






一:前期准备工作
-
下载并安装VMware Workstation。 下载CentOS 7的ISO镜像文件。 下载jdk安装包 下载scala安装包 下载Spark安装包。 下载并安装Xshell
-
二:开始搭建
- 准备三台虚拟机
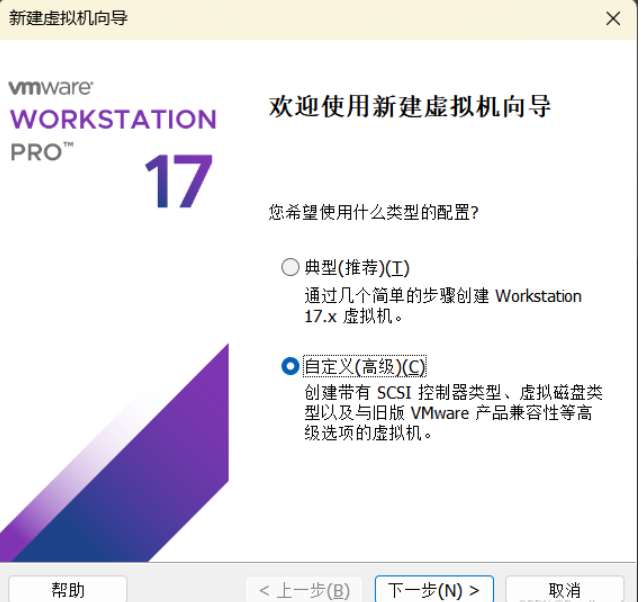
-
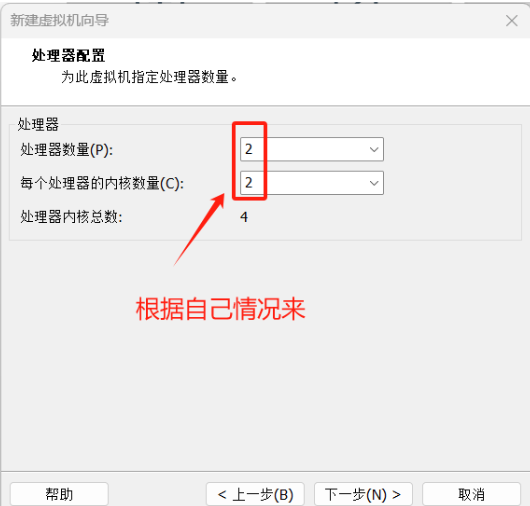
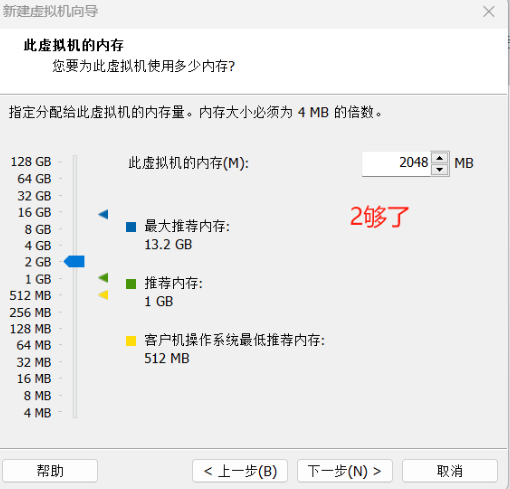
6.这里配置centos7镜像
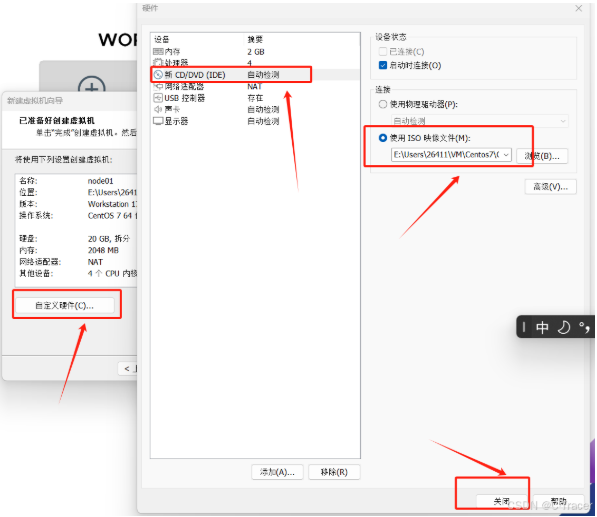
7.剩下就是centos7的安装步骤,可以参考http://cloud.tencent.com/developer/article/2037680完成后我们得到三台虚拟机,下面内容,用我之前搭建好的node1,node2,node3的进行参考
三:开始搭建
1、分别对三台虚拟机进行开机,右键,打开终端。(逐台开机可能会更快,同时开可能会卡)
2、查看ip地址:查看ip,得到三台虚拟机的ip
ip addr
或者
ifconfig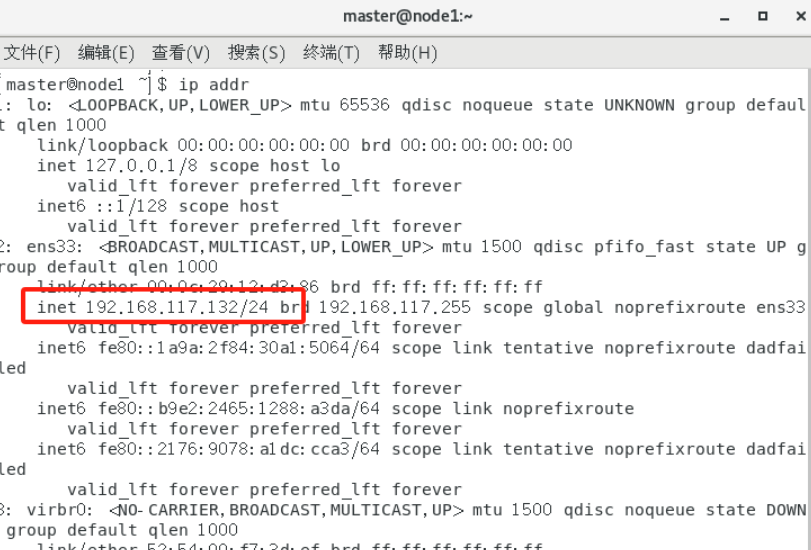
2、打开Xshell或者mobaxterm,与这三台进行连接(之后操作在Xshell中进行方便点)
3.配置静态ip地址(不会因为DHCP每次开机配置ip地址了)
vi /etc/sysconfig/network-scripts/ifcfg-ens33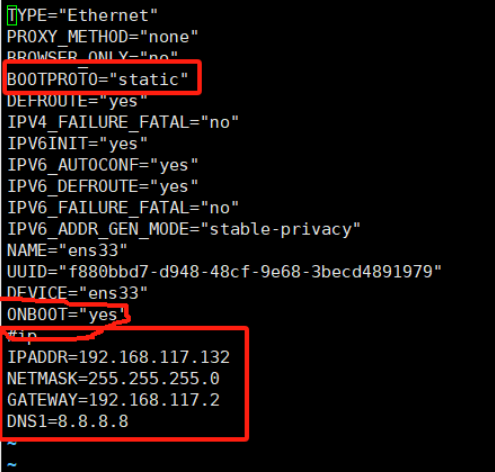
4.配置主机映射
vi /etc/hosts
#以下内容复制到末尾192.168.117.132 node1
192.168.117.133 node2
192.168.117.135 node3

5.关闭三台服务器的防火墙
#查看防火墙状态
sudo systemctl status firewalld
#暂时关闭防火墙
sudo systemctl stop firewalld
#永久关闭防火墙
sudo systemctl disable firewalld
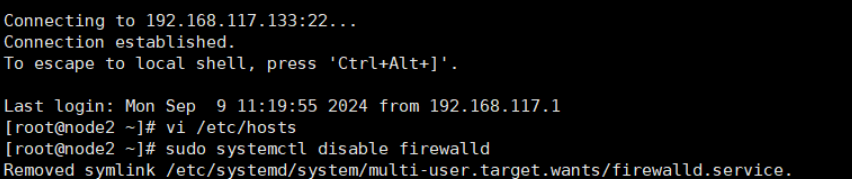
6.重启三台虚拟机,用ping测试三台是否网络通畅
7.配置各节点SSH免密码登录:
分别在3个节点执行以下命令,生成密钥文件。三次回车
ssh-keygen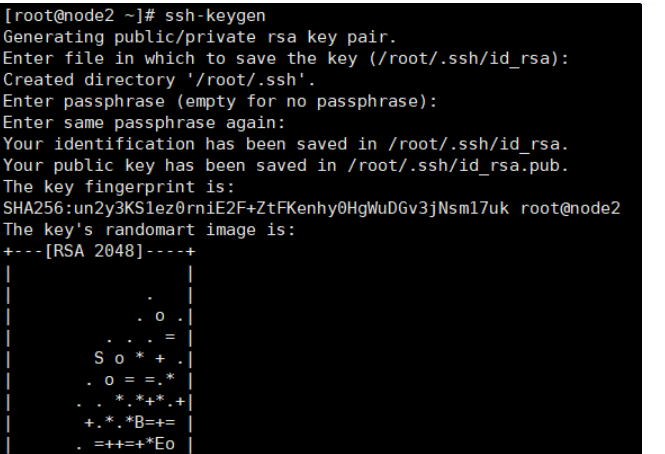
8.
首先,您需要使用 ssh-keygen 命令生成公钥信息。然后将生成的公钥信息复制到各个节点的 authorized_keys 文件中。如果报错就用root权限,用户态切换到root
- 在第一个节点上执行以下命令:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub | ssh user@node2 "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh user@node3 "cat >> ~/.ssh/authorized_keys"
- 在第二个节点上执行以下命令:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub | ssh user@node1 "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh user@node3 "cat >> ~/.ssh/authorized_keys"
- 在第三个节点上执行以下命令:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub | ssh user@node1 "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh user@node2 "cat >> ~/.ssh/authorized_keys"
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
在上面的命令中,您需要将 user@node1, user@node2, user@node3 替换为实际的节点用户名和主机名或 IP 地址。这样做可以将当前节点的公钥信息复制并追加到其他节点的 authorized_keys 文件中。
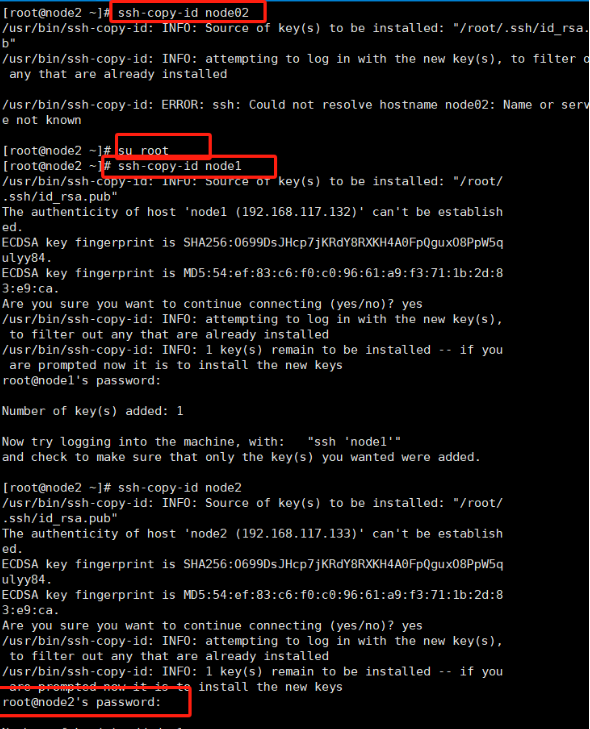
9.最后重启一下即可,使用ssh免密连接
ssh node01
ssh node02
ssh node03
四:Spark集群部署
1.先创建三个数据相关的文件夹
mkdir -p /export/servers
data放置相关数据文件
servers软件安装目录
software放置软件包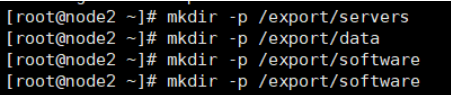
2.rz插件用来方便的从本地win系统传入linux虚拟机中文件
yum install lrzszcd -y3.如果node中有自带jdk最好删除
#先查看是否有
java -version
#之后看都有哪些
rpm -qa | grep java
#一条条卸载(卸载带有openjdk的)
rpm -e --nodeps+
#验证
java -version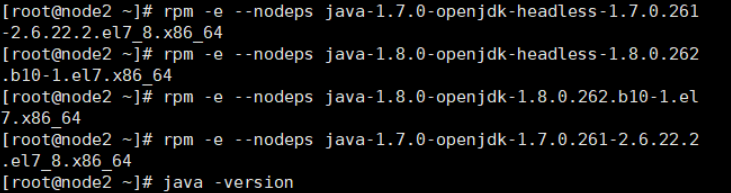
4.上传自己的安装包
rz
cd /export/servers/
tar -zxvf spark-3.5.2-bin-hadoop3.tgz -C /export/servers/ tar -zxvf scala-2.13.11.tgz -C /export/servers/ tar -zxvf jdk-8u241-linux-x64.tar.gz -C /export/servers/
mv jdk1.8.0_181 jdk
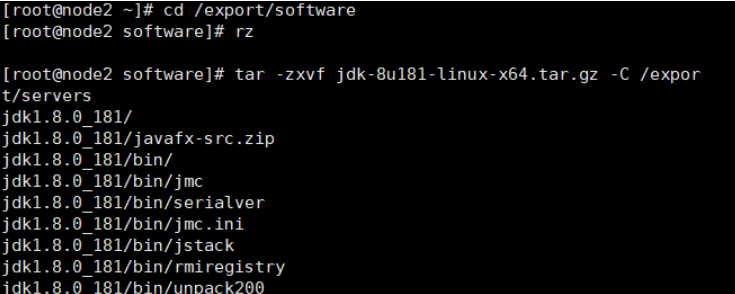
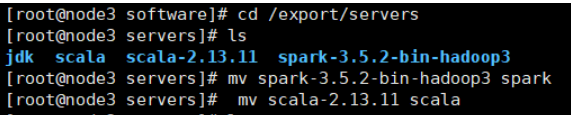
5.配置环境变量
一个个node节点去配置
#打开配置文件
vi /etc/profile
#重新加载配置文件,使环境变量生效
source /etc/profile
先配置node1,配置完成后验证环境变量是否配置成功,之后分发配置文件给另外两台虚拟机。
#配置jdk的
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#配置SCALA_HOME
export SCALA_HOME=/export/servers/scala
#添加bin路径到Path
export PATH=$PATH:$SCALA_HOME/bin
#配置SPARK_HOME
export SPARK_HOME=/export/servers/spark
#添加bin路径到Path
export PATH=$PATH:/export/servers/spark/bin
验证环境变量是否生效,可用命令echo+$变量名的方式输出:
echo $JAVA_HOME
echo $SCALA_HOME
echo $SPARK_HOME
spark,spark -version不行的话,可以试试spark-submit --version
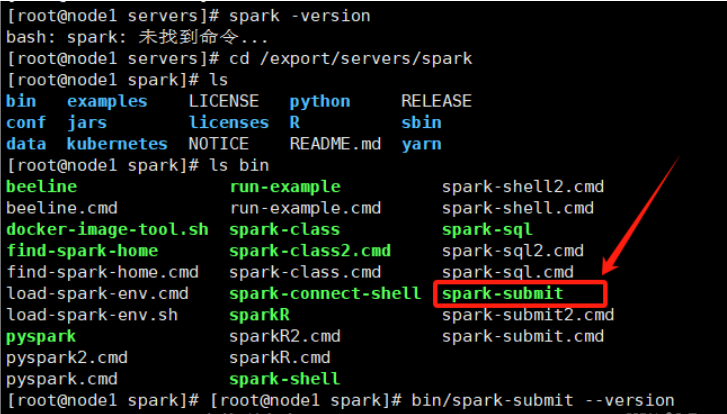
6.修改spark配置文件:
进入到conf目录,复制文件spark-env.sh.template并重命名为spark-env.sh
cd /export/servers/spark/conf
重命名spark-env.sh.template:
mv spark-env.sh.template spark-env.sh
并修改该文件配置:
vi spark-env.sh
![]()
#配置内容放在尾部,内容如下:
#配置JAVA_HOME
export JAVA_HOME=/export/servers/jdk
#配置SCALA_HOME
export SCALA_HOME=/export/servers/scala
#设置主节点
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077

最后一步:启动与关闭集群
Spark 提供了一些单点、集群的启动与停止脚本,可以在 Spark 目录下的 sbin 中查看启动与停止 Spark 的操作脚本。
进入 Spark的sbin 目录,并查看该目录下的脚本。具体命令如下。cd /export/servers/spark/sbin
#进入sbin目录下:
#启动集群:
./start-all.sh
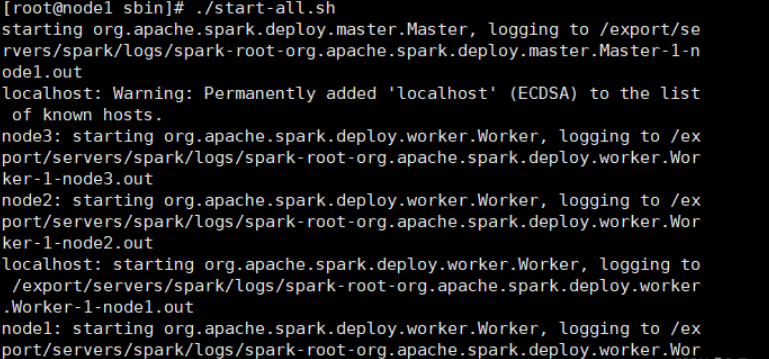
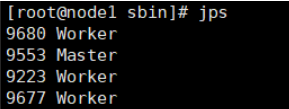
运行启动脚本后,查看返回信息,并使用jps命令查看进程启动情况。成功。


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









