






一、什么是大模型?
当我们提及大模型时,通常指的是大语言模型(Large Language Model,简称LLM),即文字问答模型,其典型代表便是OpenAI的GPT系列。然而,随着技术的日新月异,大模型已经不单单局限于自然语言处理(Natural Language Processing)领域的发光发热,而是逐渐渗透到了其他多个领域。
1、初学者学习大模型难吗?
对于初学者来说,学习大型模型确实具有一定的难度,但并非不可能。关键在于是否有扎实的基础知识、持续的学习态度和实际的动手能力。通过逐步学习和实践,初学者可以逐步掌握大型模型的相关知识和技能。
那么初学者学习大模型“难”的点在哪?
理论知识:大型模型通常基于复杂的数学和统计学原理,需要一定的理论基础。
计算资源:大型模型训练需要高性能的计算资源,这对初学者来说可能难以获得。
编程技能:实现大型模型需要熟练的编程技能,尤其是在使用深度学习框架时。
数据管理:处理和准备用于训练大型模型的大量数据是一个挑战。
调试和优化:大型模型的调试和性能优化需要经验和直觉。
概念理解:理解模型的工作原理和内部机制可能会很困难,特别是对于复杂的网络结构。
然而,随着在线教育资源的丰富和开源软件的普及,初学者可以通过以下方式逐步学习:
基础学习:首先掌握机器学习和深度学习的基础知识。
逐步深入:从简单的模型开始,逐步学习更复杂的模型。
实践操作:通过实验和项目来应用所学知识。
利用资源:利用在线课程、论坛和开源项目来学习和解决问题。
社区支持:加入学习小组和社区,与他人交流和合作。
虽然学习大型模型有难度,但通过持续的学习和实践,初学者可以逐步克服这些挑战。
2,学习大模型有什么好处?
学习大型模型可以为个人带来多方面的好处,尤其是在职业生涯和学术研究方面。
以下是一些主要的好处:
就业机会:掌握大型模型技能的人在人工智能、数据分析、软件开发等领域有更多的就业机会。
解决复杂问题:大型模型能够处理和分析大量复杂数据,帮助解决现实世界中的复杂问题,如疾病诊断、气候变化预测等。
创新研究:在学术或工业研究环境中,大型模型是推动新技术和算法发展的关键工具。
跨学科应用:大型模型的知识可以应用于多个学科,如生物学、物理学、经济学等,促进跨学科的研究和合作。
提高效率:在工业和服务业中,大型模型可以自动化复杂的任务,提高生产效率和决策质量。
商业价值:大型模型可以帮助企业和组织从数据中提取有价值的信息,用于市场分析、客户服务、风险评估等。
个人成长:学习大型模型可以提升个人的技术能力和解决问题的能力,有助于个人职业成长和发展。
社会影响:大型模型的应用可以对社会产生积极影响,如通过改善医疗保健、教育、交通等领域。
持续学习:大型模型和深度学习是快速发展的领域,学习这些模型可以让人保持对最新技术趋势的了解。
创业机会:掌握大型模型技能的人可以创办基于人工智能技术的初创公司,开发创新产品和服务。
总之,学习大型模型不仅可以提升个人的技术能力,还可以为个人的职业发展、学术研究和社会贡献带来广阔的前景。
3、怎么去学习大模型?
学习大型模型时,应循序渐进,从基础知识和简单模型开始,慢慢地提升编程能力,不仅要理解理论知识还需要动手实践以至于加深理解,利用在线资源保持学习,注意关注最新研究动态,同时注重模型原理和伦理问题,保持一定耐心和毅力。那么你学习大模型的一个态度将会是你成与败的关键点。
当然,在学习过程中可能会因为忽视基础知识、过度追求最新模型、缺乏数据或计算资源、忽视伦理问题等原因而走上错误的方向。为了避免这些误区,建议初学者应该注重基础知识学习、理论与实践相结合、关注数据质量、合理使用资源,并寻求反馈和指导。
今天我为大家分享一份学习大模型的参考资料,基础知识了解、理论学习、实践操作、专项深入、项目应用、拓展研究等等以及大AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。至于能学习到多少就看你的学习毅力和能力了 。

资料准备不容易,这也是我从刚开始接触大模型的时候,慢慢累积的一些知识,我完全愿意分享给和我一样想要学习大模型的你们。
下面是我为大家准备的一份完整的学习大模型的资料,希望对你们有所帮助:
初学者AI大模型入门指南
第一章认识大模型
1.1 大规模语言模型基本概念
1.2 大规模语言模型发展历程
1.3 大规模语言模型构建流程

第二章大语言模型基础
2.1 Transformer模型
- 2.1.1 嵌入表示层
- 2.1.2 注意力层
- 2.1.3 前馈层
- 2.1.4 残差连接与层归一化
- 2.1.5 编码器和解码器结构
2.2 生成式预训练语言模型GPT
- 2.2.1 无监督预训练
- 2.2.2 有监督下游任务微调
- 2.2.3 基于HuggingFace的预训练语言模型实践
2.3 大语言模型结构
- 2.3.1 LLaMA的模型结构
- 2.3.2 注意力机制优化

第三章语言模型训练数据
3.1数据来源
- 3.1.1 通用数据
- 3.1.2 专业数据
3.2 数据处理
- 3.2.1 低质过滤
- 3.2.2 冗余去除
- 3.2.3 隐私消除
- 3.2.4 词元切分
3.3 数据景细向分析
- 3.3.1 数据规模影响
- 3.3.2 数据质量影响
- 3.3.3 数据多样性影响
3.4 开源数据集合
- 3.4.1 Pile
- 3.4.2 ROOTS
- 3.4.3 RefinedWeb
- 3.4.4 SlimPajama
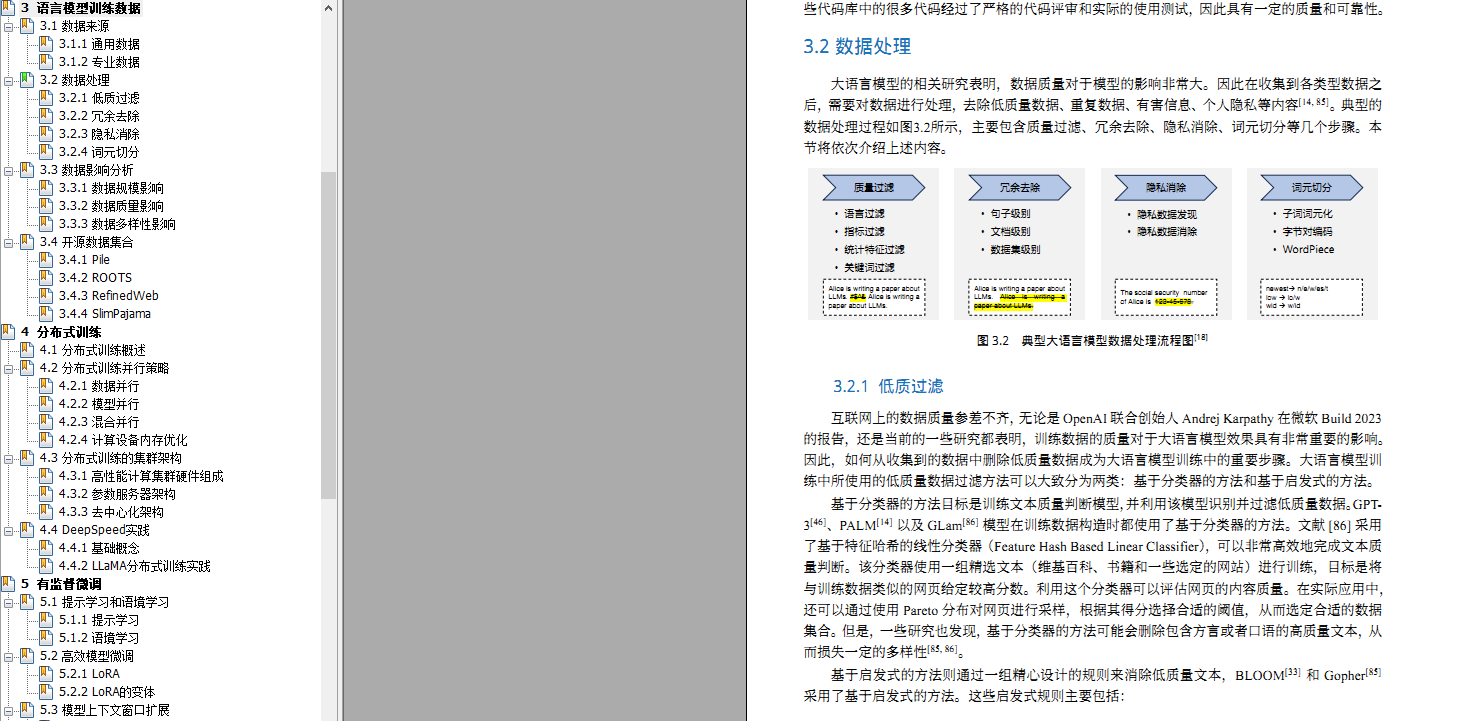
第四章分布式训练
4.1 分布式训练概述
4.2 分布式训练并行策略
- 4.2.1 数据并行
- 4.2.2 模型并行
- 4.2.3 混合并行
- 4.2.4 计算设备内存优化
4.3 分布式训练的集群架构
- 4.3.1 高性能计算集群硬件组成
- 4.3.2 参数服务器架构
- 4.3.3 去中心化架构
4.4 Deepspeed实践
- 4.4.1 基础概念
- 4.4.2 LLaMA分布式训练实践
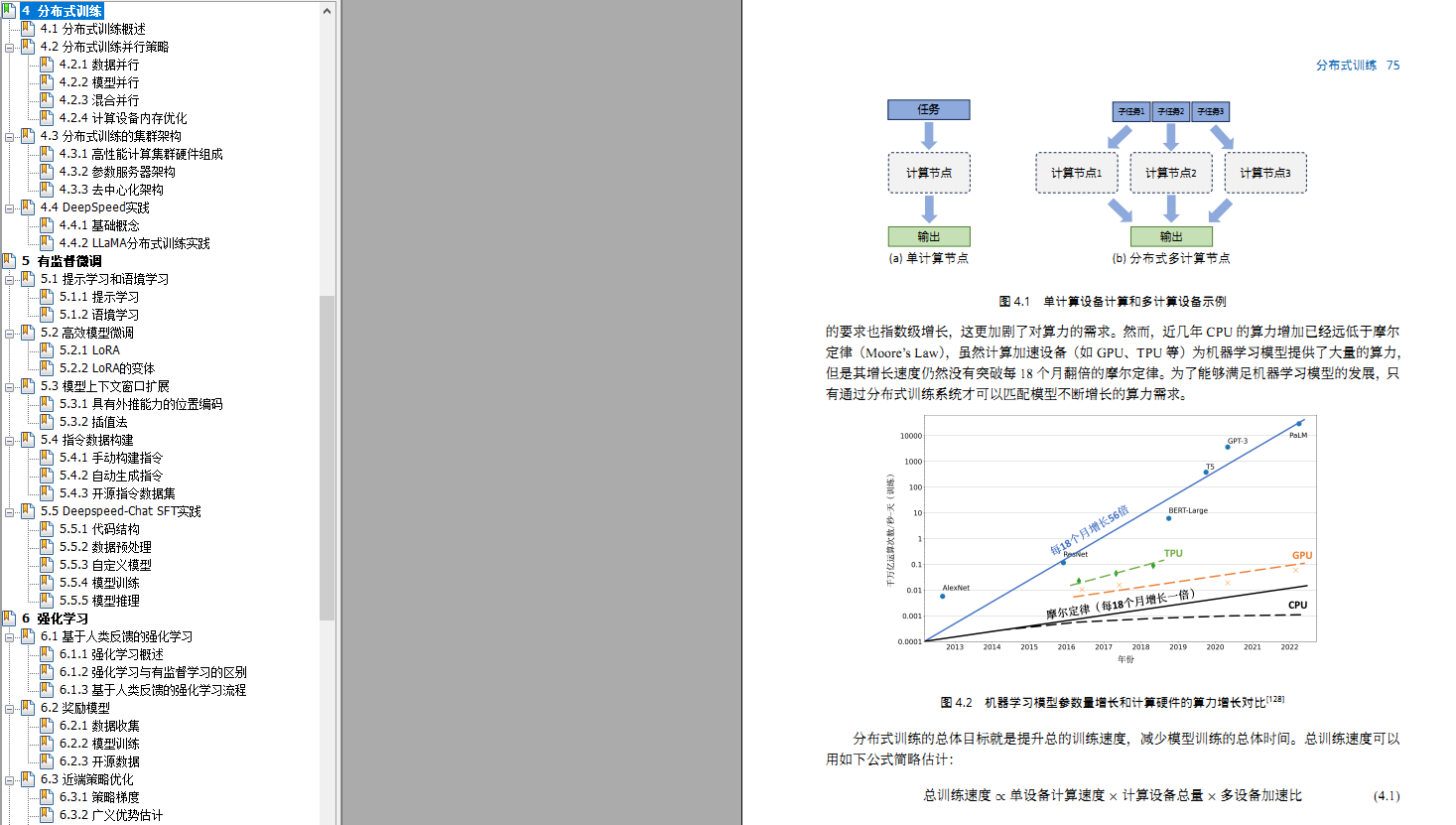
第五章有监督微调
5.1 提示学习和语境学习
- 5.1.1 提示学习
- 5.1.2 语境学习
5.2 高效模型微调
- 5.2.1 LORA
- 5.2.2 LORA的变体
5.3 模型上下交窗口扩展
- 5.3.1 具有外推能力的位置编码5.3.2 插值法
5.4 指令数据构建
- 5.4.1 手动构建指令
- 5.4.2 自动生成指令
- 5.4.3 开源指令数据集
5.5 Deepspeed-chat SFT实践
- 5.5.1 代码结构
- 5.5.2 数据预处理
- 5.5.3 自定义模型
- 5.5.4 模型训练
- 5.5.5 模型推理

第六章强化学习
6.1 基于人类反馈的强化学习
- 6.1.1 强化学习概述
- 6.1.2 强化学习与有监督学习的区别
- 6.1.3 基于人类反馈的强化学习流程
6.2 奖励模型
- 6.2.1 数据收集
- 6.2.2 模型训练
- 6.2.3 开源数据
6.3 近端策略优化
- 6.3.1 策略梯度
- 6.3.2 广义优势估计
- 6.3.3 近端策略优化算法
6.4 MOSS-RLHF实践
- 6.4.1 奖励模型训练
- 6.4.2 PPO微调

第七章大语言模型应用
7.1 推理规划
- 7.1.1 思维链提示(Chain-of-Thought Prompting)
- 7.1.2 由少至多提示(Least-to-Most Prompting)
7.2 综合应用框架
- 7.2.1 LangChain框架核心模块
- 7.2.2 知识库问答实践
7.3 智能代理
- 7.3.1 智能代理的组成
- 7.3.2 智能代理的应用实例
7.4 多模态大模型
- 7.4.1 模型架构
- 7.4.2 数据收集与训练策略
- 7.4.3 多模态能力示例
7.5 大语言模型推理优化
- 7.5.1 FastServe框架
- 7.5.2 VLLM推理框架实践
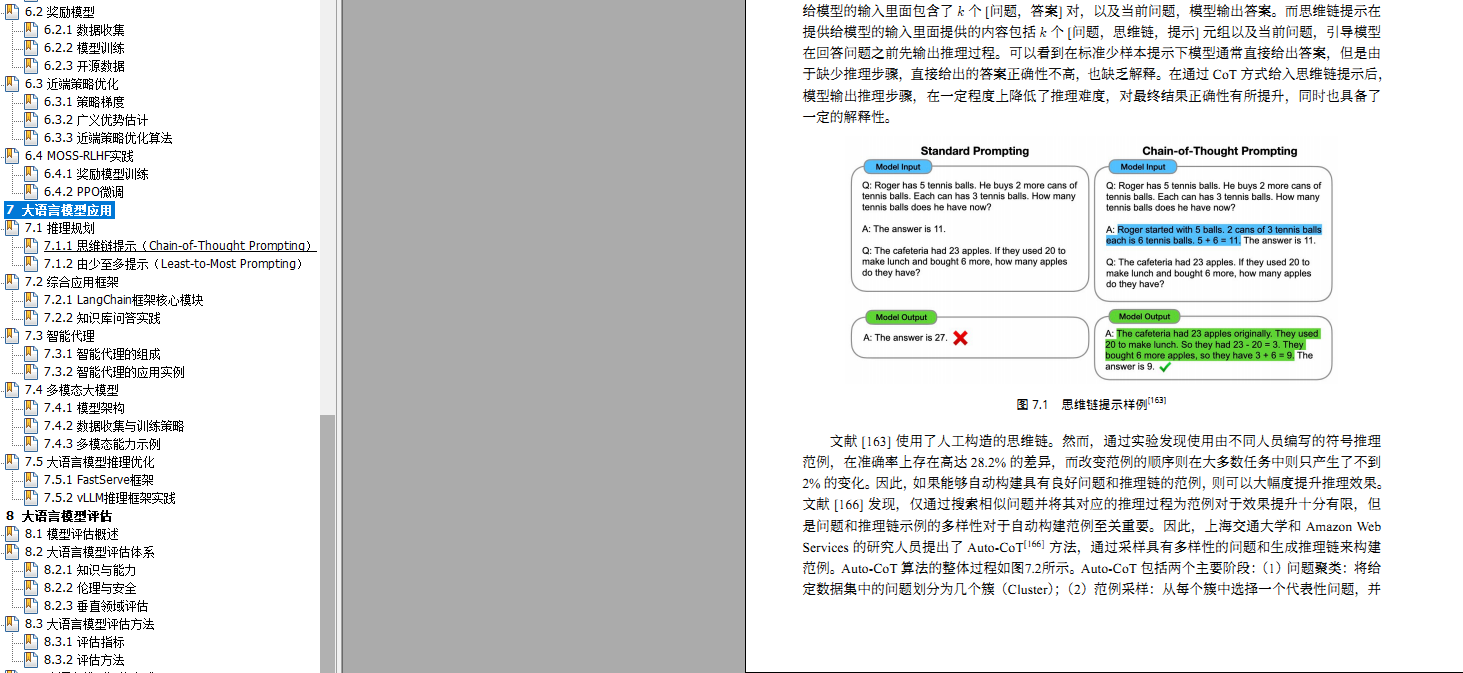
第八章大语言模型评估
8.1 模型评估概述
8.2 大语言模型评估体系
- 8.2.1 知识与能力
- 8.2.2 伦理与安全
- 8.2.3 垂直领域评估
8.3 大语言模型评估方法
- 8.3.1 评估指标
- 8.3.2 评估方法
8.4 大语言模型评估实践
- 8.4.1 基础模型评估
- 8.4.2 SFT/RL模型评估

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

总结
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。加油!















 2037
2037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









