






1. 官方案例
在 Dify 首页,第一个 Tab,官方内置了众多搭建好的智能体案例:
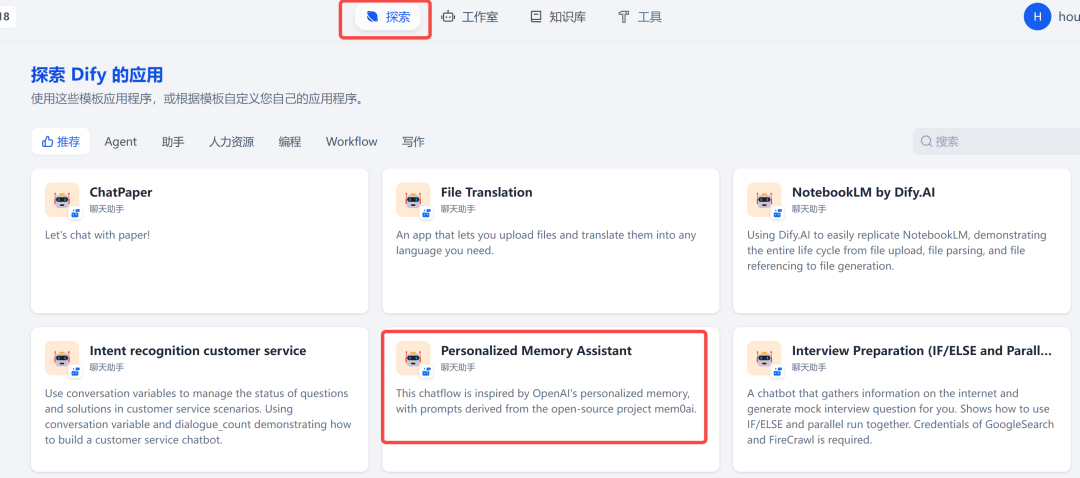
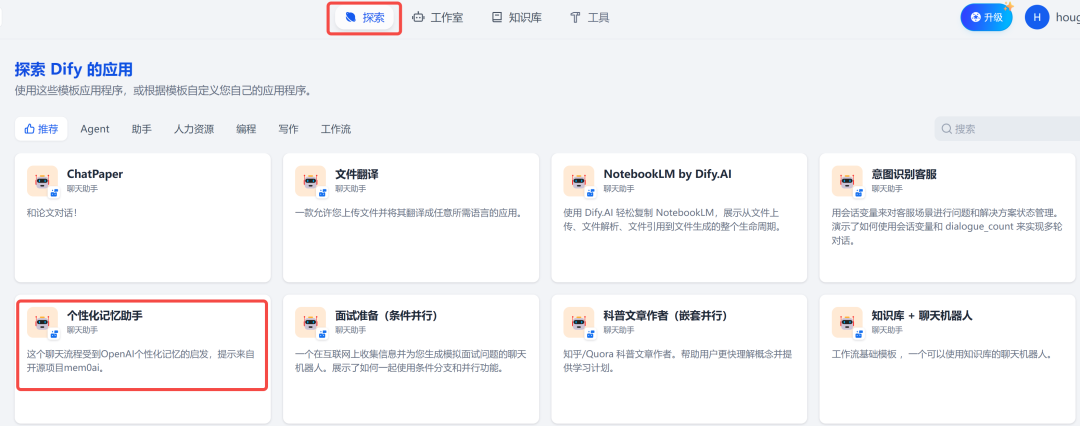
其中,有一个个性化记忆助手的智能体,点击添加到工作区:
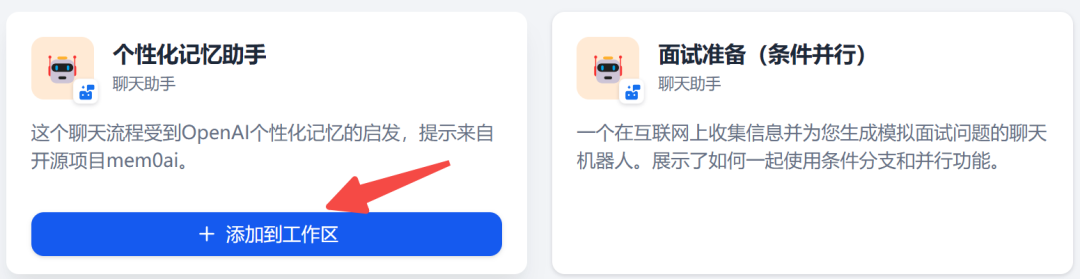
在自己的工作室,可以看到这个智能体已复制进来:
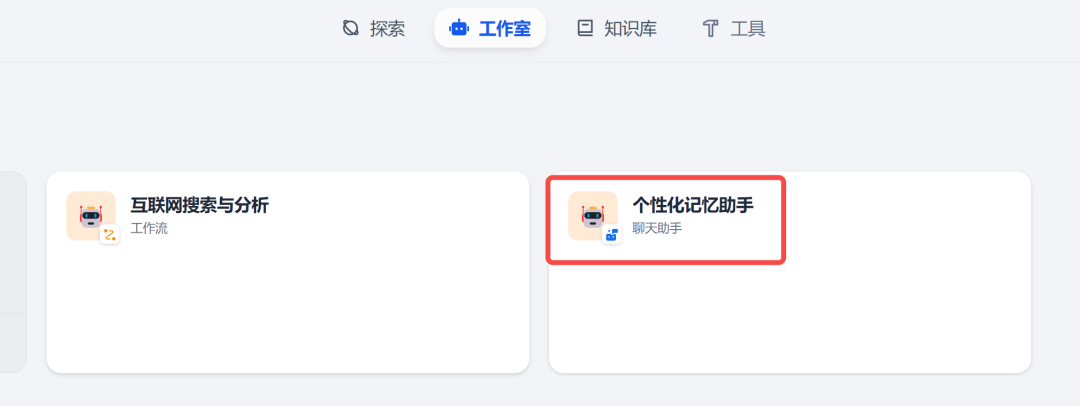
点进来,就可以看到所有的编排逻辑,然后可根据自己需求进行修改:
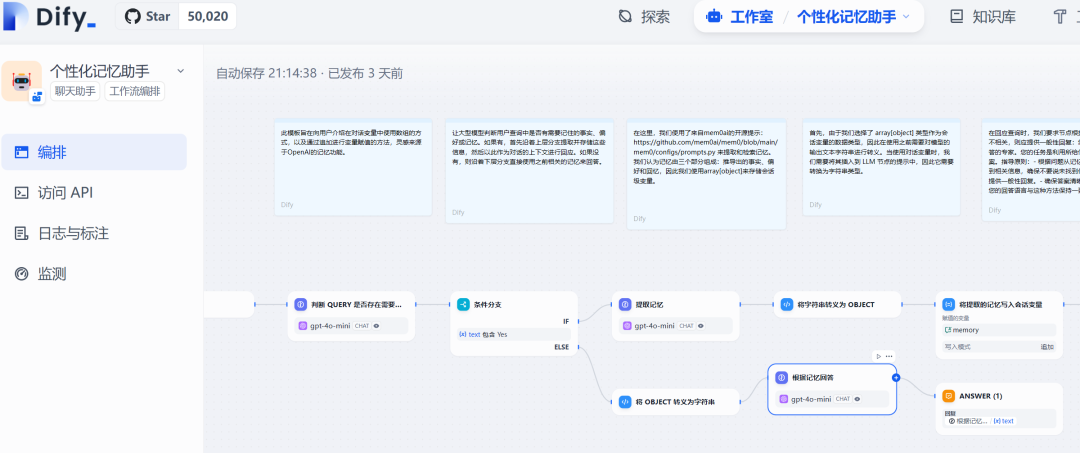
1. 了解会话变量
Dify 中内置了一个全局变量 – 会话变量,在右上角:
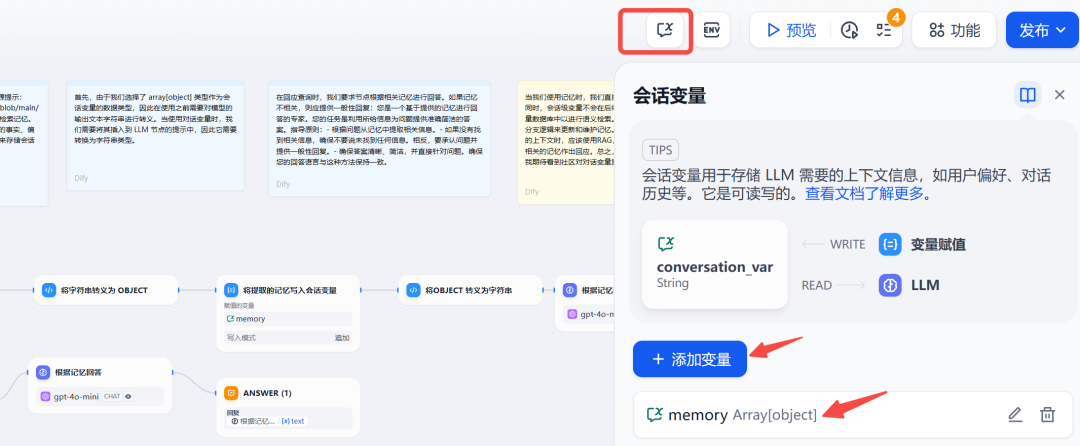
这个会话变量具体有什么用?
和多轮对话的内容一样,它也可以作为 LLM 的上下文,不过它的自定义程度更高。
比如在本文的智能体中,就定义了memory这样的会话变量,用来存储需要大模型记忆的信息。
问题来了:memory是怎么发挥作用的?
下面我们一起去探一探。
2. 智能体拆解
step 1 信息过滤: 判断用户输入中是否需要记忆的信息:
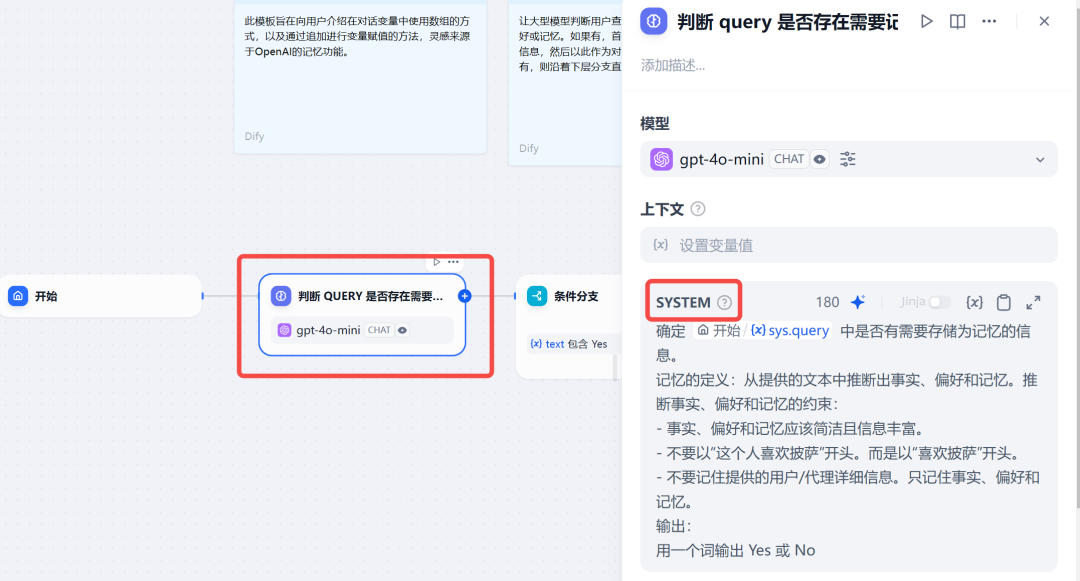
从上面的提示词,可以看出,这个节点上大模型只需输出 Yes 或 No,所以下个节点应该是条件判断。
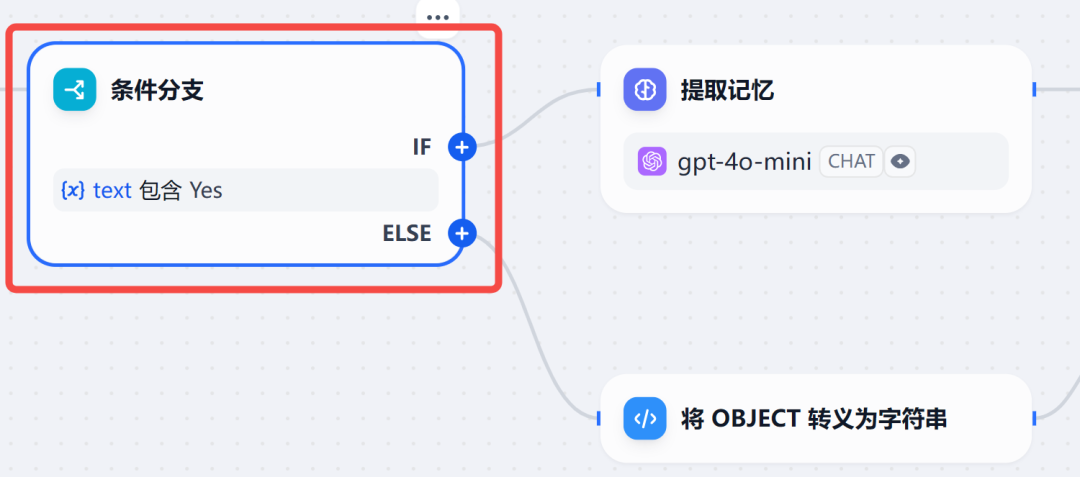
step 2 条件判断:根据上一步大模型输出的 Yes 或 No,分别路由到不同的分支,如果有需要记忆的信息,则执行上方提取记忆的分支,否则走下面的分支。
step 3 提取记忆:通过大模型的角色设定,从用户输入中提取出值得记忆的信息。
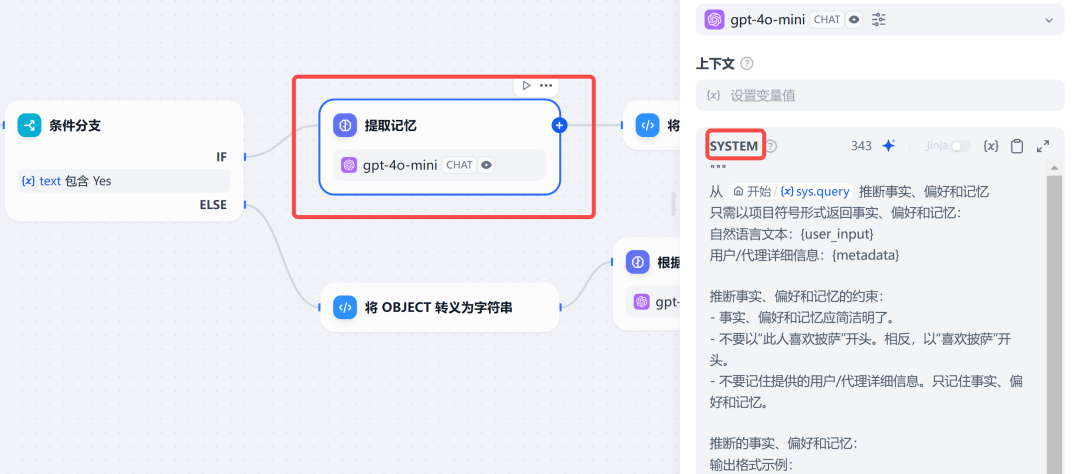
在提示词中,指定了提取的三种类型记忆:
"facts": [],
"preferences": [],
"memories": []
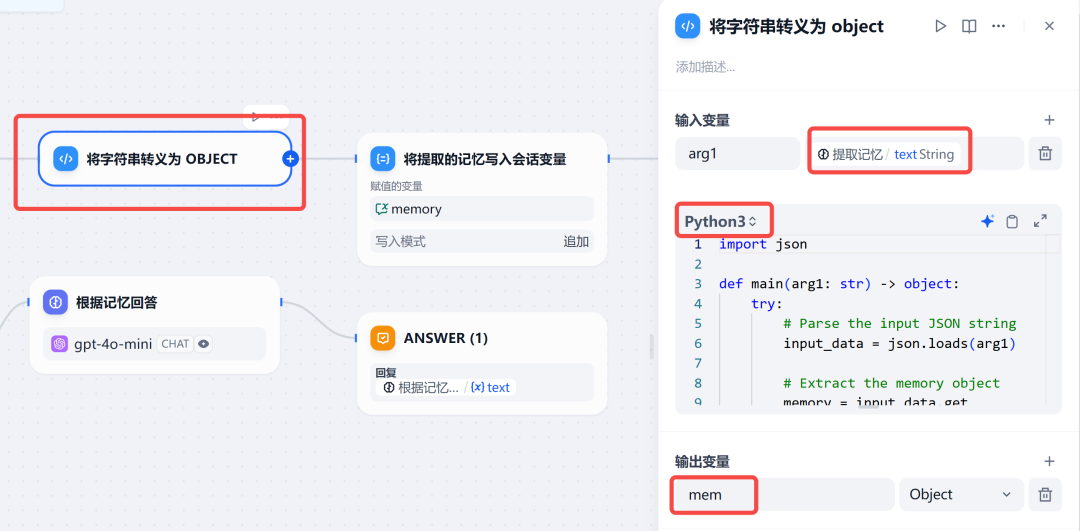
step 4 存储记忆:这一步是代码节点,通过编写简单的 Python 代码,将上一步的记忆信息,保存到一开始定义的会话变量 - memory中。
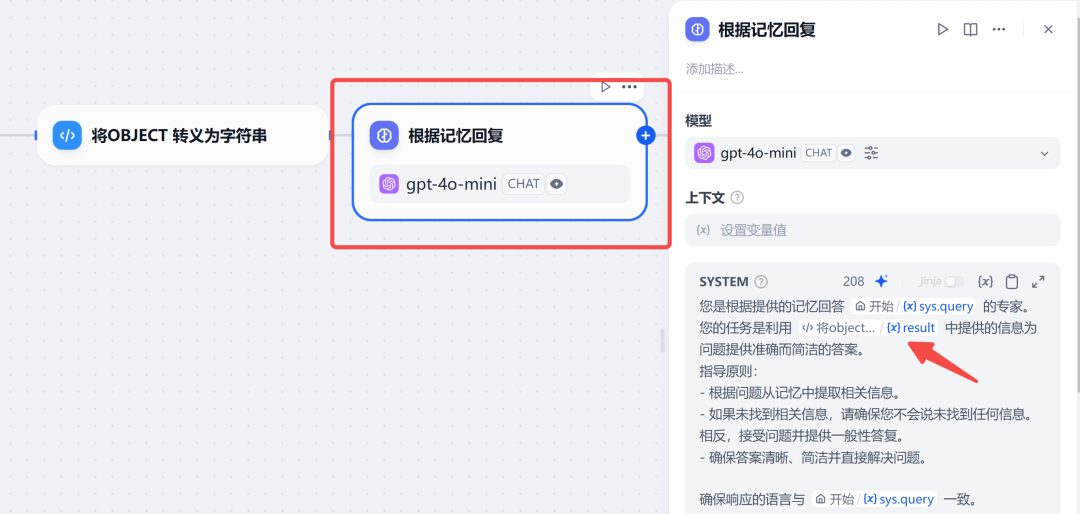
step 5 根据记忆回复:把会话变量 - memory转换成字符串,也就是下图中的{x}result,放到角色提示词中,让大模型根据记忆,进行答复。
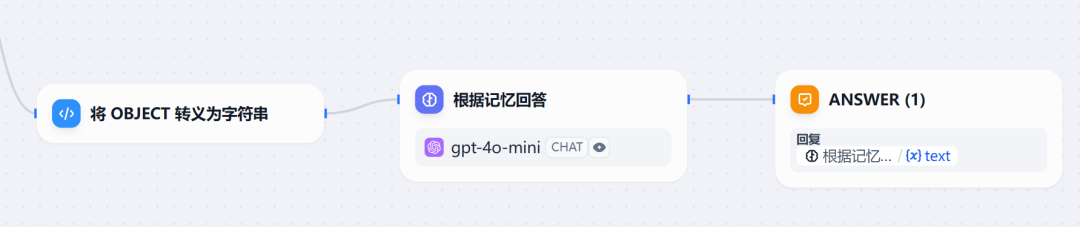
至此,基于对话内容中有需要缓存的记忆,上方提取记忆的分支就搞定了。
如果step 2判断为 No,则直接基于已有记忆进行答复,也即下方分支,流程图如下:
3. 效果展示
我在和它进行了几轮对话之后,点开右上角的会话变量,可以发现memory中已经缓存了多条事实类的记忆:
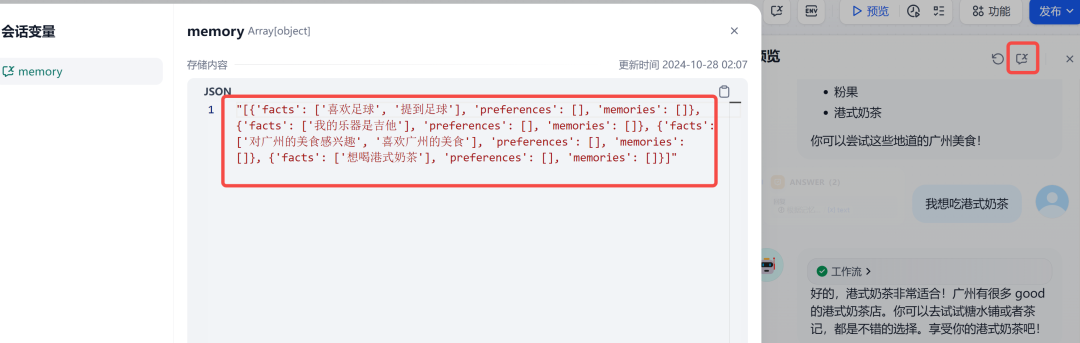
完美!
真的完美么?
相比直接把多条聊天记录作为上下文,这种方式要优雅很多,且极大减少了 Token 消耗量。
不过,个人认为至少还有两点缺陷:
- 随着记忆内容的增多,每次对话,把所有记忆内容都作为上下文,会显得十分冗余,这里可以结合 RAG 来做;
- 每次都从单论对话中提取记忆,缺乏足够的上下文,容易导致记忆内容的断章取义,理想的方式应该从多轮对话中提取有价值的信息;
写在最后
本文通过一个简单案例,带大家拆解并实操了Dify 搭建个性化记忆助手,整体流程比较简单,相信看到这里的你,一定还有很多想法要去实现,快去试试吧~
如果对你有帮助,欢迎点赞收藏备用。
之前微信机器人小爱(AI)的多轮对话,是通过本地缓存上下文信息实现,其实完全可以用本文的智能体替代,后面抽空改造后,再和大家分享!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2790
2790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









