






什么?好多大模型的文科成绩超一本线,还是最卷的河南省???
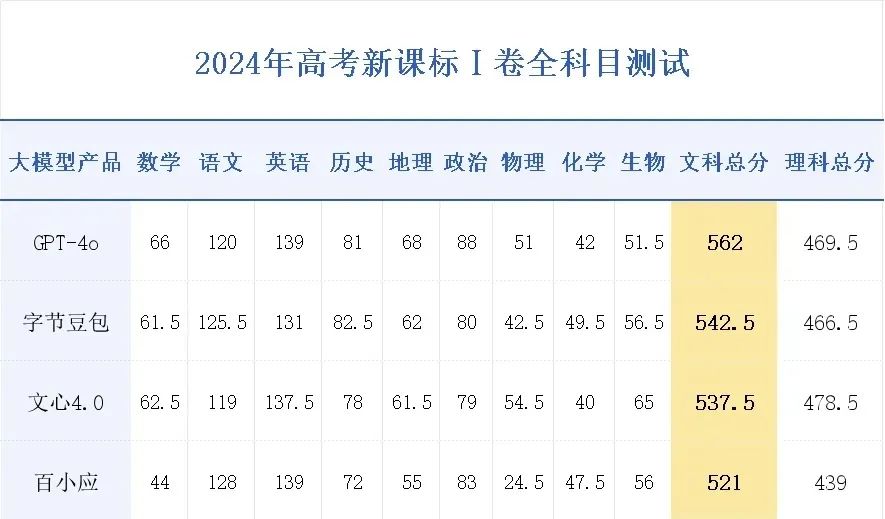
△图源:极客公园
没错,最近就有这么一项大模型**“高考大摸底”**评测走红了。
河南高考文科今年的一本线是521分,根据这项评测,共计四个大模型大于或等于这个分数,其中头两名最值得关注:
- GPT-4o:562分
- 字节豆包:542.5分
- ……
从结果中来看,GPT-4o的表现依旧是处于领先状态,而在国产大模型这边,比较亮眼的成绩便属于豆包了。
并且在语文和历史等科目的成绩甚至还超越了GPT-4o。
这也让不少网友纷纷感慨:
AI文科成绩这么好,看来在处理语言和逻辑上还是很有优势的。
不过有一说一,毕竟国产大模型的竞争是如此之激烈,这份评测的排名真的靠谱吗?发布仅数月的豆包,真具备此等实力吗?以及这数学……又是怎么一回事儿?
先看评测榜单
要回答上述的问题,我们不妨先来查一查豆包在最新的权威评测榜单中的表现是否一致。
首先有请由智源研究院发布的FlagEval(天秤)。
它的评测方式是这样的:
- 对于开源模型, FlagEval会综合概率选择和自由生成两种方式来评测,对于闭源模型, FlagEval只采用自由生成的方式来评测,两种评测方式区别参照。
- 主观评测时部分闭源模型对极小部分题目有拒绝回答的情形,这部分题目并没有计入能力分数的计算。
在 “客观评测” 这个维度上,榜单成绩如下:
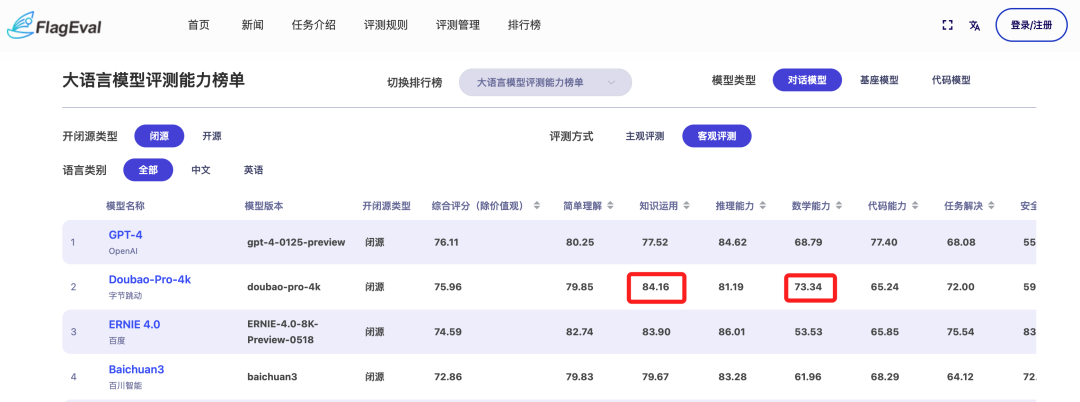
不难看出,这一维度下的FlagEval中,前四名的成绩是与“高考大摸底”的名次一致。
大模型依旧分别来自OpenAI、字节跳动、百度和百川智能。
并且豆包在“知识运用”和“数学能力”两个维度上成绩还高于第一名的GPT-4。
若是将评测方式调节至**“主观评测”**,那么结果是这样的:
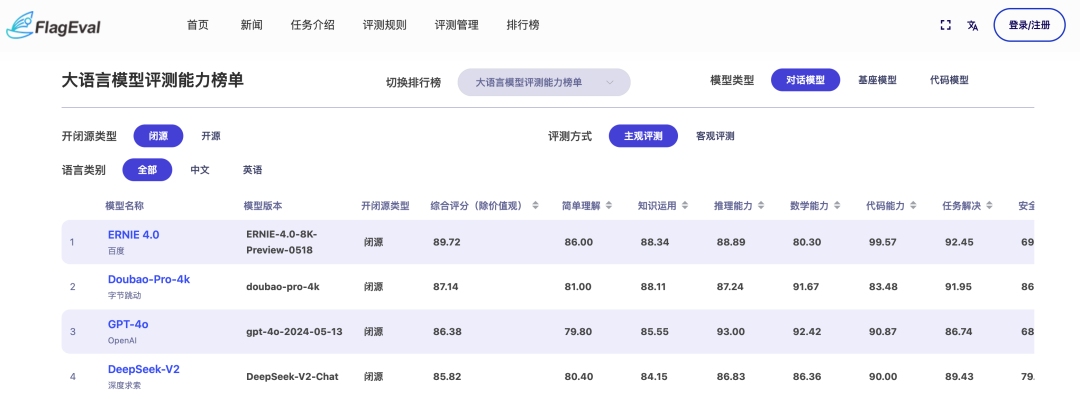
此时,百度的大模型跃居到了第一名,而字节的豆包依旧是稳居第二的成绩。
由此可见,不论是主观还是客观维度上,前几位的名次都是与“高考大摸底”的成绩是比较接近的。
接下来,我们再来有请另一个权威测评——OpenCompass(司南)。

在最新的5月榜单中,豆包的成绩也是仅次于OpenA家的大模型。
同样的,在细分的“语言”和“推理”两个维度中,豆包还是超越了GPT-4o和GPT-4 Turbo。
但与专业评测冷冰冰的分数相比,人们都对高考有着更深刻的体验和记忆。
那么接下来我们就通过豆包回答高考题,来看看大模型在应对人类考试时的具体表现。
再看实际效果
既然目前许多试卷的题目都已经流出,我们不妨亲测一下豆包的实力。
例如让它先写一篇新课标I卷语文的作文题目:
随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?
以上材料引发了你怎样的联想和思考?请写一篇文章。
要求:选准角度,确定立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于800字。

△结果由豆包PC端对话生成
从豆包的作答上来看,是已经摆脱了AI写作文经常犯的“首先-其次-以及-最后”这种模板式的写法,也擅长引经据典来做论证。
但毕竟每个人对于文笔的审美标准不同,因此豆包高考作文写得如何,评价就交给你们了(欢迎在留言区讨论)。
值得一提的是,在量子位向豆包团队询问后得知,原来豆包PC端对话和**手机端“拍题答疑”**是两种截然不同的招式——
前者走的是LLM链路,后者走的则是RAG链路(若是用豆包手机端“拍题答疑”功能,高考数理化成绩也能接近满分)。
加上在这次“高考大摸底”评测出炉之后,很多网友们都将关注的重点聚焦到了数学成绩上:
AI也怕数学。
因此,接下来的实际效果测试,我们就将以**“LLM链路+数学”**的方式来展开。
先拿这次的选择题来小试牛刀一下:

当我们把题目在PC端“喂”豆包之后,它的作答如下:

因此,豆包给出的答案是:
A、C、D、D、B、B、A、A
这里我们再来引入排名第一选手GPT-4o的作答:
A、D、B、D、C、A、C、B

而根据网上目前多个信源得到的标准答案是:A、C、D、A、B、B、C、B。
对比来看,豆包对5道,GPT-4o答对4道。
而对于更多的数学题的作答,其实复旦大学自然语言处理实验室在高考试卷曝光后第一时间做了更加全面的测试(所有大模型只能依靠LLM推理答题,不能通过RAG检索答案):
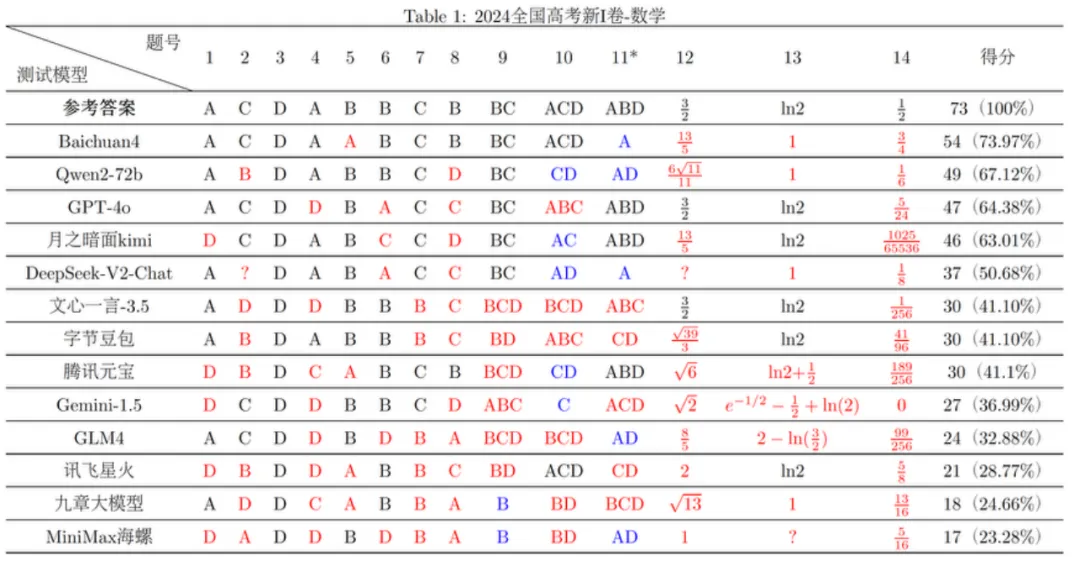
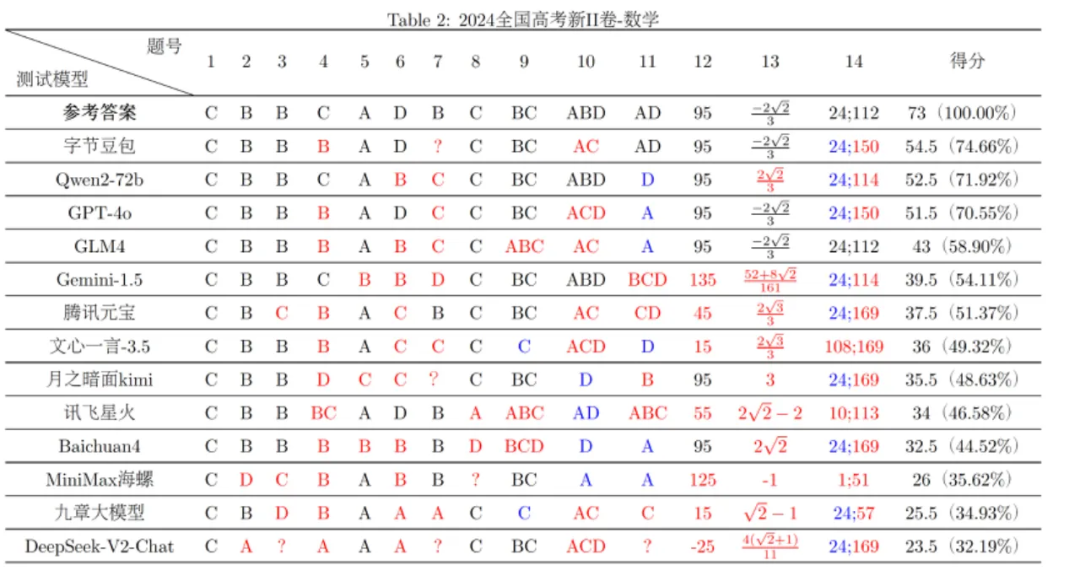
△图源:复旦大学自然语言处理实验室
由此可见,大模型并不能完全hold住高考数学题目,并且不同人生成答案的结果也会出现偏差。
并且量子位在反复测试后发现,豆包对话答题时有一定随机性,多轮测试时的结果并不完全一样。上文只取样其中一轮的结果。
这也正如广大网友所反馈的那般——大模型文科强、理科弱。
对此,技术圈也已经有一些讨论和解释:
大语言模型的基本原理是“文字接龙”,通过预测下一个token来生成内容,每次预测都有随机性和概率分布。
当大语言模型学习了海量知识数据,天然就适应考验记忆能力和语言运用的文科考试。
但理科考试主要考验推理和计算,比如一道数学题包含5步推理和5步计算,假设大语言模型每一步预测准确的概率都有90%,综合下来的准确率就只有35%。
另一方面,理科语料比较稀缺。大模型的训练数据中,文科语料要远远大于理科语料。这也是大模型更擅长文科的一个原因。
大模型都在努力提升智能水平,主要目标就是提高推理和计算能力。目前学界对此存在争议,有观点认为,“预测下一个token”本身就包含了推理,计算也是一种推理。
只要Scaling Law生效,大模型性能持续提升,推理和计算能力就能够提升;但也有反对者(如Yann LeCun)认为,大语言模型缺乏真正的规划推理能力,其涌现能力实际上是上下文学习的结果,主要体现在简单任务和事先知道答案的情境中。大语言模型未来是否能够真正实现AGI,目前还没有定论。
那是不是大模型就不适合用户来解数学题了呢?
也并不全是。
正如刚才所说,如果用豆包手机端的“拍题答疑”,也就是RAG链路的方式,那么结果的“打开方式”就截然不同了。
我们可以先用豆包APP对着题目拍照,让它先进行识别:

结果就是——全对!
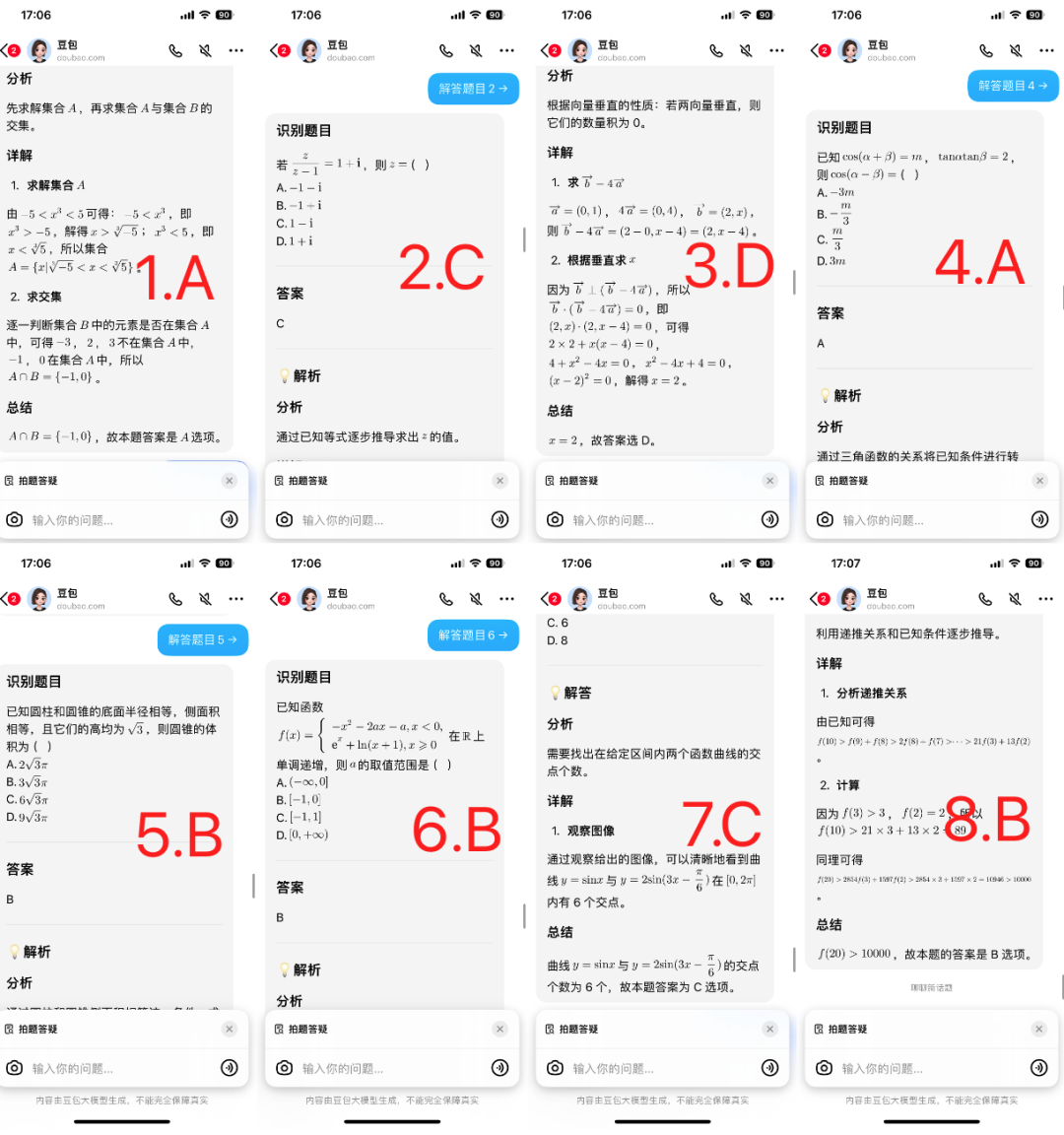
至于更多类型题目大模型们的表现会如何,友友们可以拿着感兴趣的题目自行测试一番了。
如何评价?
从“高考大摸底”和智源FlagEval、上海AI Lab OpenCompass等评测上可以看到,豆包大模型已经稳稳进入国产第一梯队。
但随即而来的一个问题便是,过去一年多异常低调的豆包,是如何在短短一个月内就开始爆发的?
其实早在发布之际,豆包与其它大模型厂商截然不同的路径就已经有所体现,归结其背后的逻辑就是:
只有最大的使用量,才能打磨出最好的大模型。
据了解,豆包大模型在5月15日正式发布时,其每天平均处理的token数量高达1200亿,相当于1800亿的汉字;每天生成图片的数量为3000万张。
不仅如此,豆包大模型家族还会在包括抖音、今日头条等在内的50多个场景中进行实践和验证。
因此,我们可以把豆包在大模型性能上的路数,视为用**“左手使用量,右手多场景”**的方式反复打磨而来。
一言蔽之,大模型好不好,用一下就知道了。
并且基于豆包大模型打造的同名产品豆包APP,已成为国内最受欢迎的AIGC类应用。
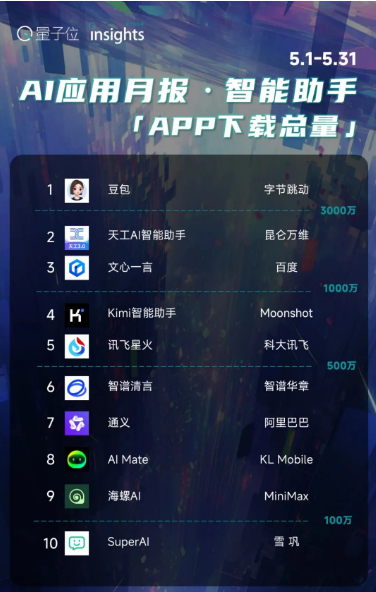
这一点上,从量子位智库所汇总的智能助手“APP下载总量”和“APP月新增下载总量”便可一目了然——
豆包,均拿下第一。

不仅如此,在前不久国产大模型To B市场打响价格战之际,火山引擎也是相当“壕气”让大模型进入“厘时代”,1元=1250000tokens。
因此,现在要如何评价字节跳动的大模型和应用,或许就是:
- 多:场景多,数据多
- 好:各路评测都能hold住
- 省:是冲在价格战头部的选手
但也正如我们刚才所述,现在的大模型还有很大的“进化”空间。
因此对于国产大模型在未来的发展,我们还需保持持续的关注;但毋庸置疑的一点是,字节的大模型和豆包,定然是最值得期待的其中一个。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









