






说到卷积神经网络,先说四个字:提取特征!为啥要提取特征呢,原因有两个:
1)原始图像包含的信息量非常庞大且复杂,直接使用原始图像作为输入会导致网络训练过程变得非常复杂和困难。
2)对于一些噪声和干扰也能够更加鲁棒。
首先解决自己的一个疑问,为撒第一层就提取底层特征,第二层提取中层特征,第三层高级特征?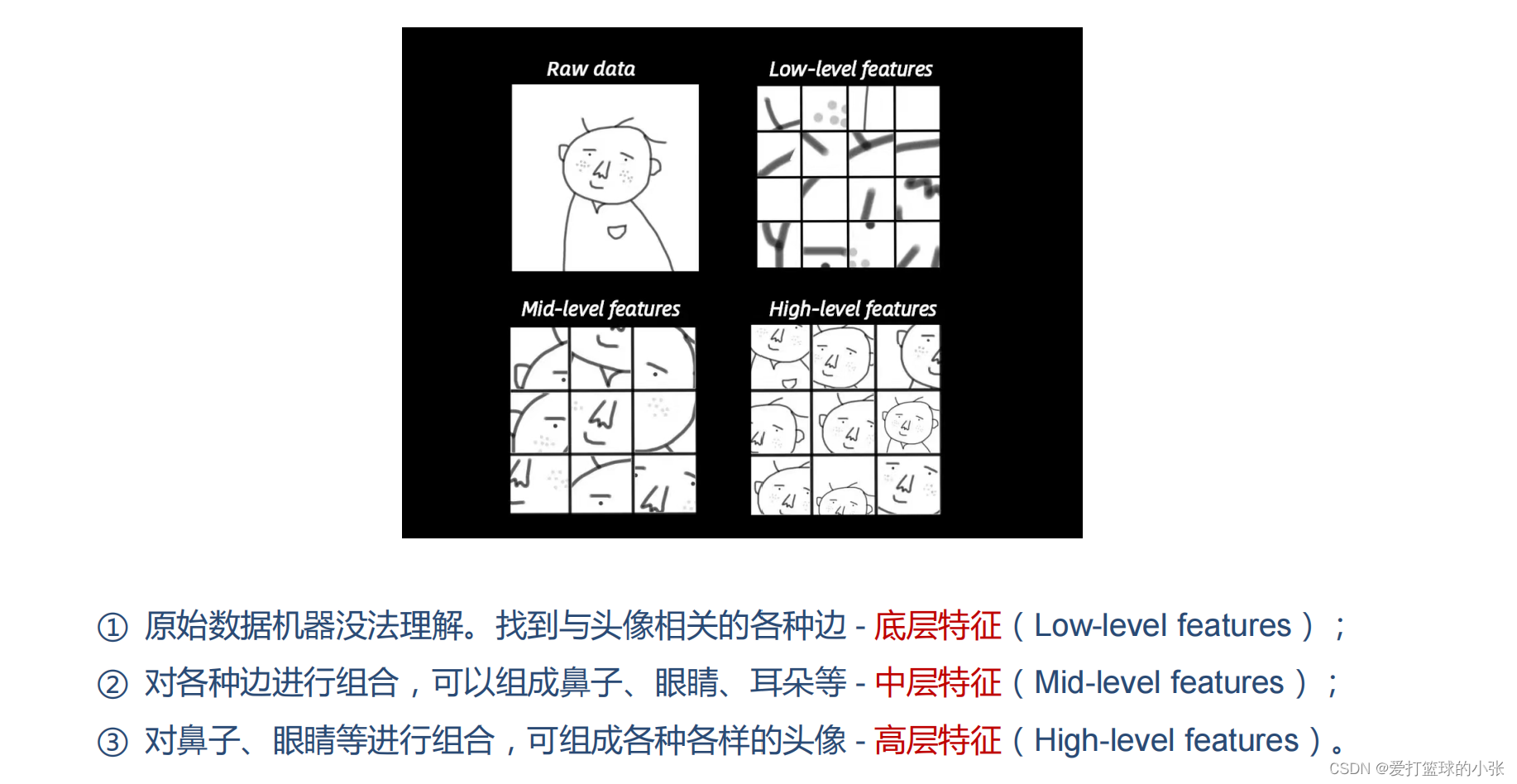
看了一下博客了解到,原因主要有两个:(具体内容的链接放在了最后)
1)、深层网络的感受野更大,大感受野下才存在一定的高阶语义
2)、深层网络所积累的特征空间更大。
一、概念
用自己的语言描述“卷积、卷积核、特征图、特征选择、步长、填充、感受野”。
卷积:
(这里说的卷积是互相关哈)关于图像问题,上下挨着的两个元素可能有很大关系,而全连接网络反应不了上下的关系,并且一压参数太多啦,于是引入了卷积,用个小卷积核卷,就是从原图像取和卷积核一样大的区域,上面的元素对应相乘再相加得到输出值。正如学长所说,卷积是一种高级的w*x+b的预算。
卷积核:
卷积核是提取图像特征的,相当于w*x+b中的w,其实我们的任务就是得到“优秀的”卷积核。具体看本节的第二问。
特征图:
就是经过卷积得到的结果,叫特征映射也叫特征图。
有个小疑问,为啥得到的特征图和原始图像接近啊,不是分类吗,不应该结果是哪一类吗?
答案: 卷积神经网络中的卷积操作是为了从原始图像中提取特征。之后的分类任务交给之后的全连接层。这也就是说卷积神经网络不光有卷积层,还有池化层,全连接层。
通过卷积层的卷积操作和池化层的池化操作,CNN能够有效地降低特征图的维度,减少计算量,同时也能够保留最重要的特征信息,从而使得全连接层能够更好地将特征映射到相应的类别标签上。
CNN的输出结果并不一定需要与原始图像完全一致。在一些任务中,如图像分类、目标检测等,我们更关注的是网络能否正确识别出图像中的关键特征,而不是输出与原始图像完全一样的结果。
特征选择:
不同卷积核选择不同特征

这个例子非常贴切,将眼睛作为卷积核,最后得到带有两个白色区域的图像,就是代表眼睛。
步长:
滑动的长度。一般从左到右,从上到下滑。如果滑着滑着,到了剩一个区域比卷积核小没法卷了,直接扔那不用卷了。
填充:
举个栗子:
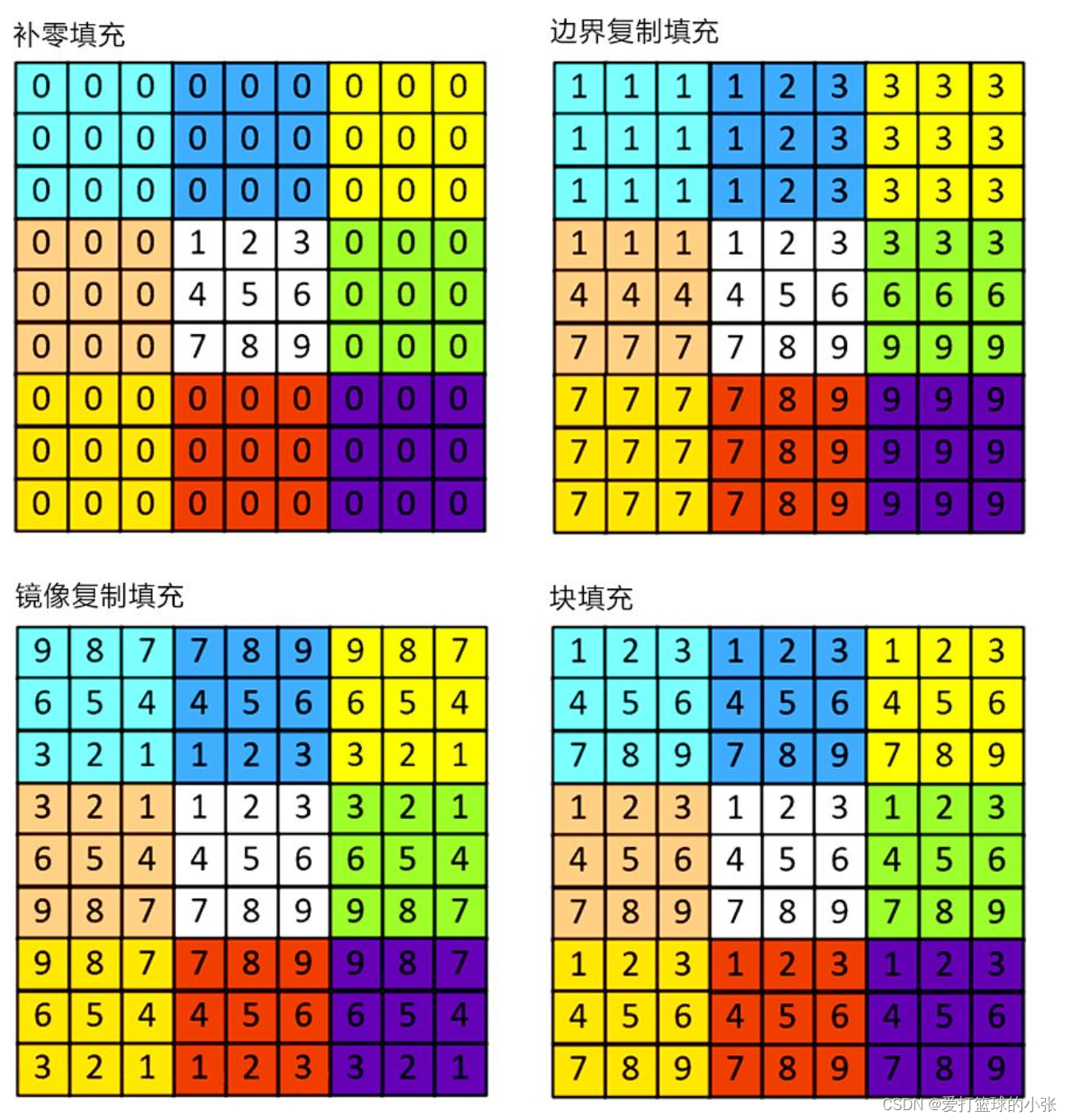
感受野:
就是特征图上的一个点对应输入图像的区域
来张图举个例子就知道了:
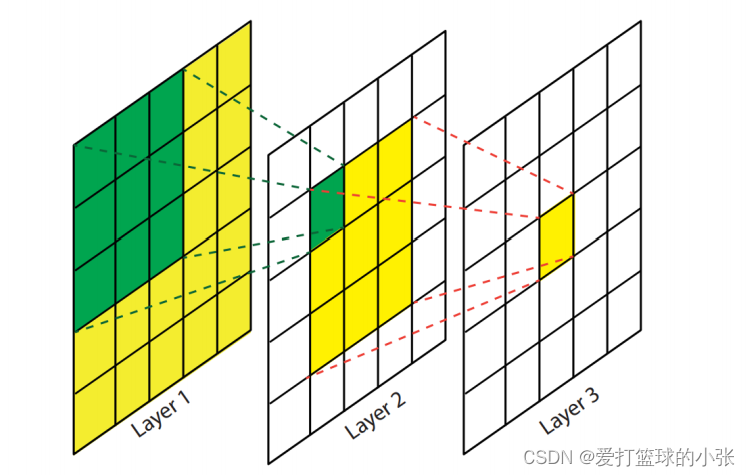
如上图,第三张图片中黄色区域对应的感受野是第一张图片的绿色区域。
我怎么刚看到这个链接,里面太全面啦,也解决了我之前遇到的问题!
卷积神经网络工作原理的直观理解_superdont的博客-CSDN博客
二、探究不同卷积核的作用
关于卷积核,先看个文章预热一下:
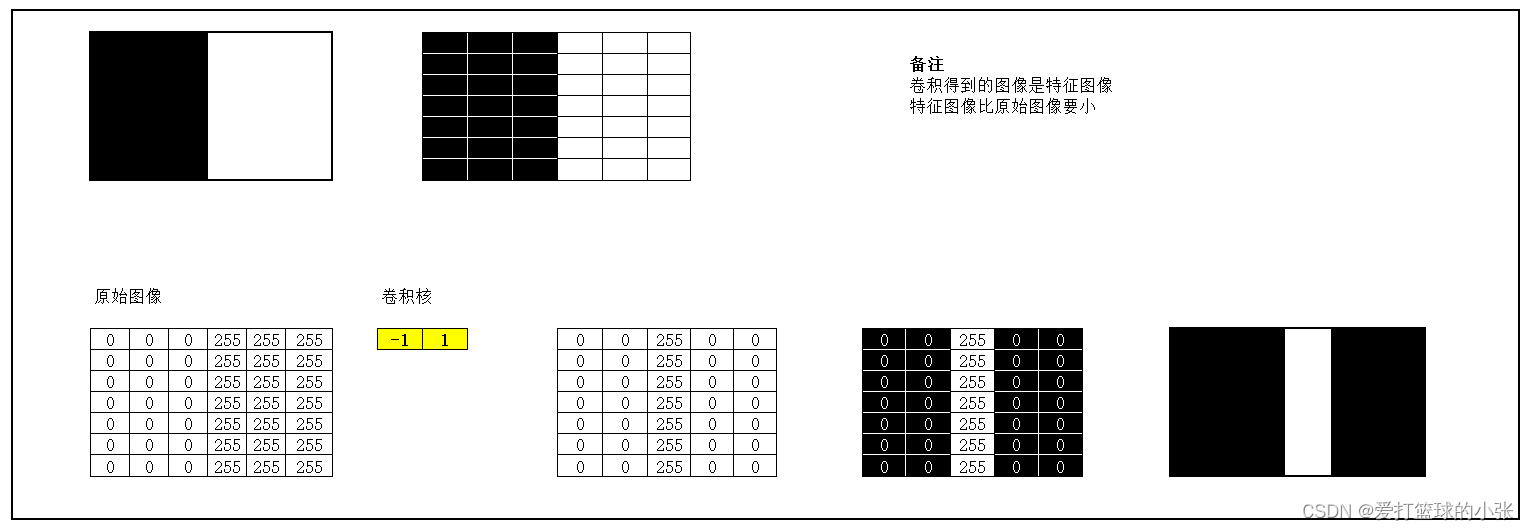
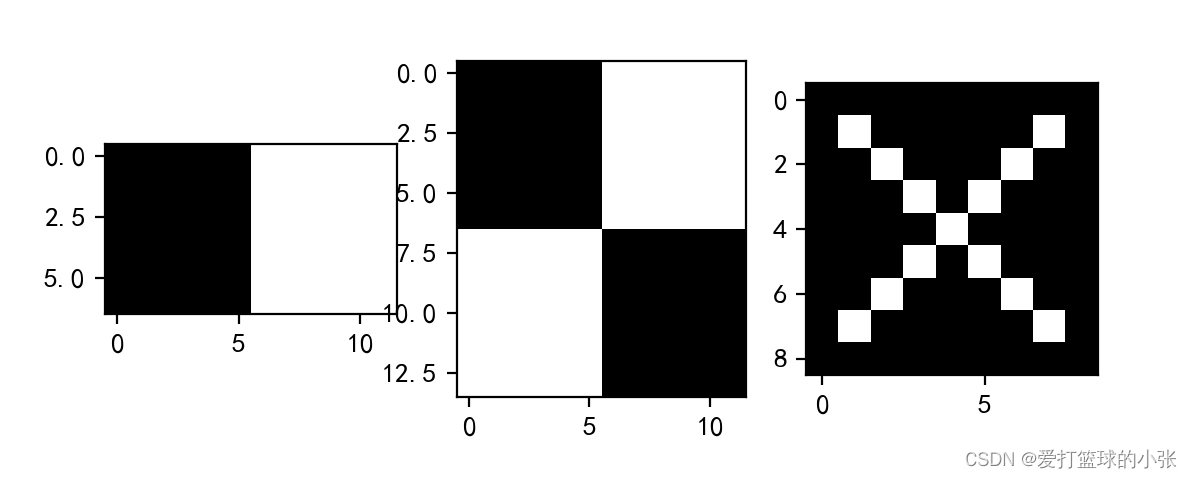
先把图形准备好:
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
pic1=torch.zeros((7,12))
pic1[:,6:12]=255
plt.subplot(2,3,1)
plt.imshow(pic1,cmap='Greys_r')#黑色对应的值是 0,白色对应的值是 1,'Greys_r' 是一种颜色映射方式,它将灰度颜色映射到从白色到黑色的渐变。
pic2=torch.ones((14,12))+254
pic2[0:7,0:6]=0
pic2[7:14,6:12]=0
plt.subplot(2,3,2)
plt.imshow(pic2,cmap='Greys_r')
pic3=torch.zeros((9,9))
for i in range(9):
for j in range(9):
if (i==j or j+i==8)and i!=0 and i!=8:
pic3[i][j]=255
plt.subplot(2,3,3)
plt.imshow(pic3,cmap='Greys_r')
plt.show()
需要用到torch.nn.Conv2d,参数详解请参考:https://blog.csdn.net/weixin_38481963/article/details/109924004使用torch自实现简易版conv2d卷积(2种方法)_conv2d 实现-CSDN博客https://blog.csdn.net/weixin_38481963/article/details/109924004
1. 图1分别使用卷积核 ,
, ,输出特征图
,输出特征图
w1 = torch.Tensor([[1,-1]])
w2 = torch.Tensor([[1],[-1]])
'''#感觉结果不太对劲,先用自定义的吧
#网络1
conv1=torch.nn.Conv2d(1,1,(1,2))#[in_channels,out_channels,int, kernel_size]
conv1.weight=torch.nn.Parameter(w1)#torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数
#网络2
conv2=torch.nn.Conv2d(1,1,(2,1))
conv2.weight=torch.nn.Parameter(w2)
'''
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
conv11=corr2d(pic1,w1)
conv12=corr2d(pic1,w2)
plt.subplot(132).set_title('图1使用卷积核为(1,-1)结果')#y1.shagpe:(1, 1, 7, 11)
plt.imshow(conv11.squeeze(),cmap='gray')
plt.subplot(133).set_title('图1使用卷积核为(1,-1).T结果')
plt.imshow(conv12.squeeze(),cmap='gray')
plt.show()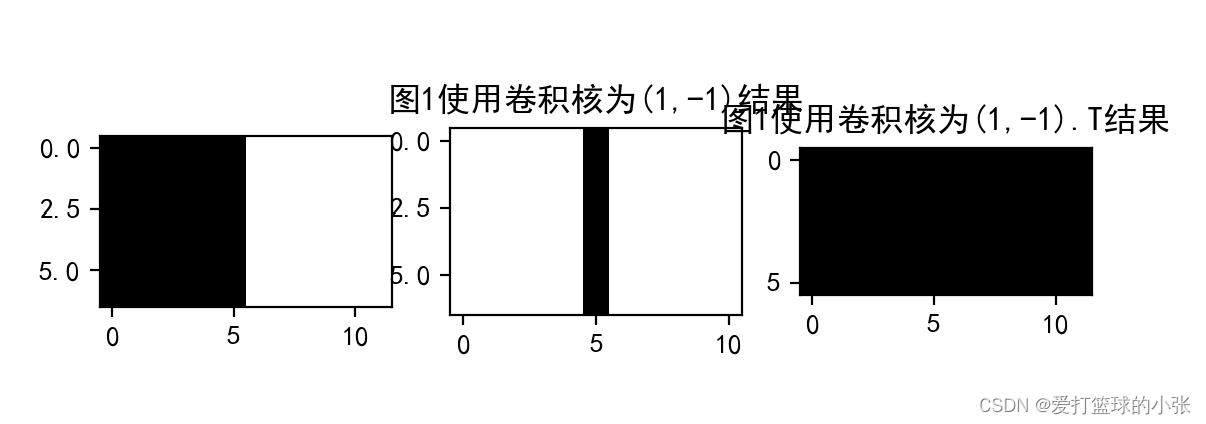
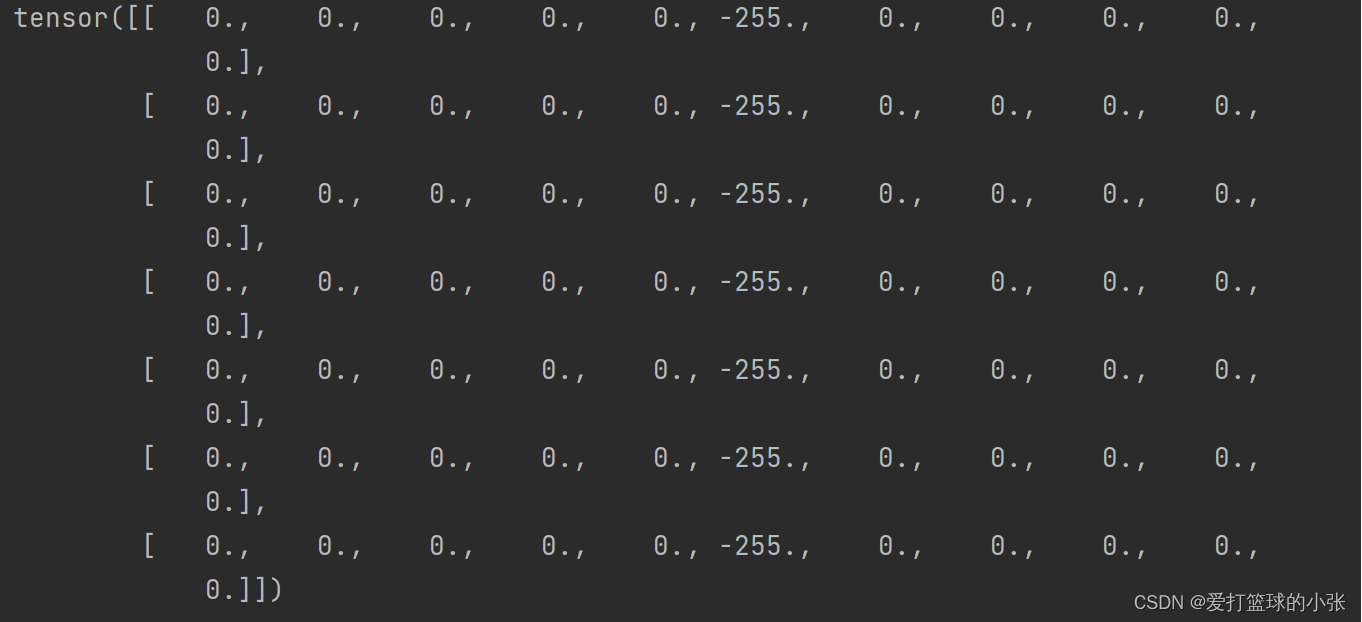
嗯?怎么是两边是白色,酷酷寻找哪里出错了,不对劲啊,将conv11的值打印出来,似乎知道了答案:它是一种映射啊
2. 图2分别使用卷积核,,输出特征图
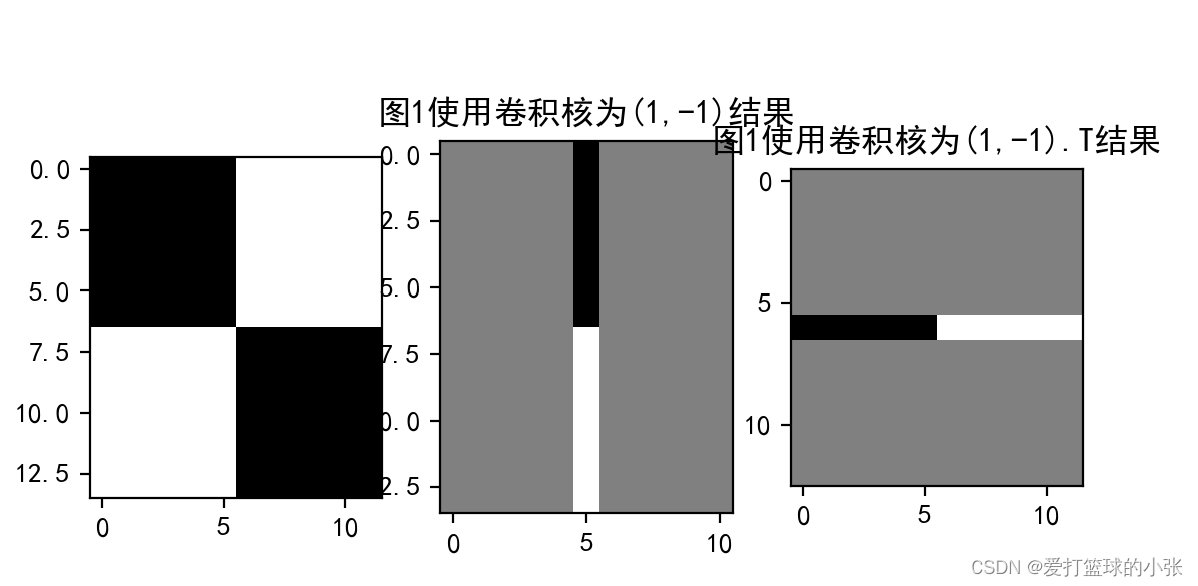
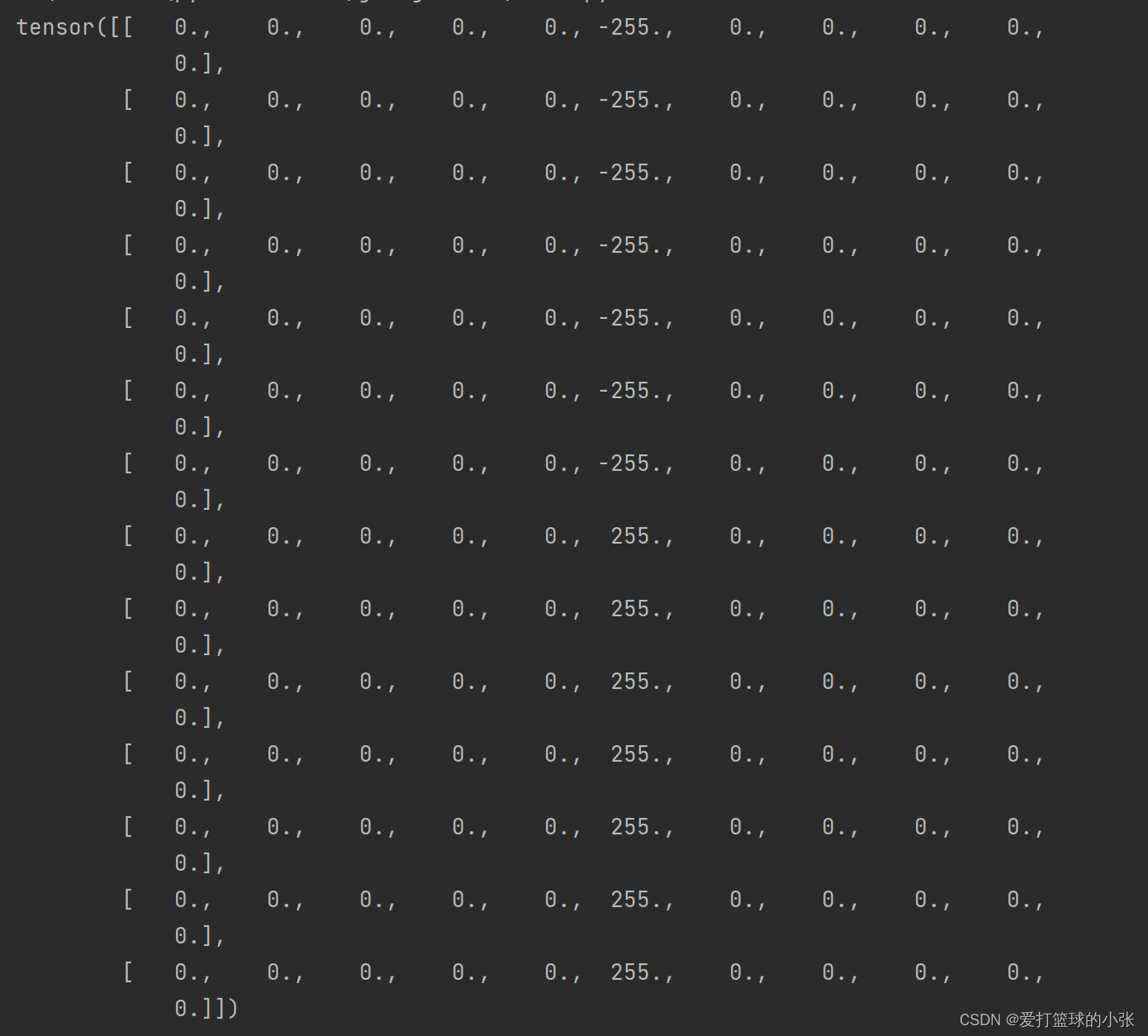
这里出现了灰色,想起老师发的博客,这下就明白了吧,它是从【-255,255】映射成黑到白,所以在0的时候就显得灰了呗。~【精选】【NNDL作业】图像锐化后,为什么“蒙上了一层灰色”?_在matlab图像处理过程中,double型图像灰度值出现负数的原因-CSDN博客
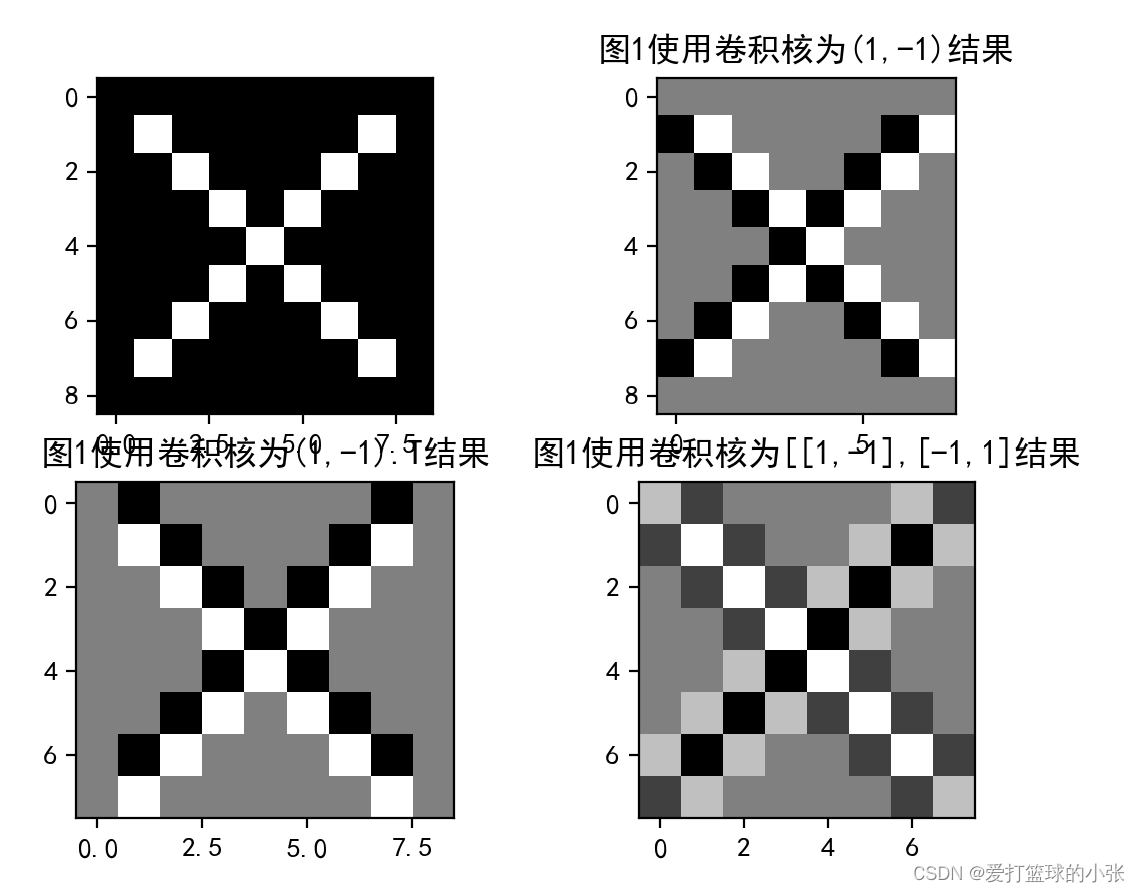
3. 图3分别使用卷积核,, ,输出特征图
,输出特征图
pic3=torch.zeros((9,9))
for i in range(9):
for j in range(9):
if (i==j or j+i==8)and i!=0 and i!=8:
pic3[i][j]=255
plt.subplot(2,2,1)
plt.imshow(pic3,cmap='Greys_r')#您将灰度值设置为1或255时,它们都对应于白色,因为在'Greys_r'颜色映射中,这两个值都位于灰度值的范围的最右侧。
#plt.subplot(2,3,3)
#plt.imshow(pic3,cmap='Greys_r')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
#卷积核的设置
#[1, 1, 2, 1]是[out_channels, in_channels, kernel_size[0], kernel_size[1]]
w1 = torch.Tensor([[1,-1]])
w2 = torch.Tensor([[1],[-1]])
w3= torch.Tensor([[1,-1],[-1,1]])
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
conv11=corr2d(pic3,w1)
conv12=corr2d(pic3,w2)
conv13=corr2d(pic3,w3)
print(conv11)
plt.subplot(2,2,2).set_title('图1使用卷积核为(1,-1)结果')#y1.shagpe:(1, 1, 7, 11)
plt.imshow(conv11.squeeze(),cmap='gray')
plt.subplot(2,2,3).set_title('图1使用卷积核为(1,-1).T结果')
plt.imshow(conv12.squeeze(),cmap='gray')
plt.subplot(2,2,4).set_title('图1使用卷积核为[[1,-1],[-1,1]结果')
plt.imshow(conv13.squeeze(),cmap='gray')
plt.show()
4. 实现灰度图的边缘检测、锐化、模糊。
说到边缘检测、锐化、模糊,就得靠卷积核提取特征了。展开讲讲:
模糊滤波核:
滤波器输出的像素等于其3×3区域的像素按照高斯分布的权值加权平均,即输出的每个像素不仅受到输入像素的影响,还均匀收到其周围像素的影响,起到了平滑模糊的效果。

锐化滤波核:
和模糊相反,锐化是放大相邻像素之间差异的一种手段,如果一个像素和周围像素较为接近但不相等,锐化后它们之间的差异会变大,有利于增强模糊的细节。
下图是具有一阶提升系数的拉普拉斯锐化滤波核

边缘检测:
卷积核内所有的值求和为0,这是因为边缘的区域,图像的像素值会发生突变,与这样的卷积核做卷积会得到一个不为0的值。而非边缘的区域,像素值很接近,与这样的卷积核做卷积会得到一个约等于0的值。检测分上边,下边,左边,右边,斜边,中间……
这说起来卷积核就太多了,分很多算子,具体看接下来的内容。
这三个的代码如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
from torch.autograd import Variable
from PIL import Image
file_path = '7.jpg'
im = Image.open(file_path).convert('L') # 读入一张灰度图的图片convert('L')表示转换为灰度图像
im = np.array(im, dtype='float32') # 将其转换为一个矩阵
im = torch.from_numpy(im.reshape((im.shape[0], im.shape[1])))
print(im)
plt.subplot(2,2,1)
plt.imshow(im,cmap='Greys_r')#您将灰度值设置为1或255时,它们都对应于白色,因为在'Greys_r'颜色映射中,这两个值都位于灰度值的范围的最右侧。
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
w1 = torch.Tensor([[0.0625, 0.125, 0.0625],
[0.125, 0.25, 0.125],
[0.0625, 0.125, 0.0625]])
w2 = torch.Tensor([[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]])
w3 = torch.Tensor([[1, 0, -1],
[2,0, -2],
[1, -0, -1]])
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if Y[i][j] > 255:
Y[i][j] = 255
if Y[i][j] < 0:
Y[i][j] = 0
return Y
conv11=corr2d(im,w1)
conv12=corr2d(im,w2)
conv13=corr2d(im,w3)
plt.subplot(2,2,2).set_title('模糊结果')#y1.shagpe:(1, 1, 7, 11)
plt.imshow(conv11,cmap='gray')
plt.subplot(2,2,3).set_title('锐化结果')#y1.shagpe:(1, 1, 7, 11)
plt.imshow(conv12,cmap='gray')
plt.subplot(2,2,4).set_title('左边缘检测结果')#y1.shagpe:(1, 1, 7, 11)
plt.imshow(conv13,cmap='gray')
plt.show()
#*运算是对应位置的单个元素相乘。内部是这个运算符
没加以下代码之前
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if Y[i][j] > 255:
Y[i][j] = 255
if Y[i][j] < 0:
Y[i][j] = 0

加上代码之后:
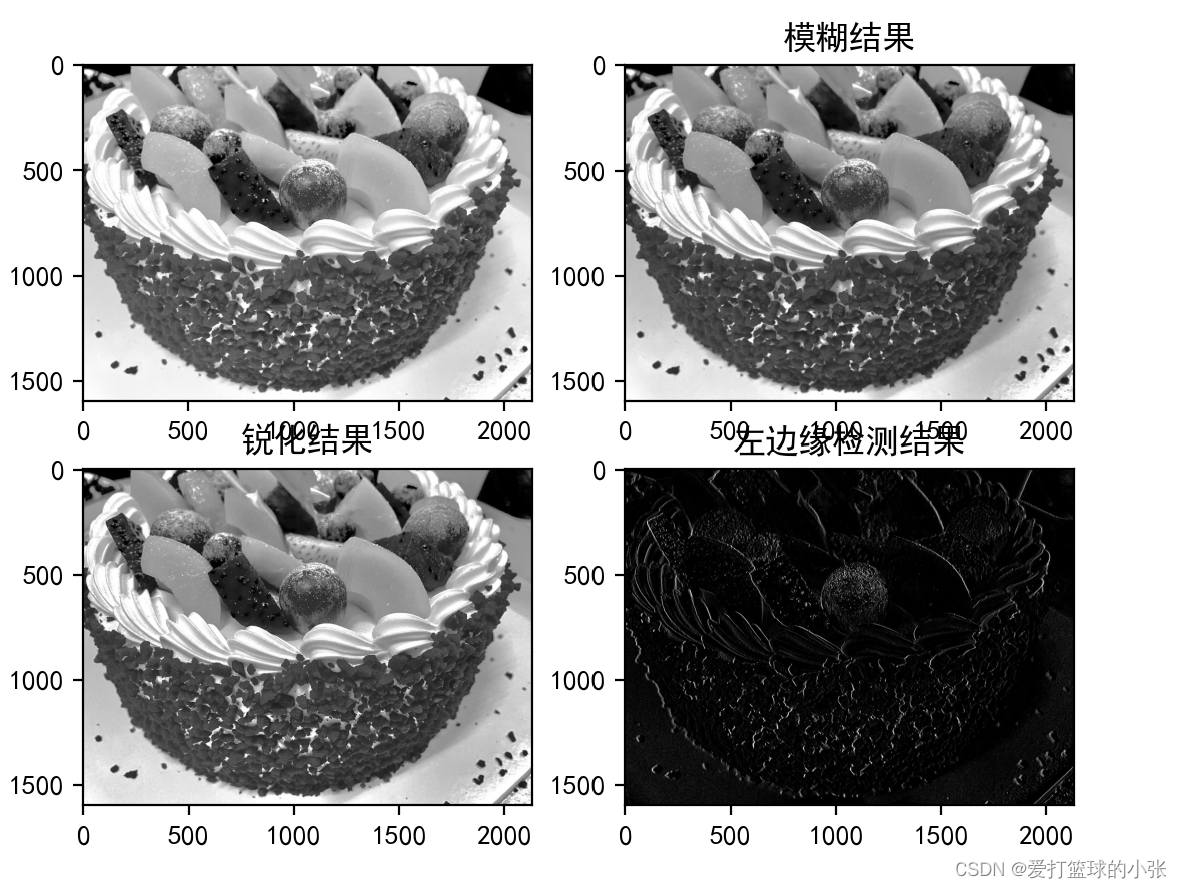
运行时间还挺长,电脑的脑瓜子又嗡嗡响了。
5. 总结不同卷积核的特征和作用。
(实例来源):Image Kernels explained visually
参考:https://blog.csdn.net/m0_49963403/article/details/129649444
模糊:
像素值求平均值,使得像素变化更加平缓
卷积核:
 等等……
等等……
锐化:
这类卷积核的作用是凸显像素值有变化的区域,使得本来像素值梯度就比较大的区域(边缘区域)变得像素值梯度更大。在边缘检测中,卷积核的设计要求卷积核内的所有值求和为0,这里的要求刚好相反,要求卷积核内的所有值应该不为0,凸显出像素值梯度较大的区域
卷积核
或:

等等……
边缘检测:
卷积核内所有的值求和为0,这是因为边缘的区域,图像的像素值会发生突变,与这样的卷积核做卷积会得到一个不为0的值。而非边缘的区域,像素值很接近,与这样的卷积核做卷积会得到一个约等于0的值。

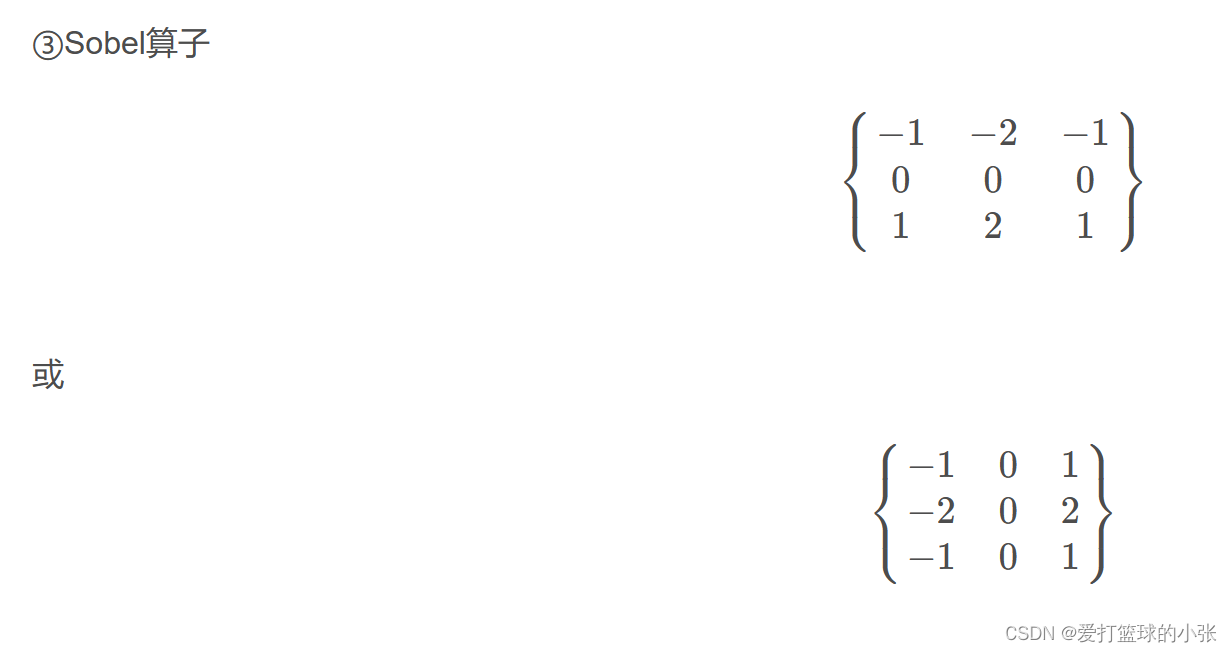
还有:
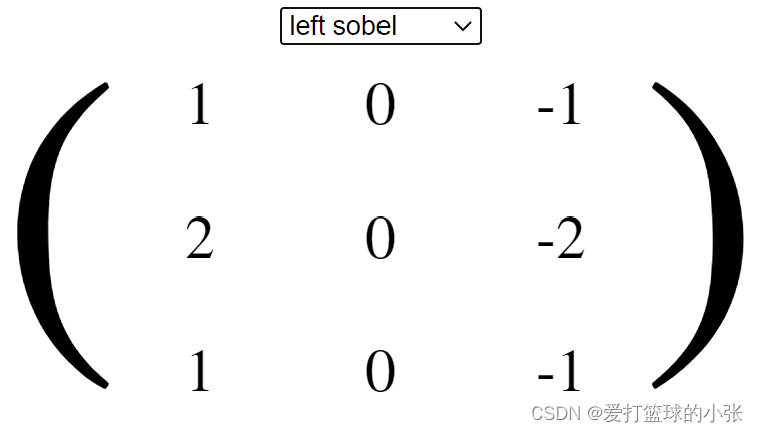
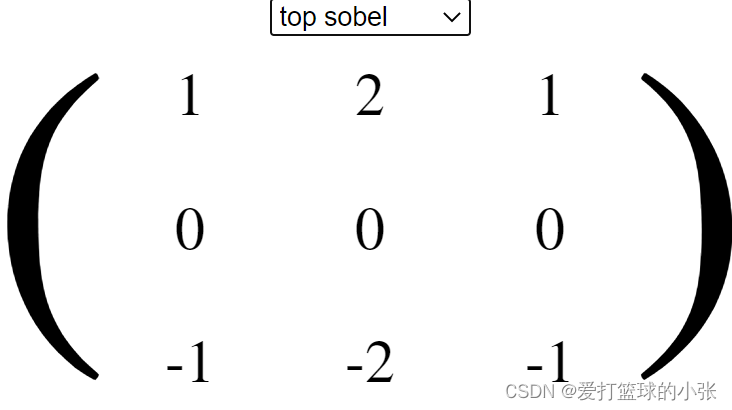

浮雕:
(这个是从同学的博客里瞟来滴)Emboss滤波器常用于检测图像的边缘和轮廓,能够有效地增强图像的高频信息(边缘和轮廓),并保留图像的低频信息(图像内容),强调给定方向上的像素差异带来的深度错觉,下图是左上角到右下角的差异。
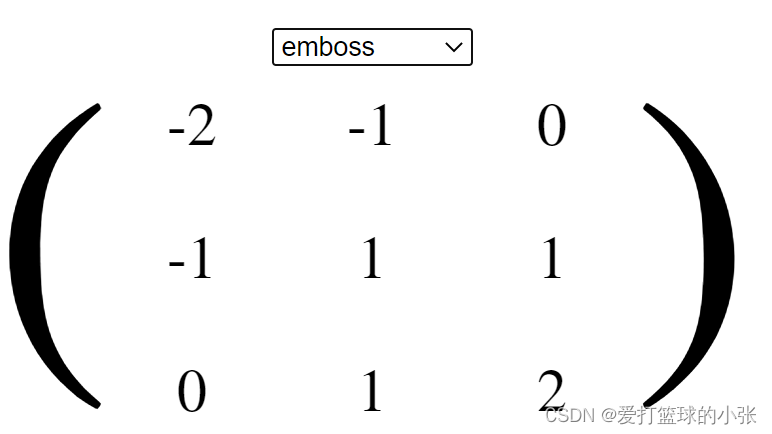

轮廓:
突出显示像素值的巨大差异

三、总结
【注意】:感觉其实咱们学的卷积神经网络,就是不断训练学这些卷积核取什么值,然后提取一定的特征,然后根据学到的参数去分类或回归得到数量和位置等。
【卷积核的规则】
1.卷积核的大小一般是奇数,这样的话它是按照中间的像素点中心对称的,所以卷积核一般都是3×3,5×5或者7×7。有中心了,也有了半径的称呼,例如5×5大小的核的半径就是2。
2.卷积核所有的元素之和一般要等于1,这是为了原始图像的能量(亮度)守恒。其实也有卷积核元素相加不为1的情况。
3.如果滤波器矩阵所有元素之和大于1,那么滤波后的图像就会比原图像更亮,反之,如果小于1,那么得到的图像就会变暗。如果和为0,图像不会变黑,但也会非常暗。
4.对于滤波后的结构,可能会出现负数或者大于255的数值。对这种情况,我们将他们直接截断到0(小于0时)或255(大于255时)即可。对于负数,也可以取绝对值。
【仍有一个疑问】当时直接调conv2d类的时候在第一个图片的卷积核为[[1],[-1]]时,卷积后我感觉理论上应该是全黑的,不知道为啥一半黑一半白,所以我最后选择的是自定义函数,希望在接下来的实验中能够找到答案吧!
【关于代码】可能是参考的代码不一样,导致了黑白前后颠倒了,后来的后来,终于发现了问题
plt.imshow(im,cmap='Greys_r')与plt.imshow(im,cmap='Gray_r')区别:
'Greys_r' 常常用于显示灰度图像,其中较低的值对应于较暗的颜色,较高的值对应于较亮的颜色。'_r' 表示 colormap 的翻转版本,所以 'Greys_r' 是 'Greys' 的反转版本,将较亮的值显示为白色,较暗的值显示为黑色。
实践证明'Greys_r与Gray对应,效果相同,所以这俩东西正好映射的相反呗~
要确保两次调用 plt.imshow 使用相同的颜色映射以获得一致的结果,您可以在两次调用中都使用 'Greys_r' 或都使用 'Gray_r',以避免颜色映射不一致。
自己动手实践的时候真的会遇到各种各样的问题,希望自己不断不断将这些妖魔鬼怪打跑!
【小试牛刀】:
3D Visualization of a Convolutional Neural Network

四、引用
为什么神经网络越深,提取的特征越高级_深度学习中 ,网络层增加对 特征提取的影响_Yuezero_的博客-CSDN博客
https://www.sohu.com/a/343722270_468740
https://blog.csdn.net/superdont/article/details/127124819
https://blog.csdn.net/weixin_38481963/article/details/109924004
Conv2d — PyTorch 2.1 documentation
【精选】人工智能基础 作业4_bottom sobel-CSDN博客















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









