






🍎 Mac本地部署DeepSeek蒸馏模型指南:Ollama极简手册
——让你的Mac变身“AI小钢炮”💥
一、准备工作:Mac的“硬件咖啡豆研磨器”
1.1 最低配置要求
| 组件 | 入门级(7B模型) | 旗舰级(33B模型) |
|---|---|---|
| 芯片 | M1(2020款) | M2 Pro/Max(2023款) |
| 内存 | 8GB(需关闭Chrome) | 32GB(可边跑AI边刷剧) |
| 硬盘 | 15GB空间(留点地方给猫片) | 100GB+(模型全家桶爱好者) |
| 系统 | macOS Monterey 12.3+ | Ventura 13.1+(推荐) |
📌 冷知识:DeepSeek蒸馏模型=原模型的"精华萃取版",体积缩小40%,性能保留85%!
1.2 必备软件
•Ollama:模型管理神器(官网[1])•Homebrew:Mac界的软件百宝箱•Python 3.10+:建议通过Miniforge安装ARM原生版
二、安装步骤:3步召唤AI小精灵🧞
Step 1:安装Ollama(比泡面还快)
`# 一键安装(终端输入)` `/bin/bash -c "$(curl -fsSL https://ollama.ai/install.sh)"` ` ``# 验证安装(看到版本号就算成功)` `ollama --version` `# 输出示例:ollama version 0.1.12 darwin/arm64`
Step 2:下载DeepSeek模型(选你爱的口味)
`# 基础编程模型(程序员必装)` `ollama pull deepseek-coder-7b` ` ``# 聊天模型(含互联网最新知识)` `ollama pull deepseek-chat-7b` ` ``# 国内加速技巧(替换镜像源)` `OLLAMA_MODELS=https://mirror.example.com ollama pull deepseek-math-7b`
Step 3:启动对话(和AI说“嗨”)
`# 基础模式` `ollama run deepseek-chat-7b "用东北话解释量子纠缠"` ` ``# 高级模式(开启GPU加速)` `OLLAMA_GPU_LAYER=metal ollama run deepseek-coder-7b`
三、模型对比:找到你的“灵魂伴侣”🤖
| 模型名称 | 内存占用 | 硬盘需求 | 推理速度 | 擅长领域 |
|---|---|---|---|---|
| 1.3B | 2.4GB | 0.8GB | ⚡⚡⚡⚡ | 数学计算/快速问答 |
| 7B | 8GB | 4GB | ⚡⚡⚡ | 代码生成/日常对话 |
| 13B | 16GB | 8GB | ⚡⚡ | 创意写作/专业咨询 |
| 33B | 32GB+ | 16GB | ⚡ | 论文润色/复杂推理 |
💡 选择建议:
•M1用户:7B模型是甜蜜点•M2 Pro用户:可挑战13B模型•内存焦虑症患者:试试
--num-gpu 50%限制显存
四、黄金搭档软件:生产力开挂套装🚀
4.1 交互神器
•Chatbox:颜值爆表的聊天界面(下载地址https://chatboxai.app/zh#download)
brew install --cask chatbox
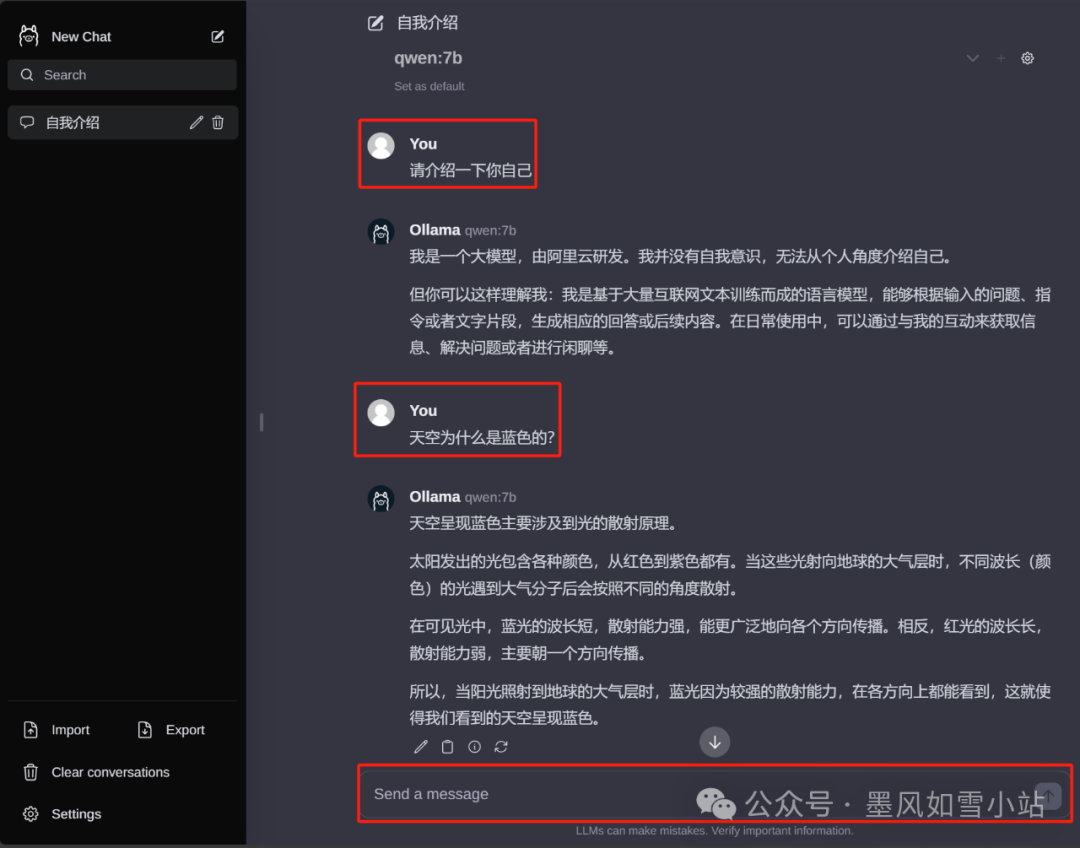
•Ollama WebUI(Docker版本):浏览器随时访问
docker run -d -p 3000:3000 -v ollama:/root/.ollama -e OLLAMA_HOST=127.0.0.1:11434 ghcr.io/ollama-webui/ollama-webui:main
4.2 开发神器
•VS Code插件:•Continue:代码自动补全•Ollama Assistant:侧边栏直接对话
4.3 效率神器
•Alfred Workflow(下载地址:https://www.alfredapp.com/workflows):快捷键秒呼AI
Alfred配置
•PopClip扩展:划词即刻提问
五、本地部署的5大核弹级优势💣
5.1 隐私安全
•你的聊天记录不会成为训练数据(想象和AI吐槽老板的内容被上传…😱)
5.2 离线王者
`# 飞机上写代码成就达成!` `sudo ifconfig en0 down && ollama run deepseek-coder-7b`
5.3 定制自由
•魔改提示词:
SYSTEM_PROMPT = "你现在是精通阴阳怪气的北京出租车司机"
•加载私人知识库:
ollama run deepseek-rag-33b --attach ~/Documents/my_knowledge.zip
5.4 成本控制
| 方案 | 7B模型年成本 |
|---|---|
| 云端API | ≈$720(按$0.002/1k tokens) |
| 本地部署 | $0(电费≈一杯奶茶钱) |
5.5 硬件压榨
•M系列芯片的神经网络引擎(ANE)火力全开•外接显卡扩展:
# 使用eGPU加速(AMD显卡限定) OLLAMA_GPU_LAYER=rocm ollama run deepseek-13b
六、常见问题急救包🆘
Q1:下载模型卡住怎么办?
`# 国内镜像加速(任选其一)` `export OLLAMA_MODELS=https://mirror.example.com` `export OLLAMA_HOST=mirror.ghproxy.com`
Q2:内存爆炸怎么救?
`# 启用4-bit量化` `ollama run deepseek-7b --quantize q4_1` ` ``# 限制GPU使用率` `OLLAMA_GPU_UTILIZATION=50% ollama run...`
Q3:如何让AI记住对话?
`# 启动时加载历史记录` `ollama run deepseek-chat-7b --history-file ~/ai_chat_history.json`
🎁 终极彩蛋:模型变身指南
`# 让AI用甄嬛体写代码注释` `ollama run deepseek-coder-7b --prompt-template "说句代码注释便是极好的,倒也不负恩泽。\n{{.Prompt}}"` ` ``# 创建私人模型分身` `ollama create my-ai -f Modelfile # 内含自定义指令`
现在,你的Mac已经解锁AI超能力!遇到问题时记住:
“重启解决90%的问题,剩下的10%需要再喝一杯咖啡☕”
如果想使用在线的R1模型 可以去硅基流动官网[2] 申请在线API使用 在我的往期教程里面就有
可以关注我的博客 里面都是我最新的文章:我的博客[3] 有源代码需求也可以关注我的:我的小店[4]
References
[1] 官网: https://ollama.ai/
[2] 硅基流动官网: https://cloud.siliconflow.cn/i/BWEwNgw1
[3] 我的博客: https://blog.worldcodeing.com/
[4] 我的小店: https://www.worldcodeing.com/
程序员为什么要学大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









