










走过路过不要错过,先关注一下,第一时间获取最新进度(或催更)

从零手搓中文大模型|🚀Day02

原本是计划直接进入「数据处理」阶段的,但由于实在精力有限,就拆成两期:这次先说说
Tokenizer,下一期说数据处理。由于
Tokenizer的训练算是一个相对独立的过程,且训练相对来说比较简单,因此我也打算偷懒先用国内大厂开源的,之后有时间再自己训练实现一个。其实分词器这块的内容经常容易被大家忽略,但实际上是非常重要的,因为它直接决定了模型的输入,进而影响到模型的训练效果。
这部分内容我自己此前也没怎么深入研究过,所以这次也是一边学习一边写,权当补课了,如果有错误的地方,欢迎指正。
Tokenizer选择
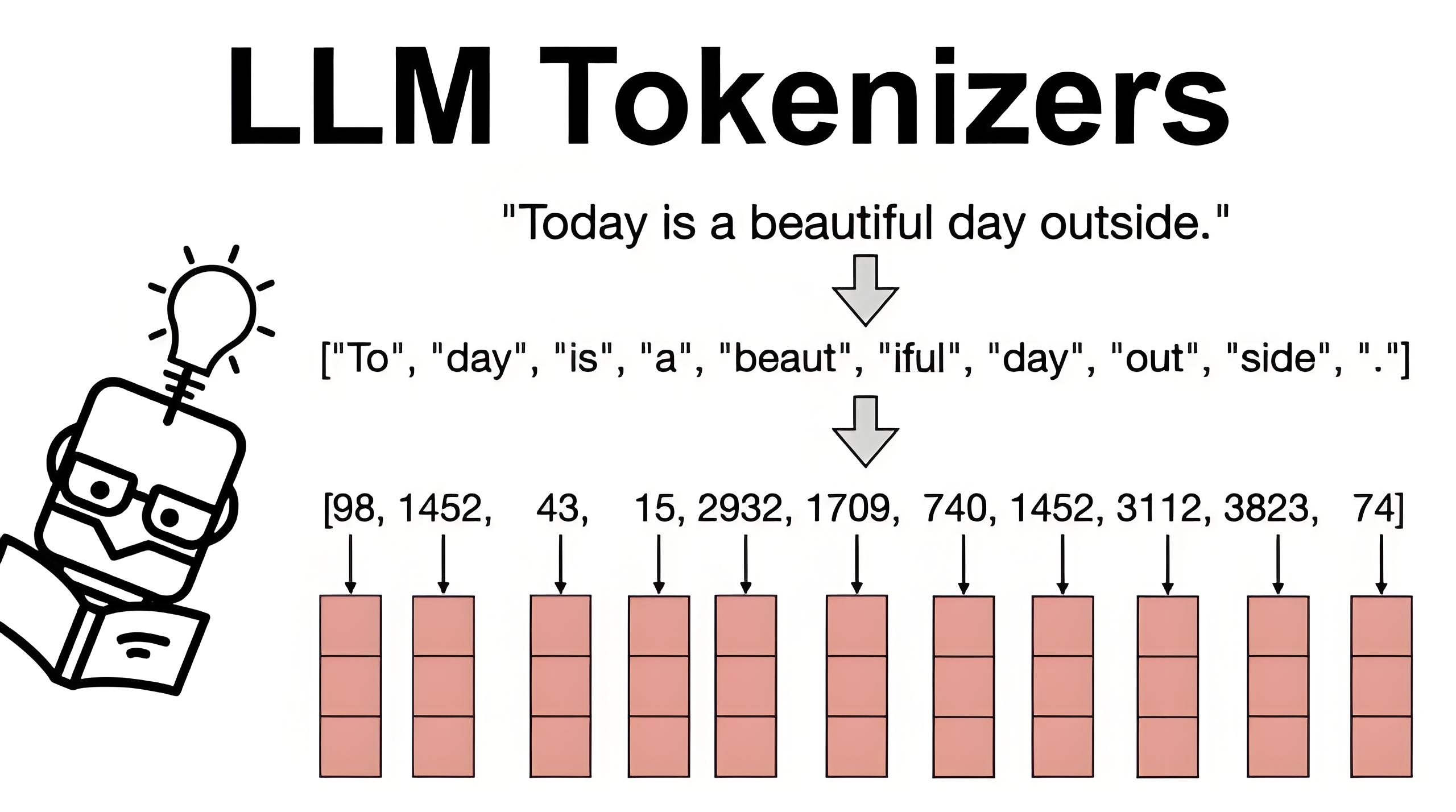
tokenization是大模型训练的第一步,是将文本转换为模型可以理解的数字表示(后面也能反向decode回来)。
其中目前比较主流的是BPE(Byte Pair Encoding)(详细的介绍可以参考链接文章,下面通过例子简单介绍一下原理)。
BPE是一种简单的数据压缩形式,这种方法用数据中不存在的一个字节表示最常出现的连续字节数据。这样的替换需要重建全部原始数据。
BPE简介
假设我们要编码如下数据
aaabdaaabac
字节对“aa”出现次数最多,所以我们用数据中没有出现的字节“Z”替换“aa”得到替换表
Z <- aa
数据转变为
ZabdZabac
在这个数据中,字节对“Za”出现的次数最多,我们用另外一个字节“Y”来替换它(这种情况下由于所有的“Z”都将被替换,所以也可以用“Z”来替换“Za”),得到替换表以及数据
Z <- aa
Y <- Za
YbdYbac
我们再次替换最常出现的字节对得到:
Z <- aa
Y <- Za
X <- Yb
XdXac
由于不再有重复出现的字节对,所以这个数据不能再被进一步压缩。
解压的时候,就是按照相反的顺序执行替换过程。
测试Tokenizer(以ChatGLM3-6B的tokenizer为例)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
编码
print(tokenizer("这是一个测试"))
{'input_ids': [64790, 64792, 30910, 36037, 32882], 'attention_mask': [1, 1, 1, 1, 1], 'position_ids': [0, 1, 2, 3, 4]}
反编码
print(tokenizer.decode(tokenizer("这是一个测试")["input_ids"]))
'[gMASK] sop 这是一个测试'
⚠️这里可以发现反向解码的时候,多出来了[gMASK]和sop这两个「奇怪」的token,原因下面会讲到。
我们看看词表的大小:
print(tokenizer.vocab_size)
64798
这里我们写一个函数,针对数据集里的一行json文本做处理,得到整行中文文本的编码数组。
import numpy as np
def process_line(line, tokenizer, add_eos=True, dtype=np.uint16):
js = json.loads(line)
story = js["story_zh"]
story = tokenizer.encode(story, add_special_tokens=False)
if add_eos:
story.append(tokenizer.eos_token_id)
# 这里可以用np.unint16,因为我们的vocab_size是小于65536的
arr = np.array(story, dtype=dtype)
return arr
❗️这里有几个需要注意的点:
-
add_special_tokens参数的作用是添加特殊token。
是chatglm自定义的例如[gMASK]/sop,属于glm架构里特有的(可以参考这里)。由于我们后续并不使用glm的架构,因此这里不需要添加,直接设置为False。
-
需要在末尾加上
eos标记对应的token_id。 -
chatglm3-6b使用的词表大小为
64798,刚好在uint16的表示范围内,所以上面我们给numpy.array设置了dtype=np.uint16。
拿一行测试一下:
import json
with open("../../Data/TinyStoriesChinese/train/data00_zh.jsonl", "r") as f:
for line in f.readlines():
data = process_line(line, tokenizer)
print(data)
print(tokenizer.decode(data))
break
[30910 56623 56623 54542 50154 31761 31155 31633 31815 54534 32693 54662
55409 31155 35632 31123 31633 34383 57427 47658 54578 34518 31623 55567
55226 31155 56623 56623 54695 39887 32437 55567 55226 31155 54790 41309
52624 31123 56856 32660 55567 55226 31155 13 30955 54834 54546 31123
54613 31404 30955 36213 31155 54613 36660 54563 54834 43881 32024 31155
56623 56623 32707 54657 33436 31155 54790 54937 56567 40714 31123 38502
56653 55483 31155 13 54613 32984 56623 56623 31155 54572 31897 54790
54657 35245 31155 36551 54695 56567 55567 55226 31155 33152 56623 56623
51556 31797 39055 31155 31694 56623 56623 31631 51556 31155 54790 54937
56567 54937 54929 31155 54790 55409 40915 34492 54537 31155 13 30955
54546 32591 56567 55567 55226 55398 31123 56623 56623 31514 30955 54613
54761 31155 56623 56623 54721 33906 31804 54887 31155 54790 46977 56567
55567 55226 31155 54613 31897 32960 54597 31155 54572 54942 34675 31155
13 56623 56623 56567 40915 54589 31123 36467 33501 31155 54790 54708
55567 55226 54547 57456 32246 31123 36712 34245 31155 54790 56901 55328
54537 55673 31155 54790 56399 37247 31155 13 30955 58394 56657 31123
58394 56657 31123 58394 56657 31404 30955 36213 31155 35957 55227 54613
31155 54790 31772 47554 31934 54790 31155 54688 54613 33551 33892 31155
54572 34247 31155 13 56623 56623 32707 54657 52992 31155 54790 31772
54790 54558 54542 54613 32097 55567 55226 31155 54790 31772 33152 33892
37322 54790 31155 54790 54531 60337 54531 57635 54563 35220 52624 31155
54790 31857 33277 32086 44829 49102 54547 31155 35328 43352 41147 31155
54572 42393 32233 31155 13 56623 56623 40466 31155 54790 31897 54613
33058 31155 54790 55947 32660 31804 41147 31155 54790 31772 38711 33857
31155 54790 54695 37300 31155 54790 54695 32462 31705 31761 31155 2]
莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。
"推我,本!"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。
本看着莉莉。他觉得她很可爱。他也想荡秋千。他在莉莉停下来之后等着。但是莉莉没有停下来。她越荡越快。她玩得太高兴了。
"我也可以荡秋千吗,莉莉?"本问。莉莉没听到他的话。她忙着荡秋千。本觉得很难过。他走开了。
莉莉荡得太高,失去了平衡。她从秋千上摔下来,落在地上。她扭伤了脚。她哭了起来。
"哎呀,哎呀,哎呀!"她说。她在找本。她希望他能帮助她。但本不在那里。他走了。
莉莉感到很抱歉。她希望她能和本分享秋千。她希望他在那里拥抱她。她一瘸一拐地走到树下。她看到有什么东西挂在树枝上。那是本的帽子。他留给她的。
莉莉笑了。她觉得本很好。她戴上了他的帽子。她希望他会回来。她想道歉。她想再次成为朋友。
选择ChatGLM3-6B的tokenizer的原因
该词表大小为64798,值得注意的是:这是一个很妙的数字,因为它刚好在uint16的表示范围(0~65535的无符号整数),每一个token只需要两个字节即可表示。
当我们的语料较大时候,相比常用的int32可以节省一半的存储空间。
另外这里选择一个小尺寸的词表还有一个更重要的原因:我们后面的模型会选择一个小参数量的,如果词表过大,会导致大部分参数被embedding层占用,而无法训练出更好的模型。
小结
- 首先熟悉了一下
BPE的原理 - 测试了一下
ChatGLM3-6B的tokenizer - 编写了一个函数,用于将一行json文本转换为token_id数组
- 解释了为什么选择
ChatGLM3-6B的tokenizer
走之前点个赞和关注吧,你的支持是我坚持更新的动力!
我们下期见!



















 1541
1541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











