






难度大升级的多任务长视频理解评测基准MLVU来了!
由智源联合北邮、北大和浙大等多所高校推出。
究竟有多难呢?最终排名第一的GPT-4o单选正确率还不足65%。

而且研究发现,大部分模型的性能都会随着视频时长增加显著下降。
研究进一步证明,提升上下文窗口,提升图像理解能力,以及使用更强大的LLM Backbone对长视频理解的性能具有显著的提升作用。
目前相关论文及数据集已公开,具体细节下面一起看看吧~
MLVU的构建过程
当前流行的Video Benchmark主要针对短视频设计,大部分视频的长度都在1分钟以内。
且现有评测基准往往专注在特定领域的视频(例如电影、第一视角)和特定的视频评测任务(例如Captioning,Temporal Perception,Action Understanding)。
此外,现有部分长视频理解评测任务往往只和局部帧有关,或者针对经典电影进行问答,这导致MLLMs可以直接凭借text prompt正确回答而无需对视频进行分析。

针对以上不足,新基准MLVU从以下3个层面进行构建:
时长和来源更丰富
MLVU的视频时长覆盖了3分钟到超过2小时,平均视频时长12分钟,极大扩展了当前流行的Video Benchmark的时长范围。
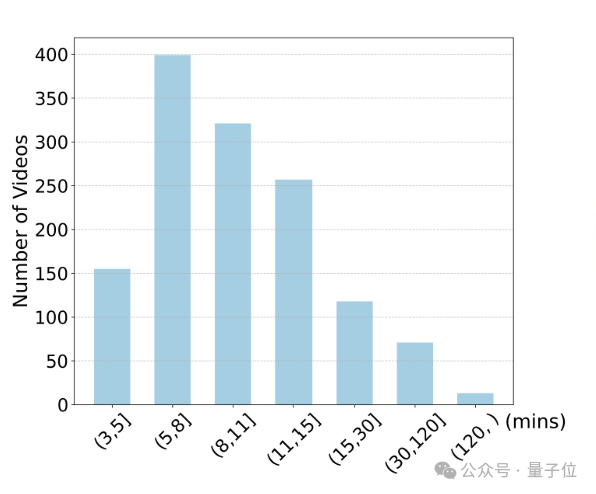
另外,MLVU的大部分任务标注过程中进行了片段-问题对应标注。
例如,Video Summarization任务分段标注了视频的前3分钟,前6分钟……
这意味着,MLLMs可以灵活地在MLVU上选择测试不同时长情况下的长视频理解能力。
同时,MLVU收集了包括电影、电视剧、纪录片、卡通动画片、监控视频、第一视角视频和游戏视频等多个类型的长视频,覆盖了长视频理解的多个领域范围。
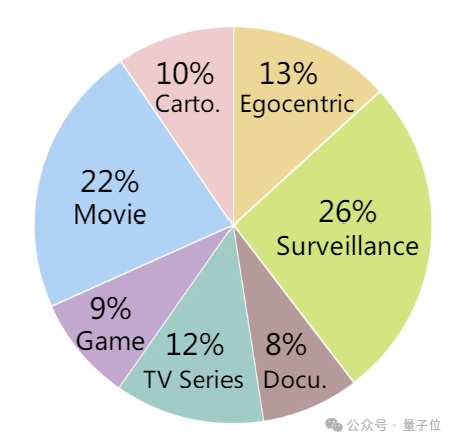
任务类别更全面
团队针对长视频理解设计了9类不同的任务,并进一步将任务分为三类:全面理解、单细节理解、多细节理解。
- 全面理解任务:要求MLLMs理解和利用视频的全局信息来解决问题
- 单细节理解任务:要求MLLMs根据问题定位长视频中的某一细节,并利用该细节来解决问题
- 多细节理解任务:要去MLLMs定位和理解长视频中的多个相关片段来完成和解决问题
此外,还包括了单项选择题和开放生成式问题,全面考察MLLMs在不同场景下的长视频理解能力。
以下为9大任务的示例:

问题设置与答案标注更合理
为了突出新旧基准变化,直接以情节问答(Plot Question Answering)任务为例。
假如以电影、电视的角色作为问题线索来对MLLMs进行提问,旧基准的常见问题有两种。
一是挑“经典”下手,这导致MLLMs在没有对视频进行分析的情况下,直接使用了自有知识回答问题。
另一部分试图避免这个问题,但由于长视频的复杂性,仅仅利用代词和描述性语句来指代情节细节非常困难。
他们的问题非常宽泛或者需要在问题中额外指定具体的时间片段而不是让MLLMs自己根据题目寻找对应细节。
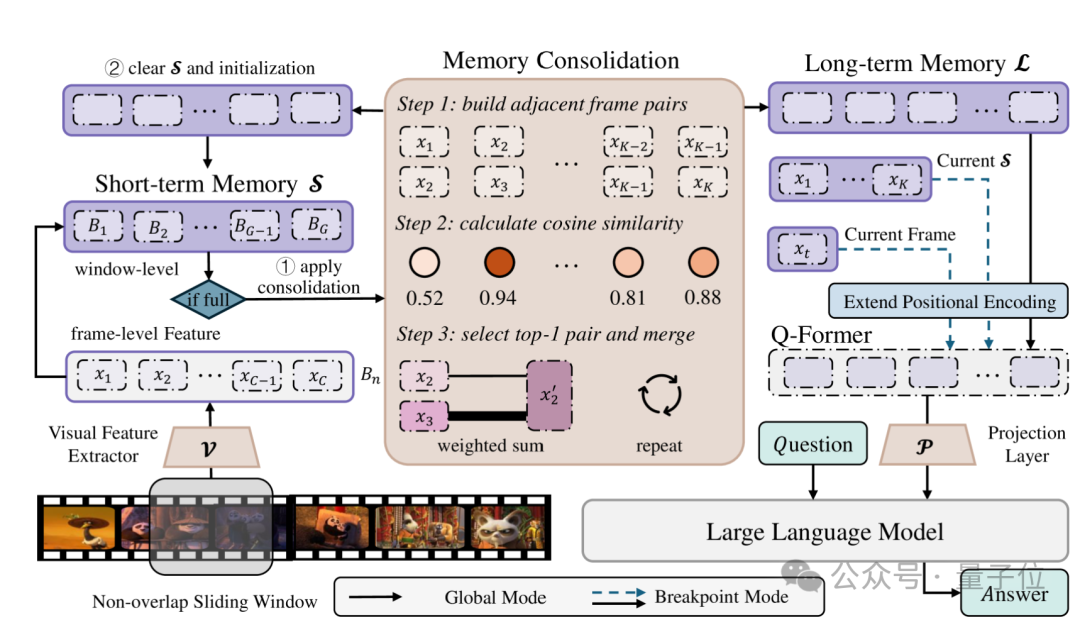
MLVU通过精细的人工标注克服了这些问题。
在所有的情节问答任务中,MLVU均使用**“具有详细细节的代词”**来指代情节中的人物、事件或背景,避免了问题泄露带来的潜在影响,MLLMs需要根据问题提供的线索识别和定位相关片段才能进一步解决问题。
此外,MLVU的Plot QA问题具备丰富的多样性,增强了评测的合理性和可靠性。

模型在MLVU上的表现
团队在MLVU上对20个流行的MLLM进行了评测,包括开源模型和闭源模型。
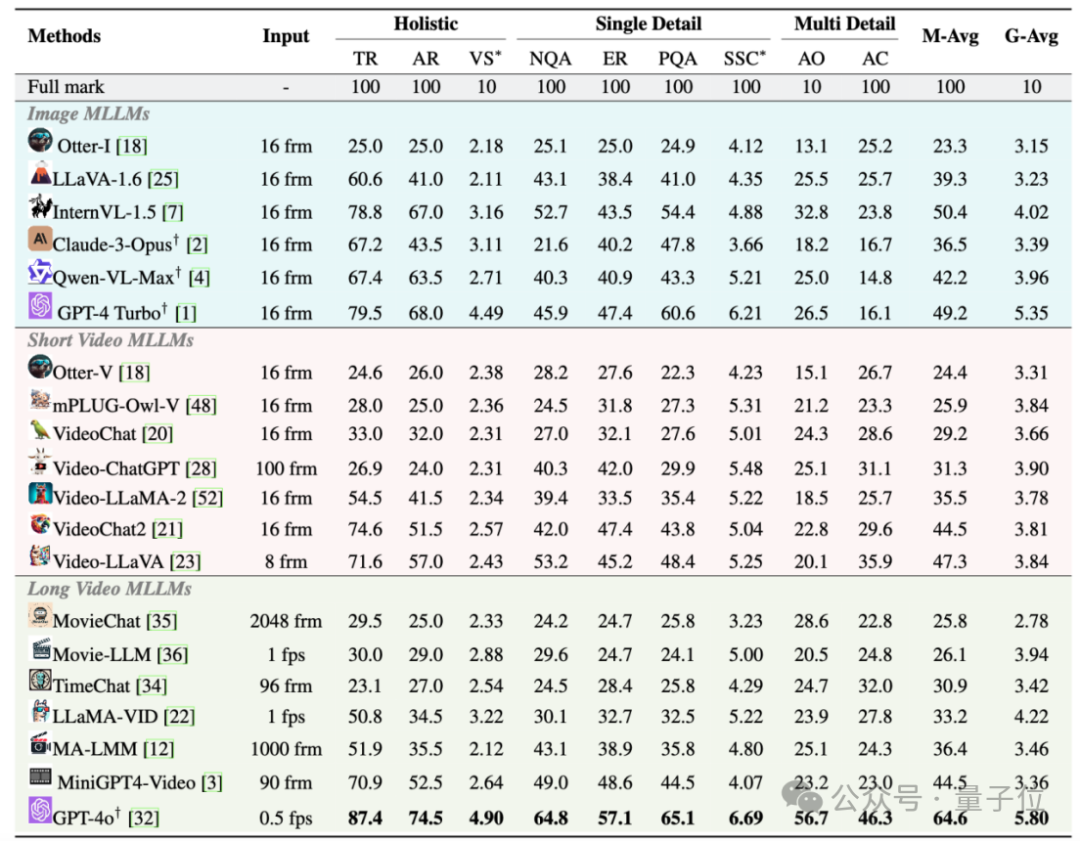
实验结果表明,尽管GPT-4o在所有任务中均取得了第1名,但它的单选平均准确率只有64.6%。
且所有模型都在需要细粒度理解能力的任务上(单细节、多细节理解任务)表现糟糕。
此外,大部分模型的性能都会随着视频时长增加显著下降。
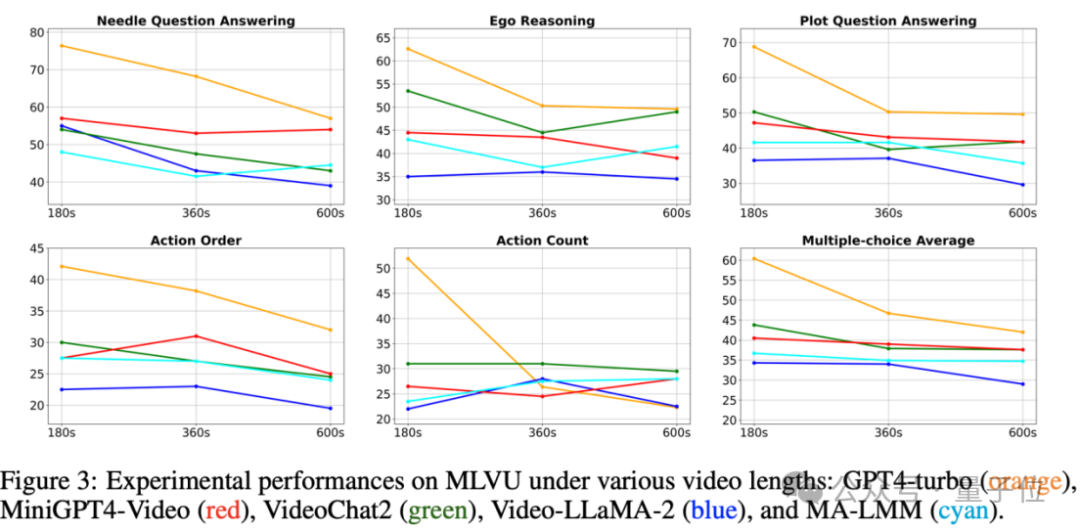
另一明显结论是,开源模型和闭源模型之间存在较大的差距。
开源模型中单项选择题性能最强的InternVL-1.5单选平均准确度仅有50.4%;开放生成式题目最强的LLaMA-Vid得分仅有4.22,均远远落后于GPT-4o的64.6%和5.80。
不过研究发现,提升上下文窗口,提升MLLM的图像理解能力,以及使用更强大的LLM Backbone对长视频理解的性能具有显著的提升作用。
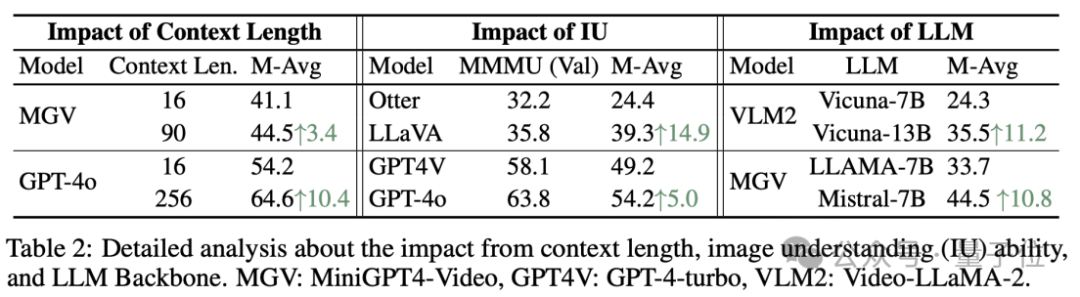
这揭示了未来MLLMs在提升长视频理解能力的重要改进方向。
论文:
https://arxiv.org/abs/2406.04264
项目链接:
https://github.com/JUNJIE99/MLVU
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









