






一名来自新西兰的帅气小伙将大模型决策过程可视化了!
在线网址:
https://bbycroft.net/llm
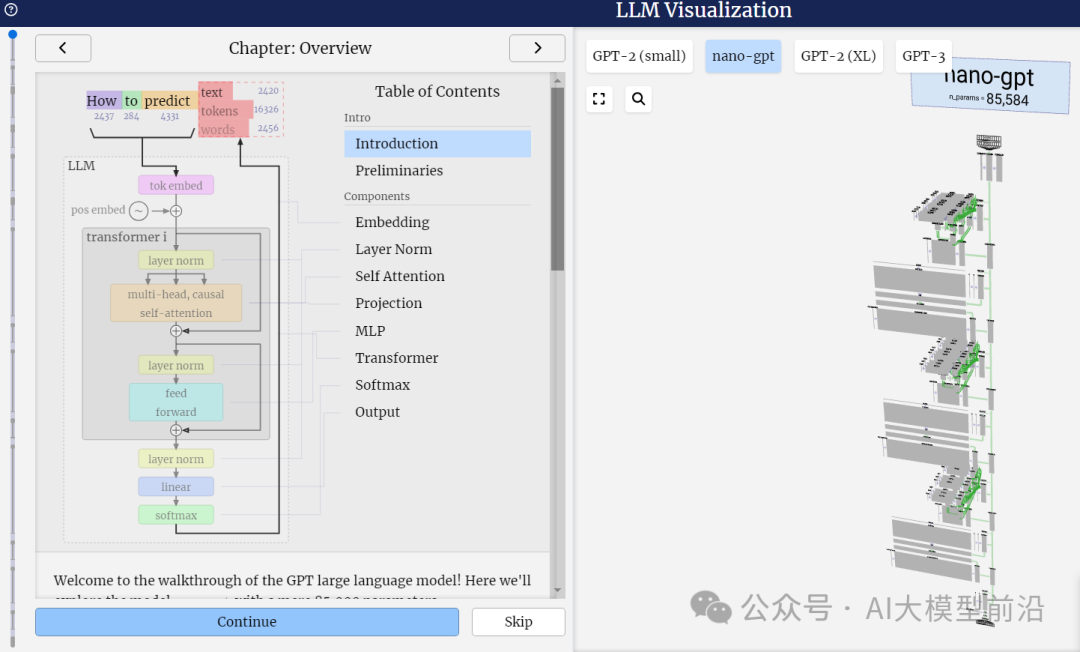
项目****简介
llm-viz的主要目标是展示大型语言模型(LLM)的工作流程和内部机制。具体来说,它提供了一个GPT风格网络的工作实现的3D模型,即OpenAI的GPT-2、GPT-3(以及可能的GPT-4)中使用的网络拓扑结构的可视化。通过这个项目,用户可以更直观地理解LLM的内部架构和工作原理。
在llm-viz中,显示的第一个具有工作权重的网络是一个微小的网络,用于对字母A、B和C的小列表进行排序。这个演示示例模型是基于Andrej Karpathy的minGPT实现。渲染器还支持可视化任意大小的网络,尽管对于较大的网络,权重文件可能由于体积庞大(数百MB)而没有被下载。
llm-viz提供了在线体验地址,用户可以在线查看LLM的可视化效果。
线上版本:https://bbycroft.net/llm
如果在线玩感觉不过瘾,可以部署到本地,用户需要先安装依赖项,然后启动开发服务器即可进行本地运行,下面是源码,内附部署教程。
本地部署版本:https://github.com/bbycroft/llm-viz
大模型可视化
在此我们以nano-GPT为例,将推理过程进行了可视化。
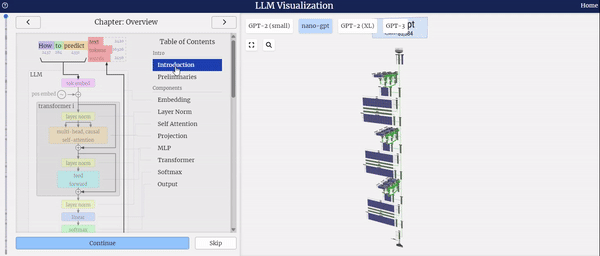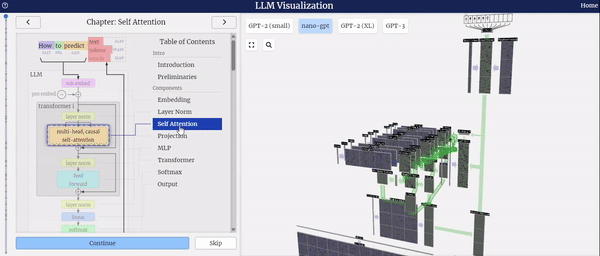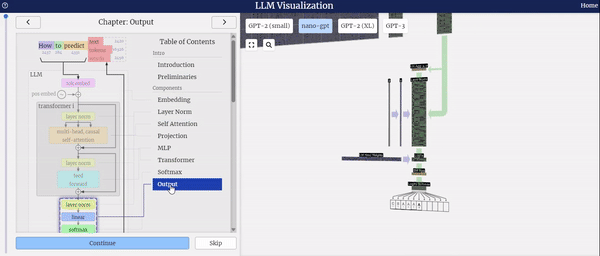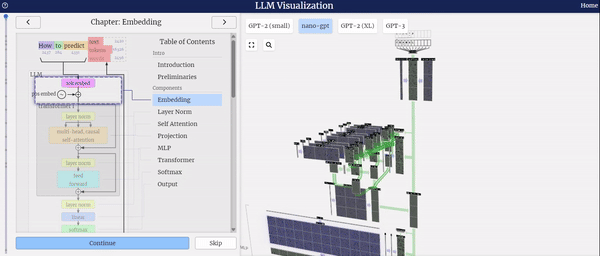
左侧的图表展示了模型结构的全面概览,详细描绘了模型的整体框架及其各个组件的组成。
从上图中,我们可以清晰地看到nano-GPT是基于Transformer架构构建的。Transformer架构本质上是一种Encoder-Decoder结构,然而GPT模型独辟蹊径,仅采用了Decoder部分。在Decoder中,每个Token的输出仅依赖于当前输入Token之前的Token信息,因此Decoder主要被应用于文本生成任务,它通过自回归的方式预测下一个可能出现的单词。
当然,有仅采用Decoder的模型,自然也有仅利用Encoder的模型。Bert便是其中的佼佼者。在Encoder中,每个Token的输出都融合了所有输入Token的信息,这使得Encoder在文本理解方面表现尤为出色。
此外,还有一类模型同时使用了Encoder和Decoder,它们构成了典型的seq2seq架构。其中,Encoder负责捕获源序列的内在表示,而Decoder则将这些表示解码为目标序列。这种架构在诸如语言翻译、语音识别等应用中发挥了重要作用。
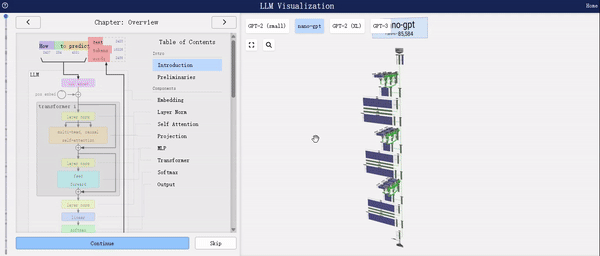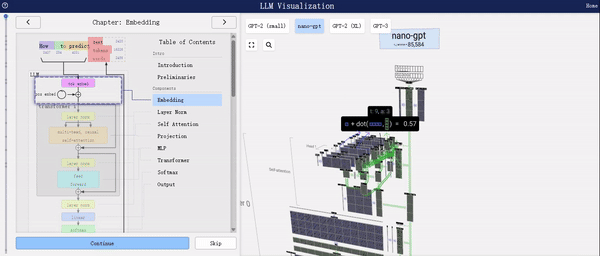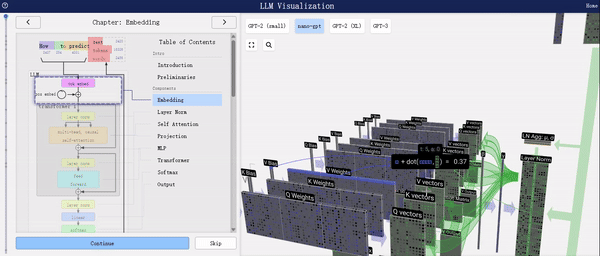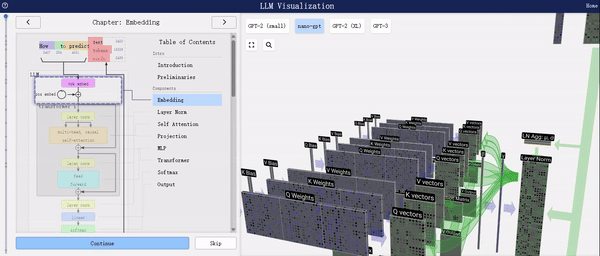
在选择模型整体或特定组件时,右侧界面支持鼠标交互功能,让您能够轻松获取所选部分的详细信息。
从上述图表中,我们可以清晰地看到LLM(大型语言模型)的工作流程。首先,它将输入的文本切分为Token,随后依据预定义的字典将这些Token转换为对应的字典索引,即IDs。紧接着,通过Word2Vec或其他自定义的Embedding技术,这些IDs被进一步转化为embedding向量,这些向量能够更好地捕捉文本中的语义信息。最后,这些向量被输入到Transformer编码器中进行深度处理。
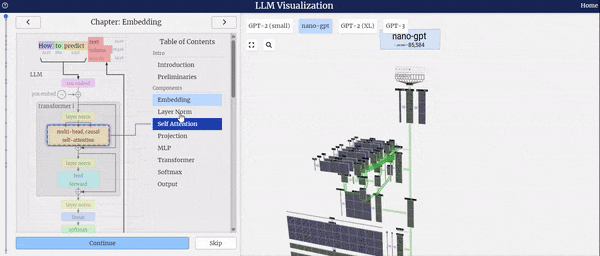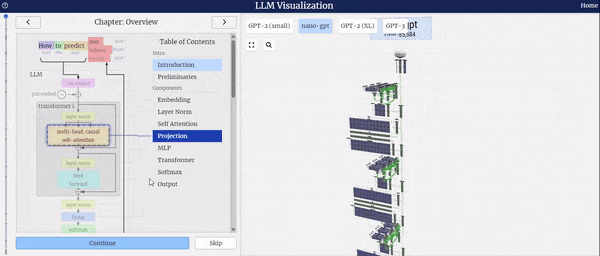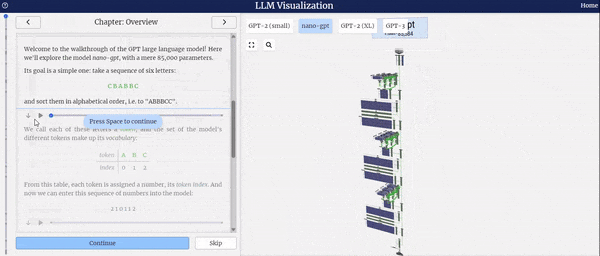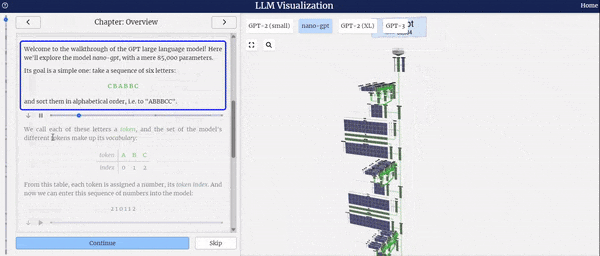
特别值得一提的是,当您选择模型整体或其中某个组件时,右侧界面将实时播放各个组件处理数据的动画,让您能够直观地了解数据在模型中的流转过程,从而更深入地理解模型的工作原理。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









