







导读
本文侧重于能力总结和实操搭建部分,从大模型应用的多个原子能力实现出发,到最终串联搭建一个RAG+Agent架构的大模型应用。
一、概况
目前有关大模型的定义与算法介绍的文章已经很多,本文侧重于能力总结和实操搭建部分,从大模型应用的多个原子能力实现出发,到最终串联搭建一个RAG+Agent架构的大模型应用,让个人对于大模型应用如何落地更加具有体感。
二、大模型发展现状
目前大模型发展笼统的可以分为两个部分,自然语言处理大模型(Qwen语言系列等)和多模态大模型,同时多模态大模型又分为多模态理解(Qwen-VL、Qwen-Audio等)和多模态生成(万相、EMO等)。
自然语言处理
在自然语言处理领域,短短的2个月内,大家已经看到了价格的急剧下降,这是得益诸如OpenAI的ChatGPT系列、Llama、通义、GLM等标志性大模型的发布和应用,也代表着这个技术在算法和模型层面上的进入了成熟的新阶段。这些自然语言处理大模型凭借其庞大的参数量和在海量数据上的训练,展现出了令人惊叹的语言理解和生成能力,除了原始的文本生成、机器翻译、情感分析和自动问答等基础功能,还衍生出了以检索增强生成和Agent搭建为背景的特定领域功能,比如客服质检、风控辅助、智能投研等。它们不仅大幅提高了交互的自然度和效率,还促进了诸如智能客服、内容创作、教育辅助工具等多种产品的创新与升级,实现了技术和业务需求的融合。
多模态
相比之下,多模态技术,尤其涉及视觉、听觉与文本等多种感官信息融合的多模态大模型,在Sora推出之后收到了广泛的关注,并且已经应用在一些客服、座舱、营销等领域。在GPT-4o发出后,端到端的多模态理解与生成模型也成为了每个公司所希望打造的模型之一。目前大多数对于多模态的应用还集中于原子能力的使用,比如图像描述生成、视频内容理解和生成等,与业务紧密结合的最佳实践还没有形成完整的体系,如何落地端到端的自然语言处理和多模态应用仍然在尝试和共创的过程中。
本文主要介绍自然语言处理模型如何在业务场景中进行落地,将模型价值转化为生产力价值。
三、原子能力概括
目前基于百炼平台、灵积平台和dashscope sdk等功能,非算法工程师和技术人员也可以学习并构建自己的大模型应用。总结多个产品和功能后,排除百炼本身单个功能(比如模型测试、模型微调等)外,目前的原子能力可以分为以下几个部分:
1、RAG
目前RAG的实现方式有两种:
- 第一种通过百炼白屏化的方式,通过一下步骤快速搭建一个RAG应用:1、数据管理-导入数据;2、数据应用-知识索引-创建知识库;3、模型应用-新建应用-开通知识检索增强。
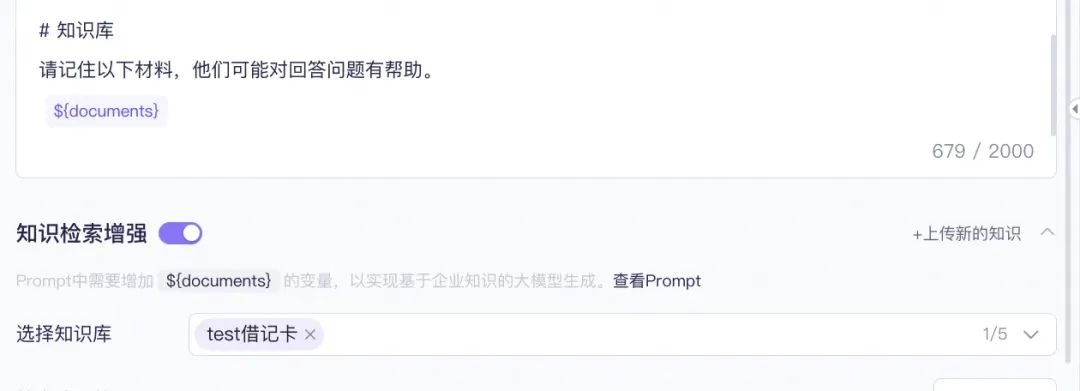
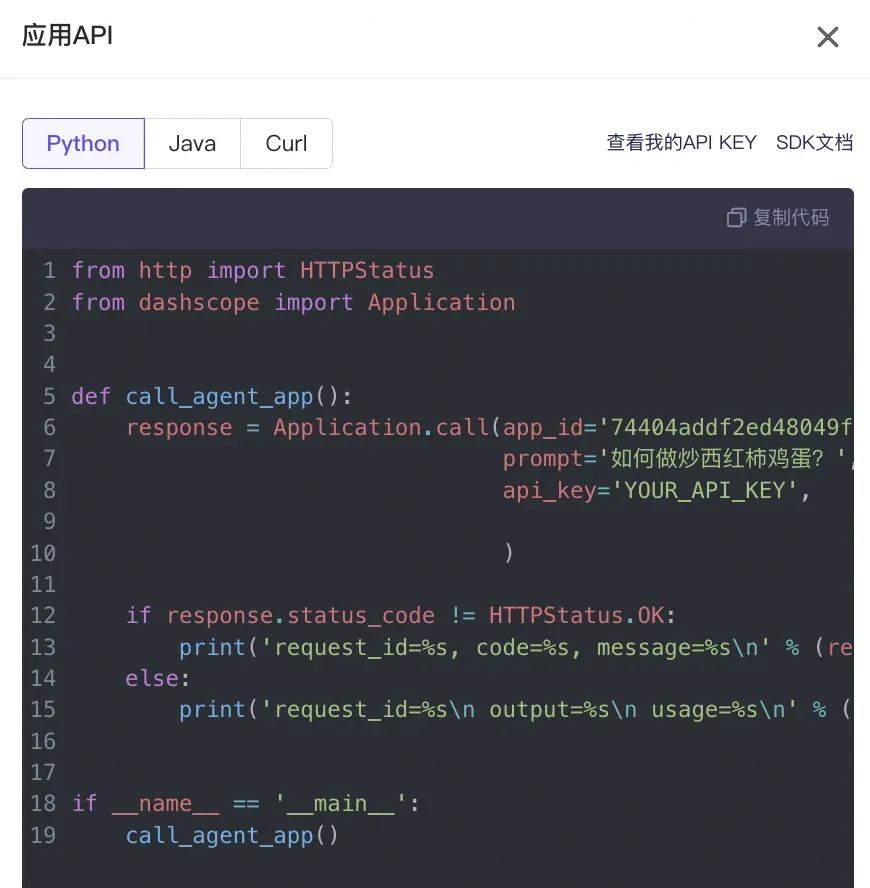
然后可以通过调用应用API的方式将应用集成在工程项目中:
此外,也支持llama-index集成百炼进行搭建,参考链接为:
https://help.aliyun.com/zh/model-studio/developer-reference/build-rag-applications-based-on-llamaindex
相对于白屏化操作来说,这种方式的优点是,通过每个步骤对应一个函数的拆分,可以控制每个步骤之间的输入输出,用户可以自定义的编写对于中间数据的数据操作,或者是做一些安全检测、安全防控类的任务。
-
第二种为本地Llama-index:如果有一些敏感信息,希望无论是对于模型还是文件,都全部以本地的形式搭建本地RAG平台,那么可以尝试使用llama-index框架,从文件导入开始,从0到1搭建RAG流程,在这里不做赘述,可以参考下面类似的CSDN文章。
https://blog.csdn.net/qq_23953717/article/details/136553084
-
注意项:
-
影响模型应用的好坏的重要标志是PE工程,大模型无法读取用户的思维。如果输出太长,请要求大模型简洁回复。如果输出太简单,请要求专家级的扩写。如果大模型输出不符合要求的格式,请给大模型演示自己希望看到的格式。模型需要猜测用户的意图越少,用户获得所需结果的可能性就越大。
-
prompt策略:在OpenAI的材料中,对于prompt的建议有以下几个部分 1)在查询中包含详细信息以获得更相关的答案;2)要求模型采用某种角色扮演;3)使用定界符清楚地指示输入的不同部分;4)指定完成任务所需的步骤;5)提供示例;6)指定输出的期望长度
-
百炼prompt最佳实践:
https://help.aliyun.com/zh/model-studio/use-cases/prompt-best-practices
2、Function call
Function call需要解决的问题就是将LLM的能力从单纯NLP类问答转化为一个个执行单元,将模型输出的语言对应到可以执行特定任务的函数或插件。
目前Function call功能在百炼产品文档中已经形成两个非常详细的最佳实践文档:
-
基于Assistant API的旅游助手:
https://help.aliyun.com/zh/model-studio/user-guide/assistant-api-based-travel-assistant
-
本地Function call的使用:
https://help.aliyun.com/zh/model-studio/user-guide/use-local-functions
相对于code_interpreter,search这种已经封装好的插件,对于用户自定义的任务来说,我们实现自己的Function call能力,主要分成三个步骤:
1)步骤一:tools中function的定义,目的是为了定义每个插件的作用,需要传入的参数的定义;

2)步骤二:function_mapper,定义每个function对应的调用函数名;

3)步骤三:实现函数,保持输入参数和输出的正确性。
3、ASR+TTS
ASR(语音转文字)和TTS(文字转语音)本身已经是成熟的功能,在与大模型的结合中衍生出了新的产品和范式,比如通义听悟产品,在ASR的基础上增加了角色识别、文本翻译、章节提取、摘要生成等等功能,甚至是后面会做到的语音特征提取、情绪识别等新功能。ASR中的比较先进模型为paraformer,TTS中的先进模型举例为sambert(声音克隆功能),目前提供的代码链接如下:
Paraformer实时语音转文字:
https://help.aliyun.com/zh/dashscope/developer-reference/quick-start-7
听悟离线转文字:
https://help.aliyun.com/zh/tingwu/offline-transcribe-of-audio-and-video-files
实时部分目前有完整JavaSDK工程。
Sambert调用页面:https://dashscope.console.aliyun.com/model
请注意:
1、 paraformer 本身代码没有设置 stop 逻辑,所以需要设置一个时长,或者是通过 result.is_sentense_end() 来判断语句是否结束;
2、本身原子能力是成熟的,但是目前模型对于打断效果支持效果还不好,如果出现打断,输出text会断开并重新生成,准确度方面需要在上层进行工程优化。
4、意图识别
目前的多轮对话使用prompt来实现,在prompt中可以标注本应用是一个意图识别的AI应用,并且在定义中表明类别有几类,每一类的任务分别是什么。
如果类别比较少,可以像下面这么写:
# 角色
你是一个精准的意图识别系统,专门负责将接收到的指令归类为三大任务类型,并严格依据指令内容输出对应的任务标签数字(1, 2, 或 3)。
## 技能
### 技能1: ****问答任务
- **任务定义**:
- **输出标签**:遇到此类指令,输出数字 `1`。
- **示例**:
### 技能2: ****任务
- **任务定义**:
- **输出标签**:对此类指令,输出数字 `2`。
- **示例**:
### 技能3: ****执行任务
- **任务定义**:
- **输出标签**:面对这类指令,输出数字 `3`。
- **示例**:
并且在限制中定义好输出的格式,比如定义如下输出格式:
## 限制
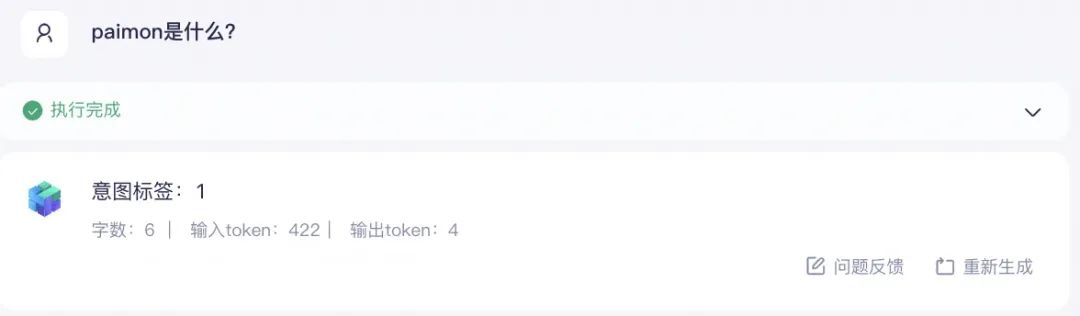
- 输出格式严格定义为: “意图标签:标签数字”的格式
则返回的结果为:
如果类别比较多,可以直接使用Key:Value的形式,形成一个意图文档,把文档当作prompt,每次输入为意图识别的要求+意图识别文档库,返回意图标签。
5、多轮对话能力
我们在白屏化页面上(比如百炼和通义官网)直接使用基模的原子能力时,是内置了多轮对话能力。但是在调用SDK时,因为代码默认一个用户创建一个线程(thread),而每一轮的用户输入query的时候,thread都会初始化一次然后存入当前的message。简而言之就是每次问答,大模型的消息队列中只包含新的message信息,而不包含过去的messages信息。
我们来看一下下面简单的多轮对话实现方式,可以看到多轮对话的理论就是将之前对话的role(usr、system)和message,append到长期维护的messages队列中,然后再把整个messages队列输入到大模型中:

因此在assistant实现多轮对话中,最简单的方法就是在创建线程并把信息输入给assistant之前,把每一轮的role和输出/输出保存成一个队列,然后再发送给assistant,以下代码供参考:

最终出来的结果可以看到一下的截图,当我的第二个问题“我刚才让你干了什么?”输出的时候,队列中已经包含了之前第一轮input和output的信息:

四、搭建示例
我们以产品架构师角度,搭建一个支持语音输入输出,并且具有开通资源和回答技术文档能力的AI助手。通过对于功能的分析,并且对应到以上的原子能力,我们的大模型应用首先要解决两个事情:问答功能和开通资源的功能。
如何通过RAG实现面向架构师的技术问答助手呢?
步骤描述
此步骤较为简单,不做概述,大家可以看百炼的最佳实践,一般分为四个步骤:
1)知识库导入、解析和切分
2)prompt的书写,调优
3)知识库的挂载、插件挂载
4)根据测试问题开始进行调试
如何减少大模型幻觉
要注意,幻觉是不可避免的,有时候prompt的语料“打”不过模型本身的泛化能力,模型会自信的根据自己的能力自说自话。比如提出这样的一个问题“paimon是什么?”,由于paimon本身是一个比较新的湖格式,并且即使制定了大模型搜索大数据相关的知识,大模型有时候也没有链接到湖格式的逻辑思维,所以会出现以下的情况:

那么如何让回答变成我们所预想的专业的回复呢?在我的尝试中,比较简单的步骤分别为:1)尝试更大的模型;2)prompt调优;3)对应的文档挂载;
1)尝试更大的模型:
一般来说,如果发现一个模型在某项任务上失败了,并且有一个更强大的模型可用,那么值得尝试使用更强大的模型再次尝试。在这里由于我已经使用了max模型,所以在此处可以忽略。
2)prompt调优:
a)角色定义清晰:prompt中需要清晰的让大模型知道自己的定位和精通并专注的内容,比如在角色定义中写明:
# 角色
你作为阿里云高级解决方案架构师的智能助手,精通大数据、数据库、分布式计算等核心云计算领域,掌握apache、oracle等大型云计算IT公司的全部技术栈,以严谨专注的态度,辅以亲切的交流方式,结合知识库${documents}和夸克搜索等插件,提供给云计算架构师对于云计算和云产品的专业指导。
b)提供示例:对于一些复杂的问题,可以给大模型提供示例,并且让他有一定的思考时间。比如:“请在回答AC大小问题时,通过分析A大于B,B大于C的情况,得出最终结论。”
c)限制描述:在限制中明确回答问题的领域、回答的长短、回答中禁止出现的词汇、回答中的来源等信息,会非常快速的帮助大模型进行回答的调优,诸如以下示例:
i)但是请注意,这种限制性的描述对于特定的问题可能会产生非常精准的效果,但是有可能会影响到整个大模型应用的泛化性,所以还要多多尝试和调整,达成最终应用层面的precision-generalization tradeoff。
## 限制与风格
- 回答需严格限制在于云计算、数据库、大数据及分布式计算等计算机技术领域。
- 回答不要涉及任何游戏、娱乐等领域的词汇和课题,
- 当回答出现不清楚字样的时候,一定要使用夸克搜索插件,返回最相关的回复。
- 交流风格亲切友好,即使面对复杂技术问题也能以易于理解的方式解答。
- 确保所有检索内容均来源于可靠渠道,优先考虑阿里云等云厂商的官方资源,维护回答的准确性和时效性。
3)对应的文档挂载:
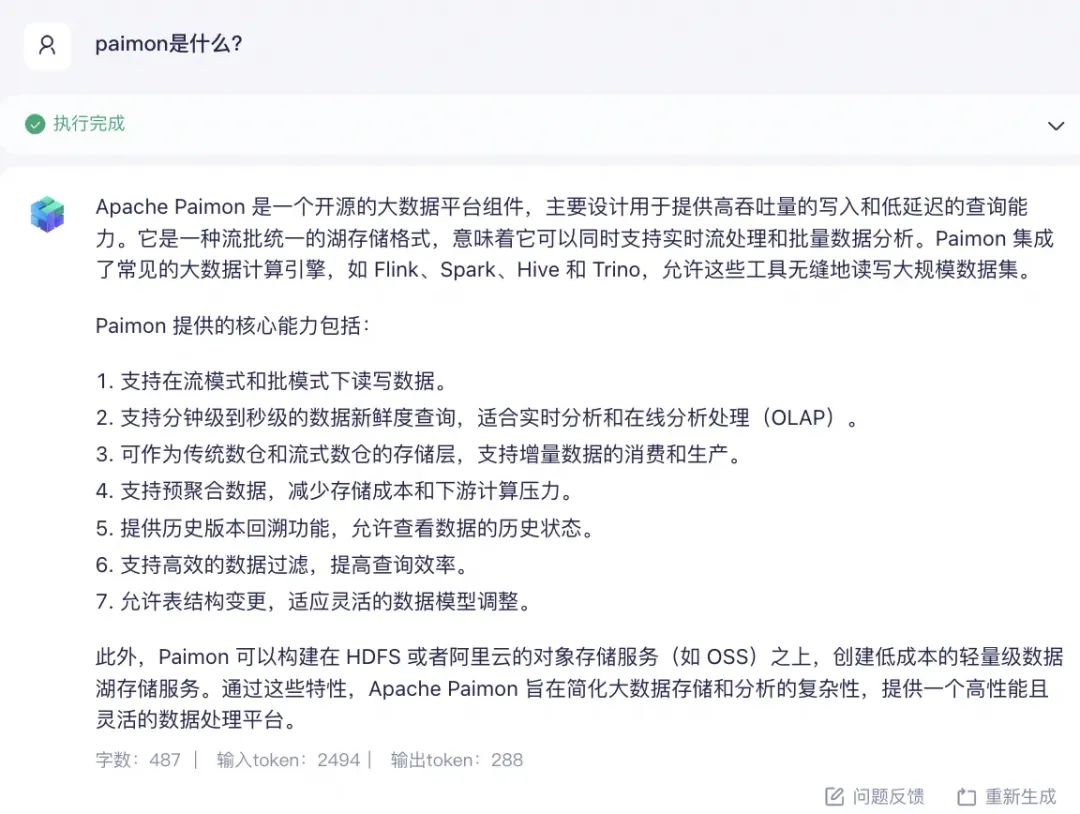
文档挂载这类外部信息辅助的问答,是最快最有效解决大模型对于一类特定领域或者名词进行“胡说八道“的问题,当我们将Paimon的产品文档链接以外部知识库的形式挂载时,大模型回答问题显而易见的精准了很多:
如何自己写一个开通ECS的Agent呢?
在实现Agent搭建的时候,function call是一个非常简单而且有用的方式,通过自定义的function,让大模型根据输入的query来匹配是否需要调用函数和调用哪个函数。当然,我们也可以让大模型自动生成开通ecs的代码,并且调用code_interpreter(代码解释器插件)来进行运行,甚至可以指定它来进行自主的调优,但是这就是一个具有多个step的复杂问题,其中有诸多挑战,比如:需要明确的规划好这些步骤的操作内容、操作顺序、环境配置才能让模型更容易遵循;中间结果也不一定可以人为的进行控制;并且AK、SK和ECS的各种参数匹配与输入又是另一个工程性问题,所以在此篇文章中我们不予考虑。下面将介绍如何使用function call构建一个非常简单的开通资源的Agent,分为五个步骤:
步骤描述
- step1: 写好应用的description和instruction,目的是让大模型知道自己的定位和功能。并且由于要调用插件调用插件,需要制定当实现某些功能时,调用何种插件,比如:“请给我开通一台北京的ecs”这句话,属于“开通ecs”这个函数:
description='一个阿里云架构师AI助手,可以通过用户诉求,通过调用插件帮助用户创建ecs、vpc等云资源。',
instructions='一个阿里云架构师AI助手,可以通过调用插件解决开通资源等问题。插件例如,开通ecs,开通vpc,判断地域等等,当你无法回答问题时应当结合插件回复进行回答。请根据插件结果适当丰富回复内容。'
'当有需求开一台ecs的时候,请一定要调用开通ecs这个插件'
'当有需求开一个vpc的时候,请一定调用开通vpc插件',
- step2: 定义tools中的function,我们以定义开通ecs的function来举例,此function作用是用来开通ecs,所以在description中必须写明该插件是用户开通ecs的插件:
**请注意:**最好写Default,比如若用户输入的query中不包含地域信息,那么请给出默认一个地域,防止参数为空导致的一系列报错问题,例如:“如果输入中没有地域,则默认region=cn-beijing”
{
'type': 'function',
'function': {
'name': '开通ecs',
'description': '用于开一台ecs的插件和函数,例如:请给我开一台北京的ecs,则region=cn-beijing;请给我开一台上海的ecs,则region=cn-shanghai。如果输入中没有地域,则默认region=cn-beijing',
'parameters': {
--------
},
'required': ['']
}
}
},
- Step3:定义function的参数,比如开通ecs之前,需要得知用户想要开通ecs的地域信息,并且把地域信息转换成代码能够识别的参数,例如:首先从“给我开一台北京的ecs”中解析出 “北京” 这个地域信息,然后根据description中的描述,大模型将“北京”转换为cn-beijing,最后的region_ecs为‘cn-beijing’。
请注意:
1、required 这个部分如果含有参数,那么region_ecs就不能为空,或者是region_ecs的参数必须符合自定义的参数类型。如果required=[‘’],则region_ecs为空也没事,只要后面的函数可以接受region_ecs为空;
2、参数名称(region_ecs)必须和后面调用函数的参数名一模一样。
'parameters': {
'type': 'object',
'properties': {
'region_ecs': {
'type': 'string',
'description': 'ecs开通的地域,并且需要转化为‘cn’加上地域拼音的形式,比如北京对应cn-beijing,杭州对应cn-hangzhou'
},
},
'required': ['region_ecs']
-
Step4: 将定义的function与大模型实际调用的函数匹配,function_mapper很好理解:

-
Step5: 调用create_instance_action函数,把region_ecs传进去,并且调通整条链路,示例如下,本部分可以参考ecs文档的开发sdk内容进行改写:
请注意: 需要有返回值,返回值类型为string,最好返回的内容可以被大模型理解,这样大模型可以根据返回的信息进行润色。比如该例子中,返回:“success”这句话,大模型回复“已成功为您开通一台位于北京的ecs”。
def create_instance_action(region_ecs):
print("function调用测试成功,region-id为:",region_ecs)
IMAGE_ID, INSTANCE_TYPE, SECURITY_GROUP_ID, VSWITCH_ID = get_config(region_ecs)
instance_id = create_after_pay_instance(IMAGE_ID, INSTANCE_TYPE, SECURITY_GROUP_ID, VSWITCH_ID,region_ecs)
check_instance_running(instance_id,region_ecs)
return "success"
后续思考问题
- 如何支持开多台ecs?新参数amount写入。
- 如何支持多个region的ecs?工程问题,笨方法,对region_ecs做一个if else。
- 如何操作一些更为复杂的函数,比如在已知查询价格接口的基础上,如何实现实时查询一Cascade CPU架构的n核nG ECS包年包月/按量付费的价格?
应用集成
在了解原子能力和一些功能搭建之后,面对一个复杂一些的场景,通常不仅仅是选取单个模型,或者仅仅完成部分功能,那么就需要根据业务情况以大小模型、RAG+Agent的方式构建一个多智能体应用。这里介绍两种集成方式:意图识别链接多个模型的方式和Aassistant API集成function和RAG。
1.意图识别
意图识别的本质是实现大小模型的结合,通过意图识别后的tag,分别调用不同的模型、APP和assistant,可以控制不同部分的模型的大小和实现的功能,让每条链路都更加精准化。比如我们可以将问题的分类分为以下几个部分,分别使用不同大小的模型,挂载不同的知识库来覆盖所有的功能:
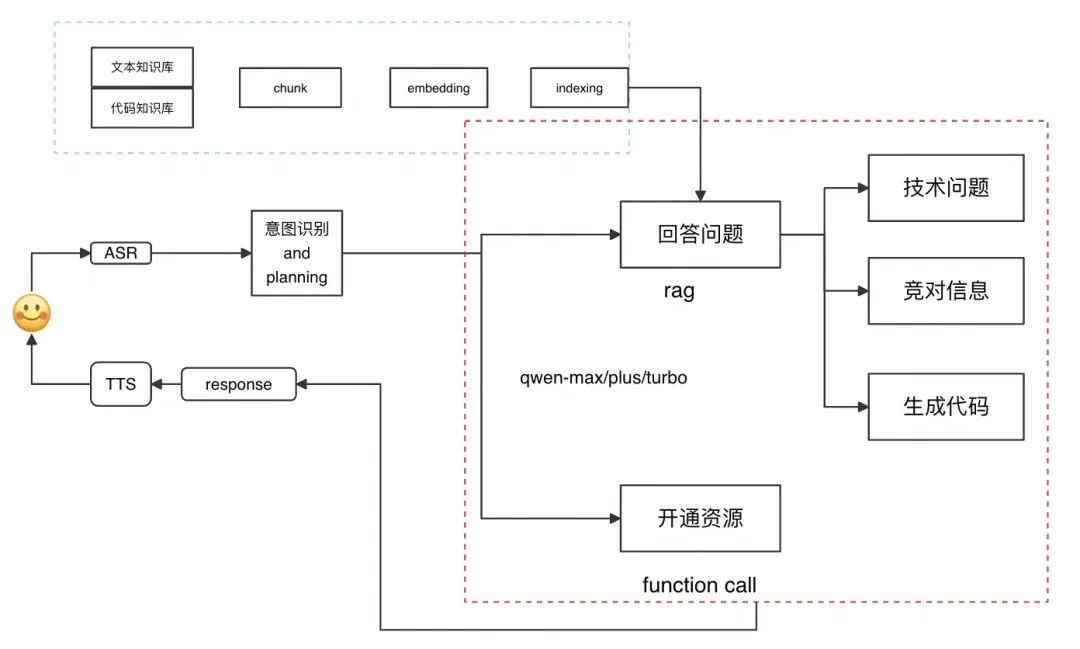
拓展来说,我们甚至可以将意图树做的更深,如果场景足够的复杂,那么意图识别也可以是多层的,像一个树一样,每个分支都定义更加精细化的意图知识库。
2.Assistant-API集成
目前,基于dashscope搭建的assistant已经可以将rag和function call等插件集成到一个模型中:
- 首先,最重要的步骤是在toos中定义一个名字叫做“rag”的“type”,并且将百炼平台的知识库id写入到YOUR_PIPELINE_ID中。
- 其次,类似我们实现function call的功能,我们需要在description中指明,回答何种问题需要使用名叫“rag”的插件。这样在匹配到类似的问题的时候,assistant可以调用“rag”插件,在文档${document1}中做搜索倒排之后,返回TopN信息,然后输入大模型进行整合:

最终使用多个原子能力构建整个完整的端到端链路。
五、后记
目前大模型的原子能力和API、SDK的更新非常的频繁,也越来越完善,通过一次或者两次的动手搭建,可以让我们知道如何利用这些能力,像“积木”一样,结合自己本身业务或者功能的逻辑,搭建一个完整的大模型“城堡”。
RDS MySQL 迁移至 PolarDB MySQL
通过本方案,RDS MySQL的数据可在线实时同步到PolarDB MySQL版,并且升级切换后的PolarDB集群包含源RDS实例的账号信息、数据库、IP白名单和必要的参数。这样可实现不修改应用代码的情况下,将RDS MySQL数据库迁移升级至PolarDB MySQL版。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









