






在深度学习领域,检索增强生成(RAG)技术正崭露头角。它通过将大语言模型(LLM)与外部知识库相连,显著提升了LLM的性能,在降低成本、优化特定领域知识应用、保障数据安全等方面优势尽显。
添加查询重写步骤
查询堪称整个RAG流程的核心,它为后续信息检索指明方向。若查询表述不清或未经优化,即便再强大的系统也难以输出精准、有价值的结果。因此,优化查询是获取理想结果的关键所在。为实现这一目标,人们运用了多种技术,全力确保终端用户能获得最佳且最相关的信息,让RAG系统更加高效、可靠。
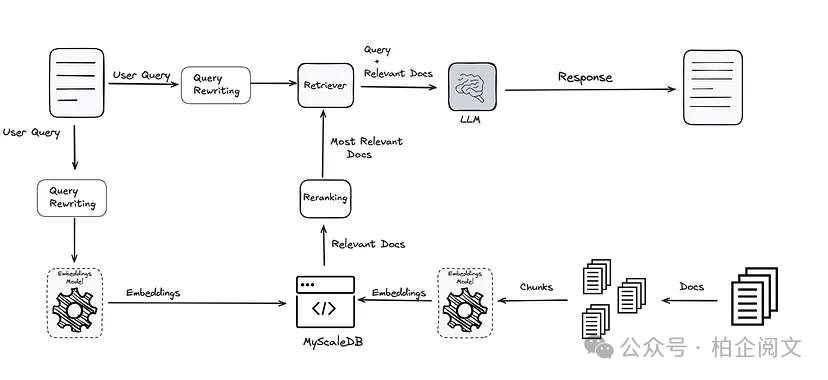
查询改写
通常情况下,用户输入的查询语句很难直接契合LLM的理解模式,并且往往存在很大的优化空间。LLM和其他检索系统对特定词汇较为敏感,改写查询语句有助于优化理解效果。
举例来说,[2]中给出这样一个原始查询:“A car - manufacturing factory is considering a new site for its next plant. Which of the following would community planners be most concerned with before allowing the plant to be built?” 这个查询过于复杂,LLM难以精准理解,也就无法给出答案。而经过重写器处理后,新的查询变为:“What would community planners be most concerned with before allowing a car - manufacturing factory to be built?” 如此一来,系统不仅能够顺利理解,还能返回正确答案。
查询改写的方法丰富多样,比如用同义词替换、添加元数据、优化语法,甚至还有将查询扩展为更具意义的形式,或者生成原始查询的排列组合等。有意思的是,部分改写方法还会借助LLM自身的能力,这就形成了一种递归应用,用LLM来优化输入到另一个(或同一个)LLM的内容。
查询规范化
查询规范化主要用于修正原始查询中的语法和拼写错误等问题,像将字母统一小写、去除停用词这类预处理操作,也属于查询规范化的范畴。例如,“Who was the author of Brothers Karamazov?” 显然比 “who wrote broter karamov” 更容易理解,后者存在明显的拼写错误。
不过,需要注意的是,LLM作为强大的Transformer模型,即便查询规范化程度不高,通常也能理解句子含义。所以,在进行查询规范化时,要把握好尺度,避免过度处理。
查询扩展
多数时候,我们无法预知一个查询的执行效果,此时一种常用策略是创建查询的多个变体,并获取所有变体的结果。除了经典的释义方法外,LLM在这方面也表现出色。
下面以LangChain和OpenAI的GPT - 4模型为例(案例最初源自LangChain):
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class ParaphrasedQuery(BaseModel):
"""You have performed query expansion to generate a paraphrasing of a question."""
paraphrased_query: str = Field(
...,
description="A unique paraphrasing of the original question."
)
system = """You are an expert at converting user questions into database queries.
You have access to a database of tutorial videos about a software library for building LLM - powered applications.
Perform query expansion. If there are multiple common ways of phrasing a user question
or common synonyms for key words in the question, make sure to return multiple versions
of the query with the different phrasings.
If there are acronyms or words you are not familiar with, do not try to rephrase them.
Return at least 3 versions of the question."""
prompt = ChatPromptTemplate.from_messages(
("system", system),
("human", "{question}")
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.25)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
构建好查询扩展器后,就可以投入使用了。从其输出结果可以看到,它提供了丰富的查询变体(若有需要,还能进一步增加变体数量),这对LLM处理查询极为有益。
上下文适应
上下文适应旨在依据具体的提问情境调整查询,强化学习(RL)在其中发挥着关键作用,它能借助上下文信息优化查询措辞。有一种方法是利用小型语言模型(LM)作为查询改写器,结合互联网数据等外部资源丰富查询上下文,随后RL组件依据改写后查询在特定情境中的反馈,对其进行微调。[2]和[3]等研究都对这一方法进行了探索,充分验证了其在提升查询相关性和性能方面的有效性。
查询分解
有些查询往往包含两个或更多不同的问题,这让LLM理解起来颇具难度。而且LLM很容易受到不相关上下文的干扰。例如在关于Jessica年龄的经典问题中,如果引入不相关表述,就可能使LLM陷入困惑。

以[4]中的一个低效查询理解案例来说,这个案例凸显了查询分解的必要性。原查询中带下划线的红色语句让问题变得复杂,增加了LLM的理解难度。更好的处理方式是将查询分解,比如:“Jessica is six years older than Claire. In two years, Claire will be 20 years old.” “Twenty years ago, the age of Claire’s father is 3 times of Jessica’s age” “How old is Jessica now?” 甚至,第二个语句可能都可以省略。
不过,查询分解虽然好处不少,像让问题更清晰、助力LLM逐步推理,但也面临一些挑战:
- 过度拆分:拆分过度会削弱上下文联系,导致结果相关性下降。
- 合并结果:聚合子查询结果颇具挑战,尤其是当结果存在矛盾或不完整的情况。
- 查询依赖:部分查询依赖于前面步骤的结果,这就需要进行迭代处理。
- 成本和延迟:将查询拆分会增加检索和计算步骤,进而提升计算成本。
尽管查询分解前景广阔,但鉴于上述挑战,仍有很大的改进空间。如果对是否使用该方法心存疑虑,为节省成本考虑,保守选择更为妥当。
嵌入优化
嵌入通常由BERT、Titan等常见的自然语言处理模型生成,在众多应用场景中表现不俗。但为了实现更优的理解效果,往往还需要对其进行优化。为此,像Massive Text Embedding Benchmark(MTEB)[5]这样的基准测试应运而生,它用于评估嵌入在分类、聚类、摘要等8种不同任务中的性能表现。
MTEB研究发现,“没有一种万能的最优解决方案,不同模型在不同任务中各擅胜场”。确实,没有一个模型能在所有任务中都表现最佳,不同模型在汇总、分类等任务上各有优势。而且,即使是相同的任务,模型在不同数据集上的表现也参差不齐。
假设文档嵌入(HyDE)
2022年,研究人员提出了一种创新的零样本方法——假设文档嵌入(HyDE)[6]。该方法的核心思路是创建一个虚拟文档,然后利用其嵌入在嵌入空间中查找相似的真实文档。
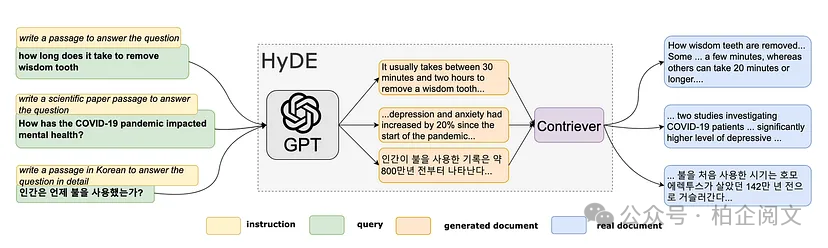 目前,HyDE作为RAG中优化查询的工具,正受到越来越多的关注。其具体流程如下:
目前,HyDE作为RAG中优化查询的工具,正受到越来越多的关注。其具体流程如下:
- 生成假设文档:以查询为基础,生成一个假设文档。操作很简单,比如提示LLM “Make a document which answers this question” 即可,后面会通过示例详细说明。
- 计算其嵌入:可以选用任何模型或服务来计算嵌入,MyScale就提供了EmbedText()方法。获取假设查询的嵌入后,就能用于查询向量数据库。
- 使用嵌入查询向量数据库:从假设查询中找到最相似的文本,再将其与原始查询一同输入LLM,生成最终响应。
假设文档创建
第一步是依据查询生成假设文档。我们可以借助OpenAI的GPT - 4(mini)模型来完成(对于大多数任务,GPT4 - mini性能足够且成本较低),具体代码如下:
from openai import OpenAI
openai_client = OpenAI(api_key='sk-xxxxx')
def Make_HyDoc(query):
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": "Make a document that answers the question:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
# 现在有了这个函数,就能基于查询生成假设文档
嵌入计算
这里我们使用MyScale的内置函数EmbedText()直接计算嵌入:
service_provider = 'OpenAI'
hypoDoc = Make_HyDoc("What was the solution proposed to farmers problem by Levin?")
parameters = {'sampleString': hypoDoc,'serviceProvider': service_provider}
x = client.query("""
SELECT EmbedText({sampleString:String}, {serviceProvider:String}, '', 'sk-*****', '{"model":"text-embedding-3-small", "batch_size":"50"}')
""", parameters=parameters)
input_embedding = x.result_rows[0][0]
使用嵌入查询向量数据库
得到嵌入结果 input_embedding 后,就可以通过简单的SQL查询,将其与存储在表(这里是DocEmbeddings表)中的向量进行比较:
SELECT
id,
title,
content,
cosineDistance(embedding, input_embedding) AS similarity
FROM
DocEmbeddings
ORDER BY
similarity ASC
LIMIT
10;
在Python中执行上述查询,并以数据框形式展示结果:
import pandas as pd
query = f"""
SELECT
id,
sentences,
cosineDistance(embeddings, {input_embedding}) AS similarity
FROM
DocEmbeddings
LIMIT
10
"""
df = pd.DataFrame(client.query(query).result_rows)
最终就能得到最相关的文档。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









