







 本文介绍了如何使用ResNet18模型构建FCN,通过`children()`方法选取网络层,并利用转置卷积进行上采样。同时,文章详细阐述了微调过程中添加新层的两种方法,并讨论了它们的区别。此外,还展示了如何初始化转置卷积层的权重,以及训练和预测过程中的损失函数计算方法。
本文介绍了如何使用ResNet18模型构建FCN,通过`children()`方法选取网络层,并利用转置卷积进行上采样。同时,文章详细阐述了微调过程中添加新层的两种方法,并讨论了它们的区别。此外,还展示了如何初始化转置卷积层的权重,以及训练和预测过程中的损失函数计算方法。
在此讲解FCN全连接网络,主要介绍里面的children()拾取原网络中部分网络层并附加新网络层的操作,并对分割任务的loss计算流程进行了debug,为后续类似做法做参考。
目录
1.children()操作
使用ResNet18模型提取图像特征,但是不要最后的全局平均池化层和全连接层,只提取上面的
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]在此,使用list并嵌套children操作,将原net中的每一层作为单独的元素填充到一个list中,如下图:

1.2含义解释:
children() 是一个用于获取模型的子模块的方法。它返回一个生成器,该生成器包含模型的所有子模块。子模块是指模型中的直接子模块,这些子模块可以作为独立的模块进行操作。返回的值为generator类型type,可以嵌套进list中。
1.3与微调finetune的关系
如果想使用for layer in net:,则net必须为Sequential生成的才行。
这里用list和children将原net中各个layer提取出来并组成列表,并通过Seq构造新的net
net = nn.Sequential(*list(pretrained_net.children())[:-2])
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
'''
torch.Size([1, 21, 320, 480])
'''finetune微调添加新的层时,可以使用.add_module,按以下方法进行添加并设置层的名字,也可以按照之前讲的直接.newname进行赋值添加新层:
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,
kernel_size=64, padding=16, stride=32))1.3.1与原先finetune的关系:
在此想到了前几节所用的finetune操作,直接在Seq生成的net后面加.newlayer=...,这二者有什么区别?
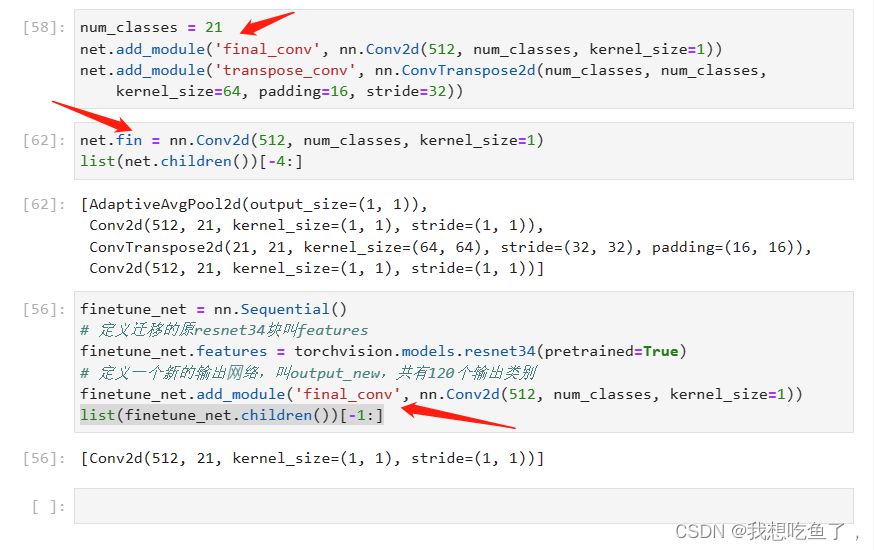
把网络名字打印出来看一下:

可以看到,上面用add._module操作添加的‘final_conv'与'transpose_conv’添加进了,并且使用前几节讲的net.fin(new_layer)直接赋值的fin层也添加上去了!
上面的56cell是前几节finetune讲述的先将原net赋值到一个新的Seq里面的features层,再将新加的赋值到新的层,这样生成的新Seq(finetune_net)在使用children()嵌套列表的时候,里面只有两个元素,因为新的Seq里面只有两层,一个features,一个final_conv。

1.3总结
前提永远都是定义了Seq的网络才能这样添加,这是两种添加方式。第一个例子使用add_module直接在原net上添加;而第二个例子先将原net赋值成features层,进而再添加的新层,所以在children中只有两个元素。
将第二个例子改成第一种例子,不定义新的features层,而是直接将模型等于原resnet,可以看到使用两种方法其实都可以添加新层:
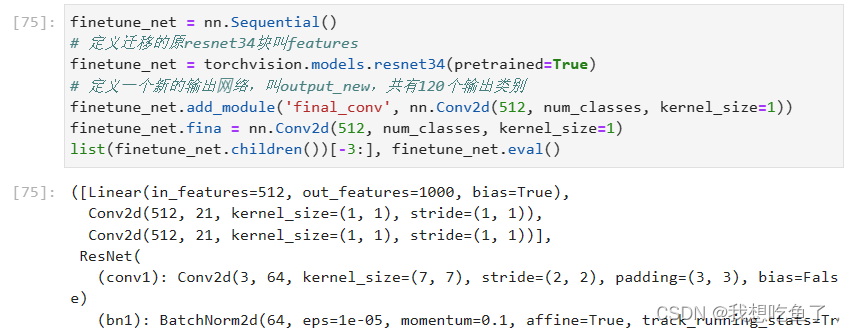
到net最后看一下新添加层情况:都添加成功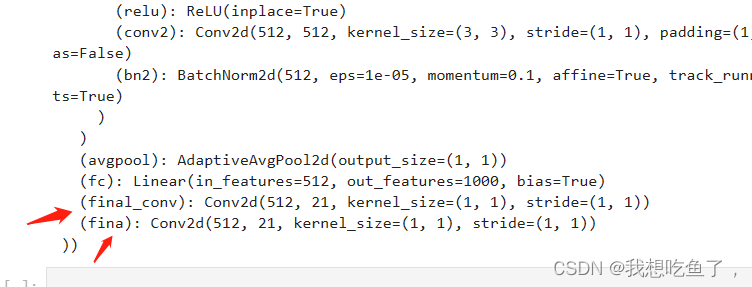
所以,1.二者均是直接在原网络的最后添加层的操作;
2.如果想任意割取net中的子块形成新的网络,使用children()嵌套list的操作,再使用如下操作:即可拾取该list的除后两个layer元素的所有层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])2.定义转置卷积与参数
2.1转置卷积
啰嗦的不说了,大白话就是实现将图片放大的卷积操作,上尺寸公式:
卷积:
转置卷积:
仔细观察可发现就是将卷积里面的out与input像转换一下,总结当k=2p+s时,转置卷积后的fmap尺寸成s倍增加!
2.2初始化转置卷积层:
使用双线性插值初始化转置卷积核的参数
这里的插值相当于finetune里面的迁移参数,用随机的也行,不过就是要多训练一些
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight注意一下如何将卷积核中的weight赋值到固定参数:
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,
bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4)); 上述双线性插值权重与转置卷积实现图片放大
这里设定的转置卷积层的作用是将图片变大s倍,使用双线性插值初始化权重,从而实现将图片拉大的效果
这里通过转置卷积与初始化双线性插值参数,实现了将pic放大s倍的操作
回顾一下使用Xavier初始化weight的操作:
nn.init.xavier_uniform_(conv_trans1.weight)再次注意:这里的插值相当于finetune里面的迁移参数,用随机的也行,不过就是要多训练一些。
3.FCN
使用双线性插值初始化转置卷积层参数,对于1×1卷积层,使用Xavier初始化参数
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);加载数据集:
class VOCSegDataset(torch.utils.data.Dataset):
"""⼀个⽤于加载VOC数据集的⾃定义数据集"""
def __init__(self, is_train, crop_size, voc_dir):
self.transform = torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.crop_size = crop_size
features, labels = d2l.read_voc_images(voc_dir, is_train=is_train) # 这里是list
self.features = [self.normalize_image(feature)
for feature in self.filter(features)]
self.labels = self.filter(labels)
self.colormap2label = d2l.voc_colormap2label()
print('read ' + str(len(self.features)) + ' examples')
def normalize_image(self, img):
return self.transform(img.float() / 255)
def filter(self, imgs):
# imgs是每个元素为tensor(c,w,h)的list,for循环后返回的即为img的tensor
return [img for img in imgs if (
img.shape[1] >= self.crop_size[0] and
img.shape[2] >= self.crop_size[1])]
def __getitem__(self, idx):
feature, label = d2l.voc_rand_crop(self.features[idx], self.labels[idx],
*self.crop_size)
return (feature, d2l.voc_label_indices(label, self.colormap2label))
def __len__(self):
return len(self.features)
def load_data_voc(batch_size, crop_size):
"""加载VOC语义分割数据集"""
voc_dir = '/CV/xhr/VOCdevkit/VOC2012'
num_workers = d2l.get_dataloader_workers()
train_iter = torch.utils.data.DataLoader(
VOCSegDataset(True, crop_size, voc_dir), batch_size,
shuffle=True, drop_last=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
VOCSegDataset(False, crop_size, voc_dir), batch_size,
drop_last=True, num_workers=num_workers)
return train_iter, test_iter指定随机裁剪的图像尺寸为320,480(wh都能被32整除);并指定bs
batch_size, crop_size = 32, (320, 480)
train_iter, test_iter = load_data_voc(batch_size, crop_size)
'''
read 1114 examples
read 1078 examples
'''
4.训练
对高宽分别做平均,在高处做一个均值,在宽出也做一个均值。
重新做了一个loss损失函数计算,主要添加了两个mean操作 ,具体见下面debug讲解:
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)笔者比较好奇这里面的loss是如何计算的,故进行了debug
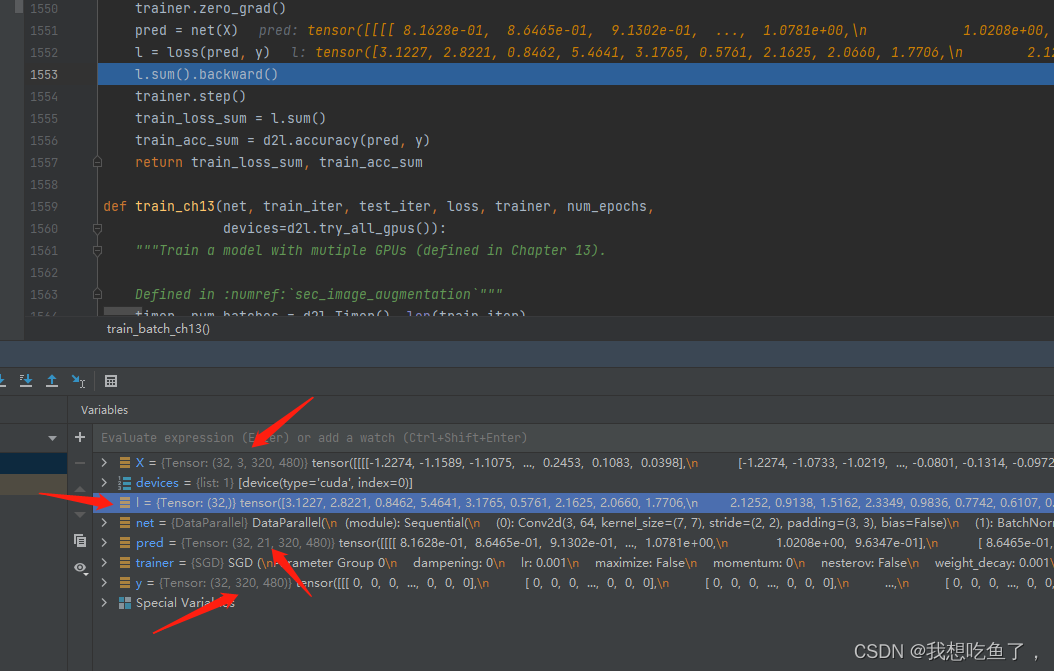
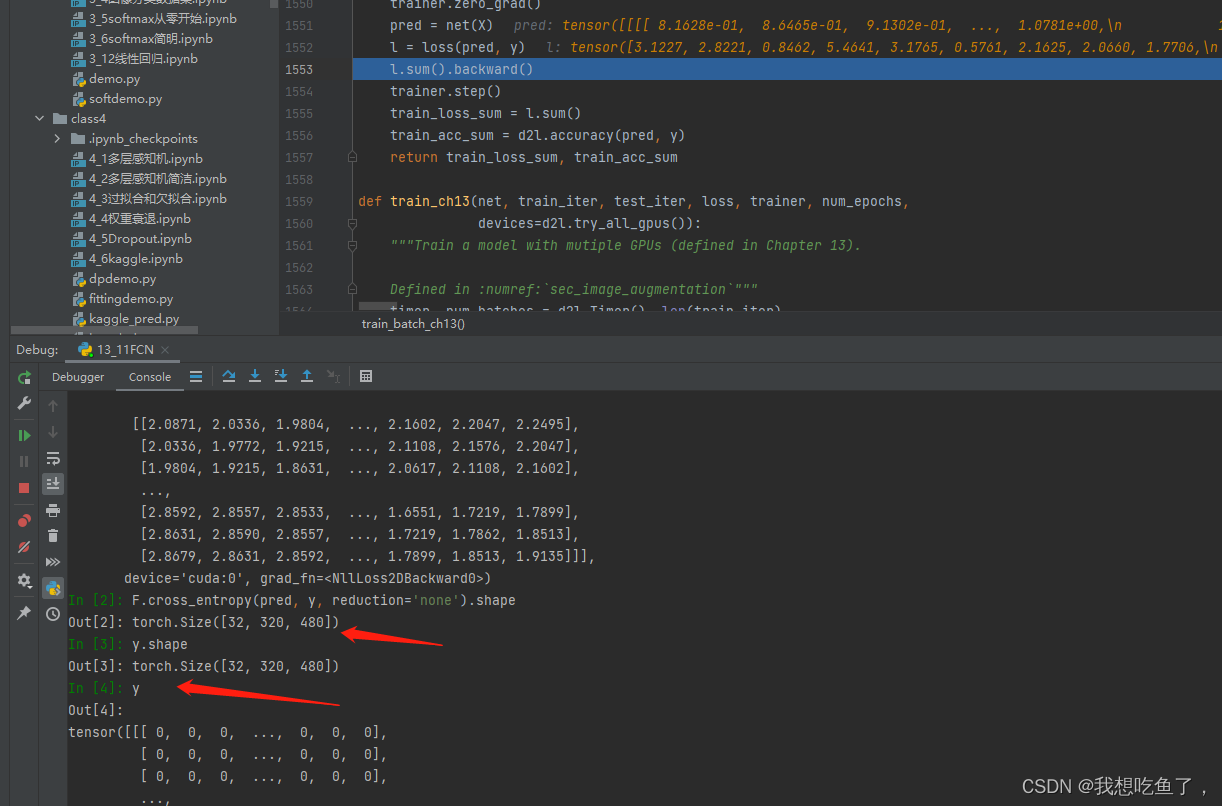
可得结论:
1.y为标记,其wh的每一个像素均为标记值。
2.pred为预测,有21(cls)个通道,每个通道的wh中的每一个像素为该cls下,各个像素的预测得分。
3.经过交叉熵后,得到与y相同的尺寸,即消去cls(与图像分类一致从(bs,cls)得到(bs.)),此时每个像素上均为每个像素各个通道的pred与label单个通道所做的交叉熵。
4.然后再将wh分别做mean,即定义的loss中后面的两个mean(1)操作。即得到bs个loss值,再相加成为标量做backward
5.预测
pred出来后,每一个类放在对应通道上,所以dim取1对应的是每个像素中,每个c中最大的那个通道标号,即所对应的类
def predict(img):
X = test_iter.dataset.normalize_image(img).unsqueeze(0)
pred = net(X.to(devices[0])).argmax(dim=1)
return pred.reshape(pred.shape[1], pred.shape[2])
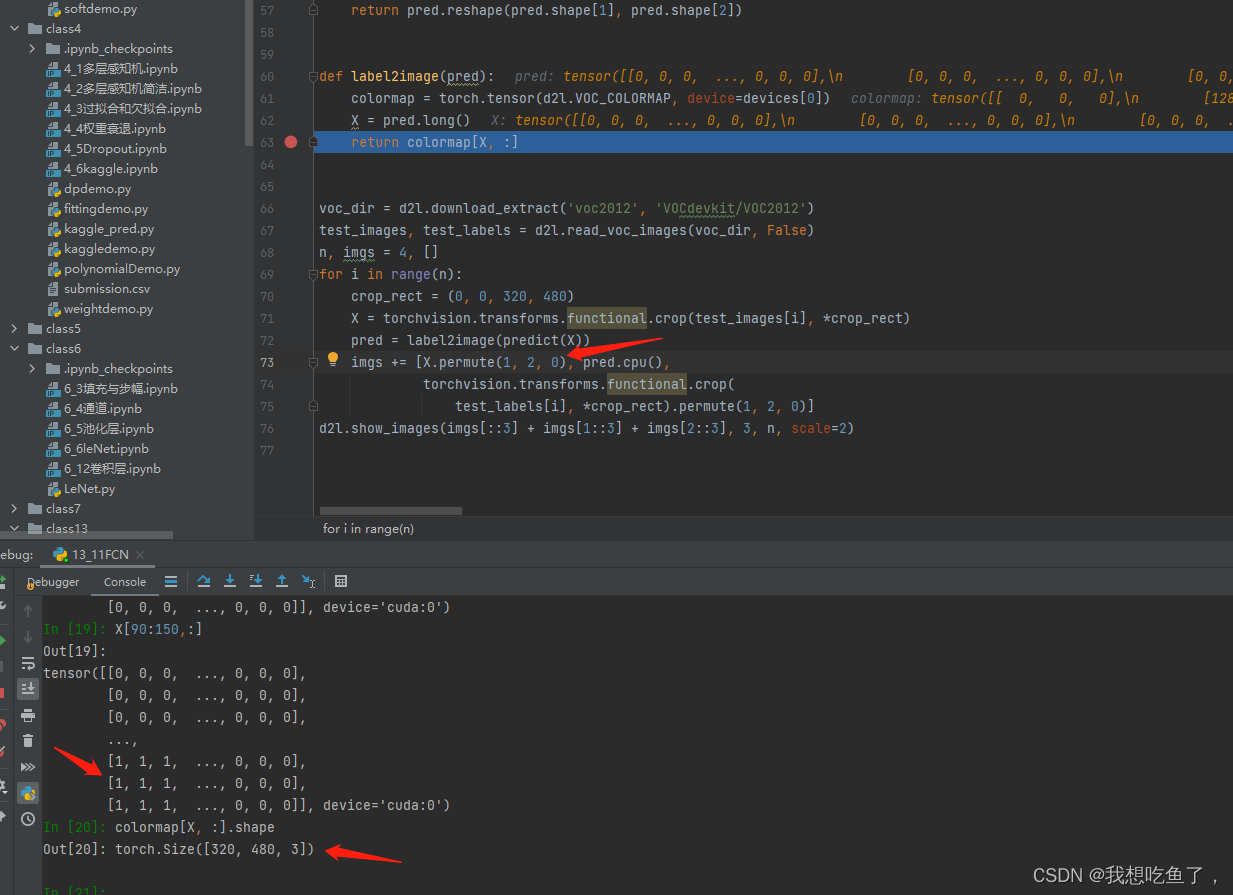
def label2image(pred):
colormap = torch.tensor(d2l.VOC_COLORMAP, device=devices[0])
X = pred.long()
return colormap[X, :]注意其中的argmax操作:
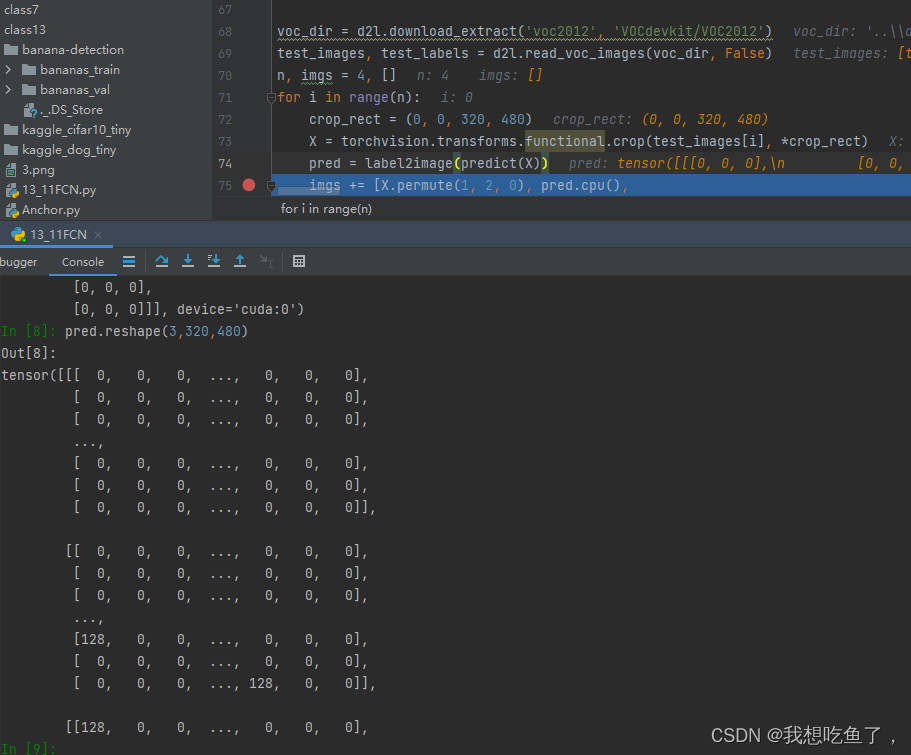
预测的时候,经过网络预测后,传出的是(bs,cls,h,w),再经过argmax(1),取1维度最大值的位置,输出的尺寸为(bs,h,w),其中每个hw中的每个像素均为前面的预测值最大通道(cls)对应的位置数字。
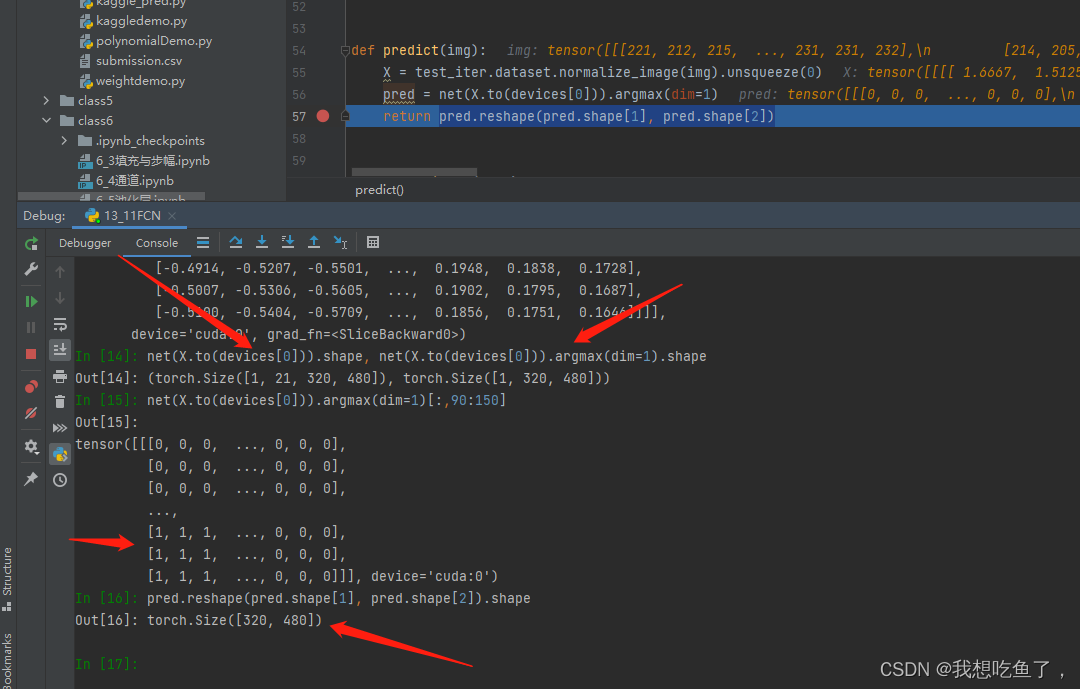
最后reshape将bs这个维度消掉,得到一个图片大小的hw矩阵,每个元素为预测最大值的对应通道(cls)的位置数字。
后面的这个label2image操作是将得到的对应cls的图片再转成对应种类对应的三通道RGB颜色(VOC_COLORMAP)方便后续绘图表达:
补充:训练好的net可以通过以下命令直接保存成pt文件:
torch.save(net, 'FCNmodel.pt')这样再使用的时候直接net = 'FCNmodel.pt'就可以调用net了!无需其他操作!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









