free_memory = cuda.mem_get_info()[0]
allocated_memory = total_memory - free_memory
# 打印显存使用情况
print(" - 总显存: {:.2f} GB".format(total_memory / (1024 ** 3)))
print(" - 已分配的显存: {:.2f} GB".format(allocated_memory / (1024 ** 3)))
print(" - 剩余可用显存: {:.2f} GB".format(free_memory / (1024 ** 3)))
# 释放上下文
context.pop()
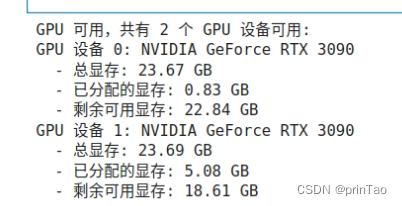
结果是准确的
gpustat
这个命令会显示当前系统中所有 GPU 设备的简要信息,包括 GPU 的编号、型号、利用率、显存使用情况等。如果你没有安装 gpustat,可以使用以下命令进行安装:


















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









