






- 最近想弄一个自己的菜谱GPT,记录下自己的美食配方,要不这些配方在手机备忘录中比较杂乱,然后就找了些教程整合了一下才弄出来,期间遇到一些报错弄了会才解决掉,为了方便大家以后少走弯路,就写了这篇文章。希望每个人都能拥有自己的智能“备忘录”。
- 想体验下本地GPT的小白朋友也可以玩玩(本教程在国内的环境也可以搭建,文章中有🪄的是需要魔法的,不过我也放上了平替)
- 操作系统: -Windows 11 23H2 -GPU : 1060 6G
一、开启WSL
- 程序和功能——启用或者关闭windows功能——(适用于Linux的windows子系统、虚拟机平台)
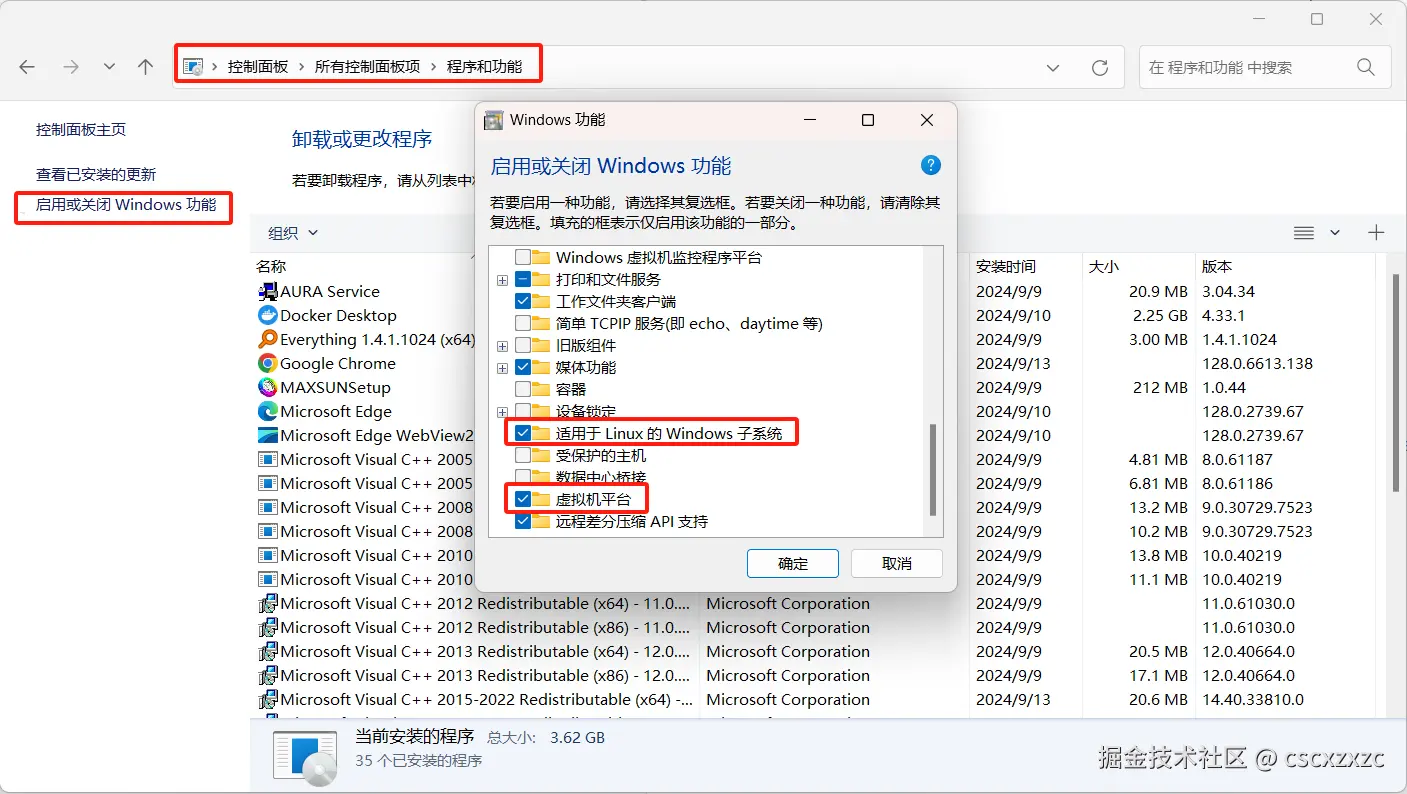
- 设置wsl
以管理员身份打开cmd
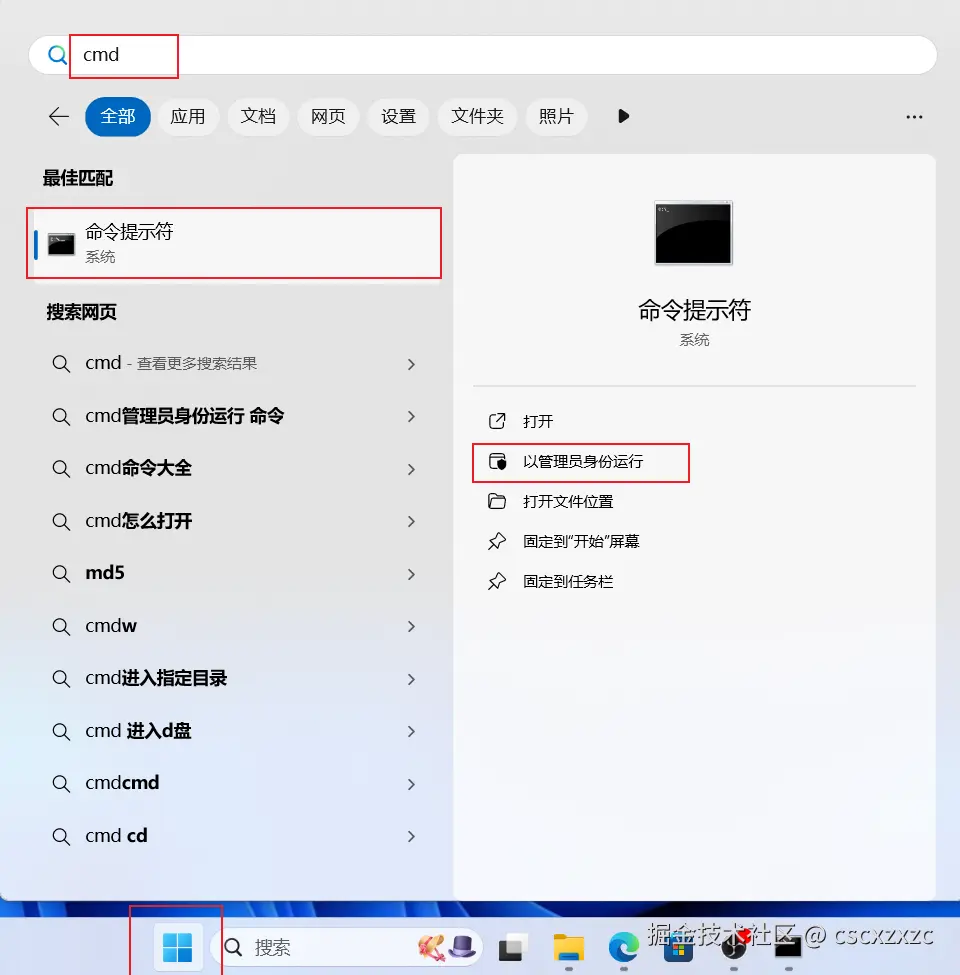
wsl --set-default-version 2
wsl --update --web-download
二、Ubuntu 下载
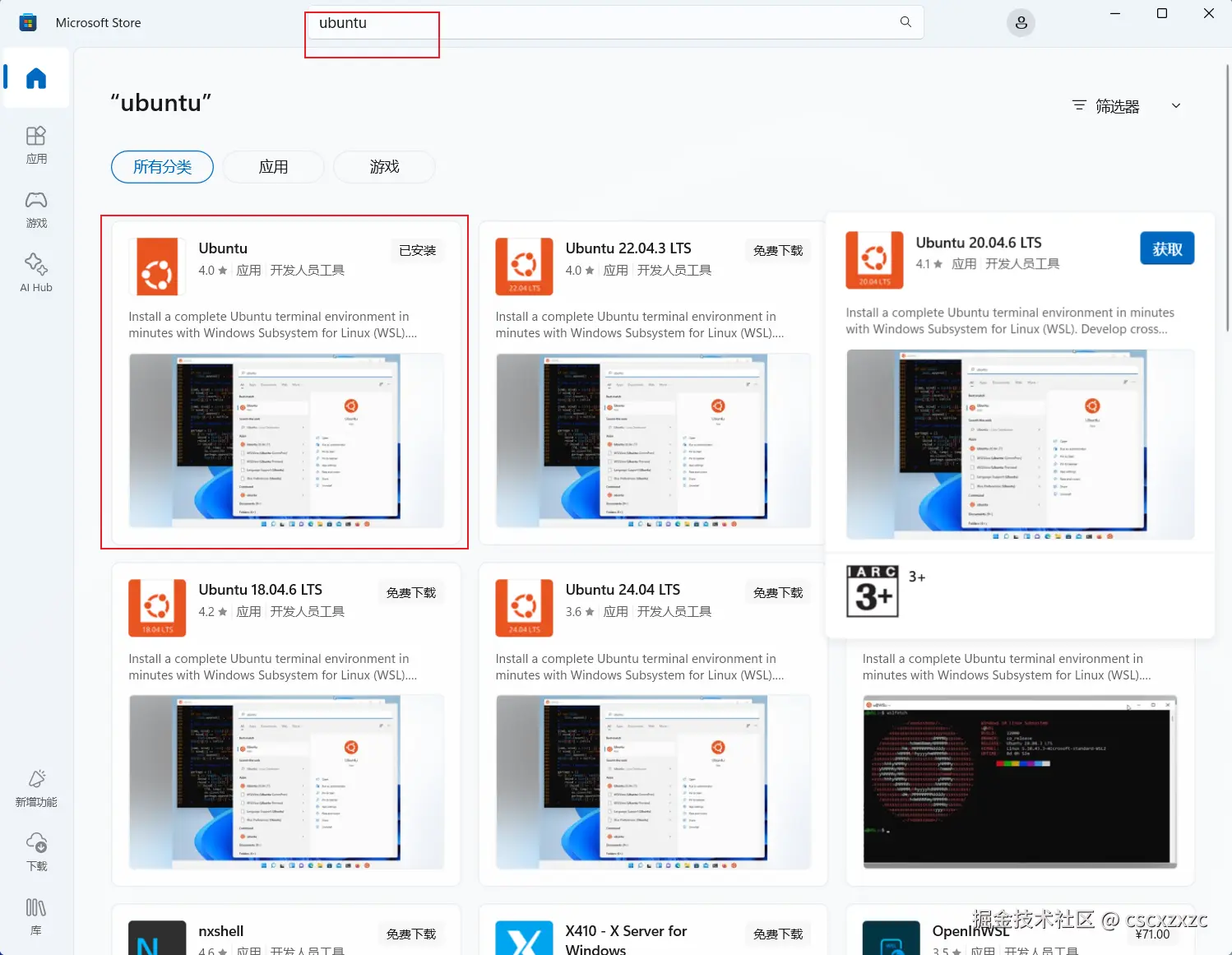
方法一:Microsoft Store 微软商店
下载Ubuntu
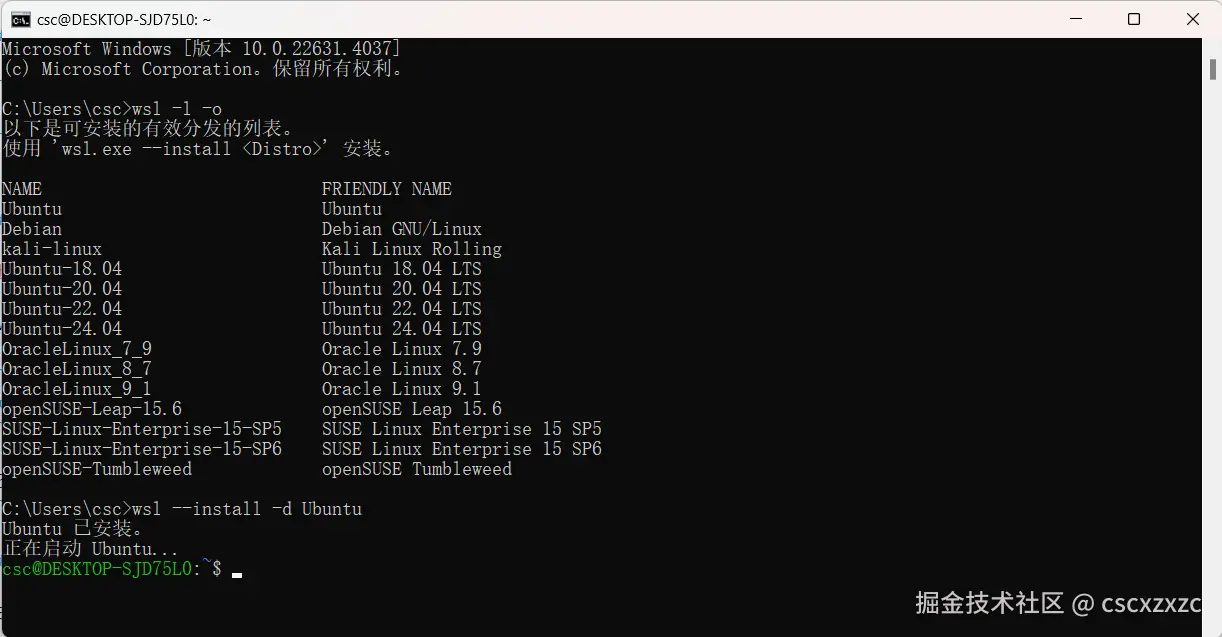
方法二🪄:命令行
wsl -l -o
wsl --install -d Ubuntu
三、docker下载:
1. 下载Docker桌面版
官网🪄:www.docker.com
GitHub:github.com/tech-shrimp…
ps:可在Microsoft Store 微软商店 下载watt加速GitHub
2. 安装Docker
Docker桌面版默认安装在C盘
下载Docker桌面版(安装到其他盘的命令):
start /w "" "Docker Desktop Installer.exe" install --installation-dir=D:\Docker
3. 查找Docker镜像:
官网🪄:hub.docker.com/
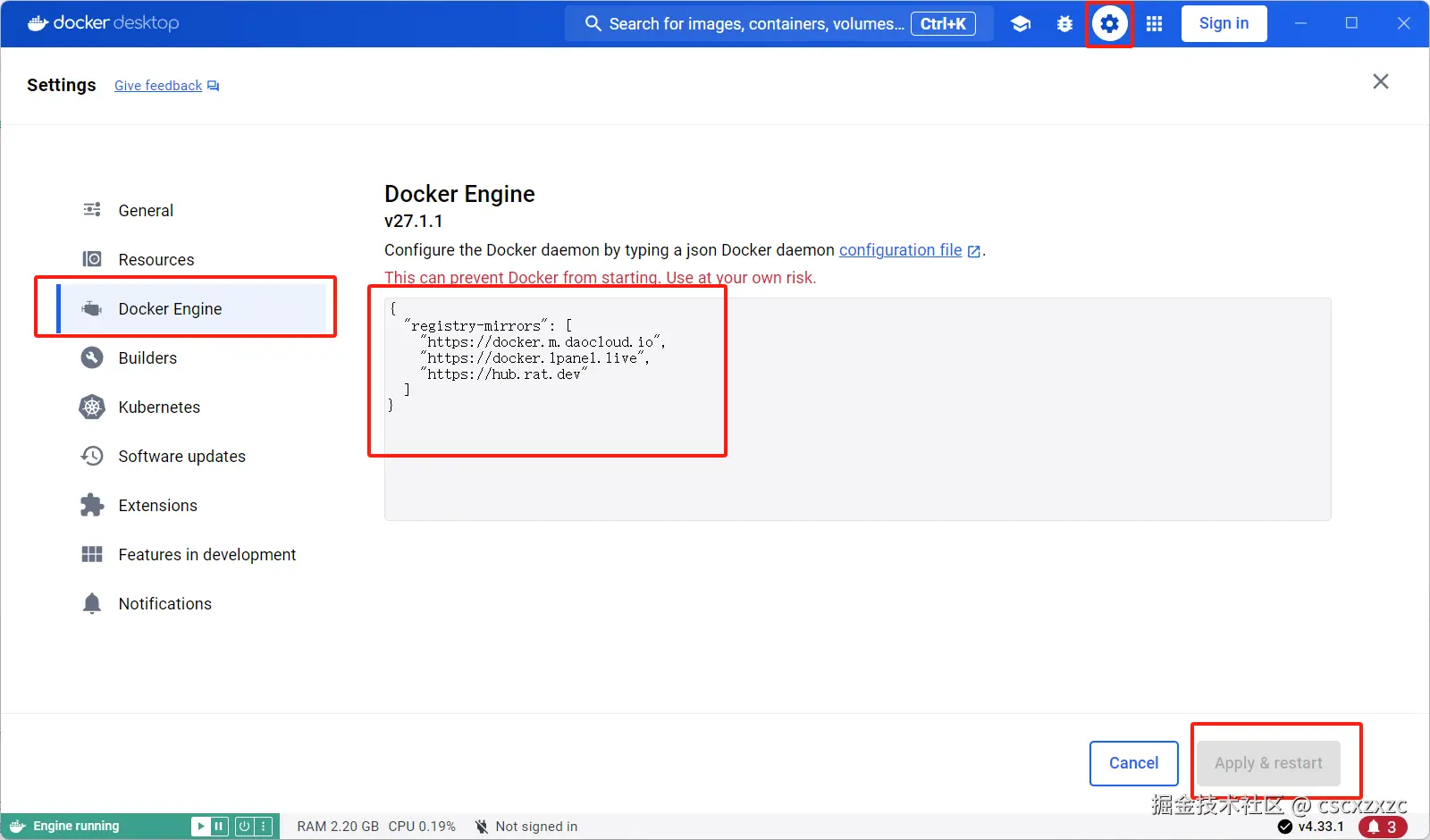
4. 修改Docker镜像源:
Settings -> Docker Engine
json代码解读复制代码{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://hub.rat.dev"
]
}
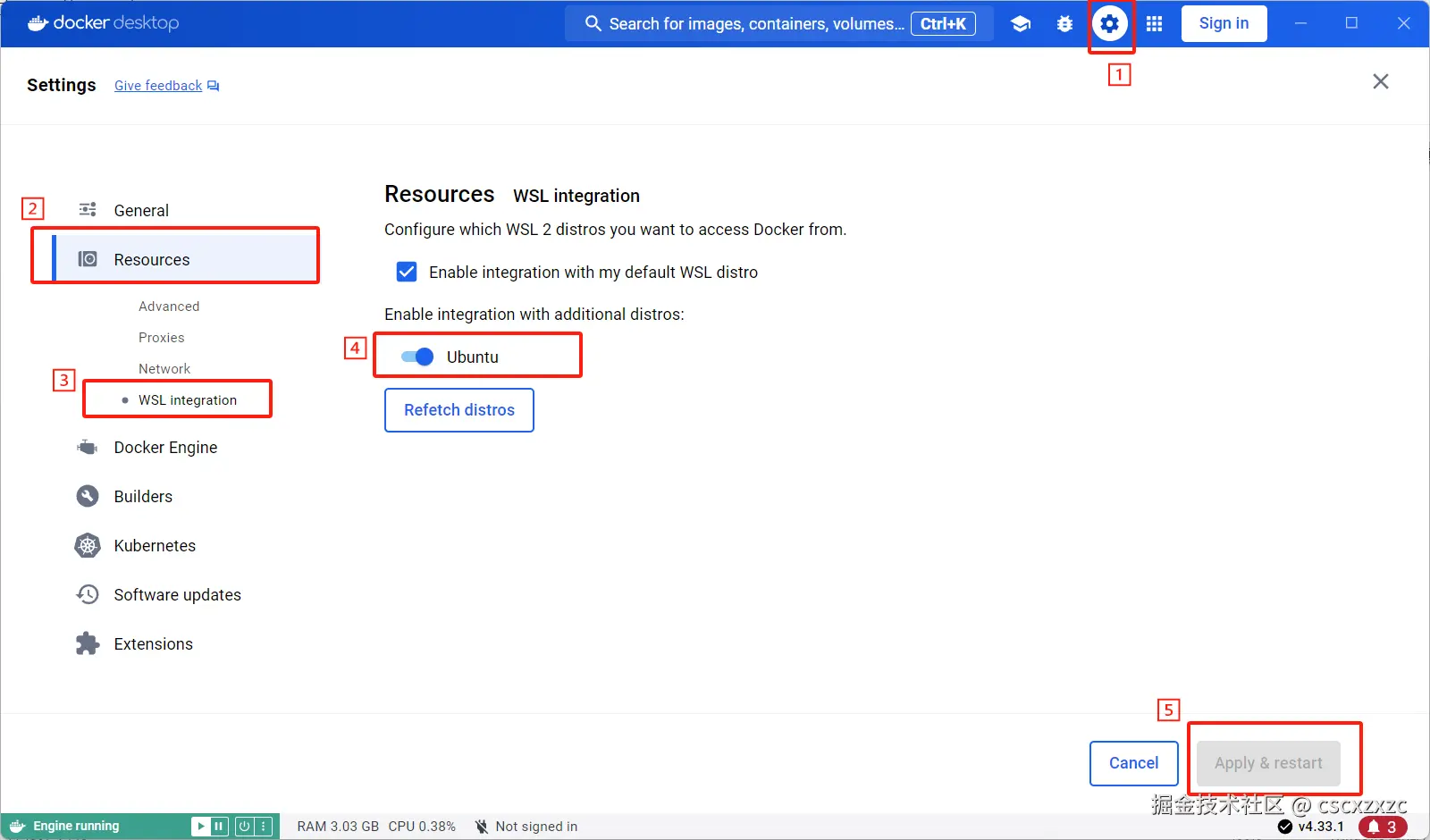
5. 开启WSL integration
Settings -> Resources -> WSL integration
四、docker-compose下载(桌面版不用下载):
GitHub:github.com/docker/comp…
Linux中下载安装docker-compose
wsl中下载安装命令:
sudo curl -L "https://github.com/docker/compose/releases/download/v2.29.3/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
查看安装版本命令: docker-compose –version
五、Fastgpt下载
技术文档:doc.tryfastgpt.ai/docs/develo…
0. 修改本机hosts文件
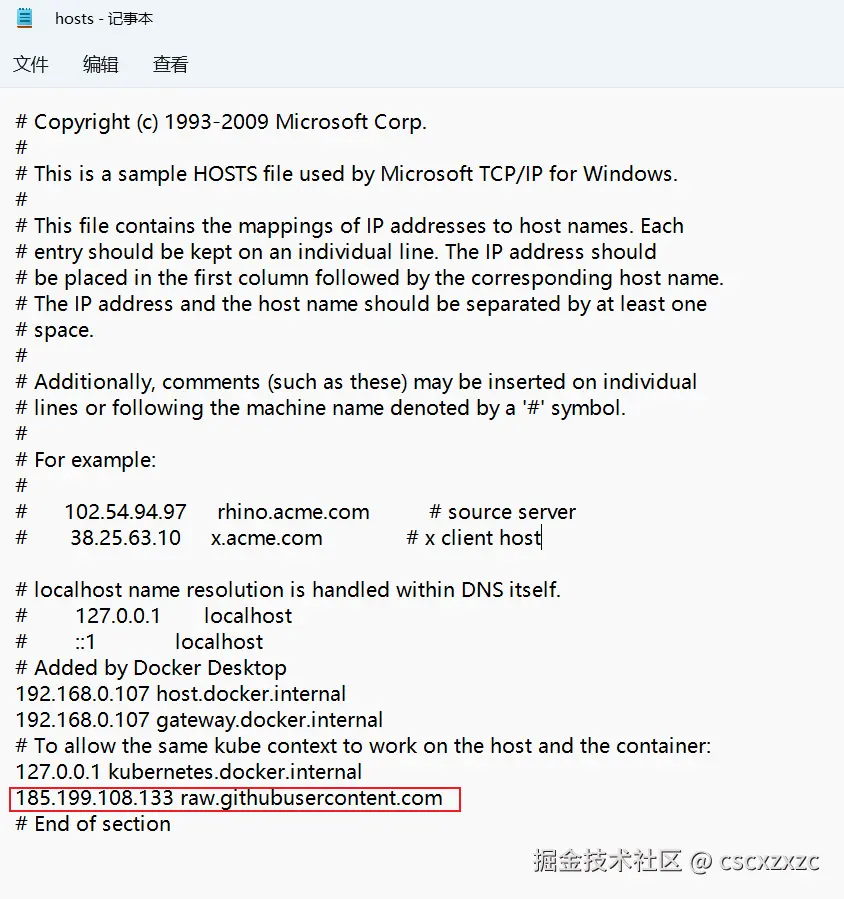

路径:C:\Windows\System32\drivers\etc
保存不了的另外存在桌面后再覆盖掉原来的文件
查询网站:www.ipaddress.com/
末尾添加 185.199.108.133 raw.githubusercontent.com
【否则后面的操作会导致下面的报错】

1. 安装命令:
ruby代码解读复制代码 mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
2. 启动容器
bash代码解读复制代码# 启动容器
docker-compose up -d
# 等待10s,OneAPI第一次总是要重启几次才能连上Mysql
sleep 10
# 重启一次oneapi(由于OneAPI的默认Key有点问题,不重启的话会提示找不到渠道,临时手动重启一次解决,等待作者修复)
docker restart oneapi
六、ChatGLM3下载
技术文档:zhipu-ai.feishu.cn/wiki/HIj5wV…
懒人包下载:
ruby代码解读复制代码以下懒人包和教程由 非官方开发者 十字鱼 友情提供
视频教程:https://www.bilibili.com/video/BV1c34y1w75K
百度网盘链接:https://pan.baidu.com/s/1fHElFanrdK9Y-pTpeY_azg
提取码:glut
七、M3E下载
1. Docker镜像拉取
原镜像:docker pull stawky/m3e-large-api:latest
我的阿里云:docker pull crpi-lttoy839cc8pgssa.cn-heyuan.personal.cr.aliyuncs.com/cscai/m3e-large-api
2. 运行容器
bash代码解读复制代码docker images
# 重命名镜像
docker tag crpi-lttoy839cc8pgssa.cn-heyuan.personal.cr.aliyuncs.com/cscai/m3e-large-api:latest stawky/m3e-large-api:latest
# 删除命名长的镜像
docker rmi crpi-lttoy839cc8pgssa.cn-heyuan.personal.cr.aliyuncs.com/cscai/m3e-large-api:latest
#查看网络
docker network ls
# GPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --gpus all --name m3e --network fastgpt_fastgpt stawky/m3e-large-api
# CPU模式启动,并把m3e加载到fastgpt同一个网络
docker run -d -p 6008:6008 --name m3e --network fastgpt_fastgpt stawky/m3e-large-api
#【记住这起的名字】
八、配置
1. oneapi配置
1.1 登录
oneapi登录账号:root 默认密码:123456
1.2 配置ChatGLM3
① 懒人包中启动api

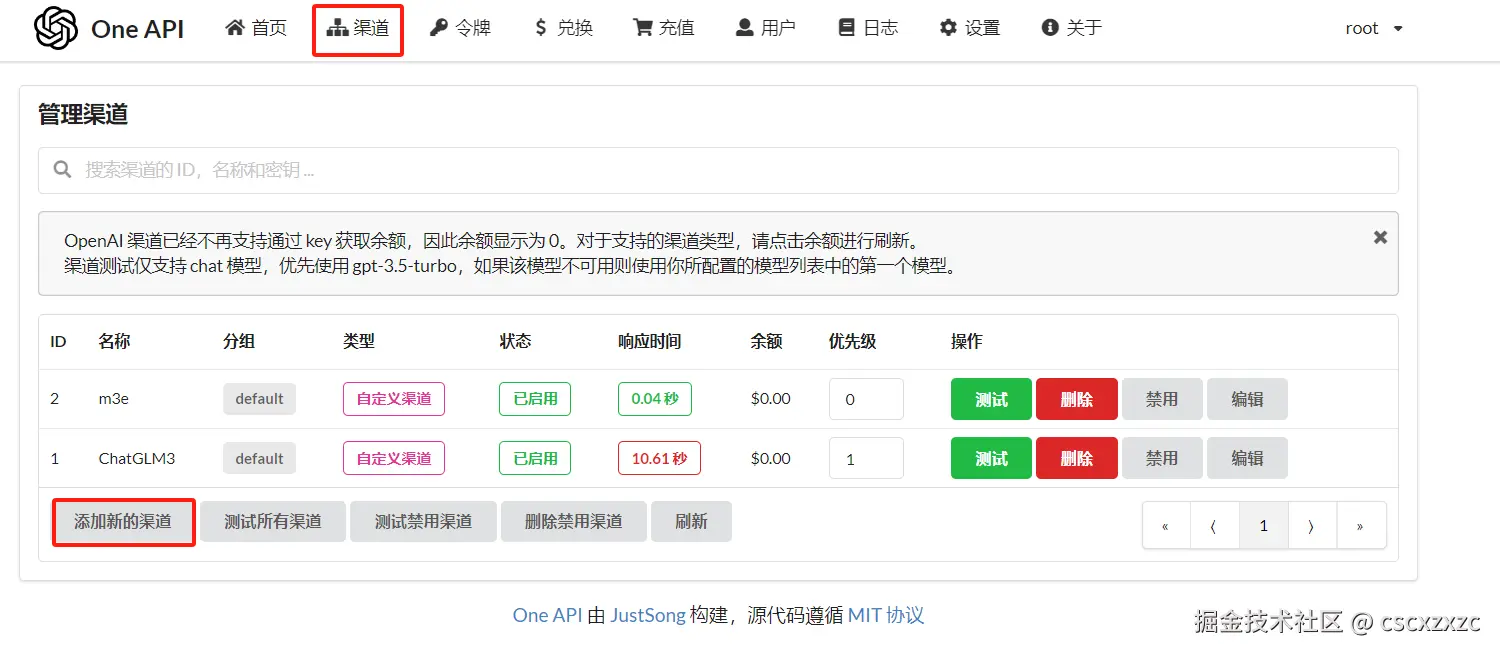
② 进入渠道页面——点击添加新的渠道
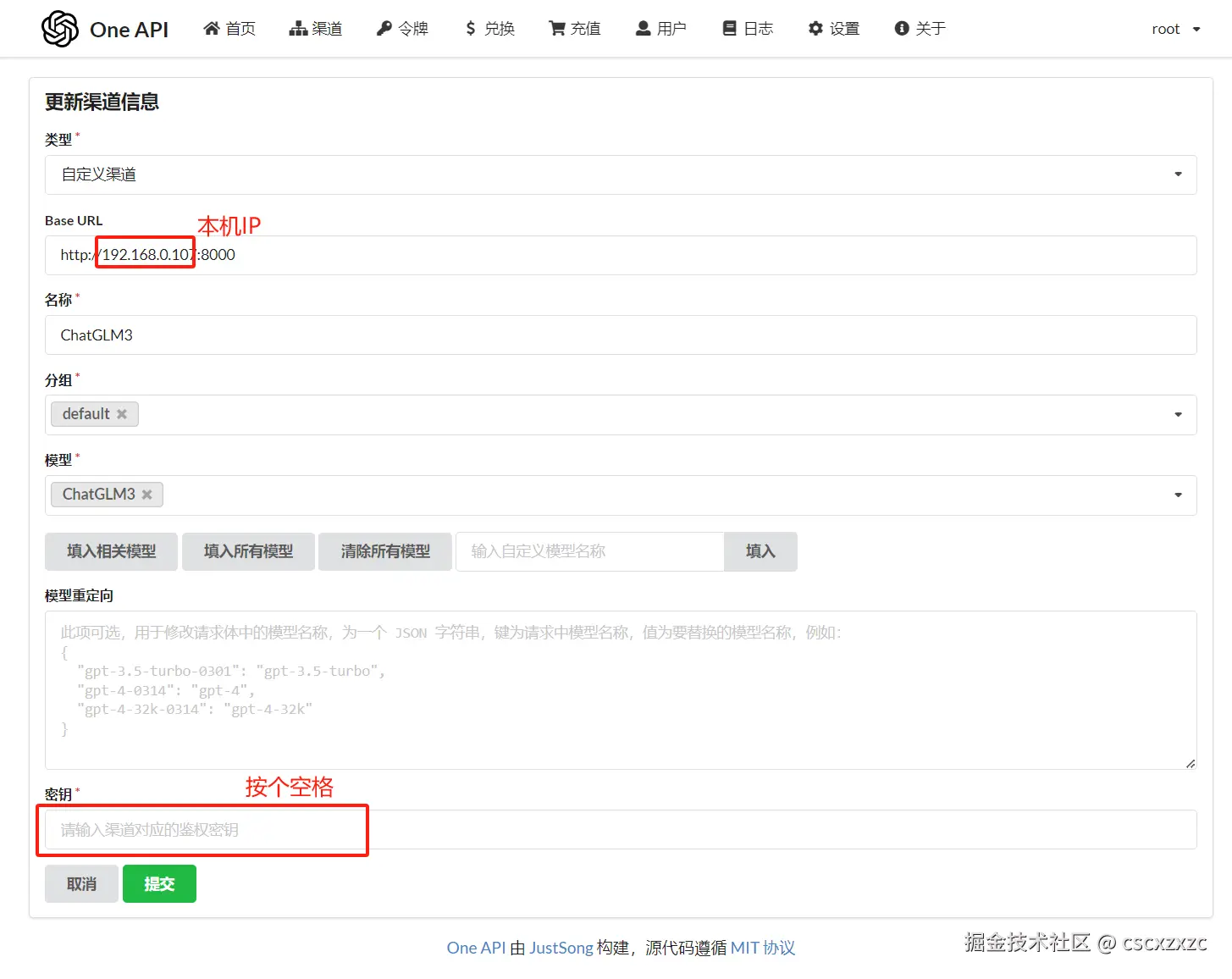
③ 填入渠道信息
bash代码解读复制代码# Base URL(ip替换为本机IP)
http://ip:8000
# 名称
ChatGLM3
# 模型(先点击“清除所有模型”)
ChatGLM3
# 密钥
“空格”
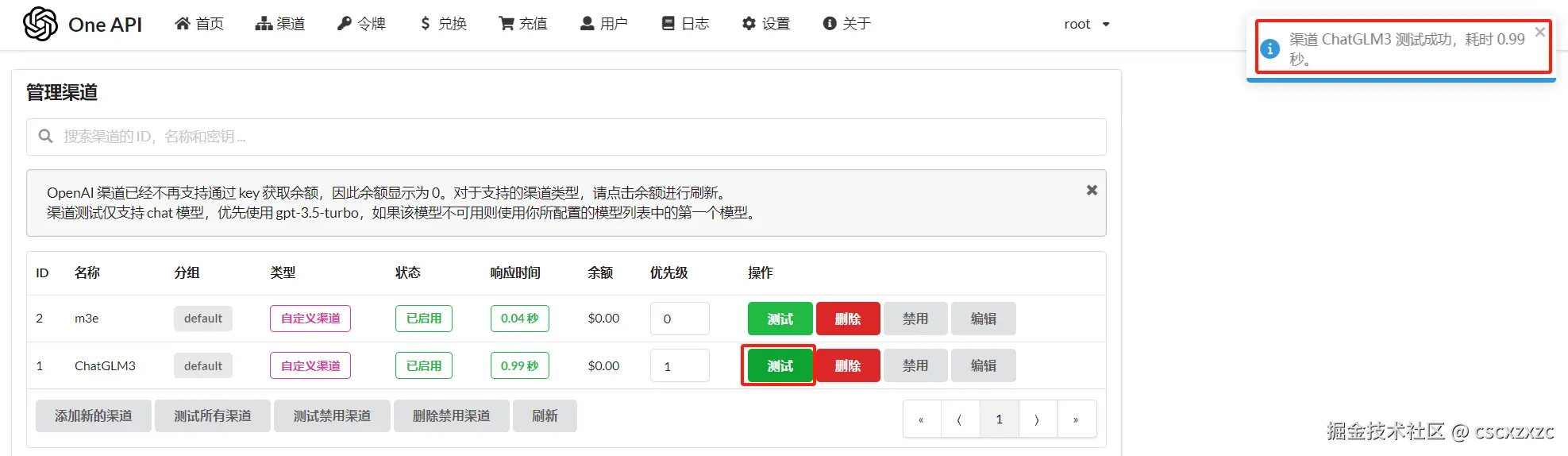
④ 测试
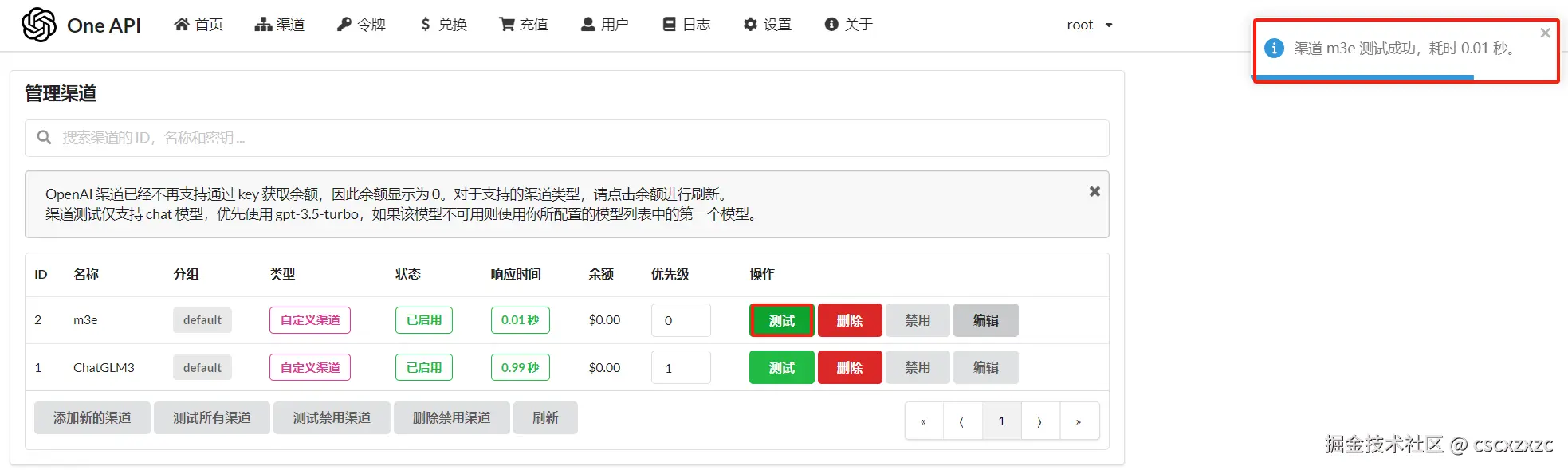
等待ChatGLM3启动成功后点击“测试”,右上角会有测试结果。

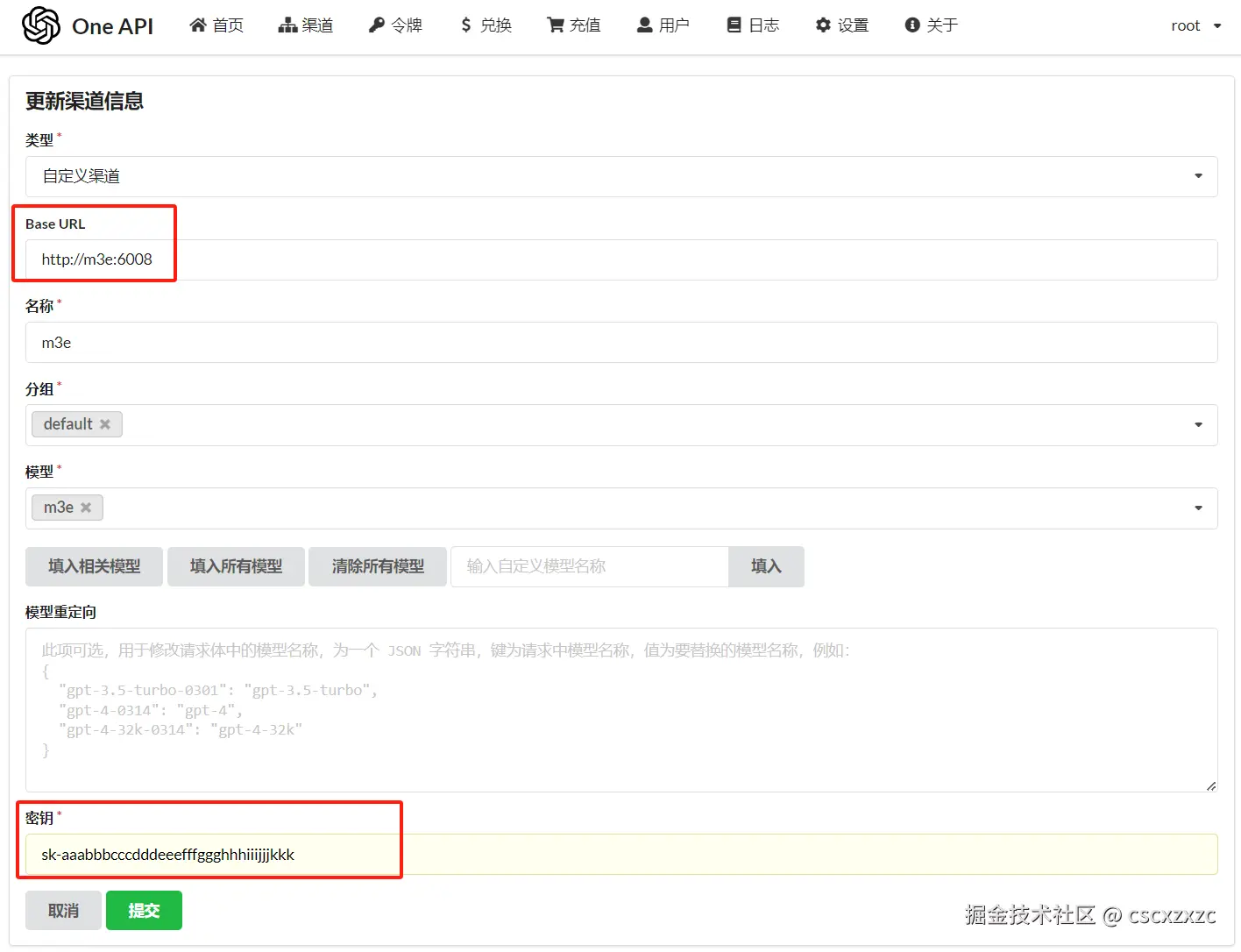
1.3 配置渠道m3e
① 添加新的渠道
bash代码解读复制代码# Base URL(m3e为你上面记住的名字,相当于域名)
http://m3e:6008
# 名称
m3e
# 模型(先点击“清除所有模型”)
m3e
# 密钥
sk-aaabbbcccdddeeefffggghhhiiijjjkkk
④ 测试
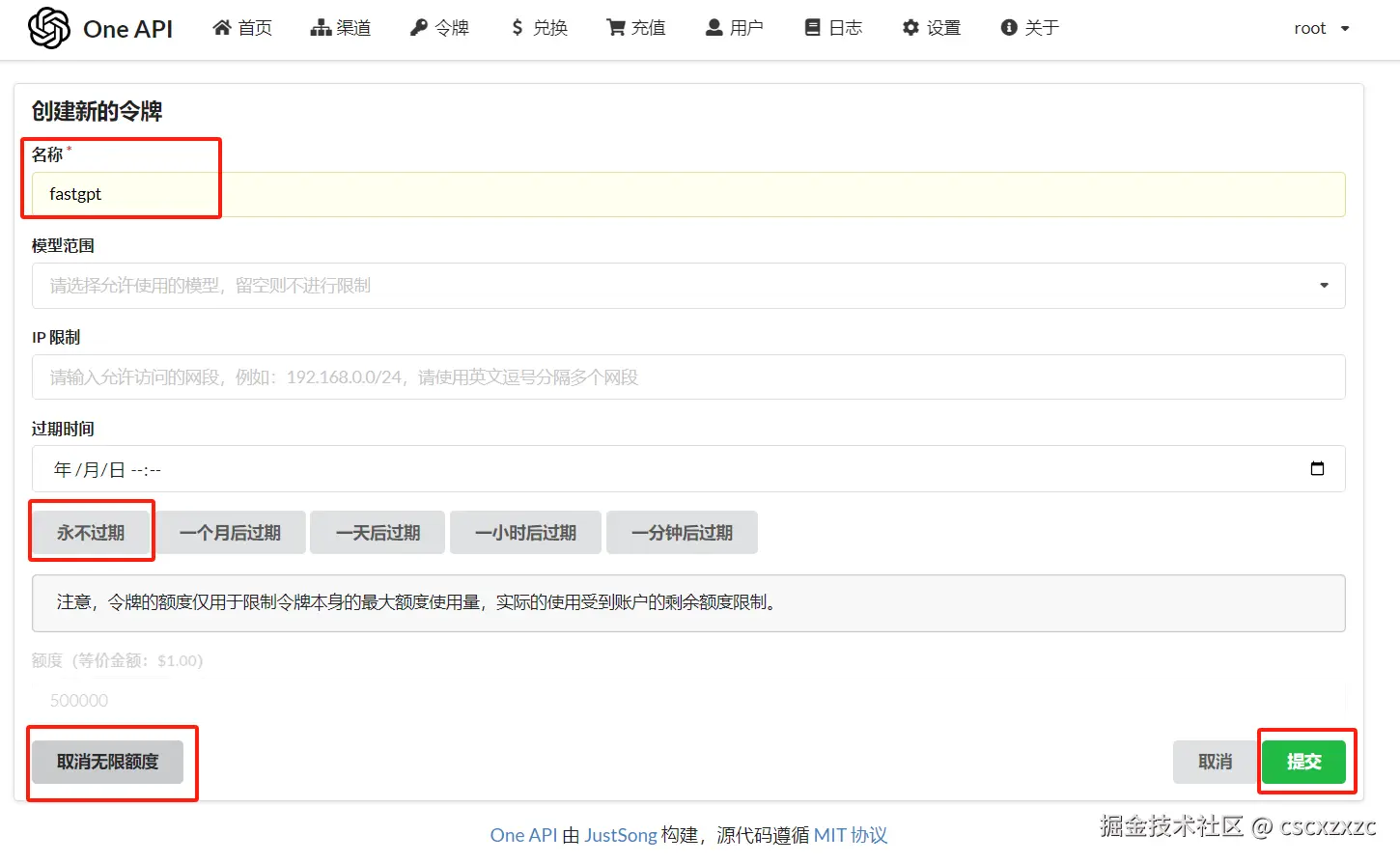
1.4 配置令牌
① 添加新的令牌
名称随便,永不过期,无限额度
② 复制令牌
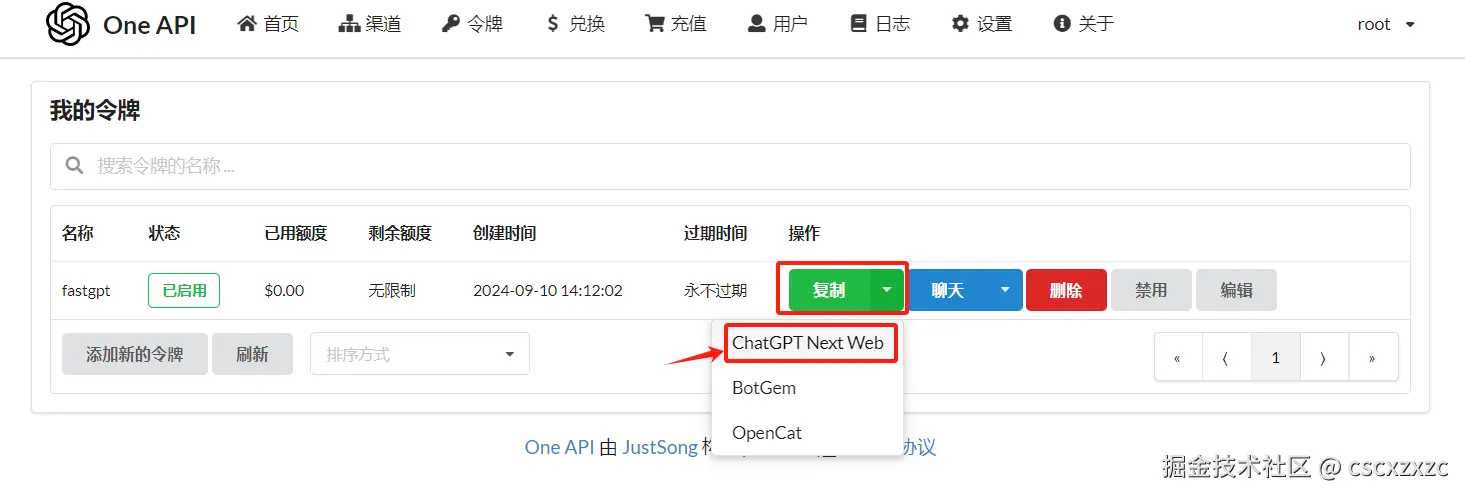
令牌格式:app.nextchat.dev/#/?settings…
复制key部分:sk-TCH2nzGlJvudk446295e8eFb111c453e8a3486E93493CeE6
2. 修改docker-compose.yml
位置: \wsl.localhost\Ubuntu\home\csc\fastgpt
2.1 修改CHAT_API_KEY
ini代码解读复制代码# AI模型的API地址哦。务必加 /v1。这里默认填写了OneApi的访问地址。
- OPENAI_BASE_URL=http://oneapi:3000/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-TCH2nzGlJvudk446295e8eFb111c453e8a3486E93493CeE6
3. 修改config.json
位置: \wsl.localhost\Ubuntu\home\csc\fastgpt
js代码解读复制代码 {
"model": "ChatGLM3", // 模型名(对应OneAPI中渠道的模型名)
"name": "ChatGLM3", // 别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 4000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 2000, // 最大引用内容
"maxTemperature": 1, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": false, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig":{} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
}
{
"model": "m3e", // 模型名(与OneAPI对应)
"name": "m3e", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 500, // 默认文本分割时候的 token
"maxToken": 1800, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig":{}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
}
修改后重启容器:
docker-compose down
docker-compose up -d
九、FastGTP配置与使用
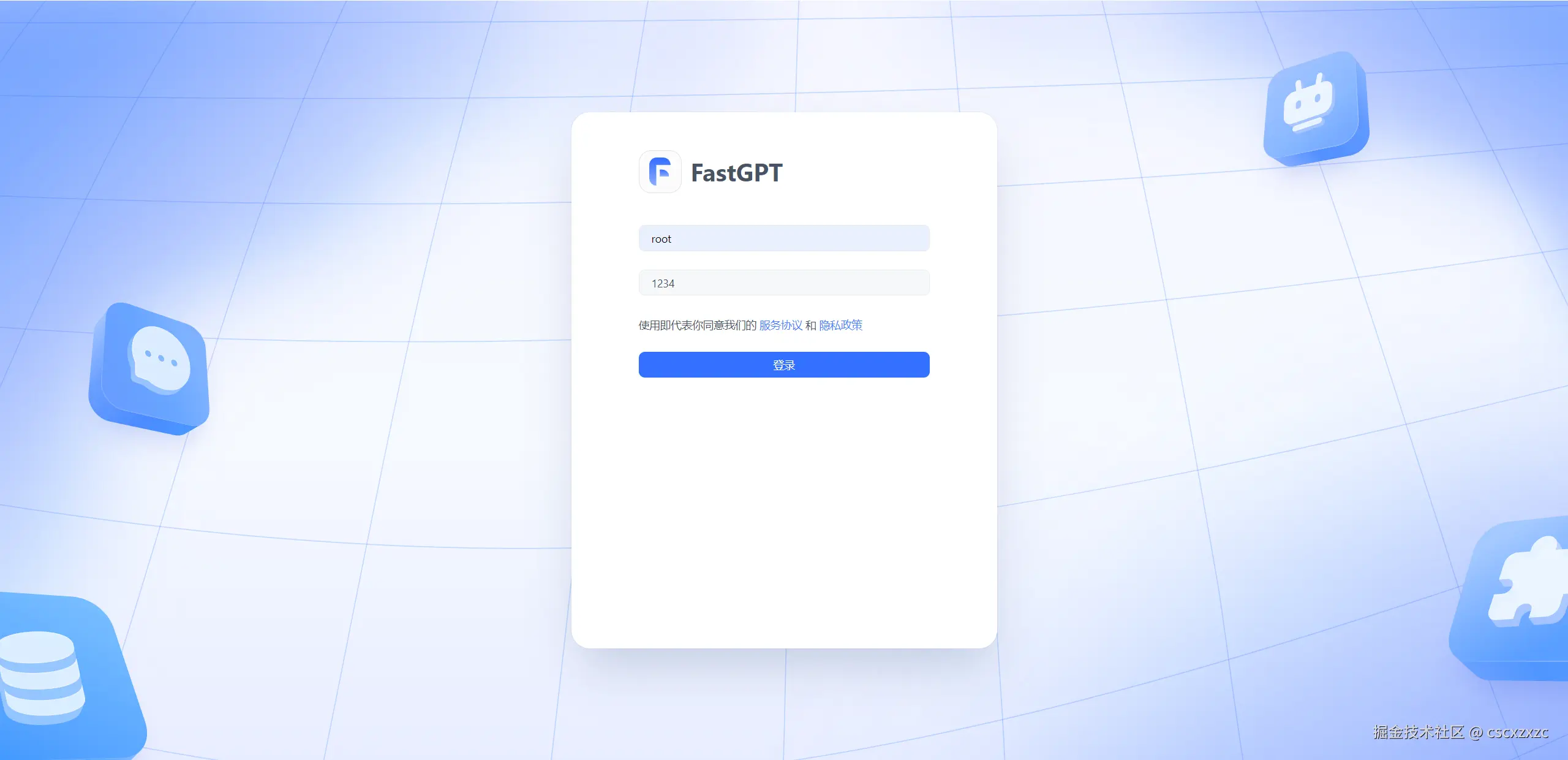
1. 登录
账号:root 密码:1234
2. 添加知识库
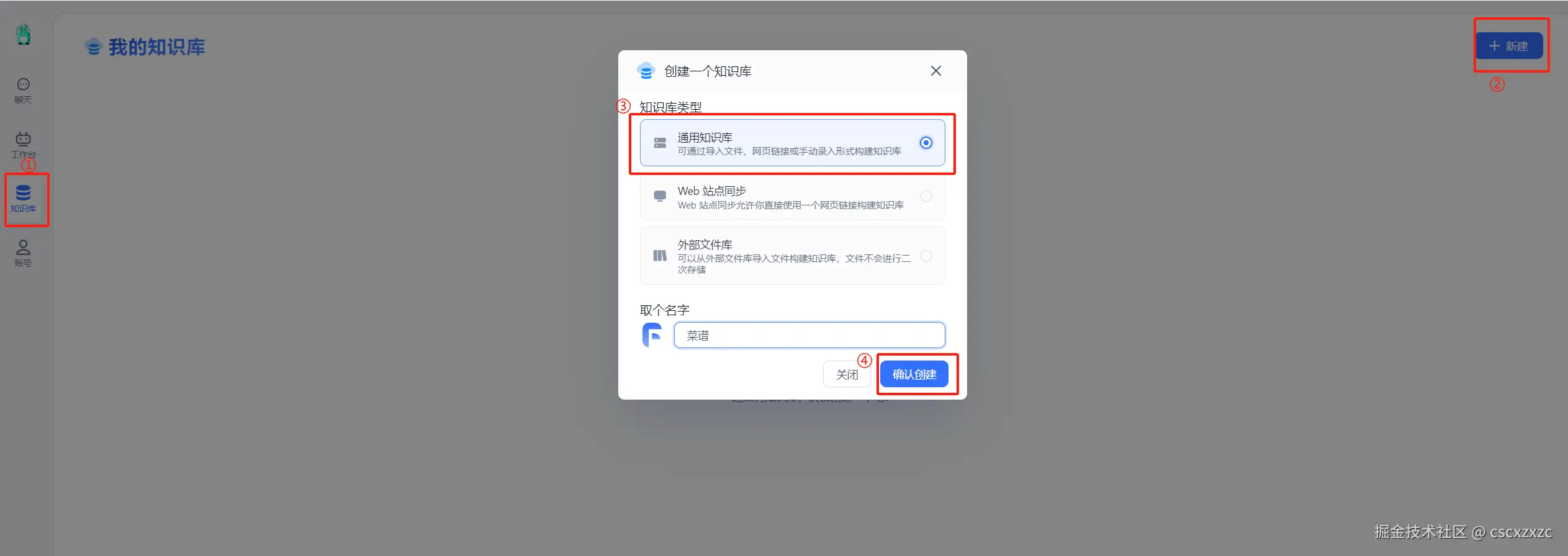
2.1 创建知识库
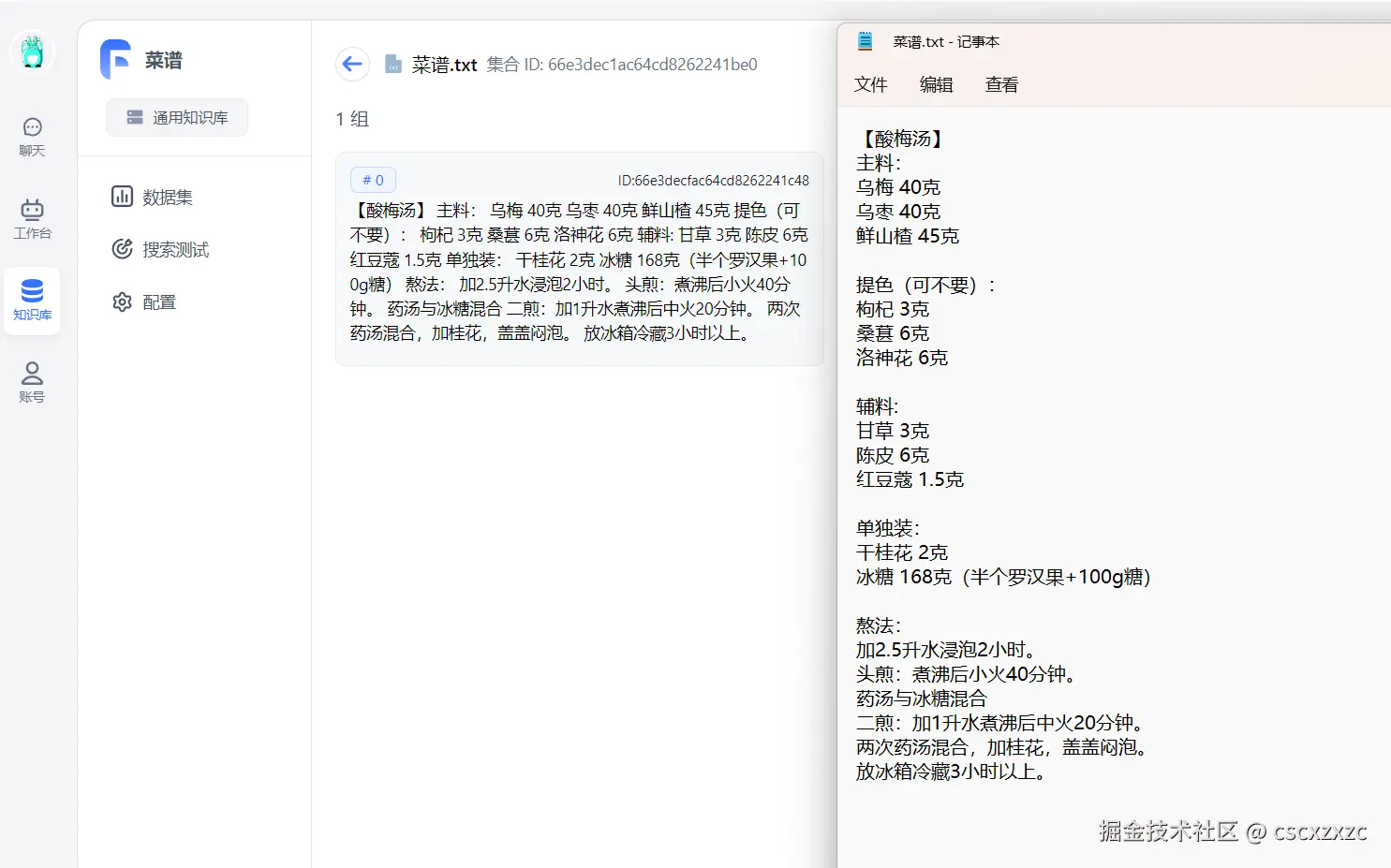
2.2 导入数据集
3. 添加应用
3.1 创建应用
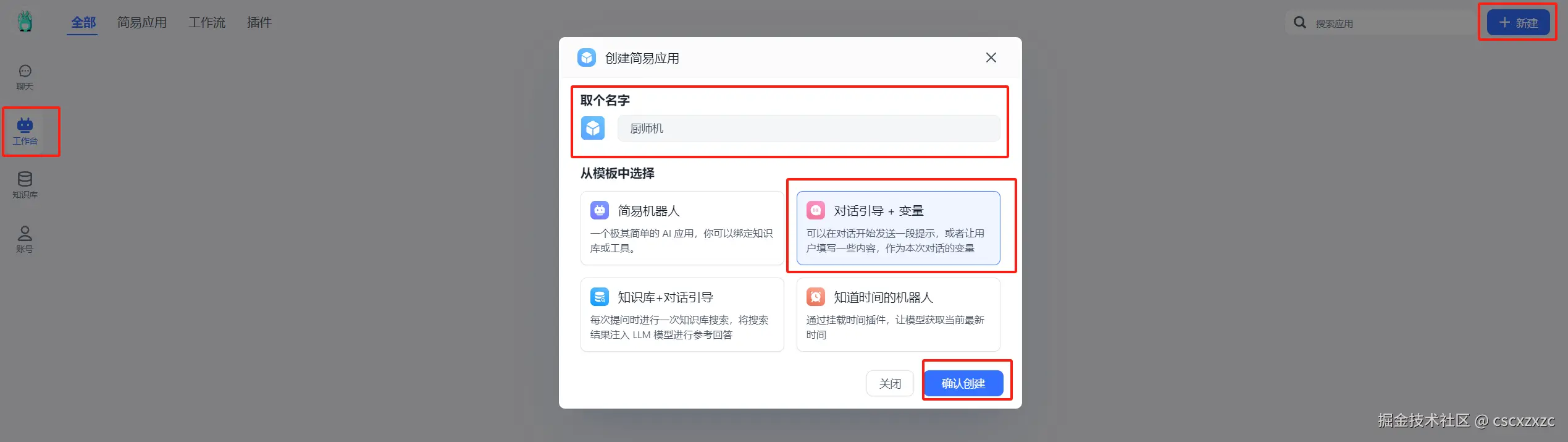
3.2 配置应用与关联知识库
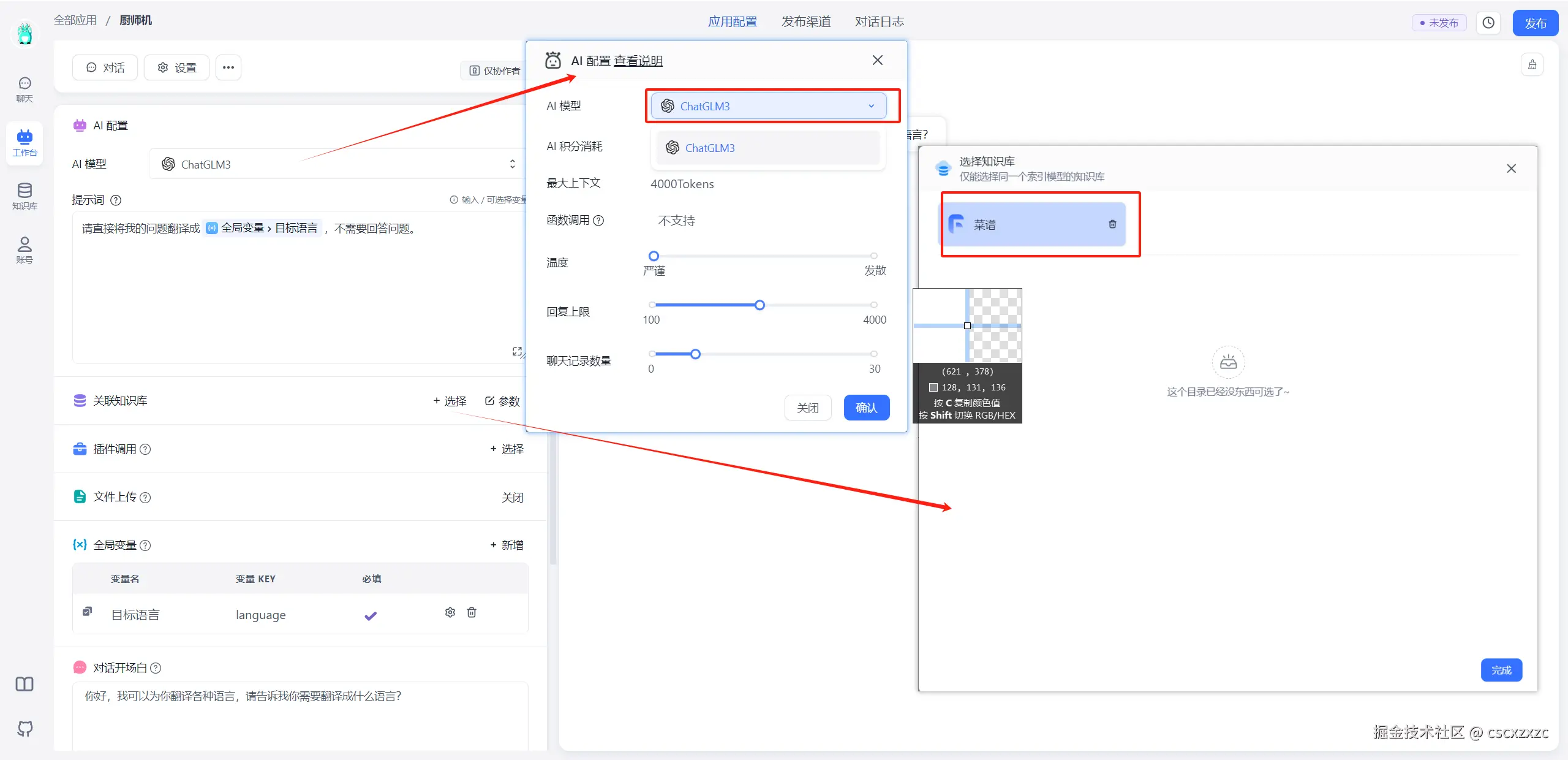
4. 发布与聊天
4.1 未添加知识库的对话
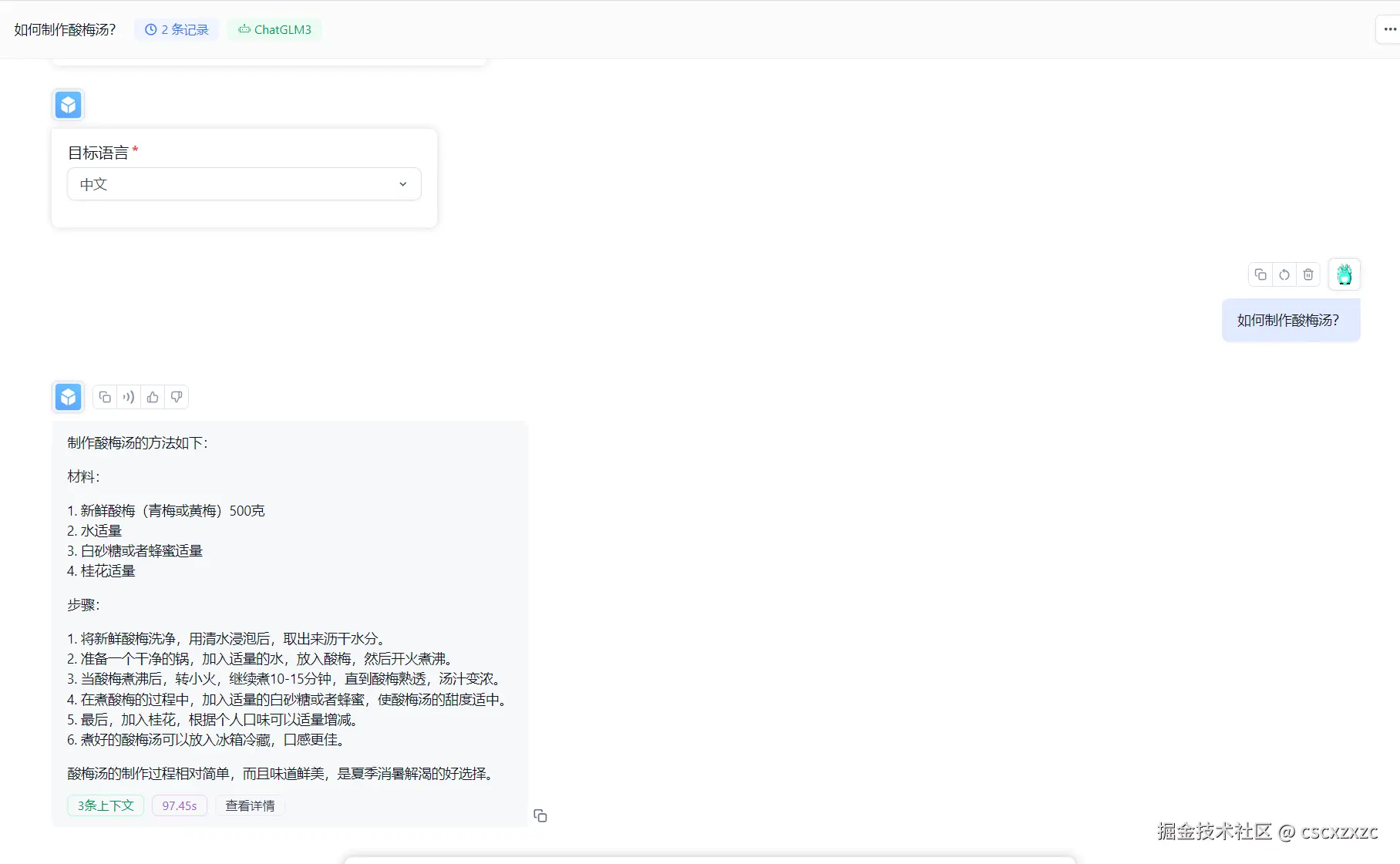
4.2 添加知识库后的对话

4.3 高级玩法
FastGPT运用的是MarkDown,这就可以用MarkDown来让他回复图片等一系列用法。
1.运用MakerDown语法配置知识库
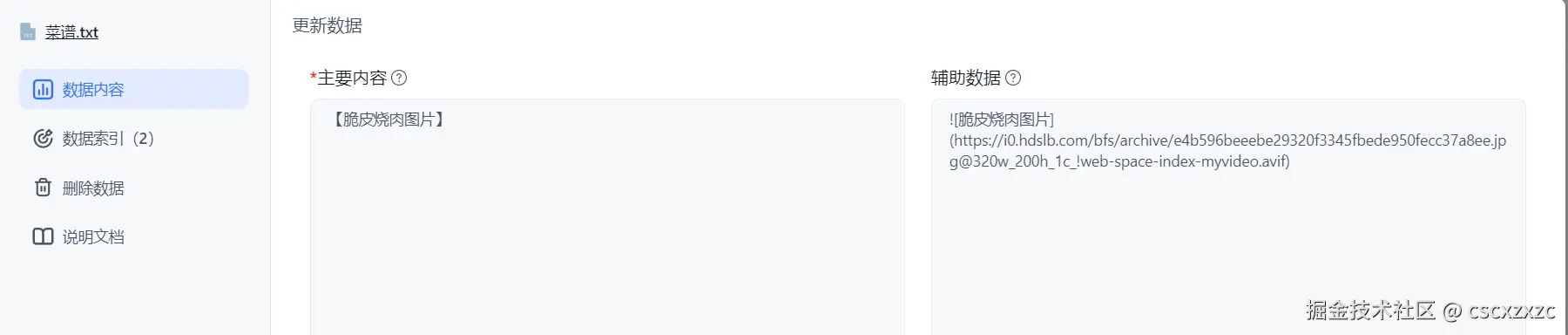
2.回复效果

如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









