






LLaMA
2024年4月18日,Meta发布了LLaMA-3,在开源大模型领域又一次引发了震动。Open AI虽然凭借GPT、DALL·E和SORA获得了巨大的成功,但这些模型都没有开源,只提供云端服务,Open AI也因此被调侃为Closed AI。而开源对于垂直领域研究和数据安全等方向都起到举足轻重的作用,因此本期借着LLaMA-3的发布,浅析开源大模型的领头羊——羊驼LLaMA系列。
背景
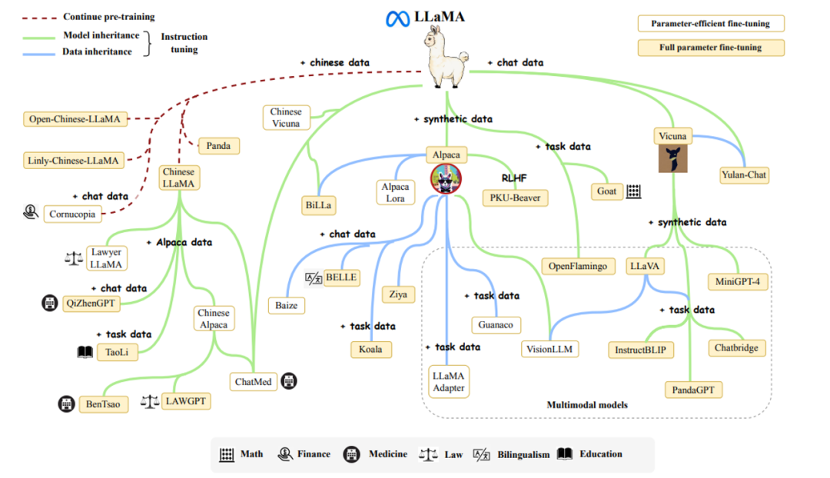
在计算机领域,任何问题都有解决方法,但要在限定算力,限定时间的情况下解决一个问题是相当困难的。以OpenAI为代表的云端大语言模型追求的是极致的效果,而以LLaMA为代表的小模型则追求在有限的资源下实现较好的效果。LLaMA-1发布于2023年2月,远晚于GPT系列,他使用了改进的Transformer解码器,并运用了各种工程化方法权衡了效果和效率,引领这开源语言模型的发展。
技术浅析
站在巨人肩膀上的LLaMA-1
LLaMA-1的发布顺应了时代的需求,OpenAI引领着云端大模型的发展,但实际应用中通信、数据安全、碳排放等都是值得思考的问题。LLaMA-1针对这些痛点提出了开放高效的基础大语言模型,其主要有两大核心要点。
LLaMA-1的第一个核心要点是针对原始的Transformer解码器进行升级。使用RMSNorm替换LayerNorm,使用SWiGLU替换原有前馈网络FFN,使用Rotary Embedding替换三角函数Embedding。
1) RMSNorm
Transformer原文使用的归一化方法是层归一化,LayerNorm,通过减去样本均值,再除以样本方差,使得整体样本不过于分散。
而RMSNorm则不减去样本均值,只进行缩放。这中方法相较于LayerNorm减少了中心化操作,通过牺牲部分样本的离散性,提升计算效率。
LayerNorm公式:
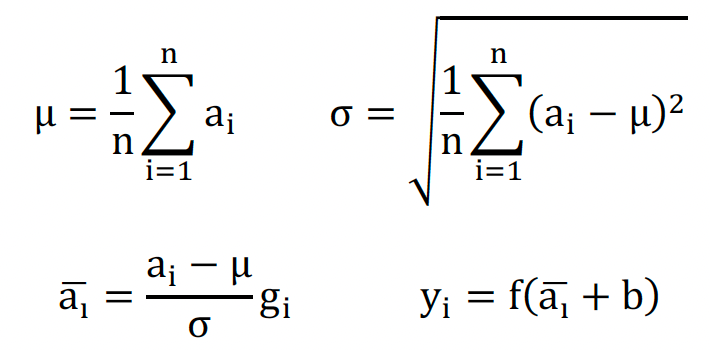
RMSNorm公式:
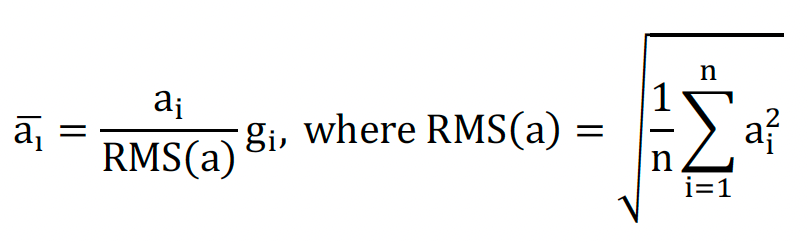
2) SWiGLU
SwiGLU本质上是对Transformer的FFN前馈传播层的第一层全连接和ReLU进行了替换,在原生的FFN中采用两层全连接,第一层升维,第二层降维回归到输入维度,两层之间使用ReLU激活函数。

SWiGLU采用两个权重矩阵和输入分别变换,再配合Swish激活函数做哈达马积的操作,因为FFN本身还有第二层全连接,所以带有SWiGLU激活函数的FFN模块一共有三个权重矩阵,SWiGLU公式如下:
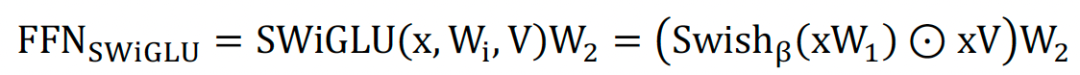
3) Rotary Position Embedding(RoPE)
旋转位置编码的基本思想是将每个位置的编码表示为一个复数,该复数的实部和虚部分别对应于一个旋转角度的余弦和正弦值。其公式可以简单表达为:
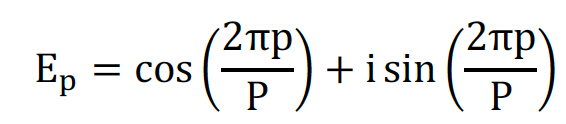
使用RoPE的意义:
\1. 通过特殊的复数位置编码可以实现数据并行计算提升模型整体推理效率
\2. 参数化的位置编码形式可以减少模型过拟合
\3. 编码方式连续且平滑,使得模型可处理较长序列文本
\4. 具有良好的数学特征,可解释性强
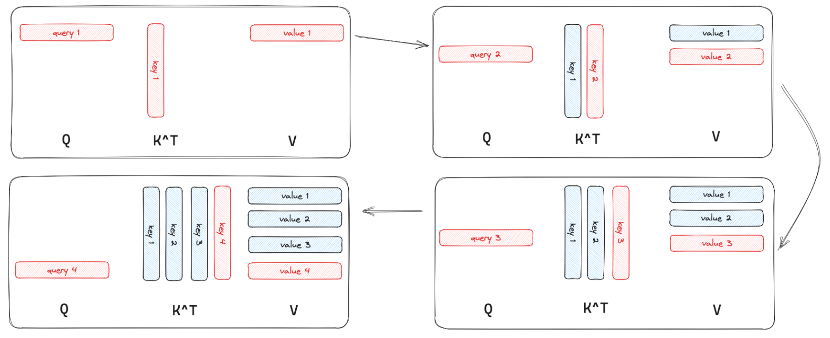
LLaMA-1另一个核心要点是使用了Key-Value Cache进行推理。众所周知,Transformer是一个训练高效,推理低效的架构。Transformer推理低效的核心原因是原始的自注意力计算随着文本长度变长,每次都需要计算之前的Key和Value的自注意力值,这造成了大量的计算浪费。
基于上述问题,LLaMA系列在推理时都采用Key-Value Cache的模式进行。Key-Value Cache在每次计算键值的自注意时,把结果存在Cache中,随着文本的增长,无需再计算之前的自注意力值,直接读取存储。这大大减轻了计算量,使得较小资源设备也能运行大语言模型,并且获得不错的效果。
人类价值观对齐的LLaMA-2
LLaMA-2在LLaMA-1发布后半年就被推了出来,他将预训练的语料扩充到了 2T token,同时将上下文长度从2,048翻倍到了4,096。他的两大核心点是使用了分组查询注意力机制和人工反馈的强化学习进行人类价值观对齐。
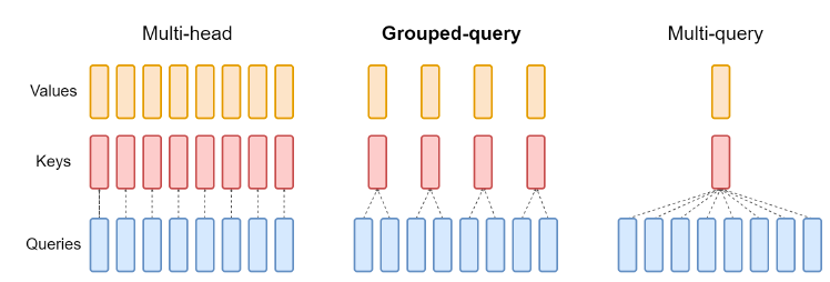
分组查询注意力其实是多头注意力和多查询注意力的权衡。多头注意力所有的Key,Value和Query都一一对应,计算复杂度大。而多查询注意力Key和Value对应,而Query是多对应关系,这中结构会造成信息损失从而导致效果不佳。因此LLaMA在此做出权衡,使用分组查询注意力,提升效率的同时保证质量。
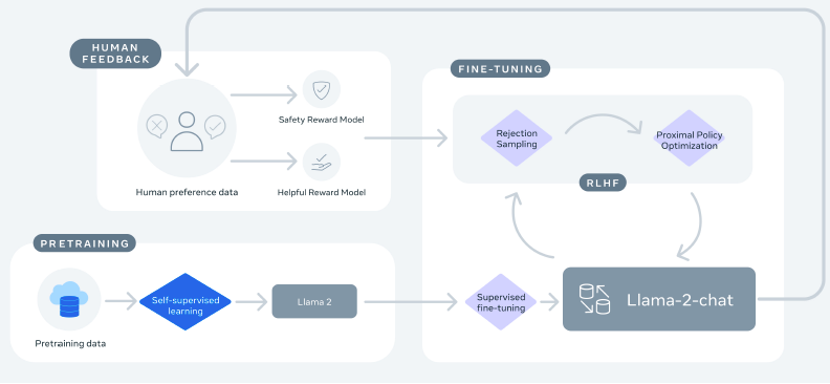
在模型与人类价值观对齐上,LLaMA-2和同时期的GPT-4类似,都采用了人工反馈的强化学习(RLHF)。而Meta基于LLaMA-2专门构建了一个LLaMA-2-chat提供人工反馈强化学习后的模型。RLHF主要通过人工标注的方式评判语言模型的输出内容是否符合人类价值观,然后形成奖励函数,并通过强化学习的方式对模型进行训练。
接近云端模型效果的LLaMA-3
上个月,Meta发布了全新的LLaMA-3的两个小参数版本8B和70B并提供在线下载,更大参数量的版本正在训练,论文细节未来也会很快公布,本节内容主要探讨公布出的效果。
LLaMA-3相较于LLaMA-2支持的上下文长度又翻了一倍,支持8k长上下文,预训练语料库也扩展为15T水平。无论是8B还是70B的模型,都比参数量接近的其他模型优秀。
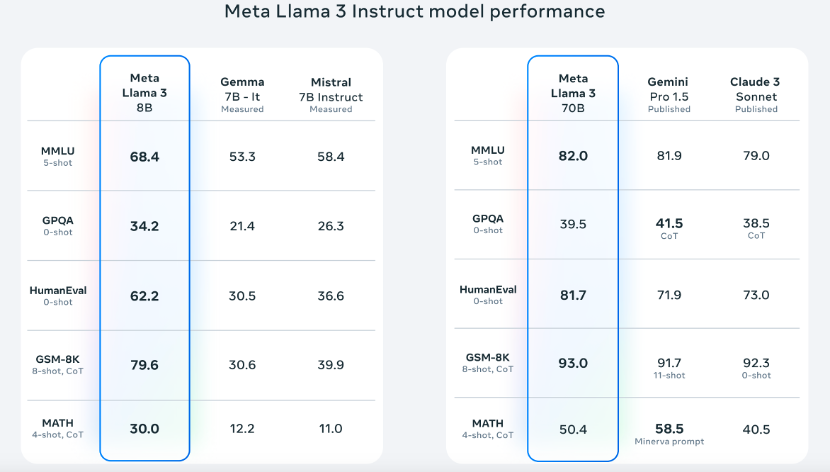
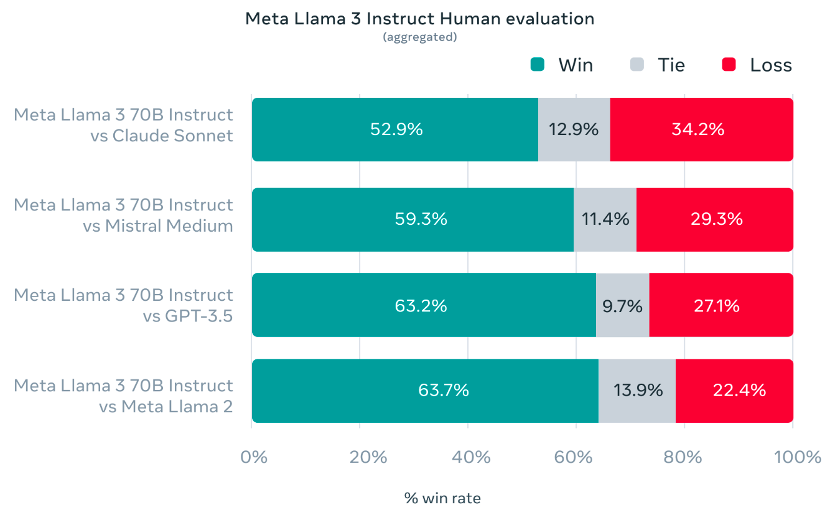
在Meta自己开发的包含1800个提示的数据集,LLaMA-3的效果战胜了Claude 3 Sonnet、Mistral Medium和GPT-3.5这些知名模型。
Meta也公布了自己正在训练的400B参数量的LLaMA-3的效果,其效果已经接近早期的云端大模型如ChatGPT,期待其完全训练完后的效果。

开源大语言模型的优势
开源大语言模型的优势主要聚焦在两个方面,一是安全性,二是低资源性。
在安全性上,开源大语言模型相较于目前常见的云端+远程调用模式,对于to B和to C商业化更加安全。针对B端用户,使用者无需将公司的核心信息,如资产负债、企业经营情况等,上传至云端进行数据分析,而是利用本地资源实现分析,提升生产效率的同时,避免数据泄露风险。针对C端用户,个人用户使用本地的开源大语言模型,避免了所有的行为数据的采集与上传,保护了个人隐私数据的安全性,减少了无序广告的推荐。
在资源上,开源大语言模型在训练和推理上需要的资源远小于以GPT为代表的闭源大语言模型。普通的小型公司也可以通过购买几块GPU来搭建企业专属的大语言模型,极大地降低了使用大语言模型的成本。对于个人用户,目前已经可以在极资源设备,如具有8G运存的iPhone15 Pro Max,iPad Pro和笔记本电脑上部署小参数版本的LLaMA模型,NVIDIA也推出了Chat with RTX工具供普通用户使用,使用大语言模型的成本得到了极大的降低。
开源大模型未来发展
虽然低资源设备部署的大模型效果不及云端大语言模型优秀,但已经具备基本语言理解和生成能力。未来开源大语言模型一定会向着更准确、更高效、更安全、更智能的方向发展。在可遇见的未来,诸如手机等边缘设备都会嵌入更强大的开源大语言模型,构建全能的个人助手,实现从工作到生活个性化管理。
结论
LLaMA系列模型的初衷是开源和高效,他就是为了打破云端大模型的垄断而提出。虽然目前的效果与最先进的云端大模型仍然有的差距,也仅限于文本模态,但是开源的魅力在于你永远不是孤军奋战。正如Linux开源后的勃勃生机,相信以LLaMA为首的开源大模型也将不断进步,向着实现通用人工智能前进。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









