




文章目录
在深度学习领域,生成式模型不断推陈出新,为数据处理与生成带来诸多可能。变分自编码器(Variational Autoencoder,简称 VAE)作为其中的佼佼者,以其独特的架构和强大的功能,在众多领域发挥着重要作用。
一、VAE 基础入门
1.1 从自编码器说起
自编码器(Autoencoder)是深度学习中常用的无监督学习模型。它的主要结构包含编码器(Encoder)和解码器(Decoder)。编码器负责将高维输入数据压缩成低维的潜在表示(Latent Representation),解码器则将这个潜在表示还原为原始数据空间的重构数据。通过最小化重构误差,自编码器能够学习到数据的重要特征,实现数据的降维与重构。例如,对于一张高分辨率图像,编码器可以将其压缩为一个包含关键特征的低维向量,解码器再利用这个向量重建出与原图相似的图像。然而,传统自编码器生成新数据的能力有限,因为它只是简单地将输入映射到固定的潜在表示,缺乏对数据分布的理解和生成多样性数据的机制。
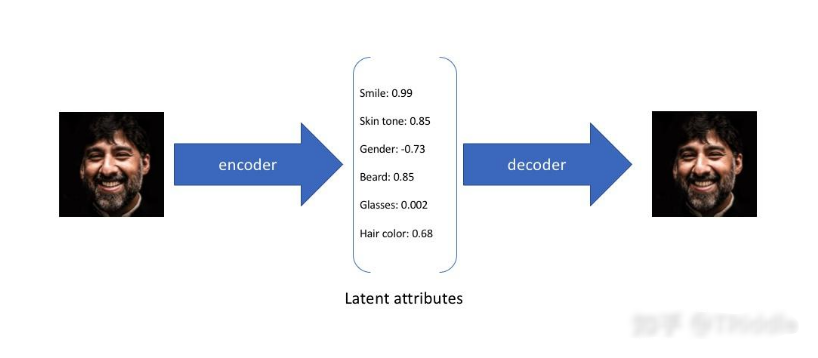
1.2 VAE 的创新之处
VAE 在自编码器的基础上进行了重大改进,引入了概率模型。其编码器并非输出一个固定的潜在表示,而是输出潜在变量的分布参数,通常假设为高斯分布的均值(mean)μ 和对数方差(log-variance)log (σ²) 。通过从这个分布中随机采样一个潜在向量 z,再由解码器将 z 映射回原始数据空间生成重构数据 x’ 。这种概率性的编码和解码方式赋予了 VAE 生成新数据的能力。从直观上理解,传统自编码器的潜在空间像是一系列离散的点,每个点对应一个特定的输入;而 VAE 的潜在空间则是一个连续的、平滑的空间,在这个空间中任意采样一个点,都可以通过解码器生成一个合理的数据样本,这使得 VAE 能够生成丰富多样且与训练数据分布相似的新数据。
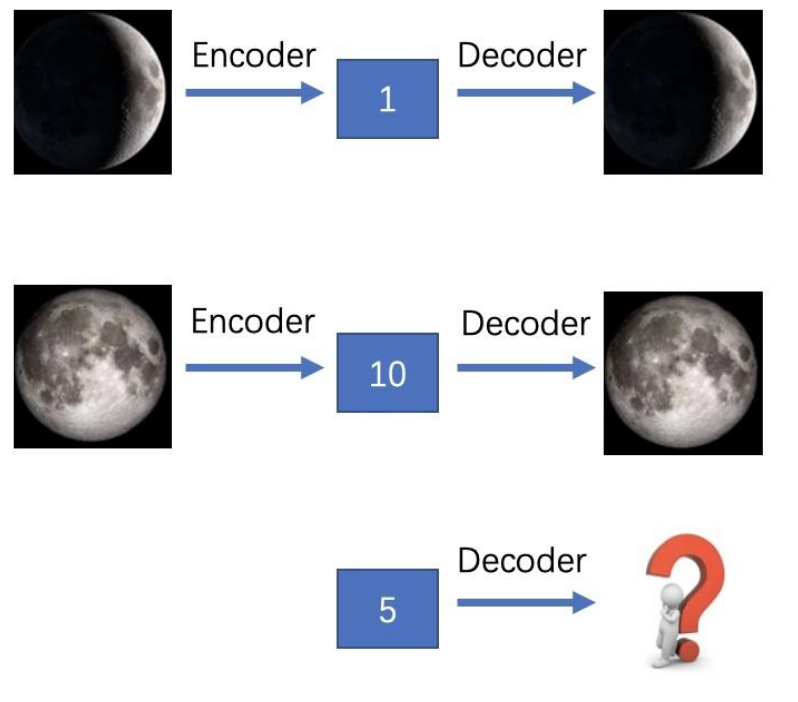
这个图展示了变分自编码器(VAE)“编码 - 解码”与“生成”的逻辑:
- 前两组:不同月相(峨眉月、满月)的图像,经编码器(Encoder)得到不同隐变量(“1”“10”),解码器(Decoder)再根据隐变量还原出对应月相。
- 第三组:直接给解码器隐变量“5”,体现VAE能从隐空间选变量,生成介于前两种月相之间的新图像(比如上弦月这类过渡月相)。
核心是展现VAE对“隐空间”的利用——既可以还原已有图像,也能生成新图像。
1.3 工作流程详解
- 编码阶段:输入数据 x 进入编码器,编码器对其进行处理,输出高斯分布的参数 μ 和 log (σ²) 。这个过程可以理解为编码器在寻找输入数据在潜在空间中的分布特征,不同的数据会对应不同的分布参数,这些参数反映了数据的独特属性。
- 采样阶段:根据编码器输出的分布 N (μ, σ²) ,通过公式 z = μ + σ * ε 进行采样,其中μ是平均值,σ 是标准差, ε 是从标准正态分布 N (0, I) 中采样的噪声。采样操作是 VAE 生成多样性数据的关键步骤,由于引入了随机噪声,即使对于相同的输入数据,每次采样得到的潜在向量 z 也会有所不同,进而生成不同的重构数据。
- 解码阶段:采样得到的潜在向量 z 进入解码器,解码器将其转换回原始数据空间,生成重构数据 x’ 。解码器学习如何利用潜在向量中的信息,尽可能准确地重建出与输入数据相似的数据。
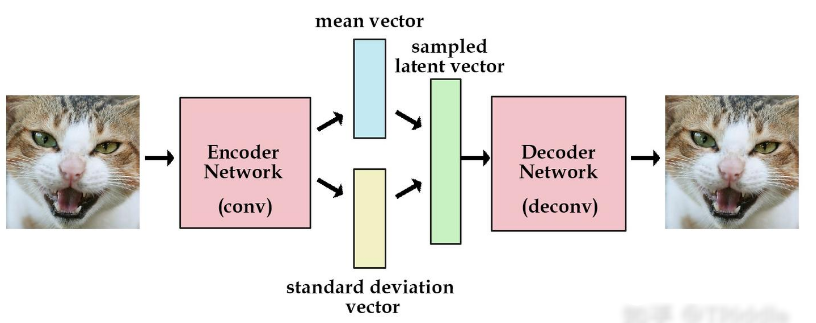
1.4 训练目标剖析
VAE 的训练目标是最大化证据下界(Evidence Lower Bound,ELBO) ,ELBO 由两部分组成:
- 重构损失(Reconstruction Loss):衡量原始输入 x 和重构输出 x’ 之间的相似度,常用均方误差(Mean Squared Error,MSE)或交叉熵(Cross Entropy)来计算。重构损失确保潜在表示 z 包含了足够的信息来重构 x,如果重构损失过大,说明解码器无法很好地利用潜在向量重建数据,或者编码器提取的潜在表示丢失了太多关键信息。
- KL 散度正则项(KL Divergence Regularizer):用于衡量编码器产生的潜在分布 q (z|x) 与一个预设的先验分布 p (z)(通常是标准正态分布 N (0, I))之间的差异。通过最小化 KL 散度,促使编码器产生的潜在分布尽可能地接近标准正态分布。这样做的好处是使潜在空间结构更规整,有利于从先验分布 p (z) 中采样生成新数据。如果 KL 散度为 0,那么潜在分布 q (z|x) 就与先验分布 p (z) 完全一致,此时潜在空间具有良好的连续性和可操作性,从潜在空间中任意采样都能生成合理的数据。
二、VAE 的应用场景
2.1 图像生成与编辑
- 图像生成:VAE 能够学习图像的潜在分布,从而生成逼真的图像。例如,在人脸图像生成任务中,通过在大量人脸图像数据集上训练 VAE,模型可以捕捉到人脸的各种特征,如五官的形状、位置、肤色等信息在潜在空间中的分布规律。从潜在空间中采样不同的点,经过解码器生成的人脸图像具有多样性,且看起来与真实人脸无异,这在影视特效制作、虚拟人物创建等领域有很大应用潜力。
- 图像风格迁移:可以利用 VAE 实现图像风格迁移。将源图像和目标风格图像分别编码到潜在空间,然后在潜在空间中对表示风格的特征进行融合或调整,再通过解码器生成具有目标风格的源图像内容。比如,将一幅普通照片转换为梵高风格的画作,VAE 能够分析出梵高画作的色彩、笔触等风格特征在潜在空间中的表示,并将其与普通照片的内容特征相结合,生成独特的艺术作品。
- 图像修复与超分辨率:对于损坏或低分辨率的图像,VAE 可以发挥修复和提升分辨率的作用。训练 VAE 时,输入损坏或低分辨率图像,让模型学习从这些不完美数据到完整、高分辨率图像的映射关系。在实际应用中,当遇到有划痕、噪点的老照片或者模糊不清的监控图像时,VAE 能够根据学习到的潜在表示对图像进行修复和增强,恢复图像的清晰度和完整性。
2.2 医疗领域的助力
- 医学图像分析:在医学图像领域,如 X 光、CT、MRI 图像,VAE 可用于图像降噪和特征提取。医疗图像常常受到噪声干扰,影响医生对病情的准确判断。VAE 通过学习正常图像的潜在分布,能够识别并去除噪声,同时提取出关键的医学特征,帮助医生更清晰地观察病变区域。例如,在肺部 CT 图像中,VAE 可以突出显示肺部结节等异常病变的特征,辅助医生进行疾病诊断。
- 生物信号处理:对于心电图(EEG)等生物信号,VAE 能够对其进行分析和处理。它可以学习到正常生物信号的模式,并通过潜在表示进行重构。当检测到异常生物信号时,由于其与正常信号在潜在空间中的分布差异,会产生较大的重构误差,从而帮助医生及时发现异常,用于心脏疾病的早期诊断和监测。
- 生成合成医疗数据:在医疗数据稀缺的情况下,VAE 可以生成合成医疗数据,用于模型训练和医学研究。例如,生成具有不同病情特征的虚拟患者数据,这些数据可以用于训练疾病预测模型、评估新的治疗方案效果等,有助于在真实数据有限的情况下推动医学研究的进展。
2.3 自然语言处理中的应用
- 文本生成:VAE 能够学习文本的潜在语义表示,并生成新的文本。在训练过程中,模型将输入文本编码到潜在空间,捕捉文本的主题、情感、语法结构等信息。从潜在空间中采样生成的文本可以保持与训练数据相似的语言风格和语义逻辑。例如,生成新闻报道、故事、诗歌等。以诗歌生成为例,VAE 可以学习不同诗歌的韵律、意象、情感表达等特征,生成富有诗意且语义连贯的诗句。
- 文本摘要:通过将长文本编码到潜在空间,VAE 可以提取文本的关键信息,生成简洁的文本摘要。模型能够理解文本中各部分内容的重要性,并在潜在表示中突出关键信息。解码时,生成的摘要保留了原文的核心观点和主要内容,帮助用户快速了解长文本的主旨,在信息检索、新闻资讯等领域有重要应用。
- 机器翻译辅助:在机器翻译中,VAE 可以帮助学习源语言和目标语言之间的潜在语义联系。将源语言文本编码到潜在空间后,通过调整潜在表示,使其更接近目标语言的语义分布,再解码生成目标语言文本。这种方式有助于提高机器翻译的准确性和流畅性,改善翻译质量。
2.4 其他领域的应用
- 异常检测:在工业生产、金融交易等领域,VAE 可用于检测异常情况。通过学习正常数据的潜在分布,当出现与正常分布差异较大的数据时,VAE 的重构误差会显著增大,从而识别出这些异常数据。例如,在工业生产线上,监测设备采集的数据如果出现异常波动,VAE 能够及时发出警报,帮助工作人员发现设备故障或生产过程中的问题;在金融交易中,检测异常的交易行为,防范欺诈风险。
- 时间序列预测:对于时间序列数据,如股票价格走势、天气预报数据等,VAE 可以学习时间序列的潜在模式,并生成未来的预测数据。模型能够捕捉时间序列中的趋势、周期等特征,通过潜在空间的表示进行外推预测。例如,预测未来一段时间内的股票价格变化,为投资者提供决策参考;预测未来的天气情况,帮助气象部门做好气象预警和资源调配。
- 强化学习中的应用:在强化学习中,VAE 可以用于学习环境状态的潜在表示,帮助智能体更好地理解环境信息,做出更优的决策。通过将复杂的环境状态编码到低维潜在空间,减少状态表示的维度,提高强化学习算法的效率和收敛速度。例如,在机器人控制任务中,VAE 帮助机器人快速理解周围环境状态,规划更合理的行动路径。
参考资料
- https://zhuanlan.zhihu.com/p/108262170
- https://zhuanlan.zhihu.com/p/719968411

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









