






1. 前言
在大语言模型的训练过程中,偏好对齐是一项至关重要的任务,它能够更好地帮助语言模型的输出与人类的喜好进行对齐。目前,开源界的许多项目已经实现了基于偏好数据的 Reward Model、 DPO(Direct Preference Optimization)及 DPO 的衍生方法的训练,然而,这些方案普遍存在一个显著的问题——显存浪费。
为什么会出现显存浪费的现象呢?这是由于在偏好训练的一次迭代中,需要至少包含 chosen 和 rejected 两个样本对。这两个样本对的长度往往存在差异,因此在组合这两个样本的时候,必须对短的样本进行补零(Padding),而这些补零的 token,都是被浪费的计算量!我们统计了目前使用范围最广的偏好对齐数据集 UltraFeedback,如果按 batch size=1 进行补零,则有 14.61% 的 token 是无意义的 padding token,而如果想把显存拉满而增大 batch size,则 padding 的 token 数量会显著增加,当 batch size=8 时 padding 占比居然已经超过了 50%!由此可见,偏好训练的过程中有大量的计算资源被浪费了****!
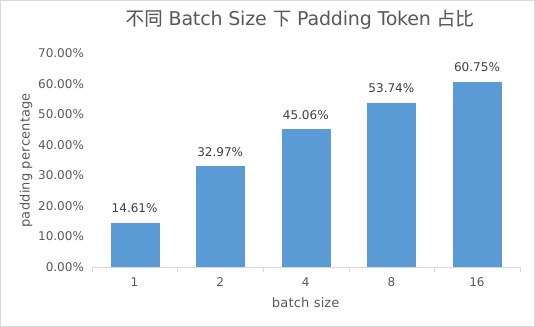
padding token 占比随着 batch size 增大而显著增加
2. 零显存浪费
为了解决这一问题,XTuner 首次开源了零显存浪费的偏好对齐训练方案!
https://github.com/InternLM/xtuner
那么,这是如何做到的呢?这就不得不提到大语言模型中常用的数据拼接(pack)技巧,数据拼接通过将不同的序列拼接为一个一维序列作为模型的输入,从而避免的组 batch 时的 padding,这样的训练方式在预训练与 SFT 中已经广泛使用。但是在偏好数据的训练的过程中使用该方法却存在一个问题,那就是注意力泄露。在 DPO 以及其他偏好训练的过程中,必须要求 chosen 和 rejected 两条样本是互相看不见的,如果只是简单将两条数据拼接,那么拼在后面的样本中的 token 的注意力会“看到”前面样本的 token,破坏了偏好训练的过程。这就要求我们对两条样本的 attention 进行魔改,避免两个样本互相之间能看到对方。
可惜 HuggingFace 的 transformers 中实现的语言模型并没有提供这样的接口!这也就是为什么目前没有开源项目能够支持数据拼接的方式进行偏好对齐训练。不过,XTuner 自有妙招**!**我们通过给模型打补丁的方式,魔改了模型中注意力层的计算过程,利用 flash attention 提供的变长注意力接口,我们成功让 HuggingFace 格式的语言模型支持了偏好数据的拼接训练。
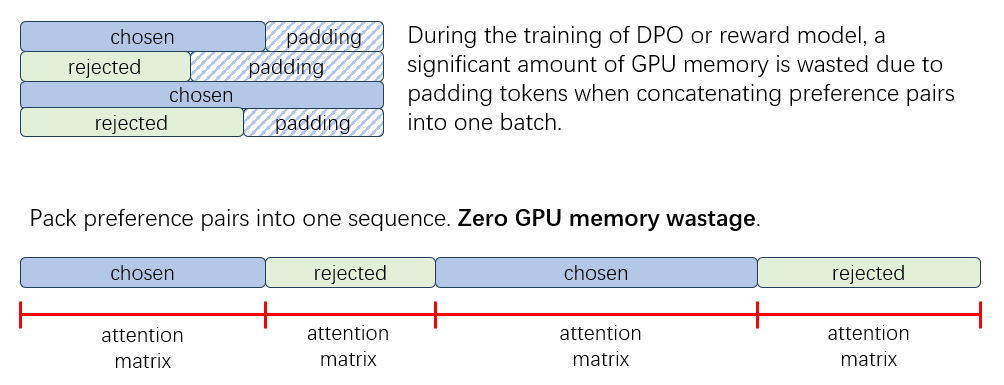
利用变长注意力将序列拼接,避免了 padding 的出现
在使用了 XTuner 的零显存浪费的 DPO 训练方案后,训练效率得到了巨大提升!我们测算了不同大小模型的训练时长,在相同的数据集 UltraFeedback上,Llama 3 的 DPO 训练的时间能够降低至原本的一半!
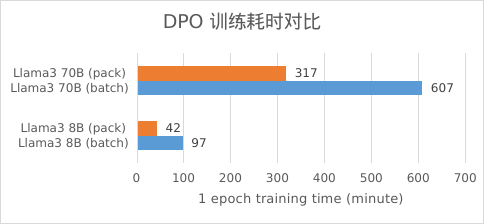
ultrafeedback 训练 1 epoch,max_length=2k,
8B packed_length=16k,70B packed_length=8k
3. 序列并行
除了零显存浪费的训练方案,XTuner 还首次开源了支持序列并行(sequence parallel)的偏好训练,这让在同样的数据长度下训练更大尺寸的模型或是在相同尺寸的模型下训练更长的偏好文本成为了可能。举例来说,XTuner 能够支持仅使用 8 卡 A100 在 max length = 128k 长度的偏好数据下训练 Llama3 8B 的偏好模型,而如果使用其他的训练框架,则会因为显存溢出而无法训练。而在使用 64 卡 A100 训练 70B 模型的情况下,我们最长能支持 1M 的序列长度,这是目前其他所有训练框架都无法做到的。
| Model | GPU Num | Sequence Length | Sequence Parallel | Success |
|---|---|---|---|---|
| Llama3 8B | 8 | 32k | wo | ✅ |
| sp=1 | ✅ | |||
| 64k | wo | ✅ | ||
| sp=1 | ✅ | |||
| 128k | wo | ❌ OOM | ||
| sp=2 | ✅ | |||
| 32 | 1m | wo | ❌ OOM | |
| sp=16 | ✅ | |||
| Llama3 70B | 64 | 8k | wo | ✅ |
| sp=1 | ✅ | |||
| 32k | wo | ❌ OOM | ||
| sp=2 | ✅ | |||
| 64k | wo | ❌ OOM | ||
| sp=4 | ✅ | |||
| 128k | wo | ❌ OOM | ||
| sp=8 | ✅ | |||
| 1m | wo | ❌ OOM | ||
| sp=64 | ✅ |
4. Reward Model 全尺寸开源
在如此高效的训练方案的加持下,我们训练了 1.8B,7B,以及 20B 大小的 Reward Model 开源给大家来使用!我们完全复现了 InternLM2 技术报告中的 Reward Model 的训练方案,这些模型均在高达 240 万条的偏好数据上进行了训练,并且在 Reward Bench 上取得了优异的性能。
| Models | Score | Chat | Chat Hard | Safety | Reasoning |
|---|---|---|---|---|---|
| InternLM2-20B-Reward | 89.5 | 98.6 | 74.1 | 89.4 | 95.7 |
| InternLM2-7B-Reward | 86.6 | 98.6 | 66.7 | 88.3 | 92.8 |
| InternLM2-1.8B-Reward | 80.6 | 95 | 58.1 | 81.8 | 87.4 |
与现有的开源 Reward Model 不同的是,我们的模型不仅仅训练了对话的偏好,还涵盖了诸如文本创作、诗歌、总结、代码、数学、安全等维度。更重要的是,InternLM2 的 Reward Model 训练数据不只有英文,还包含了大量的高质量中文数据。全面的偏好维度,再加上对中文的良好支持,这样的宝藏模型谁不爱,赶快点击链接下载试用吧!
Hugging Face 链接:
- https://huggingface.co/internlm/internlm2-1_8b-reward
- https://huggingface.co/internlm/internlm2-7b-reward
- https://huggingface.co/internlm/internlm2-20b-reward
Model Scope 链接:
- https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-1_8b-reward
- https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-7b-reward
- https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-20b-reward
5. 总结
XTuner 带来了零显存浪费的偏好训练方案以及序列并行的功能,解决了传统方法中的计算资源浪费问题,让大语言模型的训练更加高效、经济。不仅如此,XTuner 还开源了全尺寸的 Reward Model,涵盖多种应用场景,并提供了简易的接口,方便开发者快速上手。如果你还在为显存不足和训练效率发愁,那就赶紧来试试最新版的 XTuner 吧!
https://github.com/InternLM/xtuner
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 4269
4269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









