









系列(二)中,对于SMO算法中有一个重要的代码:计算样本的预测类别。如下:
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b # 第i样本的预测类别我们知道原始的预测类别计算公式是用决策面的参数w和b表示的,那么为什么这里的貌似不一样呢?
原始的预测类别计算公式为:
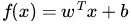
其中w可以表示为:
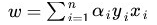
然后分类函数可以转化为:
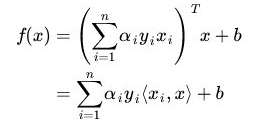
关于这个的解释,july博客上说的比较清晰:
这里的形式的有趣之处在于,对于新点 x的预测,只需要计算它与训练数据点的内积即可(<.>表示向量内积),这一点至关重要,是之后使用 Kernel 进行非线性推广的基本前提。
这样子的表示形式和上面代码就一致了。
这儿还有一个现象可以分析出来:哪些是支持向量。
答:alpha不等于0的为支持向量。
所谓 Supporting Vector 也在这里显示出来——事实上,所有非Supporting Vector 所对应的系数alpha都是等于零的,因此对于新点的内积计算实际上只要针对少量的“支持向量”而不是所有的训练数据即可。
为什么非支持向量对应的alpha等于零呢?直观上来理解的话,就是这些“后方”的点——正如我们之前分析过的一样,对超平面是没有影响的,由于分类完全有超平面决定,所以这些无关的点并不会参与分类问题的计算,因而也就不会产生任何影响了。
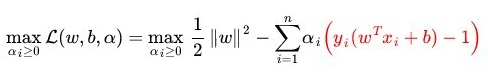
注意到如果 xi 是支持向量的话,上式中红颜色的部分是等于 0 的(因为支持向量的 functional margin 等于 1 ),而对于非支持向量来说,functional margin 会大于 1 ,因此红颜色部分是大于零的,而alpha_i又是非负的,为了满足最大化,必须alpha_i等于 0 。这也就是这些非Supporting Vector 的点的局限性。
所以,在我们运行SMO算法程序之后,可以根据这个特点求得支持向量,也就是alpha不等于0。

参考:http://blog.csdn.net/v_july_v/article/details/7624837
《Machine Learning in Action》















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









