






我们先介绍一个新的概念叫做:特征缩放(Feature Scaling)
为什么我们要进行特征缩放呢,举一个简单的例子。

在这里我们有两个特征,我们的目标是找到一个更加适合于计算出房价的函数模型,我们看左右两边的取值,很明显,在我们的左边对于我们的特征值的估计可以算出的值不是那么的准确,而右边的值所算出的答案是符合实际的,在这里我们会发现一个规律,在上面我们可以看到的范围在300到2000,而我们的
的范围在我们的0到5它们之间有着很大的差异。我们看到我们在对 w取之时呈现的是范围大的特征值小,范围小的特征值大。
这时我们就可以绘画出两幅图。

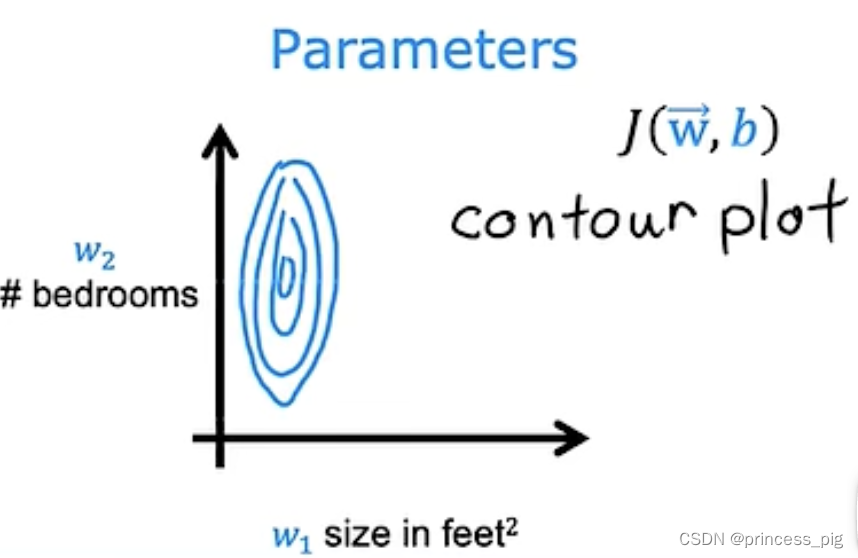
左边这个是关于x1与x2对应的图,而右边的则是用w1和w2绘出的与成本函数有关的图,我们会发现它们的图呈现的是一个扁平状。为了让他们变的比较规整,我们就需要用到特征缩放,它可以让我们对梯度下降又一个更好的应用。如果它是一个不规整的图形,那么我们在找到最小值会变的比较缓慢。

以下的图形就是我们得到在特征缩放以比较规整的图形了。
那我们应该用什么方法来对它们进行特征缩放呢?
这里有三个方法:
第一个方法就是特征缩放(feature scaling)
用我们的方法把它们变成右边的图。我们用的是
这样我们把最大值和最小值都代入,就可以得到我们缩放之后得到的值的范围,这样我们的就可以得到我们下方的图片。
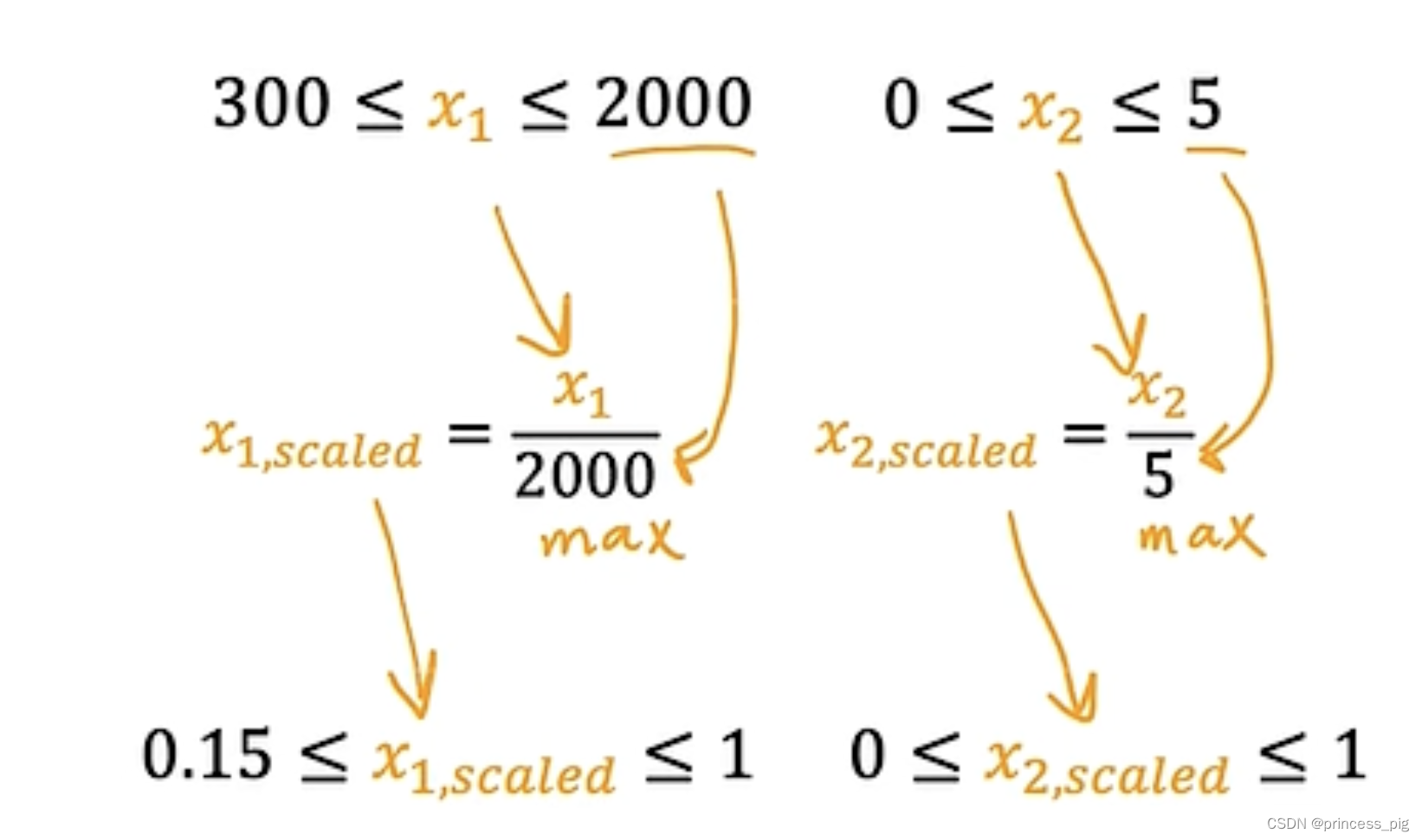


通过这个方法我们得到的图形就非常的规整了。
第二个方法是 均值归一法(mean normalization):
在我们的均值归一法中,我们使用的方式是和
,也就是在这里我们的
指的是所有x的平均值。


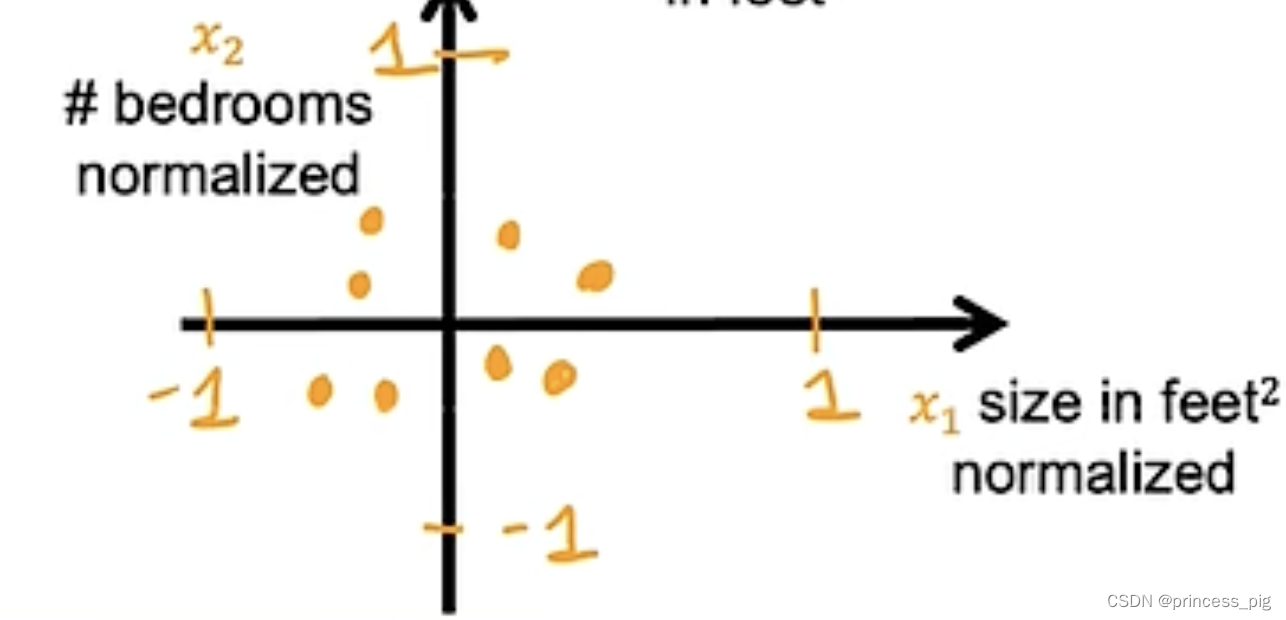 它得到的图片就会像右图,以0点作为我们的中心。
它得到的图片就会像右图,以0点作为我们的中心。
第三种方法:Z分数归一法(Z-score normalizaion)
 我们在这里用的是均值,我们的标准差到平均值的值,这里我们只要有这样的一种写法,我们用
我们在这里用的是均值,我们的标准差到平均值的值,这里我们只要有这样的一种写法,我们用来代表这个值。
我们在这里用的公式是:,就可以得到我们的缩放之后的值。

得到的和第二种方法相似。
以上就是我们得到的方法。
在这里我们要注意哪几个缩放的程度是足够的。

这个值的范围不能太大,不然效果会很差。
判断梯度下降是否收敛:
梯度下降的收敛可以认为是否让我们的成本函数是否达到了最小值。
我们在这里用到一种叫做学习曲线的模型。

在这里我们的函数模型,它的纵坐标是J(成本函数),横坐标是迭代次数,这里表示的是在迭代次数为100次,J的值是多少,在迭代次数为300时,我们发现了我们的成本函数已经和后面的值所持平,它已经到我们的最大值了,说明前面的步骤,已经到了收敛的状态了。
当然还有一种方法叫做自动收敛检测,这个可以去了解一下,但是效果还是以上的学习曲线更加适合。
学会找到一个合适的学习率(learning rate):
当我们选择了一个过于小的学习率,当然我们的迭代次数会变的很多,导致迭代的速度会变的十分的缓慢,但当我们的学习率过大时,我们则会遇到成本函数时大时小的情况,如图所示。

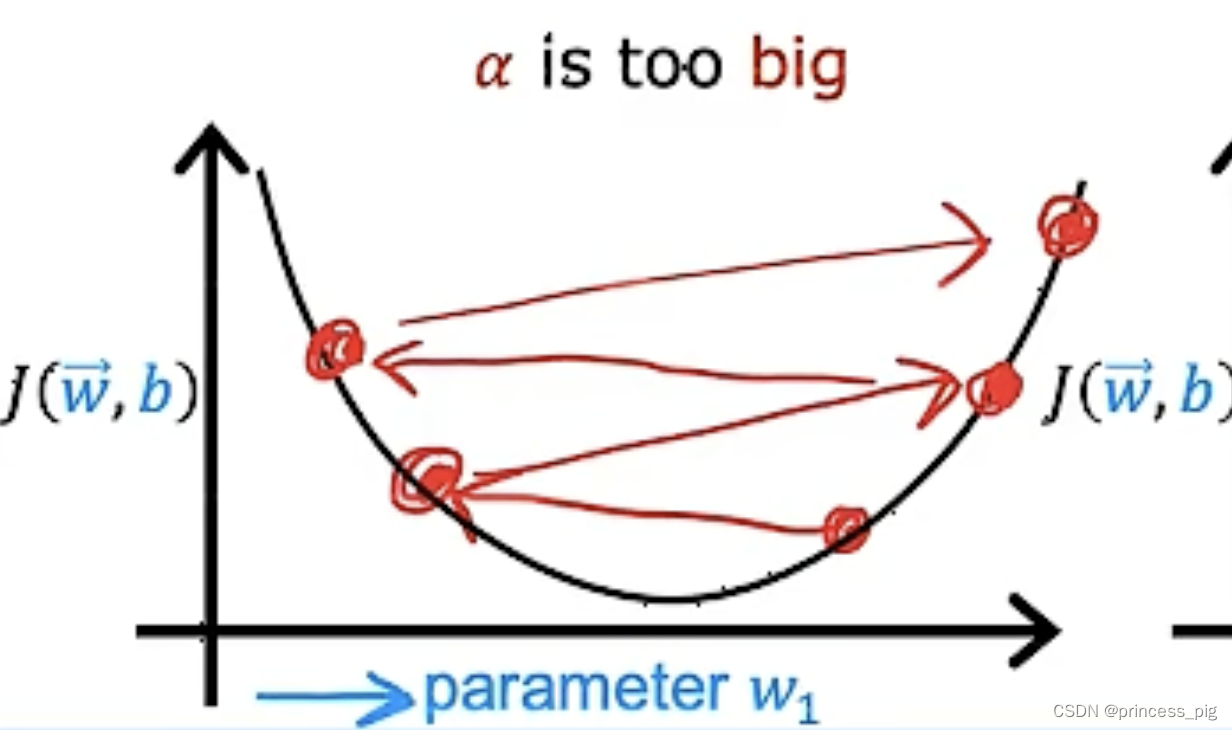
所以只有我们找到了一个小但尽可能更加快的迭代的学习率是非常重要的。让它在迭代的每一步都是在减小的,这样我们才能找到最好的一个学习率。
这里介绍一下如何去找到一个合适的学习率的值,我们先取一个较小的值,再不断的把它增大去画出它们的学习曲线,直到我们找到一个合适的学习率。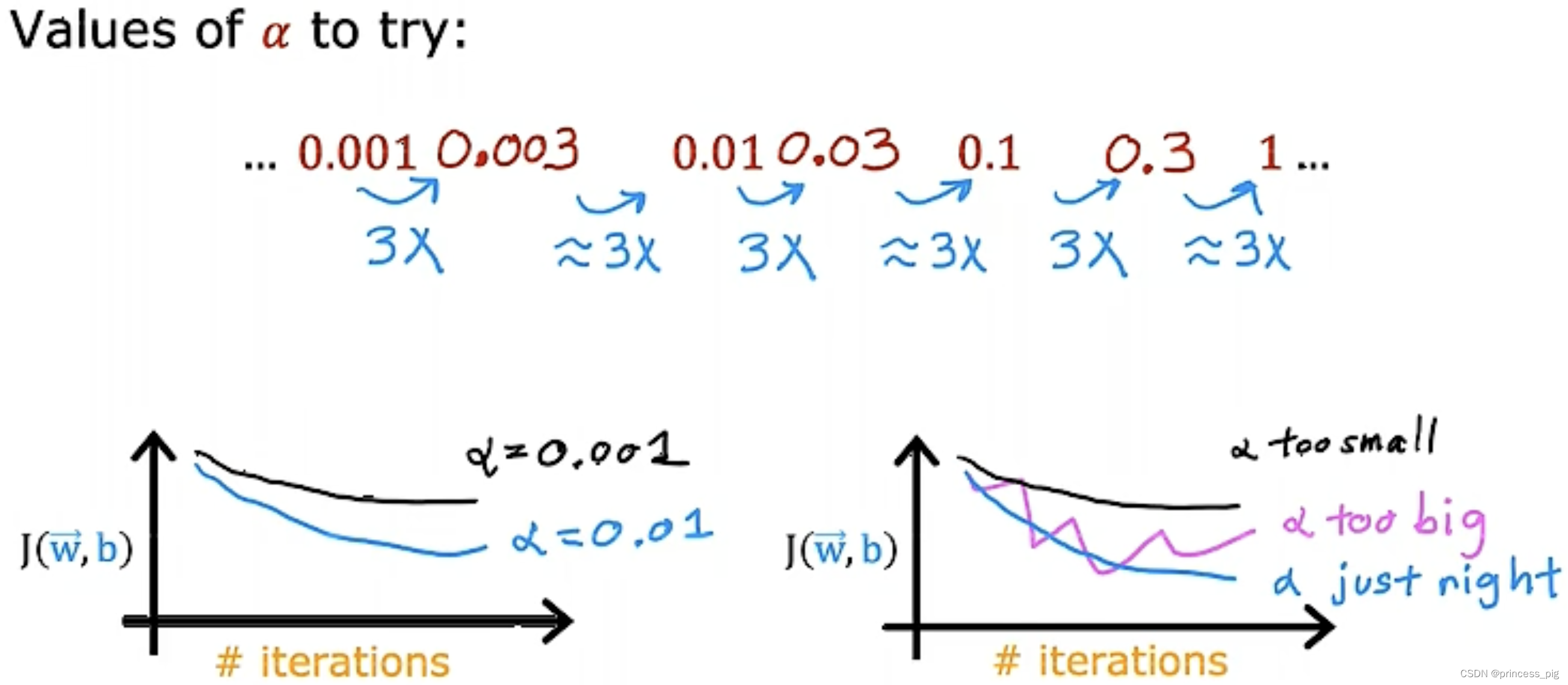
根据我们的学习函数找到我们的最合适的学习率的值。
特征工程:
特征工程就是我们在已知的得到的值上,继续通过一定的关系得到新的特征,从而使用这个特征可以对我们的模型进行优化,举个例子:
我们得到了我们房子门前的宽度x1,同时也得到了房子的纵向深度x2,这时我们的面积也就是一个新的值,我们给他取名为我们的x3。那我们的特征值也就多了一个从而我们可以把它作为我们的第三个特征值,用于我们的线性回归模型的预测。更重要的1是,它不止是适用于我们的线性函数甚至在我们的非线性函数中也可以被使用。
多项式回归:
它是由我们的多元线性回归特征工程想出的一个新的算法,取名为多项数回归。
我们得到了一下的图形。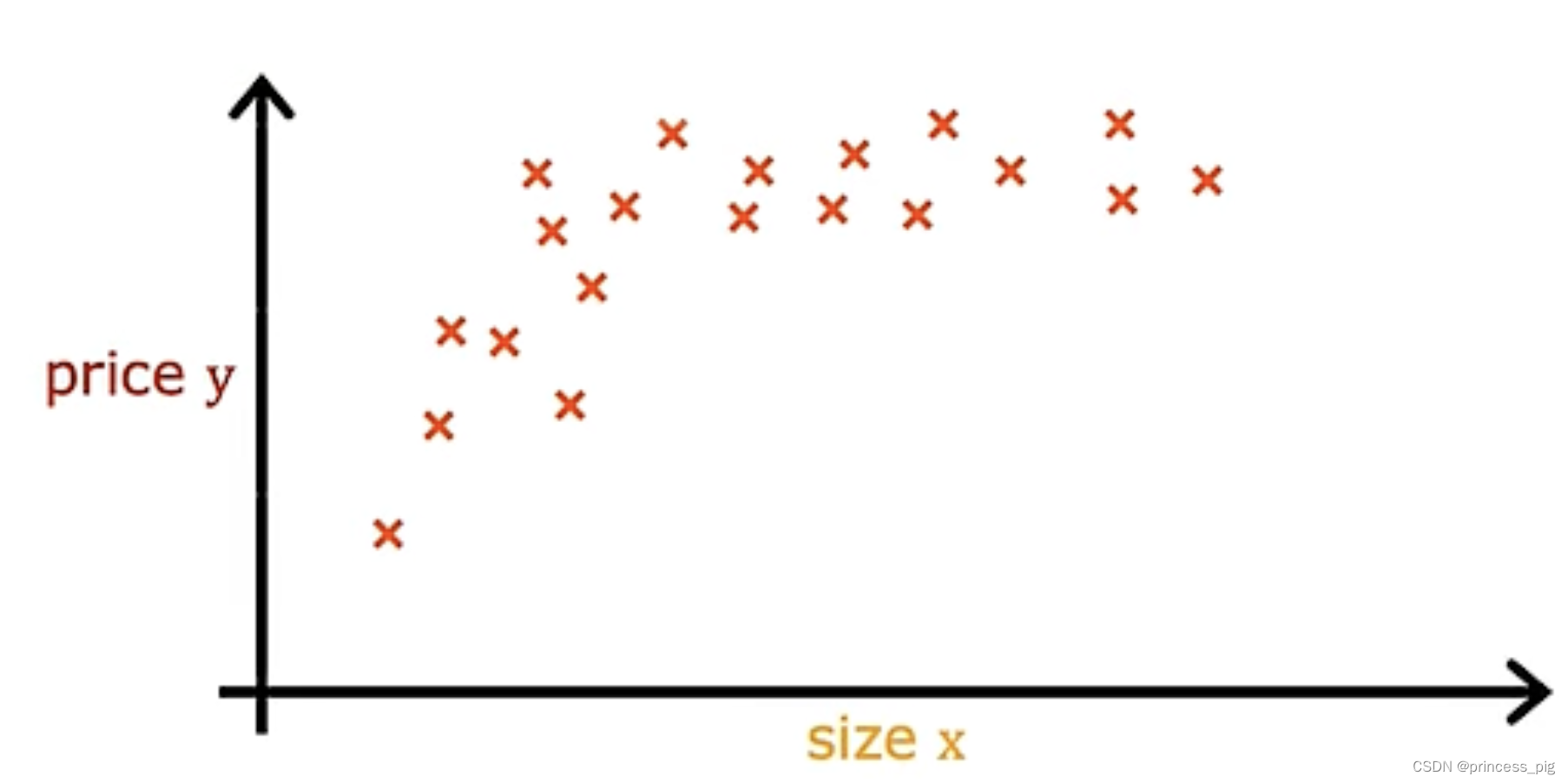
这个图形我们会觉得我们使用曲线会更加的贴切于这个图形。我们会想到用我们的二次函数,但是二次函数是有对称性,所以它是会回落的,如图所示,所以当然不适合用它。
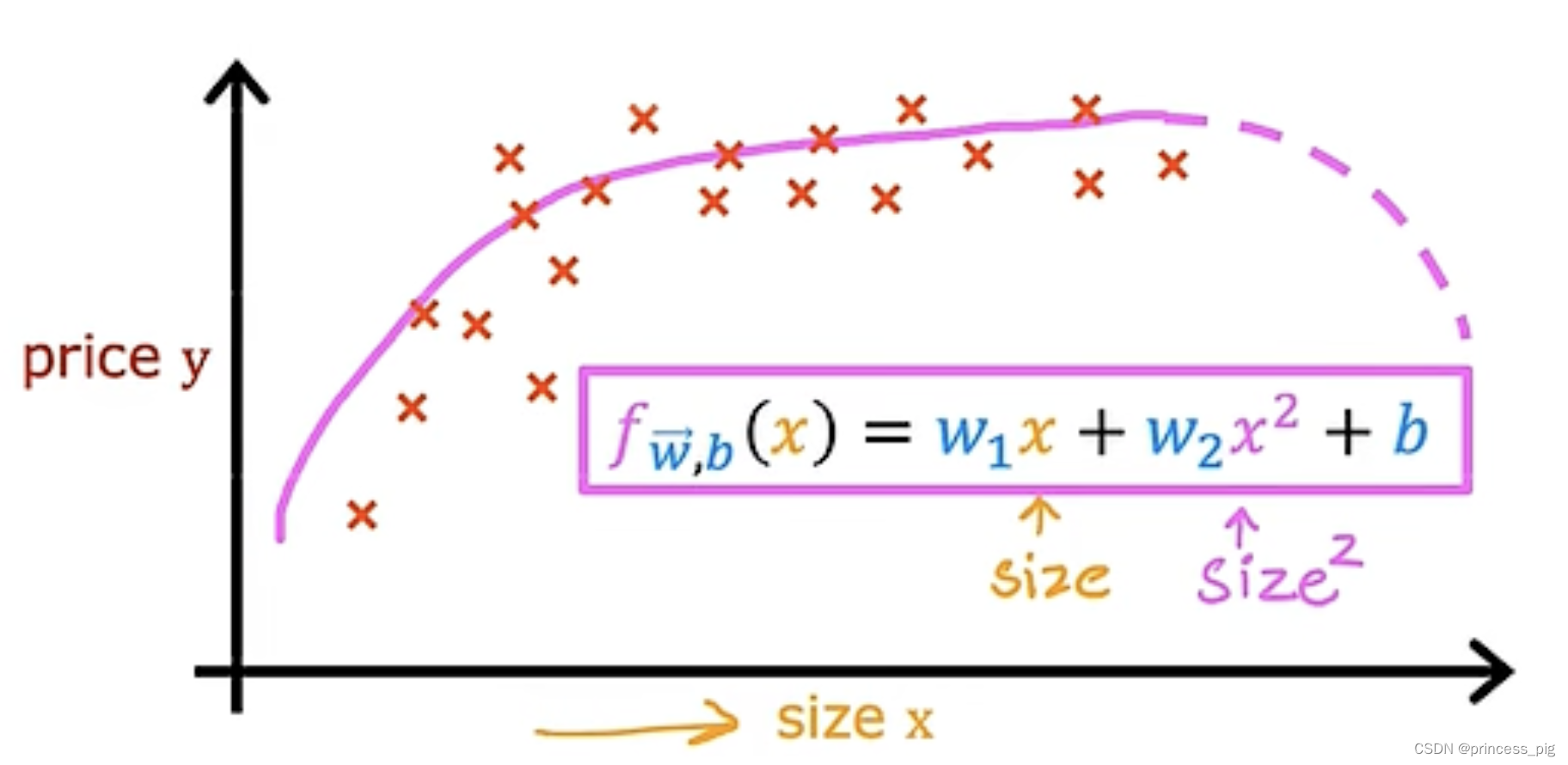
所以我们如果使用的是三次函数,那么这就会更加的合适,如图所示。 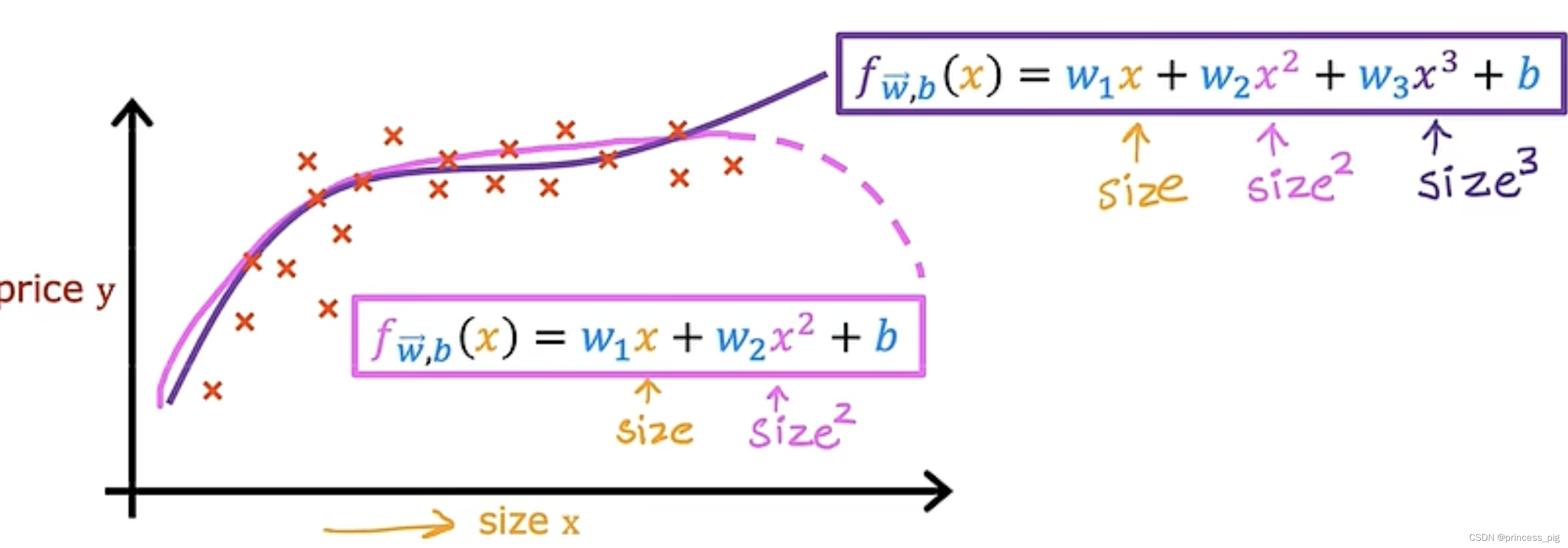
当然在这里我们的x和它们的大小差距很大当然要用到我们的特征缩放的方法,让我们在计算梯度下降的时候更加的准确。
这里我们也可以使用我们的平方根函数,如下图所示。
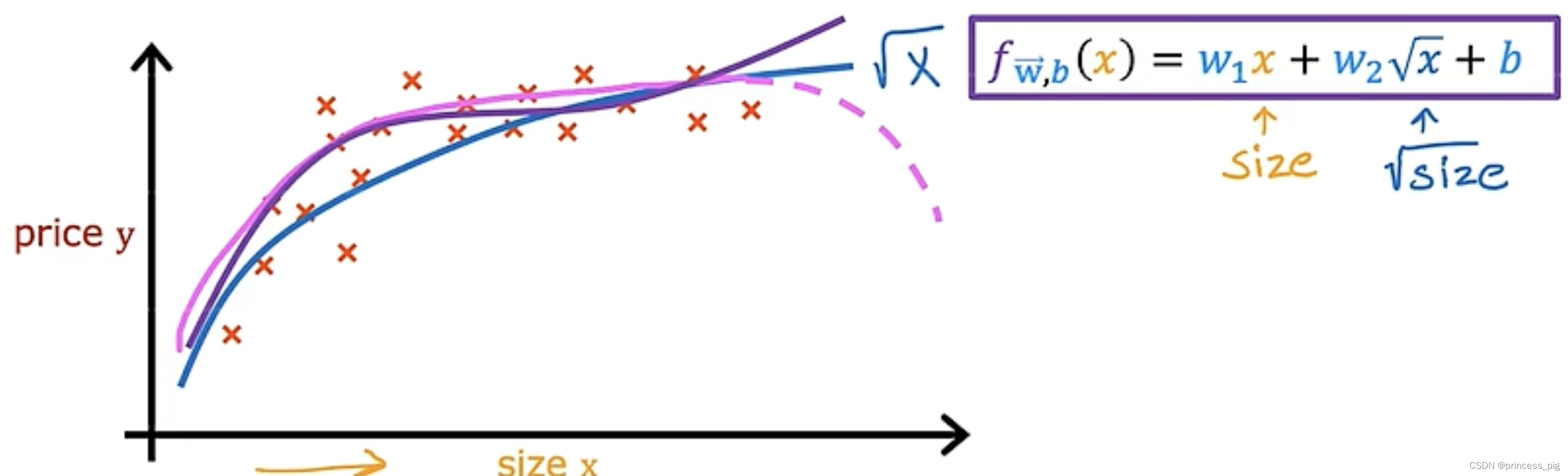
平方根函数在接近无穷的地方虽然它很平但是他们一直是在往上走的,但是他们也还是要去进行特征缩放,让我们在计算梯度下降更好的分析。
这里介绍了一个开源机器学习库,叫做scikit-learn















 3721
3721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









