







前言
前言废话依旧比较多,感觉我是个写游戏体验评测的,233。最近想起了《恶灵附身》这款游戏的几个效果:



《恶灵附身》整款游戏都是在一个“疯子”撸总的脑洞世界里面,游戏内容相当恐怖(吓得我当年一边尖叫一边玩,不光把我吓够呛,把我室友也吓坏了),有“贞子”,“保险箱怪”等等至今让我久久不能忘怀的Boss,不过整个游戏既有恐怖的地方,又有刺激的战斗,非常符合三上真司一贯的作风(我是三上生化危机系列的铁粉,哇咔咔),可惜《恶灵附身2》玩法有点转型,类似《丧尸围城》了,前半段很好,后半段不知是否是经费不足,感觉整体不如前半段好。不过还是很期待续作的。
既然整款游戏都是在脑洞世界里面,所以整个游戏的过程完全不按照常理出牌,可能前一秒还在平静的医院走廊,下一秒直接就直接切换到满是怪物的场景。整个游戏里面大量运用了各种好玩的效果,上面的屏幕扭曲,屏幕扫描波,高度雾效(个人感觉《恶灵附身》里面的应该是特效做的,不过本文的实现方式不太一样罢了)就都其中之一,今天主要是来整理一波深度图的各种知识点,然后做几个好玩的效果。
简介
深度是个好东西哇,很多效果都需要深度,比如景深,屏幕空间扫描效果,软粒子,阴影,SSAO,近似次表面散射(更确切的说是透射),对于延迟渲染来说,还可以用深度反推世界空间位置降低带宽消耗,还可以用深度做运动模糊,屏幕空间高度雾,距离雾,部分Ray-Marching效果也都需要深度,可以说,深度是一些渲染高级效果必要的条件。另一方面,光栅化渲染本身可以得到正确的效果,就与深度(Z Buffer)有着密不可分的关系。
深度对于实时渲染的意义十分重大,OpenGL,DX,Unity为我们封装好了很多深度相关的内容,如ZTest,ZWrite,CameraDepthMode,Linear01Depth等等。今天我来整理一下与学习过程中遇到的深度相关的一些问题,主要是渲染中深度的一些问题以及Unity中深度图生成,深度图的使用,深度的精度,Reverse-Z等等问题,然后再用深度图,实现一些好玩的效果。本人才疏学浅,如果有不正确的地方,还望各位高手批评指正。
画家算法&ZBuffer算法
在渲染中为了保证渲染的正确,其实主要得益于两个最常用的算法,第一个是画家算法。所谓画家算法,就是按照画画的顺序,先画远处的内容,再画近处的内容叠加上去,近处的会覆盖掉远处的内容。即,在绘制之前,需要先按照远近排序。但是画家算法有一个很严重的问题,对于自身遮挡关系比较复杂的对象,没有办法保证绘制的正确;无法进行检测,overdraw比较严重;再者对对象排序的操作,不适合硬件实现。
而另一种保证深度正确的算法就是ZBuffer算法,申请一块和FrameBuffer大小一样的缓冲区,如果开启了深度测试,那么在最终写入FrameBuffer之前(Early-Z实现类似,只是时机效果不同),就需要进行测试,比如ZTest LEqual的话,如果深度小于该值,那么通过深度测试,如果开启了深度写入,还需要顺便更新一下当前点的深度值,如果不通过,就不会写入FrameBuffer。ZBuffer保证像素级别的深度正确,并且实现简单,比起靠三角形排序这种不确定性的功能更加容易硬件化,所以目前的光栅化渲染中大部分都使用的是ZBuffer算法。ZBuffer算法也有坏处,第一就是需要一块和颜色缓冲区一样大小的Buffer,精度还要比较高,所以比较费内存,再者需要逐像素计算Z值,但是为了渲染的正确,也就是透视校正纹理映射,Z值的计算是不可避免的,所以总体来看,ZBuffer的优势还是比较明显的。关于ZBuffer的实现以及透视投影纹理映射,可以参照软渲染实现。
对于不透明物体来说,ZBuffer算法是非常好的,可以保证遮挡关系没有问题。但是透明物体的渲染,由于一般是不写深度的,所以经常会出现问题,对于透明物体,一般还是采用画家算法,即由远及近进行排序渲染。还有一种方案是关闭颜色写入,先渲染一遍Z深度,然后再渲染半透,就可以避免半透明对象内部也被显示出来的问题,可以参考之前的遮挡处理这篇文章中遮挡半透的做法。
透视投影与光栅化过程
透视投影的主要知识点在于三角形相似以及小孔呈像,透视投影实现的就是一种“近大远小”的效果,其实投影后的大小(x,y坐标)也刚好就和1/Z呈线性关系。看下面一张图:
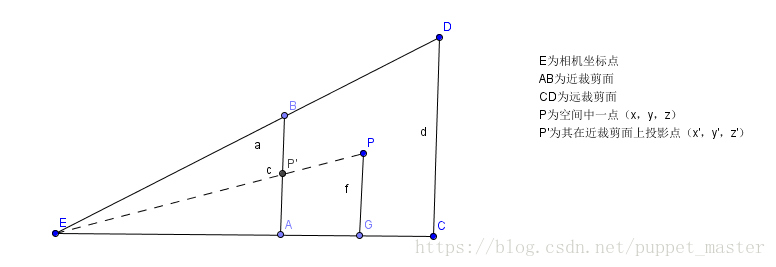
上图是一个视锥体的截面图(只看x,z方向),P为空间中一点(x,y,z),那么它在近裁剪面处的投影坐标假设为P’(x',y',z’),理论上来说,呈像的面应该在眼睛后方才更符合真正的小孔呈像原理,但是那样会增加复杂度,没必要额外引入一个负号(此处有一个裁剪的注意要点,下文再说),只考虑三角形相似即可。即三角形EAP’相似于三角形EGP,我们可以得到两个等式:
x’/ x = z’/ z => x’= xz’/ z
y’/ y = z’/ z => y’= yz’/ z
由于投影面就是近裁剪面,那么近裁剪面是我们可以定义的,我们设其为N,远裁剪面为F,那么实际上最终的投影坐标就是:
(Nx/z,Ny/z,N)。
投影后的Z坐标,实际上已经失去作用了,只用N表示就可以了,但是这个每个顶点都一样,每个顶点带一个的话简直是暴殄天物,浪费了一个珍贵的维度,所以这个Z会被存储一个用于后续深度测试,透视校正纹理映射的变换后的Z值。
但是还有一个问题,这里我们得到是只是顶点的Z值,也就是我们在vertex shader中计算的结果,只有顶点,但是实际上,我们在屏幕上会看到无数的像素,换句话说,这些顶点的信息都是离散的,但是最终显示在屏幕上的模型却是连续的,这个那么每个像素点的值是怎么得到的呢?其实就是插值。一个三角形光栅化到屏幕空间上时,我们仅有的就是在三角形三个顶点所包含的各种数据,其中顶点已经是被变换过的了(Unity中常用的MVP变换),在绘制三角形的过程中,根据屏幕空间位置对上述数据进行插值计算,来获得顶点之间对应屏幕上像素点上的颜色或其他数据信息。
这个Z值,还是比较有说道的。在透视投影变换之前,我们的Z实际上是相机空间的Z值,直接把这个Z存下来也无可厚非,但是后续计算会比较麻烦,毕竟没有一个统一的标准。既然我们有了远近裁剪面,有了Z值的上下限,我们就可以把这个Z值映射到[0,1]区间,即当在近裁剪面时,Z值为0,远裁剪面时,Z值为1(暂时不考虑reverse-z的情况)。
首先,能想到的最简单的映射方法就是depth = (Z(eye) - N)/ F - N。直接线性映射到(0,1)区间,但是这种方案是不正确的,看下面一张图:
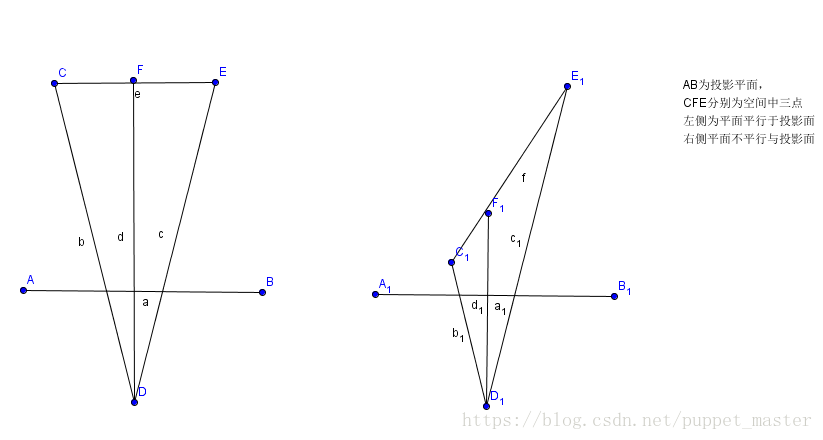
右侧的三角形,在AB近裁剪面投影的大小一致,而实际上C1F1和F1E1相差的距离甚远,换句话说,经过投影变换的透视除法后,我们在屏幕空间插值的数据(根据屏幕空间距离插值),并不能保证其对应点在投影前的空间是线性变换的。关于透视投影和光栅化,可以参照上一篇文章中软渲染透视投影和光栅化的内容。
透视投影变换之后,在屏幕空间进行插值的数据,与Z值不成正比,而是与1/Z成正比。所以,我们需要一个表达式,可以使Z = N时,depth = 0,Z = F时,depth = 1,并且需要有一个z作为分母,可以写成(az + b)/z,带入上述两个条件:
(N * a + b) / N = 0 => b = -an
(F * a + b) / F = 0 => aF + b = F => aF - aN = F
进而得到:
a = F / (F - N)
b = NF / (N - F)
最终depth(屏幕空间) = (aZ + b)/ Z (Z为视空间深度)。
通过透视投影,在屏幕空间X,Y值都除以了Z(视空间深度),当一个值的Z趋近于无穷远时,那么X,Y值就趋近于0了,也就是类似近大远小的效果了。而对于深度值的映射,从上面看也是除以了Z的,这个现象其实也比较好理解,比如一个人在离相机200米的地方前进了1米,我们基本看不出来距离的变化,但是如果在相机面前2米处前进了1米,那么这个距离变化是非常明显的,这也是近大远小的一种体现。
Unity中生成深度图
先来考古一下,我找到了一个上古时代的Unity版本,4.3,在4.X的时代,Unity生成深度图使用的还是Hidden/Camera-DepthTexture这个函数,机制就是使用Replacement Shader,在渲染时将shader统一换成Hidden/Camera-DepthTexture,不同类型的RenderType对应不同的SubShader,比如带有Alpha Test就可以在fragment阶段discard掉不需要的部分,防止在深度图中有不该出现的内容。那时候,也许还有些设备不支持原生的DepthTexture RT格式(SM2.0以上,DepthTexture支持)还有一个UNITY_MIGHT_NOT_HAVE_DEPTH_TEXTURE的宏,针对某些不支持深度格式的RT,使用普通的RGBA格式编码深度图进行输出,采样时再将RGBA解码变回深度信息,使用编码的好处主要在于可以充分利用颜色的四个通道(32位)获得更高的精度,否则就只有一个通道(8位),编码和解码的函数如下:
// Encoding/decoding [0..1) floats into 8 bit/channel RGBA. Note that 1.0 will not be encoded properly.
inline float4 EncodeFloatRGBA( float v )
{
float4 kEncodeMul = float4(1.0, 255.0, 65025.0, 160581375.0);
float kEncodeBit = 1.0/255.0;
float4 enc = kEncodeMul * v;
enc = frac (enc);
enc -= enc.yzww * kEncodeBit;
return enc;
}
inline float DecodeFloatRGBA( float4 enc )
{
float4 kDecodeDot = float4(1.0, 1/255.0, 1/65025.0, 1/160581375.0);
return dot( enc, kDecodeDot );
}深度图生成的函数如下,其实那时绝大多数情况都已经支持DepthFormat格式了,所以直接使用了空实现,颜色返回为0:
#if defined(UNITY_MIGHT_NOT_HAVE_DEPTH_TEXTURE)
#define UNITY_TRANSFER_DEPTH(oo) oo = o.pos.zw
#if SHADER_API_FLASH
#define UNITY_OUTPUT_DEPTH(i) return EncodeFloatRGBA(i.x/i.y)
#else
#define UNITY_OUTPUT_DEPTH(i) return i.x/i.y
#endif
#else
#define UNITY_TRANSFER_DEPTH(oo)
#define UNITY_OUTPUT_DEPTH(i) return 0
#endif在Unity5.X版本后,实际上深度的pass就变为了ShadowCaster这个pass,而不需要再进行Shader Raplacement的操作了(但是DepthNormalMap仍然需要),所谓ShadowCaster这个pass,其实就是用于投影的Pass,Unity的所有自带shader都带这个pass,而且只要我们fallback了Unity内置的shader,也会增加ShadowCaster这个pass。我们应该也可以自己定义ShadowCaster这个pass,防止类似AlphaTest等造成深度图中内容与实际渲染内容不符的情况。
ShadowCaster这个pass实际上是有两个用处,第一个是屏幕空间的深度使用该pass进行渲染,另一方面就是ShadowMap中光方向的深度也是使用该pass进行渲染的,区别主要在与VP矩阵的不同,阴影的pass是相对于光空间的深度,而屏幕空间深度是相对于摄像机的。新版的Unity使用了ScreenSpaceShadowMap,屏幕空间的深度也是必要的(先生成DpehtTexture,再生成ShadowMap,然后生成ScreenSpaceShadowMap,再正常渲染物体采样ScreenSpaceShadowMap)。所以,如果我们开了屏幕空间阴影,再使用DepthTexture,就相当于免费赠送,不用白不用喽。
新版本的Unity,本人目前使用的是Unity2017.3版本,VS和PS阶段的宏直接全部改为了空实现:
// Legacy; used to do something on platforms that had to emulate depth textures manually. Now all platforms have native depth textures.
#define UNITY_TRANSFER_DEPTH(oo)
// Legacy; used to do something on platforms that had to emulate depth textures manually. Now all platforms have native depth textures.
#define UNITY_OUTPUT_DEPTH(i) return 0
而ShadowCaster的实现也是颇为简单,VS阶段不考虑ShadowBias的情况下其实就是MVP变换,而PS也直接是空实现:
#define SHADOW_CASTER_FRAGMENT(i) return 0;为何Unity会如此肆无忌惮,直接空实现我们就可以得到一张深度图呢?我们可以用framedebugger看到我们使用的深度图的格式实际上是DepthFormat:
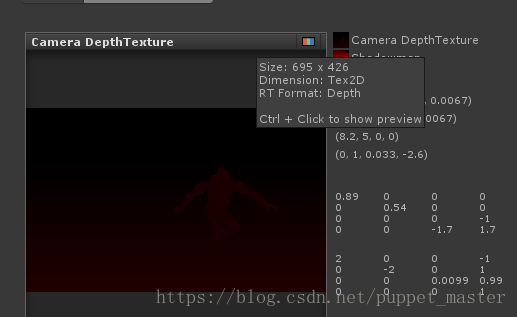
正如上文中Untiy新版本shader注释中所说的,“现在所有平台都支持原生的深度图了",所以也就没有必要再RGBA格式编码深度然后在进行解码这种费劲的方法,直接申请DepthFormat格式的RT即可,也就是在采样时,只将DepthAttachment的内容作为BindTexture的id。ColorBuffer输出的颜色是什么都无所谓了,我们要的只是DepthBuffer的输出,而这个输出的结果就是正常我们渲染时的深度,也就是ZBuffer中的深度值,只是这个值系统自动帮我们处理了,类似固定管线Native方式。
至于Unity为何不直接用FrameBuffer中的Z,而是使用全场景渲染一遍的方式,个人猜测是为了更好的兼容性吧(如果有大佬知道,还望不吝赐教),再者本身一张RT同时读写在某些平台就是未定义的操作,可能出现问题(本人之前测试是移动平台上大部分都挂了,这也是为什么很多后处理,比如高斯模糊等在申请RT的时候要申请两块,在两块RT之间互相Blit的原因)。倒是之前了解过一个黑科技,直接bind一张RT的DepthAttachment到depth上,然后读这张RT就是深度了,然而没有大面积真机测试过,真是不太敢用 。
深度图的使用
大概了解了一下Unity中深度图的由来,下面准备使用深度图啦。虽然前面说了这么多,然而实际上在Unity中使用深度图,却是一个简单到不能再简单的操作了,通过Camera的depthTextureMode即可设置DepthTexture。我们来用一个后处理效果把当前的深度图绘制到屏幕上:
/********************************************************************
FileName: DepthTextureTest.cs
Description:显示深度贴图
Created: 2018/05/27
history: 27:5:2018 1:25 by puppet_master
*********************************************************************/
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
[ExecuteInEditMode]
public class DepthTextureTest : MonoBehaviour
{
private Material postEffectMat = null;
private Camera currentCamera = null;
void Awake()
{
currentCamera = GetComponent<Camera>();
}
void OnEnable()
{
if (postEffectMat == null)
postEffectMat = new Material(Shader.Find("DepthTexture/DepthTextureTest"));
currentCamera.depthTextureMode |= DepthTextureMode.Depth;
}
void OnDisable()
{
currentCamera.depthTextureMode &= ~DepthTextureMode.Depth;
}
void OnRenderImage(RenderTexture source, RenderTexture destination)
{
if (postEffectMat == null)
{
Graphics.Blit(source, destination);
}
else
{
Graphics.Blit(source, destination, postEffectMat);
}
}
}Shader部分:
//puppet_master
//2018.5.27
//显示深度贴图
Shader "DepthTexture/DepthTextureTest"
{
CGINCLUDE
#include "UnityCG.cginc"
sampler2D _CameraDepthTexture;
fixed4 frag_depth(v2f_img i) : SV_Target
{
float depthTextureValue = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);
//float linear01EyeDepth = LinearEyeDepth(depthTextureValue) * _ProjectionParams.w;
float linear01EyeDepth = Linear01Depth(depthTextureValue);
return fixed4(linear01EyeDepth, linear01EyeDepth, linear01EyeDepth, 1.0);
}
ENDCG
SubShader
{
Pass
{
ZTest Off
Cull Off
ZWrite Off
Fog{ Mode Off }
CGPROGRAM
#pragma vertex vert_img
#pragma fragment frag_depth
ENDCG
}
}
}依然是我最常用的测试场景,哇咔咔,场景原始效果如下:

显示深度效果如下:

上面的Shader中我们使用了SAMPLE_DEPTH_TEXTURE这个宏进行了深度图的采样,其实这个宏就是采样了DepthTexuter的r通道作为深度(除在PSP2平台不一样),其余平台的定义都是下面的:
define SAMPLE_DEPTH_TEXTURE(sampler, uv) (tex2D(sampler, uv).r)LinearEyeDepth&Linear01Depth
在上面的Shader中,我们使用了LinearEyeDepth和LinearDepth对深度进行了一个变换之后才输出到屏幕,那么实际上的Z值应该是啥样的呢,我放置了四个距离相等的模型,来看一下常规的Z值直接输出的情况(由于目前开启了Reverse-Z,所以用1-z作为输出),即:
float depthTextureValue = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv);
return 1 - depthTextureValue;效果:

经过Linear01Depth变换后的效果:

对比两张图我们应该也就比较清楚效果了,没有经过处理的深度,在视空间上不是线性变化的,近处深度变化较明显,而远处几乎全白了,而经过处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









