






一文读懂RAGFlow:手把手教你搭建RAG知识库
引言
最近随着Deepseek的火爆,如何高效地整合海量数据与生成式模型成为了技术领域内的一大热点。传统的生成模型在回答复杂问题时常常依赖于预训练数据的广度与深度,而检索增强生成(Retrieval-Augmented Generation,简称RAG)则有效结合了检索与生成的优势,为各类应用场景提供了更为灵活、高效的解决方案。
RAGFlow概述
RAGFlow的定义
RAGFlow是一种融合了数据检索与生成式模型的新型系统架构,其核心思想在于将大规模检索系统与先进的生成式模型(如Transformer、GPT系列)相结合,从而在回答查询时既能利用海量数据的知识库,又能生成符合上下文语义的自然语言回复。该系统主要包含两个关键模块:数据检索模块和生成模块。数据检索模块负责在海量数据中快速定位相关信息,而生成模块则基于检索结果生成高质量的回答或文本内容。
在实际应用中,RAGFlow能够在客户服务、问答系统、智能搜索、内容推荐等领域发挥重要作用,通过检索与生成的双重保障,显著提升系统的响应速度和准确性。
特点
- • 高效整合海量数据:借助先进的检索算法,系统能够在大数据中迅速找到相关信息,并将之用于生成回答。
- • 增强生成质量:通过引入外部数据,生成模块能够克服模型记忆限制,提供更为丰富和准确的信息。
- • 应用场景广泛:包括但不限于在线问答系统、智能客服、知识库问答、个性化推荐等。
RAGFlow应用场景
在在线客服系统中,RAGFlow能够利用用户的历史咨询记录、产品文档以及FAQ等数据,实时检索出最相关的信息,并通过生成模块整合成自然、连贯的回复,从而大幅提升客户满意度。
RAGFlow系统架构
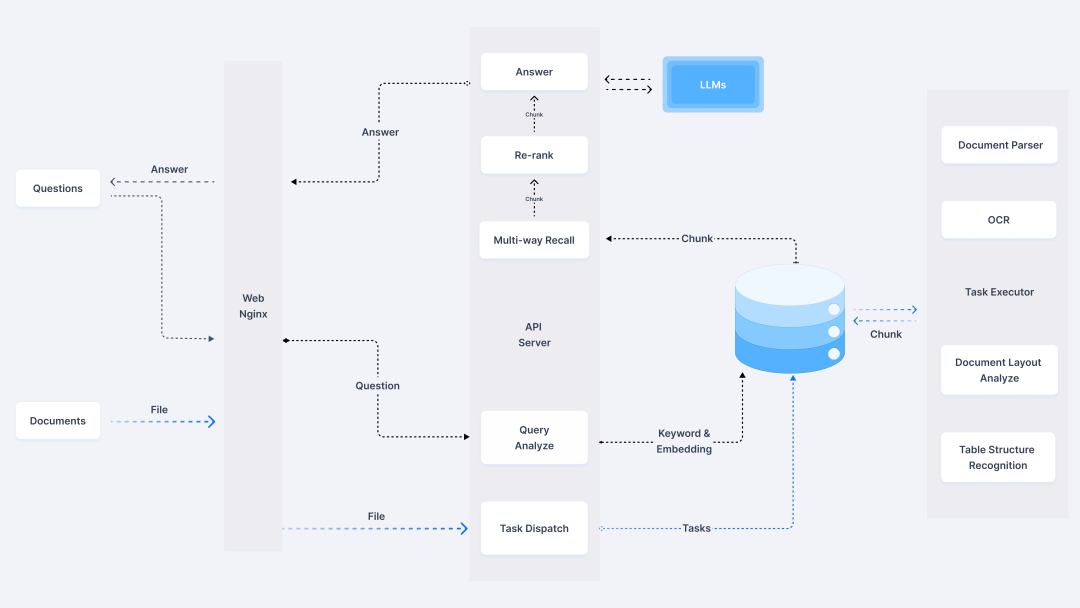
环境准备与系统搭建
环境需求
在搭建RAGFlow系统前,需要确保开发与运行环境满足以下要求:
- • 硬件配置:建议采用多核CPU、充足内存(16GB及以上)以及支持高并发访问的存储设备;如需部署大规模检索服务,可考虑使用分布式存储集群。
- • 操作系统:推荐使用Linux发行版(如CentOS、Ubuntu)以便于Shell脚本自动化管理;同时也支持Windows环境,但在部署自动化脚本时可能需要适当调整。
- • 开发语言与工具:主要使用Java进行系统核心模块开发,同时结合Shell脚本实现自动化运维。
- • 依赖环境:需要安装Java 8及以上版本,同时配置Maven或Gradle进行依赖管理;对于数据检索部分,可采用ElasticSearch、Apache Solr等开源检索引擎;生成模块则依赖于预训练模型,可以借助TensorFlow或PyTorch进行实现。
服务器配置
- • CPU >= 4 核
- • RAM >= 16 GB
- • Disk >= 50 GB
- • Docker >= 24.0.0 & Docker Compose >= v2.26.1
安装
修改 max_map_count
确保 vm.max_map_count 不小于 262144
如需确认 vm.max_map_count 的大小:
$ sysctl vm.max_map_count
如果 vm.max_map_count 的值小于 262144,可以进行重置:
# 这里我们设为 262144:
$ sudo sysctl -w vm.max_map_count=262144
你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把 vm.max_map_count 的值再相应更新一遍:
vm.max_map_count=262144
下载仓库代码
git clone https://github.com/infiniflow/ragflow.git
Docker拉取镜像
修改镜像为国内镜像并且选择embedding版本
修改文件docker/.env/
默认配置为:RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim
修改为国内镜像:RAGFLOW_IMAGE=registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow:v0.16.0
| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|---|---|---|---|
| v0.16.0 | ≈9 | ✔️ | Stable release |
| v0.16.0-slim | ≈2 | ❌ | Stable release |
| nightly | ≈9 | ✔️ | Unstable nightly build |
| nightly-slim | ≈2 | ❌ | Unstable nightly build |
运行命令拉取镜像
docker compose -f docker/docker-compose.yml up -d
 查看日志
查看日志
docker logs -f ragflow-server
提示下面提示说明启动成功
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
访问IP,进入 RAGFlow,注意不是 9380 端口,Web是http://127.0.01默认为 80 端口
应用
注册账号
注册完直接登录
添加模型
本文用到的模型类型:Chat 和 Embedding。 Rerank 模型等后续在详细介绍。
点击右上角->模型提供商->添加模型
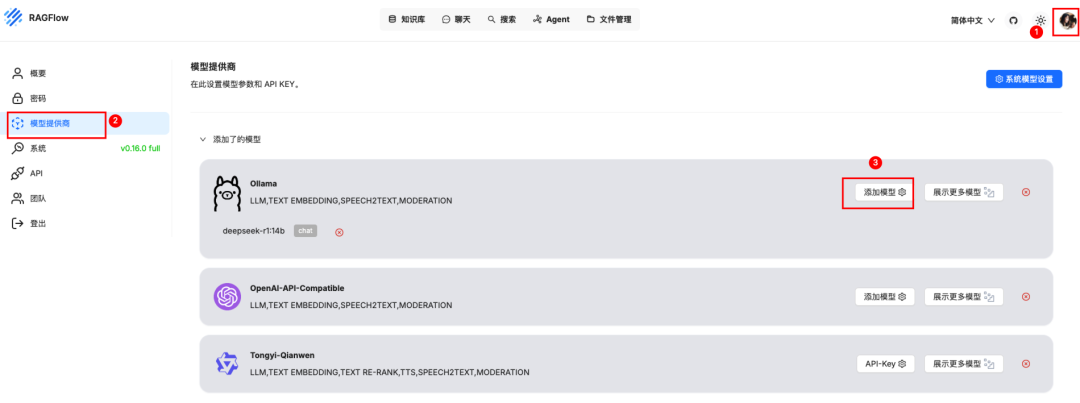
填写模型信息,模型类型选 chat
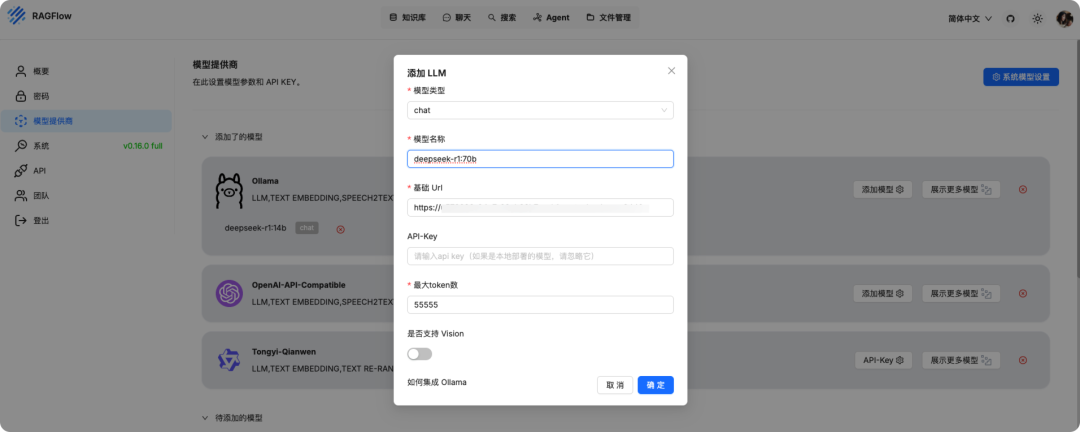
再添加一个 Embedding 模型用于知识库的向量转换(RAGFlow 默认也有 Embedding)
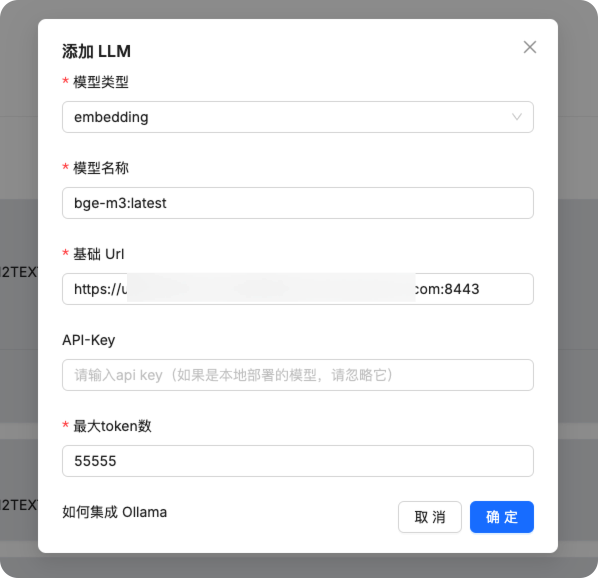
在系统模型设置中配置聊天模型和嵌入模型为我们刚刚添加的模型
创建知识库

填写相关配置
- • 文档语言:中文
- • 嵌入模型:选择我们自己运行的
bge-m3:latest,也可以用默认的。具体效果大家自行评估
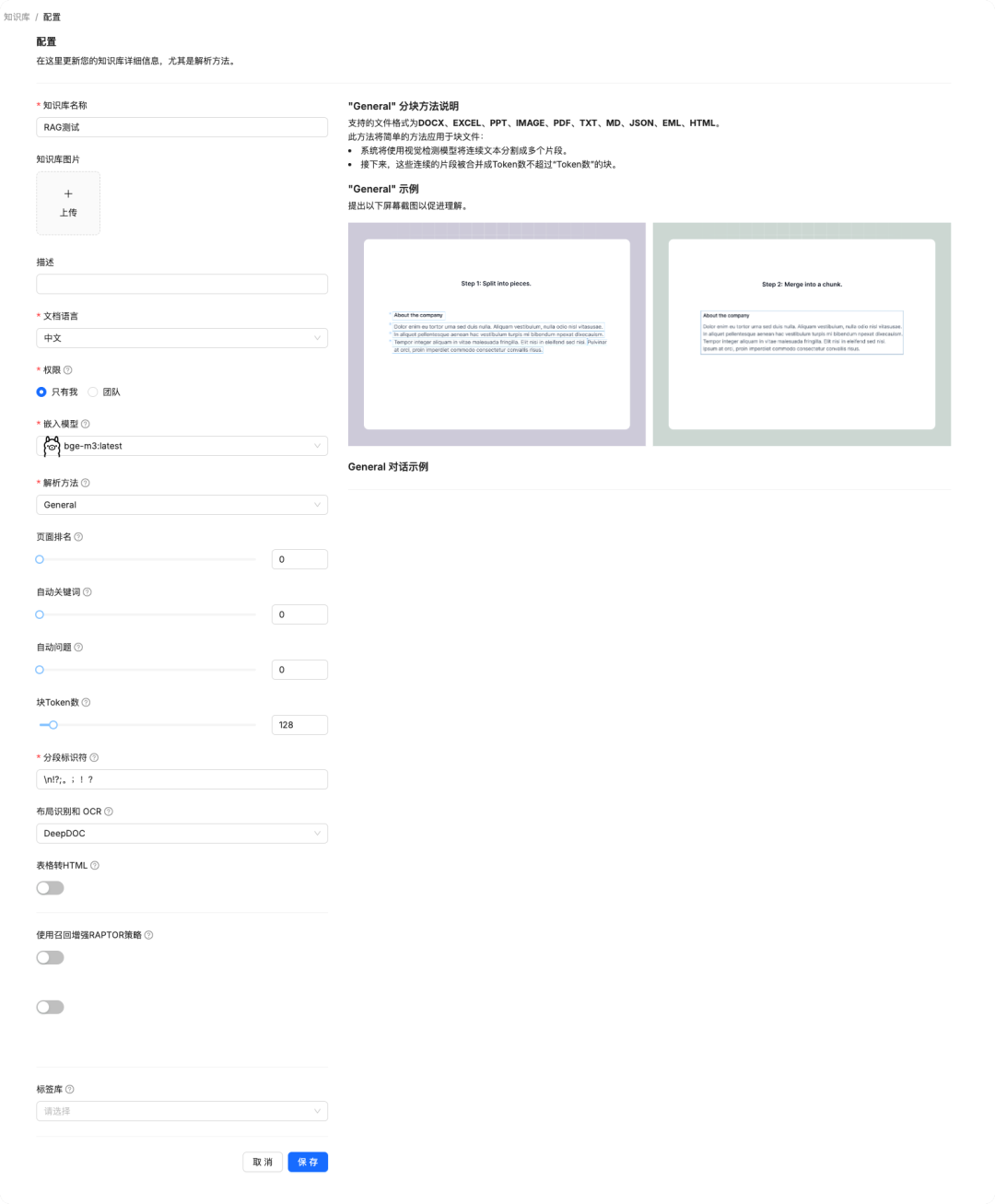
上传文件
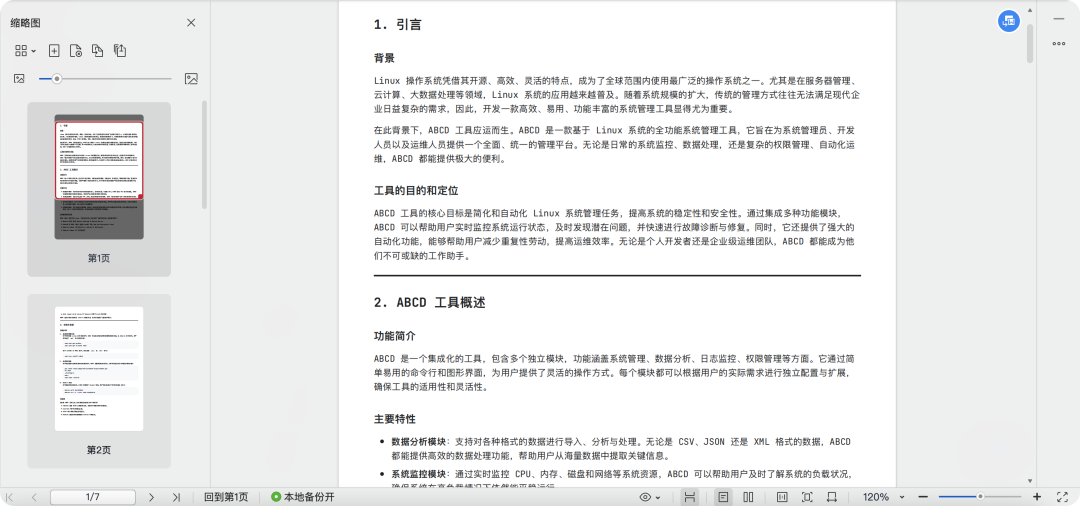
这里我自己造了一个测试文档来验证知识库,内容是编的,介绍一个 ABCD 工具,文档在文末提供下载。
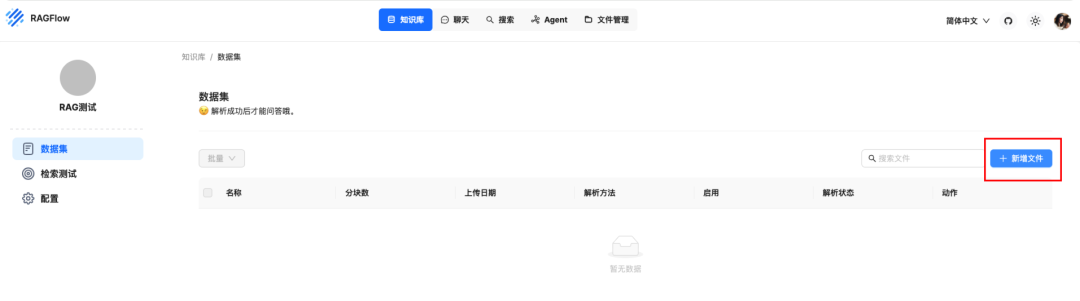
文件上传后是未解析状态,需要解析才可以使用,点击解析
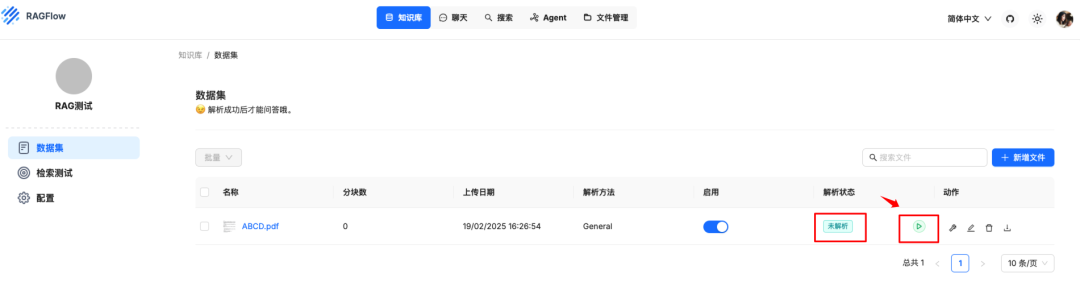
解析成功后点击文件可以看到解析效果
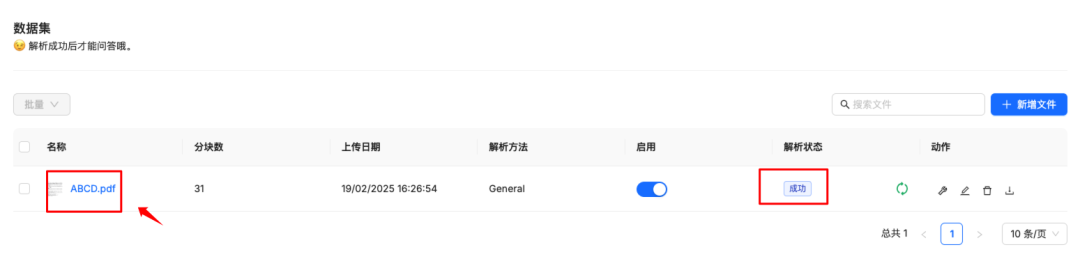
效果

创建聊天
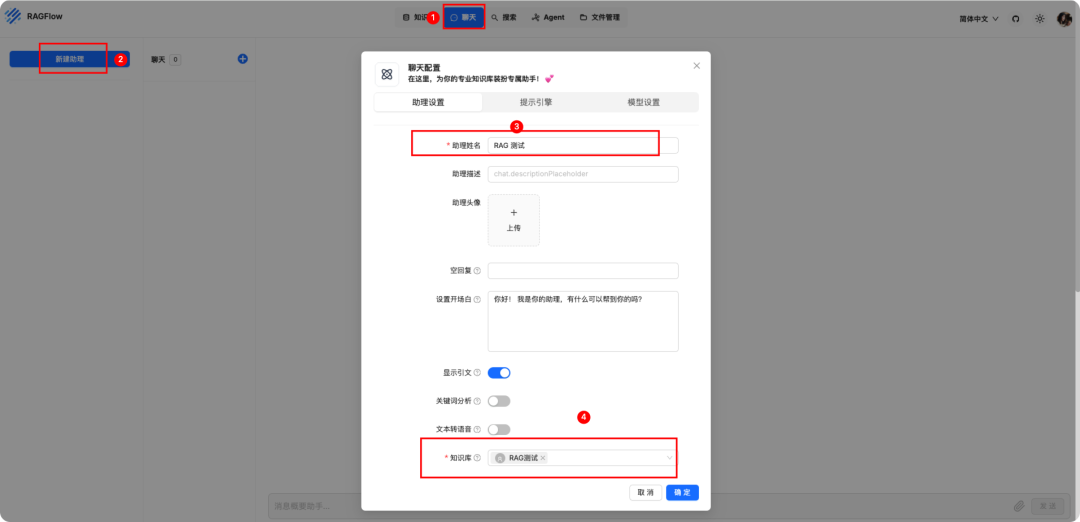
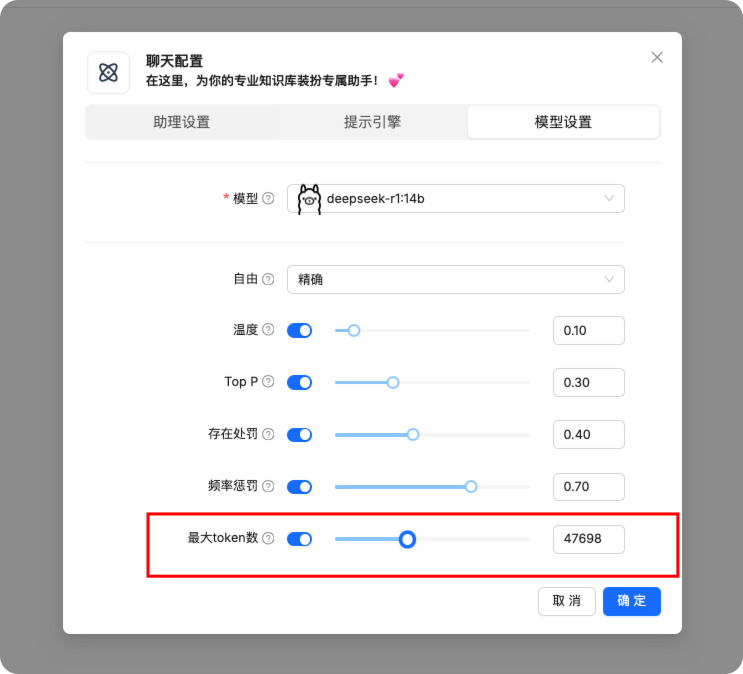
设置模型。token 调整大一些
验证效果
问题一:直接发送 ABCD
知识库回答
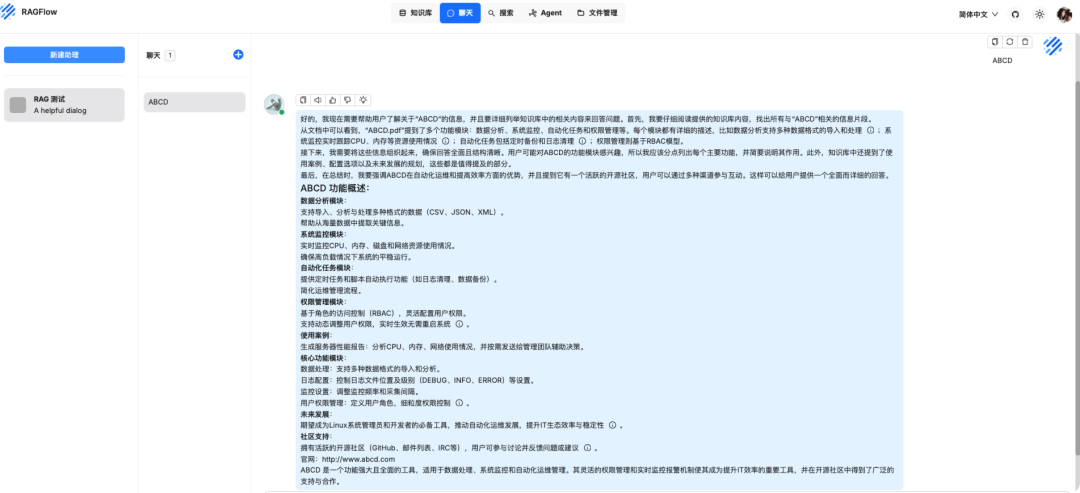
原文档

问题二:ABCD 错误代码有哪些
知识库回答
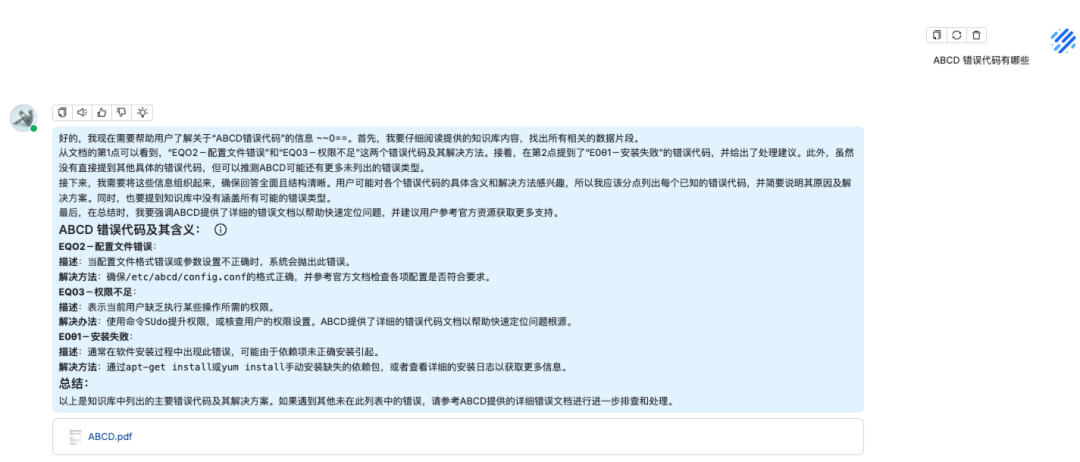
原文档

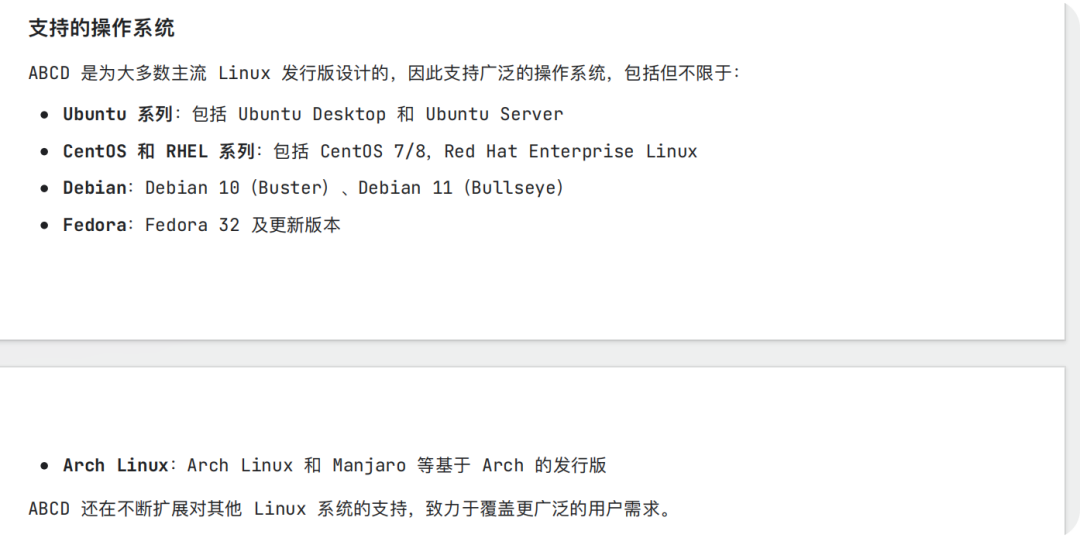
问题三:ABCD 支持哪些系统
知识库回答
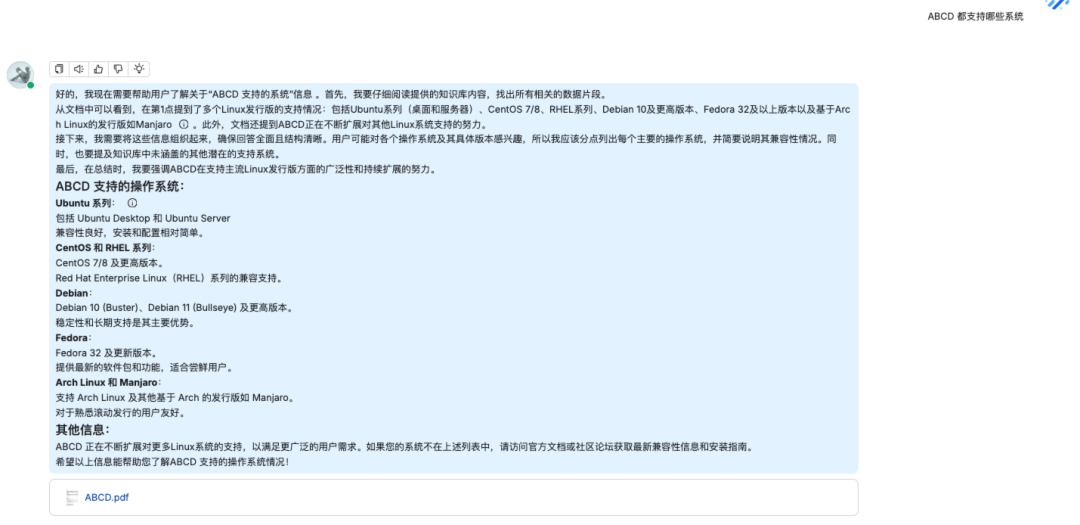
原文档
问题四:ABCD 官网
知识库回答
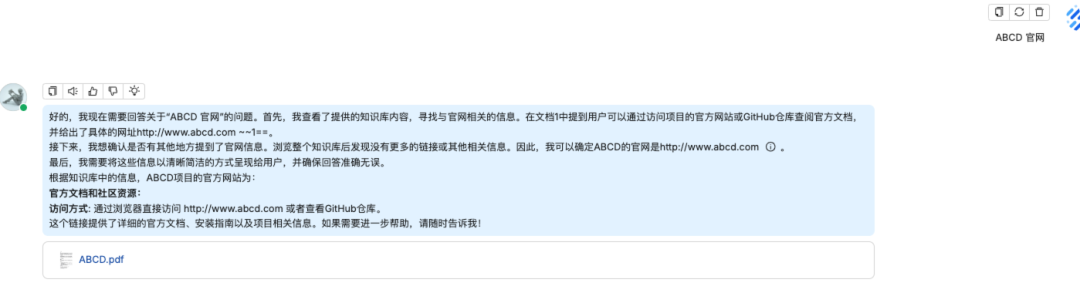
你也可以在回答的结果看到他引用的知识库
原文档

总结
本文介绍了 RAGFlow 的基础使用方法,从演示效果来看尚可。然而,在实际应用场景中,各类文件格式与结构各不相同,文件解析成为一大难题。一旦解析不准确,即便使用性能强劲的 Deepseek-R1 大模型(经亲测),也会出现分析错误的情况。因此,在 RAG 过程中,文件解析、Embedding 以及 LLM 是提升准确率的三大关键攻克点。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 3516
3516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









