







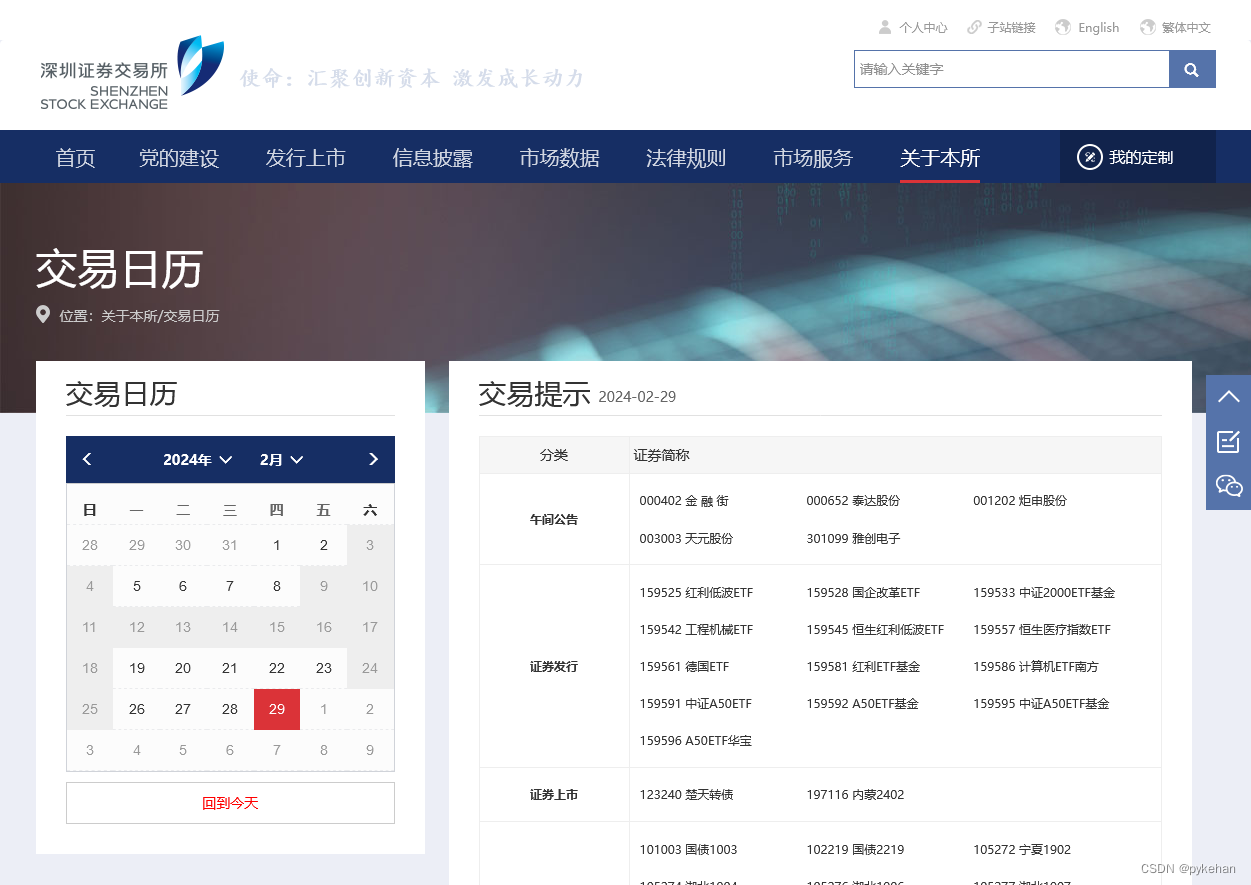
深交所https://www.szse.cn/aboutus/calendar/index.html网站提供了交易所的交易日历,如下图:
在Edge浏览器中,打开网页后,F12进入开发工具,然后对交易日历切换(比如从2月切换成4月),可以在“网络”项中,发现发生变化的html页面地址。如下图:
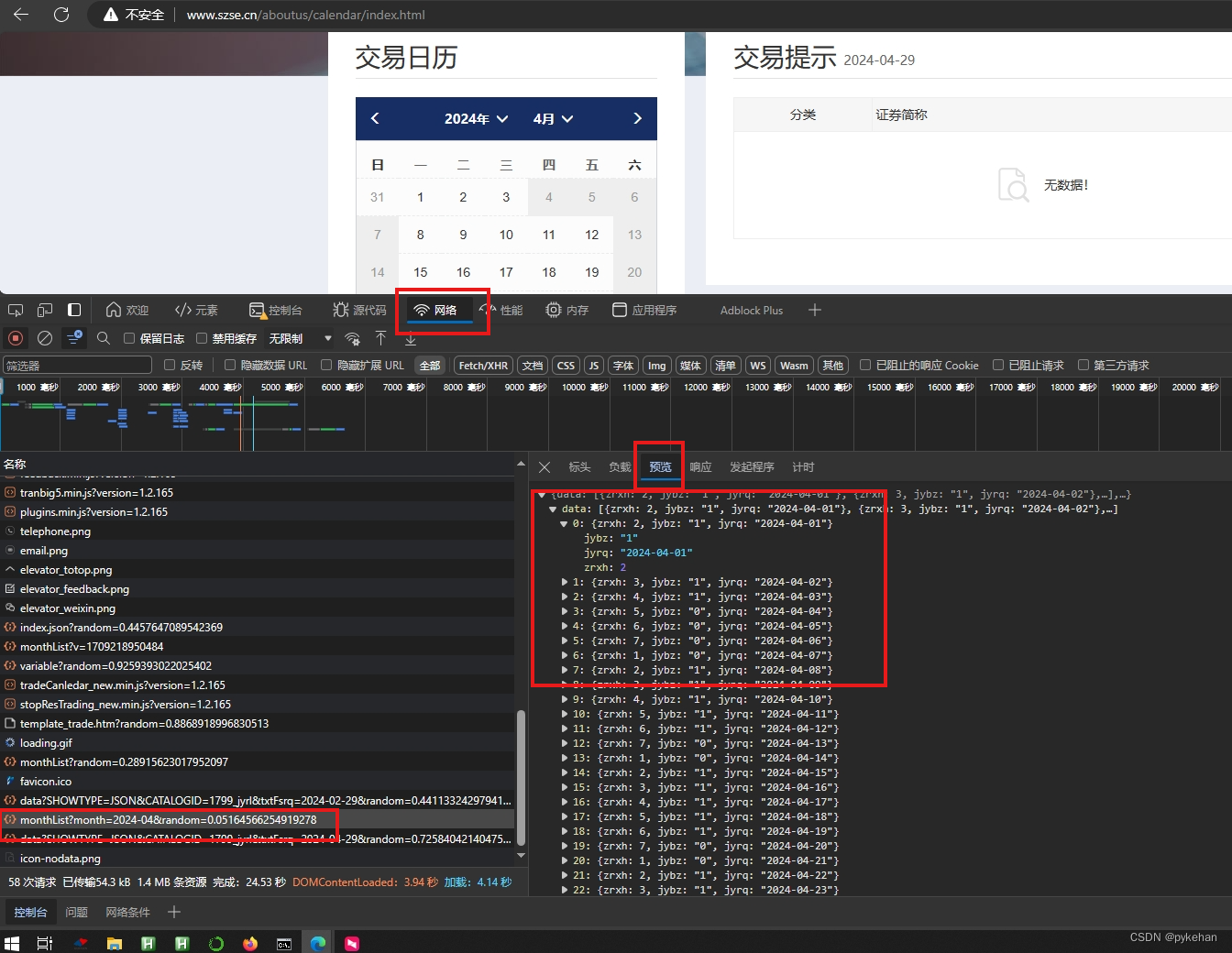
可以看到框中的html地址对应的预览数据是json,由此找到了交易日历对应的网址:
http://www.szse.cn/api/report/exchange/onepersistenthour/mont
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









