










走过路过不要错过,先关注一下,第一时间获取最新进度(或催更)

从零手搓中文大模型|🚀 Day05
模型预训练完啦 🎉
在Day 04的内容里已经介绍过了我的参数配置,在这个配置下呢我训练了200k step。
由于数据集比较小,参数量级也不大,在这个步数上validation loss的下降已经非常缓慢了,所以我停止了训练。
wandb的曲线如下:
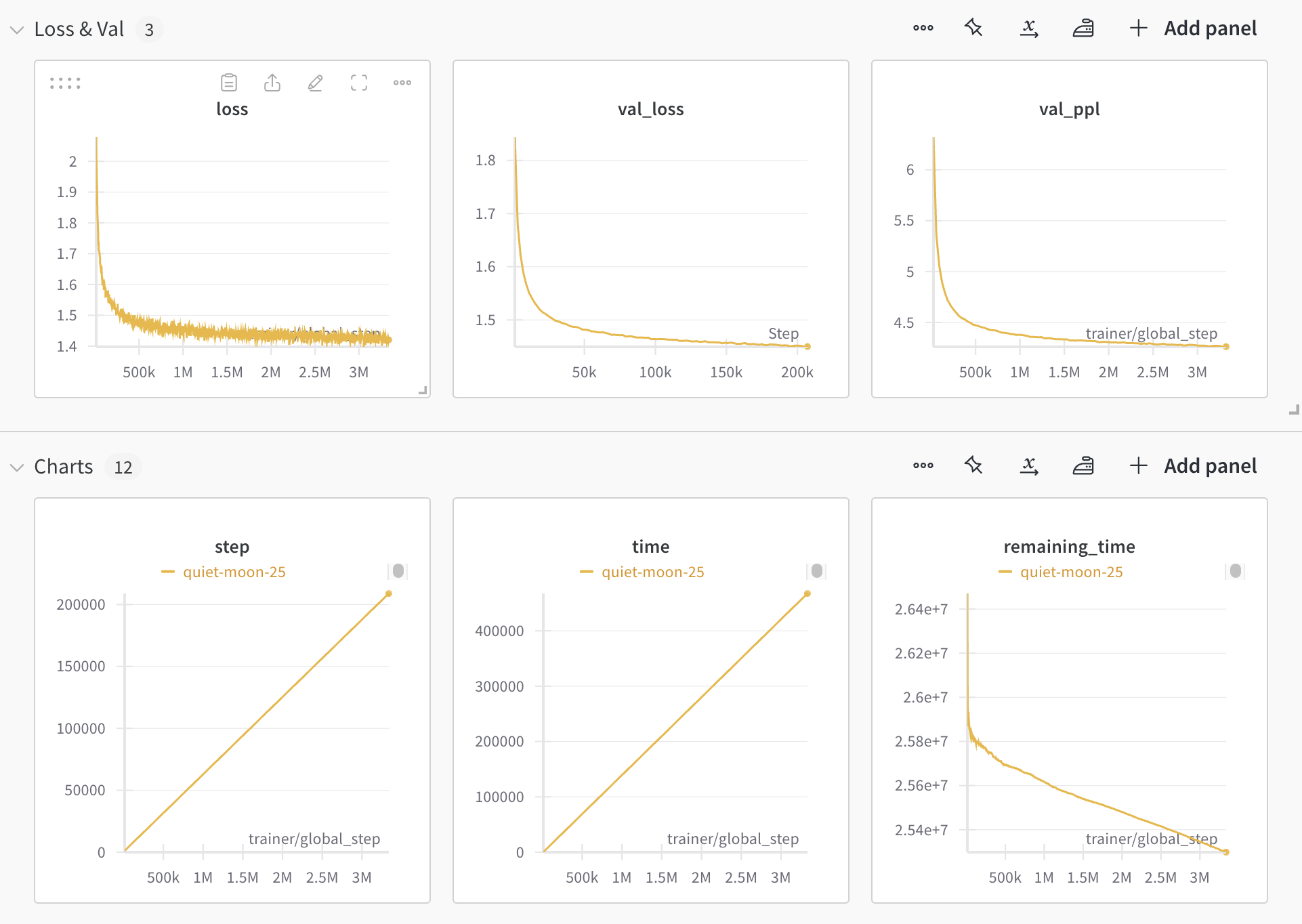
每1000 step保存一次模型,所以现在我已经有200多个模型了。
然后看看最后几个模型文件👇:
! ls ../../Experiments/Output/pretrain/microstories | tail -5
step-00205000
step-00206000
step-00207000
step-00208000
step-00209000
让我们看看模型效果吧 🥳
模型inference测试
直接使用litgpt.api里的代码,我们用第一个checkpoint来尝试生成一些文本。
from litgpt import LLM
llm = LLM.load(model="../../Experiments/Output/pretrain/microstories/step-00001000")
llm.generate(
prompt="汤姆和杰瑞是好朋友,",
max_new_tokens=500,
temperature=0.8,
top_p=0.9,
top_k=30,
)
可以看到训练了1000 steps的模型已经可以生成一些连贯的文本了,但是长度非常短。
看一眼0.044B模型的显存占用:
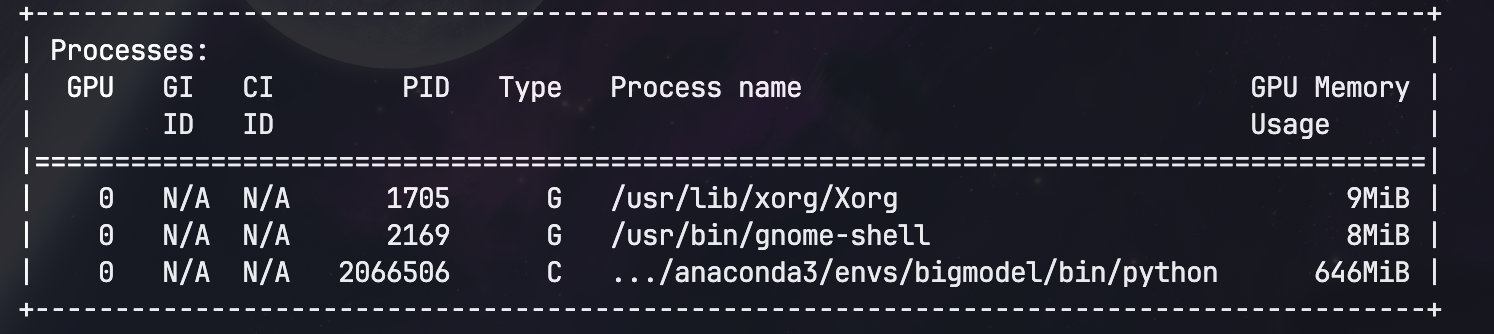
毕竟只有44M参数,GPU占用连650M都不到。
批量测试
我接下来从200多个checkpoints中每20个选一个,来测试一下效果。
import gc
prompt = "汤姆和杰瑞是好朋友,"
for i in range(20, 220, 20):
llm = LLM.load(
model=f"../../Experiments/Output/pretrain/microstories/step-{i*1000:08d}"
)
print(f"step-{i*1000:08d}")
print("-" * 13)
result = llm.generate(
prompt=prompt,
max_new_tokens=500,
temperature=0.8,
top_p=0,
top_k=30,
)
result = prompt + "\n".join(filter(lambda x: x.strip(), result.split("\n")))
print(result)
print("*" * 100)
print("\n")
del llm
gc.collect()
step-00020000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们不知道里面有什么。他们想打开它看看里面有什么。
“我们打开箱子吧!”汤姆说。杰瑞同意了。他们试图打开箱子,但太难了。他们推拉,但箱子没有打开。他们很伤心。
然后,他们看到一个高大的男人。他戴着一顶大帽子,穿着长外套。他看到汤姆和杰瑞,微笑了。
“你们好,孩子们。你们想要个礼物吗?”他问。
“是的,请!”汤姆和杰瑞说。
“你们想要什么?”男人问。
“你们想要什么?”汤姆和杰瑞问。
“你们想要什么?”男人问。
“你们想要什么?”汤姆和杰瑞问。
男人想了一下。他喜欢汤姆和杰瑞。他们喜欢他。
“你们想要什么?”男人问。
“你们想要什么?”汤姆和杰瑞问。
男人想了一下。他喜欢汤姆和杰瑞。他们很好奇。
“你们想要什么?”男人问。
“你们想要一个玩具。一个球。一个球。你们想要一个球。你们想要一个球吗?”男人问。
汤姆和杰瑞瑞点点头。他们喜欢球。
男人给了他们一个球。它很软,弹跳得很高。汤姆和杰瑞很高兴。他们感谢了男人。
男人微笑着。他很高兴他们喜欢这个礼物。他喜欢这个礼物。
汤姆和杰瑞也很高兴。他们有了一个新朋友。他们有了新玩具。他们有了新朋友。他们有了新的玩具。他们有了新的玩具。他们有了新的朋友。他们很开心。
****************************************************************************************************
step-00040000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们想看看里面有什么东西。
“我们打开看看吧!”汤姆说。
“好的!”杰瑞说。
他们试图打开箱子,但太难了。他们推拉了一下,但箱子没有打开。他们很伤心,也很累。
“也许我们可以用棍子打开它。”汤姆说。
他找到一根棍子,试图打开箱子。但是棍子太短了,打不开。他试了又试,但棍子就是打不开。
“也许我们可以用棍子打开箱子。”杰瑞说。
他找到一根棍子,试图打开箱子。但棍子太短了,打不开。他试了又试,但棍子就是打不开。
“也许我们需要一个工具。”汤姆说。
他四处张望,看到地上有一根棍子。他捡起来,用它砸向箱子。
“哎哟!”汤姆说。
他放下棍子,看着箱子。它又大又重,盖子也打不开。
“也许我们可以用这个棍子打开箱子。”汤姆说。
他捡起一根棍子,扔向箱子。棍子打中了箱子,发出很大的响声。
“砰!砰!”箱子破了。
汤姆和杰瑞瑞都笑了。他们觉得很有趣。
“看,我们成功了!”汤姆说。
“我们打开了箱子!”杰瑞说。
他们跑向箱子,试图打开它。
但是箱子太重了。他们打不开。
他们听到一声巨响。
“砰!”箱子破了。
他们看着箱子,看到箱子破了。
他们很伤心。
他们看着彼此。
他们拥抱了一下,说:“对不起。”
他们决定一起玩箱子。他们用箱子做了一个房子。他们用箱子做了一个门和一个窗户。他们用箱子做了一个门和一个窗户。
他们很高兴。
他们说:“我们爱你们。”
他们说:“我们爱你们。”
他们说:“我们爱。”
他们玩得很开心。
****************************************************************************************************
step-00060000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去冒险。
他们走啊走,直到发现一棵大树。汤姆说:“我们爬上这棵树吧!”杰瑞说:“好的,但要小心!”于是,汤姆和杰瑞开始爬树。他们越爬越高,直到到达一个鸟巢。
在鸟巢里,他们发现了一个大蛋。汤姆说:“哇,看看这个蛋!它好大啊!”杰瑞说:“我们把它带回家吧!”于是,他们把蛋带回了鸟巢。
但是当他们回到家时,发现蛋不见了!汤姆和杰瑞很伤心。他们到处找蛋,但找不到。然后,他们听到一声响动。他们看到蛋在动!蛋裂开了,一只小鸟出来了。小鸟说:“谢谢你们把我吵醒!”汤姆和杰瑞很高兴,他们交了一个新朋友。
****************************************************************************************************
step-00080000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们发现了一个大箱子。他们想看看里面有什么。
汤姆说:“我们打开箱子吧!” 杰瑞同意了,于是他们打开了箱子。里面有很多玩具。他们非常高兴,开始玩这些玩具。
但是,接下来发生了一件意想不到的事情。这些玩具开始说话了!玩具们说:“你们好,汤姆和杰瑞!我们是魔法玩具。我们来给你们一个惊喜!” 汤姆和杰瑞非常惊讶,但他们也很兴奋。他们和魔法玩具们一起玩了一整天,度过了很多快乐时光。
****************************************************************************************************
step-00100000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了一些三明治、水果和果汁。
当他们到达公园时,发现了一个大而可怕的森林。他们很害怕,但他们想探索一下。他们走了又走,直到发现一棵大树。他们爬上树,看到了一个鸟巢。他们想看看里面有什么,于是伸手去拿。
突然,他们听到一声巨响。是一只熊!熊生气了,开始追赶他们。汤姆和杰瑞跑得很快,但熊跑得更快。他们跑啊跑,但熊跑得更快。他们试图躲起来,但熊找到了他们。他们非常害怕,不知道该怎么办。
熊越来越近,他们不知道该怎么办。他们试图呼救,但没有人听到。熊吃了他们,然后他们就再也没有出现过。结束。
****************************************************************************************************
step-00120000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了三明治、水果和饼干。
当他们到达公园时,他们看到一个大牌子上面写着“禁止进入”。汤姆和杰瑞很伤心,因为他们想玩,但又不希望违反规定。他们决定偷偷溜进公园,玩捉迷藏游戏。
在玩捉迷藏时,他们听到一声巨响。是一只大狗!狗追着他们,他们跑得很快。他们试图逃跑,但狗跑得太快了。突然,他们看到一个写着“禁止进入”的标志。他们很害怕,不知道该怎么办。
就在这时,一位好心的女士看到了他们,过来帮助他们。她把狗吓跑了,他们安全了。汤姆和杰瑞非常感激,感谢这位女士。他们意识到,尽管他们喜欢玩捉迷藏游戏,但遵守规则并确保安全是很重要的。
****************************************************************************************************
step-00140000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了一些三明治和果汁来分享。
当他们到达公园时,他们看到一个大牌子上面写着“禁止在此野餐”。汤姆和杰瑞很伤心,因为他们不能在公园里野餐了。他们决定去公园的另一边,那里有一个大池塘。
当他们到达池塘时,他们看到一只鸭子在游泳。汤姆和杰瑞想和鸭子玩,但他们知道必须遵守规则。他们决定在池塘边野餐,并邀请鸭子加入他们。鸭子很高兴,他们一起度过了一个美好的野餐时光。
****************************************************************************************************
step-00160000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去冒险。他们收拾好行李,去了机场。
在机场,他们看到了一架大飞机。汤姆说:“我想坐那架飞机!”杰瑞说:“不,我想坐那架飞机!”他们开始争吵,声音越来越大。
突然,飞机开始摇晃,他们很害怕。他们试图逃跑,但飞机太强大了。飞机坠毁了,他们再也没有回到家。结束。
****************************************************************************************************
step-00180000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园玩。
当他们到达公园时,他们看到一个很大的滑梯。汤姆和杰瑞想尝试一下,但有一个问题。滑梯的顶部有一个标志,上面写着“禁止进入”。汤姆和杰瑞很伤心,因为他们真的很想滑下滑梯。
突然,他们看到一个拿着大袋子的人。那个人说:“我给你们一个惊喜。我给你们一个装满玩具的袋子!”汤姆和杰瑞非常高兴,感谢了那个人。他们玩了玩具,度过了很多乐趣。他们忘记了滑梯,只是享受着新玩具带来的乐趣。
****************************************************************************************************
step-00200000
-------------
汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们去公园玩。
在公园里,他们看到一棵大树。汤姆说:“我们爬树吧!” 杰瑞很害怕,但汤姆说:“别担心,我会帮助你的。” 他们开始爬树。
当他们爬得越高时,他们看到了一只大鸟。鸟儿说:“你们好,朋友们!你们想和我一起玩吗?” 汤姆和杰瑞很惊讶,但他们说:“好的,我们想和你一起玩!” 他们一起玩得很开心。
****************************************************************************************************
可以看到,在60k之前的checkpoints生成的文本虽然很长,但是有非常严重的重复。
而从60k开始,生成的文本重复率开始下降,并且越来越连贯。不过可以发现明显的逻辑硬伤。
比如step-00060000里「杰瑞说:“我们把它带回家吧!”于是,他们把蛋带回了鸟巢」,要把蛋带回家,结果后面又说「他们把蛋带回了鸟巢」。
另外还有一些悲伤的故事🤣,例如:
step-00100000里两个人遇到了熊,最后「熊吃了他们,然后他们就再也没有出现过。结束。」
step-00160000里两个人在飞机上吵架,最后「飞机坠毁了,他们再也没有回到家。结束。」
效果总结
虽然有些逻辑性的问题,但是整体来说,生成文本的连贯性是越来越好的。而且几乎没有任何明显的语法错误,这一点是非常厉害的。
也算是验证了一下微软的 TinyStories 里关于小模型(SLM)也能生成连贯文本的结论。
后续计划 🗓️
微软的论文里还有一项进一步的工作,那就是通过instruction数据来继续训练模型,从而让模型能够在生成故事的时候遵循一些要求。
这部分数据集呢目前只有纯英文的,我打算翻译一下,然后用来继续训练模型的SFT阶段。
不过最近确实有点忙,可能更新进度会稍微放缓一些。

小结
- 使用
TinyStories数据集预训练了200k steps的模型,并测试了生成效果。 - 从结果来看,模型生成的文本连贯性越来越好,但是仍然存在一些逻辑问题。
- 后续计划翻译
instruction数据集,用来继续训练模型的SFT阶段。
走之前点个赞和关注吧,你的支持是我坚持更新的动力!
我们下期见!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











