






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**
一、前期工作和数据预处理
#包含导包和数据,数据处理、检查和配置数据集
from tensorflow.keras import models, layers
import tensorflow as tf
import pathlib, PIL
import matplotlib.pyplot as plt
data_dir = "/Volumes/T7 Shield/code/shoes"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob("*/*/*.jpg")))
print(image_count)
roses = list(data_dir.glob("train/nike/*.jpg"))
PIL.Image.open(roses[0])
out[1]:578 #img_count

batch_size = 32
image_height = 224
image_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"/Volumes/T7 Shield/code/shoes/train",
image_size = (image_height, image_width),
batch_size = batch_size,
seed = 123
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"/Volumes/T7 Shield/code/shoes/test",
image_size = (image_height, image_width),
batch_size = batch_size,
seed = 123
)
class_names = val_ds.class_names
print(class_names)out[2]: Found 502 files belonging to 2 classes.
Found 76 files belonging to 2 classes.
['adidas', 'nike'] #class_names
plt.figure(figsize = (20, 10))
for image, labels in val_ds.take(1):
for i in range(20):
plt.subplot(5, 10, i+1)
plt.imshow(image[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")out[3]:

AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)二、搭建cnn网络:
#三个3*3卷积,两个平均池化,外加两个dropout层
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape = (image_height, image_width, 3)),
layers.Conv2D(16, (3, 3), activation = "relu", input_shape = (image_height, image_width, 3)),
layers.AveragePooling2D(2, 2),
layers.Conv2D(32, (3, 3), activation = "relu"),
layers.AveragePooling2D(2, 2),
layers.Dropout(0.3),
layers.Conv2D(64, (3,3), activation = "relu"),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(128, activation = "relu"),
layers.Dense(2)
])
model.summary()summary一下模型
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 222, 222, 16) 448
average_pooling2d (AverageP (None, 111, 111, 16) 0
ooling2D)
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_1 (Averag (None, 54, 54, 32) 0
ePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
dropout_1 (Dropout) (None, 52, 52, 64) 0
flatten (Flatten) (None, 173056) 0
dense (Dense) (None, 128) 22151296
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 22,175,138
Trainable params: 22,175,138
Non-trainable params: 0
_________________________________________________________________
三、编译
1. 学习率
这里的问题出在原代码里改了学习率,学习率太大了一直在跳,这里把初始lr改到了0.001,正确率达到了原代码的0.89474:
initial_learning_rate = 0.001
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps = 10,
decay_rate = 0.92,
staircase = True
)2. 优化器:
opt = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(
optimizer = opt,
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ["accuracy"]
)3. 加点小组件(checkpointer和earlystooping)
checkpointer = tf.keras.callbacks.ModelCheckpoint(
"best_model.h5",
monitor = "val_accuracy",
verbose = 1,
save_best_only = True,
save_weights_only = True
)
# earlystopping = tf.keras.callbacks.EarlyStopping(
# monitor = "val_accuracy",
# min_delta = 0.001,
# patience = 30,
# verbose = 1
# )#因为在看最后能跑到多少准确率,就把earlystopping注解了
四、模型训练:
epochs = 50
history = model.fit(
train_ds,
validation_data = val_ds,
epochs = epochs,
callbacks = [checkpointer]
)
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
Epoch 1/50 15/16 ━━━━━━━━━━━━━━━━━━━━ 0s 611ms/step - accuracy: 0.5082 - loss: 7.3733 Epoch 1: val_accuracy improved from -inf to 0.72368, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 15s 659ms/step - accuracy: 0.5110 - loss: 6.9457 - val_accuracy: 0.7237 - val_loss: 0.6176 Epoch 2/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.6835 - loss: 0.5930 Epoch 2: val_accuracy did not improve from 0.72368 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.6692 - loss: 0.6071 - val_accuracy: 0.6974 - val_loss: 0.6057 Epoch 3/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.7108 - loss: 0.5699 Epoch 3: val_accuracy did not improve from 0.72368 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.7147 - loss: 0.5641 - val_accuracy: 0.7105 - val_loss: 0.5437 Epoch 4/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.7161 - loss: 0.5444 Epoch 4: val_accuracy did not improve from 0.72368 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.7129 - loss: 0.5471 - val_accuracy: 0.6316 - val_loss: 0.5698 Epoch 5/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.7426 - loss: 0.5090 Epoch 5: val_accuracy improved from 0.72368 to 0.75000, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 63ms/step - accuracy: 0.7414 - loss: 0.5107 - val_accuracy: 0.7500 - val_loss: 0.5678 Epoch 6/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.7393 - loss: 0.4984 Epoch 6: val_accuracy improved from 0.75000 to 0.77632, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 62ms/step - accuracy: 0.7450 - loss: 0.4941 - val_accuracy: 0.7763 - val_loss: 0.4796 Epoch 7/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.8263 - loss: 0.3997 Epoch 7: val_accuracy did not improve from 0.77632 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 17ms/step - accuracy: 0.8310 - loss: 0.3977 - val_accuracy: 0.7632 - val_loss: 0.4676 Epoch 8/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.8544 - loss: 0.3663 Epoch 8: val_accuracy did not improve from 0.77632 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.8558 - loss: 0.3665 - val_accuracy: 0.7763 - val_loss: 0.4454 Epoch 9/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.8896 - loss: 0.3128 Epoch 9: val_accuracy improved from 0.77632 to 0.81579, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 4s 262ms/step - accuracy: 0.8902 - loss: 0.3136 - val_accuracy: 0.8158 - val_loss: 0.4194 Epoch 10/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9004 - loss: 0.2866 Epoch 10: val_accuracy did not improve from 0.81579 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.8968 - loss: 0.2890 - val_accuracy: 0.7895 - val_loss: 0.5074 Epoch 11/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.8945 - loss: 0.3077 Epoch 11: val_accuracy did not improve from 0.81579 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.8930 - loss: 0.3085 - val_accuracy: 0.7632 - val_loss: 0.4555 Epoch 12/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9072 - loss: 0.2591 Epoch 12: val_accuracy improved from 0.81579 to 0.82895, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 62ms/step - accuracy: 0.9078 - loss: 0.2585 - val_accuracy: 0.8289 - val_loss: 0.3995 Epoch 13/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9364 - loss: 0.2387 Epoch 13: val_accuracy did not improve from 0.82895 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9364 - loss: 0.2367 - val_accuracy: 0.8026 - val_loss: 0.3749 Epoch 14/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9595 - loss: 0.1921 Epoch 14: val_accuracy did not improve from 0.82895 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9559 - loss: 0.1958 - val_accuracy: 0.7895 - val_loss: 0.3649 Epoch 15/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9691 - loss: 0.1668 Epoch 15: val_accuracy did not improve from 0.82895 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9628 - loss: 0.1728 - val_accuracy: 0.8158 - val_loss: 0.3955 Epoch 16/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9615 - loss: 0.1708 Epoch 16: val_accuracy improved from 0.82895 to 0.84211, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 2s 121ms/step - accuracy: 0.9574 - loss: 0.1742 - val_accuracy: 0.8421 - val_loss: 0.3746 Epoch 17/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9718 - loss: 0.1319 Epoch 17: val_accuracy did not improve from 0.84211 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9705 - loss: 0.1348 - val_accuracy: 0.7895 - val_loss: 0.3599 Epoch 18/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9560 - loss: 0.1589 Epoch 18: val_accuracy did not improve from 0.84211 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9568 - loss: 0.1577 - val_accuracy: 0.7763 - val_loss: 0.3542 Epoch 19/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9448 - loss: 0.1468 Epoch 19: val_accuracy did not improve from 0.84211 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9499 - loss: 0.1435 - val_accuracy: 0.8289 - val_loss: 0.3404 Epoch 20/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9627 - loss: 0.1271 Epoch 20: val_accuracy did not improve from 0.84211 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9632 - loss: 0.1276 - val_accuracy: 0.8421 - val_loss: 0.3270 Epoch 21/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9788 - loss: 0.1303 Epoch 21: val_accuracy improved from 0.84211 to 0.86842, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 62ms/step - accuracy: 0.9779 - loss: 0.1287 - val_accuracy: 0.8684 - val_loss: 0.3635 Epoch 22/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9822 - loss: 0.1072 Epoch 22: val_accuracy did not improve from 0.86842 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9793 - loss: 0.1093 - val_accuracy: 0.8421 - val_loss: 0.3243 Epoch 23/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9845 - loss: 0.0964 Epoch 23: val_accuracy improved from 0.86842 to 0.89474, saving model to best_model.weights.h5 16/16 ━━━━━━━━━━━━━━━━━━━━ 1s 62ms/step - accuracy: 0.9830 - loss: 0.0978 - val_accuracy: 0.8947 - val_loss: 0.3190 Epoch 24/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9755 - loss: 0.1034 Epoch 24: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9756 - loss: 0.1040 - val_accuracy: 0.8289 - val_loss: 0.3195 Epoch 25/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9782 - loss: 0.0975 Epoch 25: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9779 - loss: 0.0966 - val_accuracy: 0.8816 - val_loss: 0.3066 Epoch 26/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9755 - loss: 0.1012 Epoch 26: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9758 - loss: 0.1002 - val_accuracy: 0.8684 - val_loss: 0.3077 Epoch 27/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9771 - loss: 0.0921 Epoch 27: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9771 - loss: 0.0917 - val_accuracy: 0.8947 - val_loss: 0.3060 Epoch 28/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9871 - loss: 0.0825 Epoch 28: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9866 - loss: 0.0844 - val_accuracy: 0.8553 - val_loss: 0.3174 Epoch 29/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9521 - loss: 0.1154 Epoch 29: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9561 - loss: 0.1104 - val_accuracy: 0.8421 - val_loss: 0.3100 Epoch 30/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9904 - loss: 0.0769 Epoch 30: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9881 - loss: 0.0783 - val_accuracy: 0.8947 - val_loss: 0.3013 Epoch 31/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9829 - loss: 0.0853 Epoch 31: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9824 - loss: 0.0851 - val_accuracy: 0.8947 - val_loss: 0.2996 Epoch 32/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9746 - loss: 0.0935 Epoch 32: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9752 - loss: 0.0915 - val_accuracy: 0.8947 - val_loss: 0.3012 Epoch 33/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9932 - loss: 0.0719 Epoch 33: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9910 - loss: 0.0744 - val_accuracy: 0.8947 - val_loss: 0.3006 Epoch 34/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9742 - loss: 0.0802 Epoch 34: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9739 - loss: 0.0806 - val_accuracy: 0.8947 - val_loss: 0.3002 Epoch 35/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9876 - loss: 0.0812 Epoch 35: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9862 - loss: 0.0803 - val_accuracy: 0.8947 - val_loss: 0.3010 Epoch 36/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9809 - loss: 0.0893 Epoch 36: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9824 - loss: 0.0862 - val_accuracy: 0.8816 - val_loss: 0.3063 Epoch 37/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9823 - loss: 0.0873 Epoch 37: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step - accuracy: 0.9835 - loss: 0.0866 - val_accuracy: 0.8947 - val_loss: 0.3014 Epoch 38/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9727 - loss: 0.0840 Epoch 38: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9737 - loss: 0.0835 - val_accuracy: 0.8947 - val_loss: 0.3000 Epoch 39/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9924 - loss: 0.0641 Epoch 39: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9899 - loss: 0.0670 - val_accuracy: 0.8947 - val_loss: 0.2997 Epoch 40/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9857 - loss: 0.0771 Epoch 40: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step - accuracy: 0.9853 - loss: 0.0760 - val_accuracy: 0.8947 - val_loss: 0.3000 Epoch 41/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9958 - loss: 0.0703 Epoch 41: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9938 - loss: 0.0708 - val_accuracy: 0.8947 - val_loss: 0.3001 Epoch 42/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9864 - loss: 0.0670 Epoch 42: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9858 - loss: 0.0679 - val_accuracy: 0.8947 - val_loss: 0.2987 Epoch 43/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9808 - loss: 0.0822 Epoch 43: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9809 - loss: 0.0815 - val_accuracy: 0.8947 - val_loss: 0.2984 Epoch 44/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9865 - loss: 0.0760 Epoch 44: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9858 - loss: 0.0762 - val_accuracy: 0.8947 - val_loss: 0.2981 Epoch 45/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9807 - loss: 0.0799 Epoch 45: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9820 - loss: 0.0779 - val_accuracy: 0.8947 - val_loss: 0.2977 Epoch 46/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9740 - loss: 0.0852 Epoch 46: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9762 - loss: 0.0829 - val_accuracy: 0.8947 - val_loss: 0.2979 Epoch 47/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9756 - loss: 0.0744 Epoch 47: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9771 - loss: 0.0740 - val_accuracy: 0.8947 - val_loss: 0.2984 Epoch 48/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9830 - loss: 0.0688 Epoch 48: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9823 - loss: 0.0704 - val_accuracy: 0.8947 - val_loss: 0.2986 Epoch 49/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9787 - loss: 0.0873 Epoch 49: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9793 - loss: 0.0850 - val_accuracy: 0.8947 - val_loss: 0.2982 Epoch 50/50 13/16 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - accuracy: 0.9885 - loss: 0.0714 Epoch 50: val_accuracy did not improve from 0.89474 16/16 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - accuracy: 0.9883 - loss: 0.0723 - val_accuracy: 0.8947 - val_loss: 0.2979
五、模型评估:
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(len(loss))
plt.figure(figsize = (12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs, acc, label = "train accuracy")
plt.plot(epochs, val_acc, label = "validation accuracy")
plt.legend(loc = "lower right")
plt.title("Accuracy")
plt.subplot(1, 2, 2)
plt.plot(epochs, loss, label = "train loss")
plt.plot(epochs, val_loss, label = "validation loss")
plt.legend(loc = "lower right")
plt.title("Loss")
plt.show()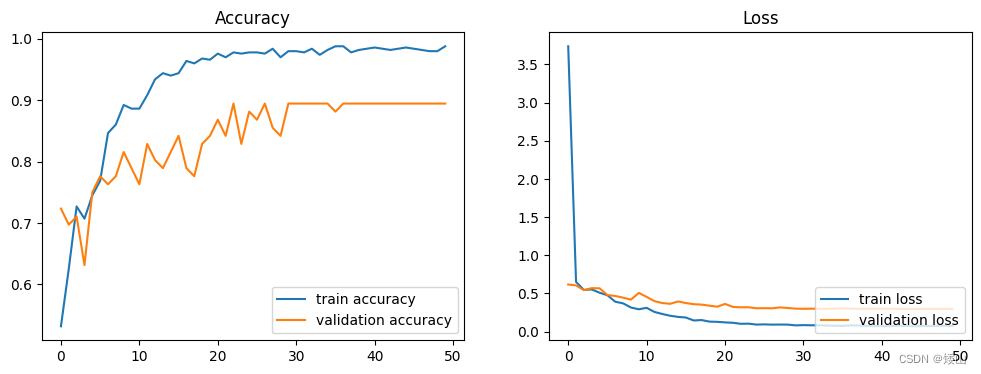
六、总结:
很神奇的是,半个月前选学习率的时候,在本地用cpu跑的0.001只能达到0.7几左右,到0.0005才能到0.85,0.0001的话就50轮完全不够用,收敛不到家(无论如何都跑不到原代码的0.89),遂放弃。半个月后为了写这周的笔记,同样的参数只能达到0.7几的准确率,完全和之前的结果不一样......于是放到gpu上跑,lr在0.001是和原代码跑出来的结果基本一样的(曲线还是有点不大相同),可以知道lr的正确答案应该就是0.001,但是差距这么大是我没想到的...















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









