






grep + awk
一、grep命令
1.1 基本格式
grep [选项]… 查找条件 目标文件
1.2 常用选项
| 选项 | 功能 |
|---|---|
| -m [ x ] | 匹配x次 后停止,x为具体数字 |
| -v | 取反 |
| -i | 忽略字符大小写 |
| -n | 显示匹配的 行号 |
| -c | 统计匹配的行数 |
| -o | 仅显示匹配到的字符串 |
| -q | 静默模式,不输出任何信息 |
| -A x after | 匹配内容的后x行 |
| -B x before | 前x行 |
| -C x context | 前后各x行 |
| -e | 实现多个选项间的逻辑or关系 |
| -w | 匹配 整个单词 |
| -E | 使用扩展正则表达式,相当于egrep |
| -F | 不支持正则表达式,相当于fgrep |
| -r | 递归目录,但不处理软链接 |
| -R | 递归目录,但处理软链接 |
| -f file | file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件 |
| -color=auto | 对匹配到的文本着色显示 |
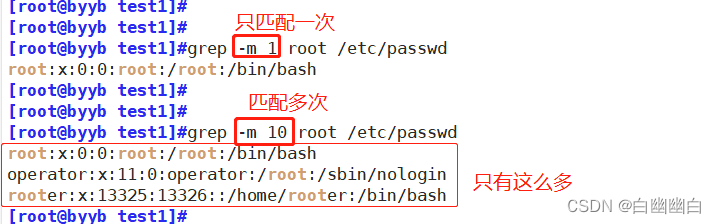
-m 匹配#次后停止
grep -m 1 root /etc/passwd #多个匹配只取第一个
-v 取反
grep -Ev '^[[:space:]]*#|^$' /etc/fstab#非空行

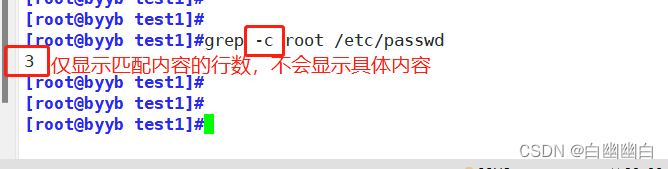
-c 统计匹配的行数
grep -c root /etc/passwd #统计匹配到的行数
-A x after 匹配内容的后x行
grep -A3 root /etc/passwd #匹配到的行后3行业显示出来

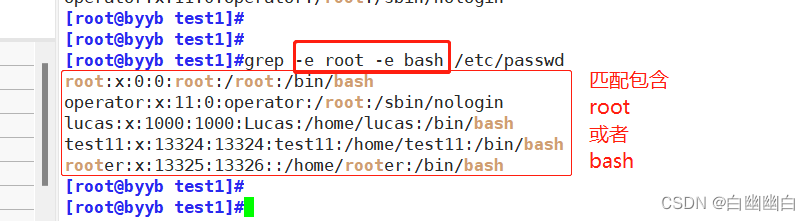
-e 实现多个选项间的逻辑or关系
grep -e root -e bash /etc/passwd #包含root或者包含bash 的行
grep -E root|bash /etc/passwd #使用扩展正则表达式的写法
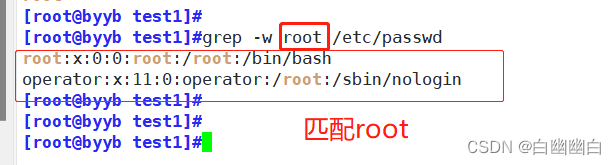
-w 匹配整个单词
grep -w root /etc/passwd
二、awk命令
2.1 awk工作原理
+-----------------+
| 输入文件 |
| 或标准输入 |
+-----------------+
|
v
+-----------------+
| 分割输入行 |
+-----------------+
|
v
+-----------------+
| 匹配模式 |
+-----------------+
|
v
+-----------------+
| 执行动作 |
+-----------------+
|
v
+-----------------+
| 处理下一行 |
+-----------------+
|
v
循环结束
-
读取输入:AWK首先读取输入文件或从标准输入接收输入;
-
分割输入:AWK默认将输入行分割成字段,并使用空格或制表符作为字段分隔符;
-
匹配模式:AWK使用模式匹配来确定需要处理的行,可以使用正则表达式或其他条件来指定匹配的行。如果没有指定模式,AWK将默认匹配所有行;
-
执行动作:当输入行与模式匹配时,AWK执行相应的动作;
-
处理下一行:一旦完成当前行的处理,AWK继续处理下一行,重复上述步骤。
2.2 awk命令格式
awk默认使用正则表达式 所以不需要\
#命令格式#
awk [选项] '[模式匹配条件]{处理动作 }' 文件1 文件2..
2.2.1 常用选项
#选项#
#一般只有-F常用
-F 指定分隔符,默认的分隔符是若干个连续空白符,默认的时候可不写
-v 自定义变量
-f 脚本
awk '/匹配条件/{ print $x }'
#匹配条件可以不写 x为任意数字
2.2.2 模式匹配条件
#模式匹配条件格式#
/ 匹配条件 /
# 起始 结束
#/ / 一定要加
2.2.3 处理动作
#操作#
#常用的 只有 print
awk '{ print $1 }'
awk '{ print $1 $2 $3 .... }'
#awk会自动压缩空格,不需要再写tr -s ' '
2.3 awk常用内置变量
| 内置变量 | 功能 |
|---|---|
| FS | 指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v “FS=:” |
| OFS | 在输出中字段之间的分隔符,默认为空格 |
| ORS | 在输出中记录之间的分隔符,默认为换行符 |
| NF | 字段数量,表示当前记录中的字段数 |
| NR | 记录编号,表示当前正在处理的输入记录的行号 |
| RS | 表示用于分割记录的字符,默认为换行符 |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 当前正在处理的文件的名称 |
2.4.1 指定分隔符 -F
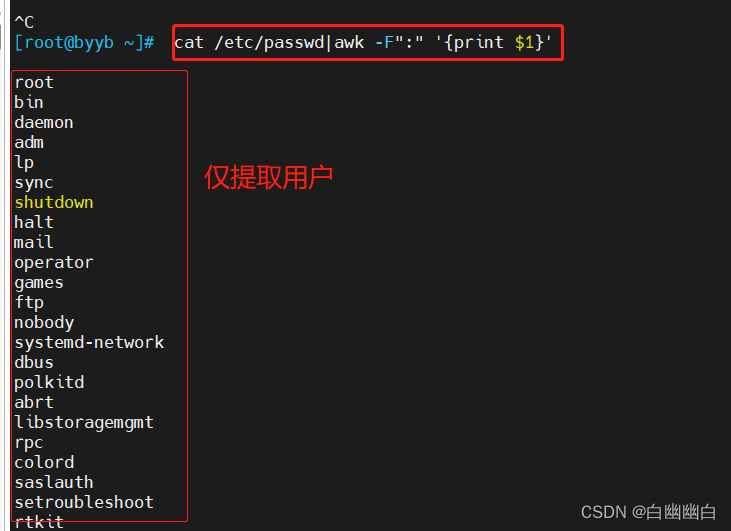
示例一:打印/etc/passwd所有用户名
指定':'为分隔符
cat /etc/passwd|awk -F":" '{print $1}'
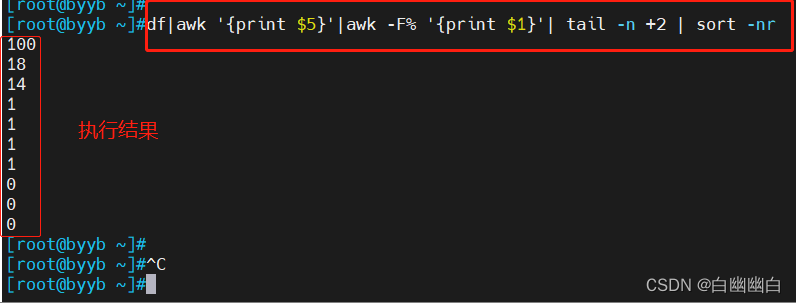
示例二:打印磁盘已经使用情况,去除%并且从第二行开始倒序显示
df|awk '{print $5}'|awk -F% '{print $1}'|tail -n +2 |sort -nr
2.4.2 BEGIN 和 END
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
awk再处理指定的文本,之后再执行END模式中指定的动作;
END{ } 语句块中,往往会放入打印结果等语句
awk 'BEGIN {x=0};/\/bin\/bash$/;{x++};END{print x}' /etc/passwd
{x=0} # 在开始之前,初始化变量x为0
/\/bin\/bash$/ # 使用正则表达式匹配包含"/bin/bash"的行
{x++} # 每匹配到一行,变量x加1
END {print x} # 结束后,输出变量x的值

2.4.3 NR
NR==用于比较NR的值,而NR=用于给NR赋值
示例一:打印特定行号的行的内容
awk 'NR==3' test.txt

示例二:计算输入文件的总行数
awk 'END {print NR}' test.txt

示例三:奇偶数行
NR%2==1取奇数行
NR%2==0取偶数行
awk 'NR%2==1 {print $2}' test.txt #奇数行提取
awk 'NR%2==0 {print $2}' test.txt #偶数行提取
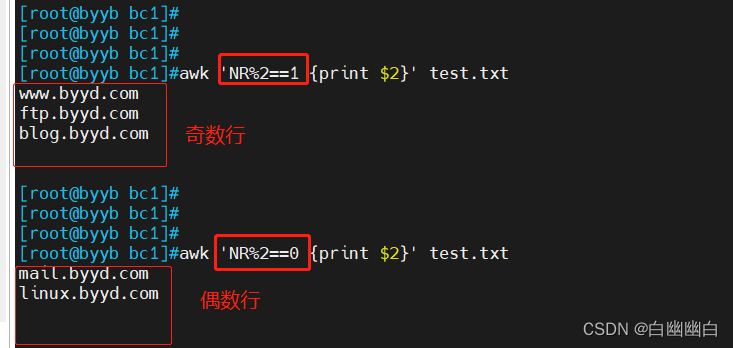
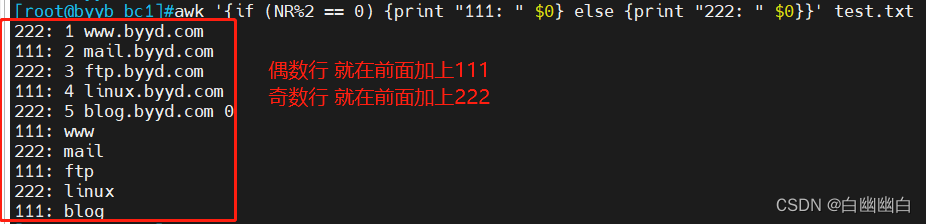
示例四:多行处理
awk '{if (NR%2 == 0) {print "111: " $0} else {print "222: " $0}}' test.txt
2.4.4 NF
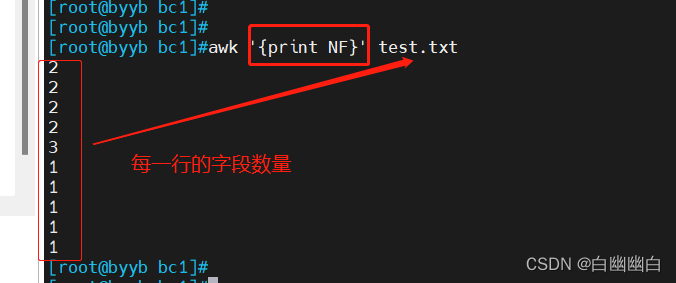
示例一:打印每一行的字段数量:
awk '{print NF}' test.txt
示例二:打印每一行的最后一个字段
awk '{print $NF}' test.txt
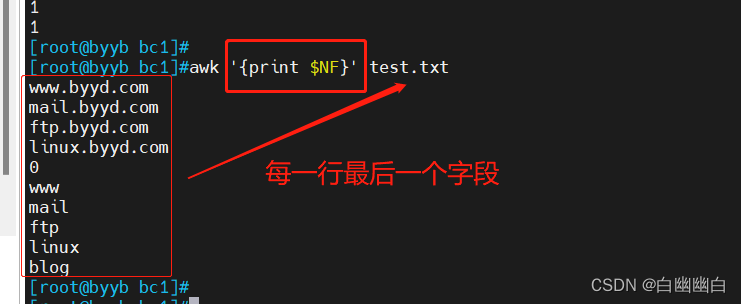
示例三:根据字段数量执行不同的操作
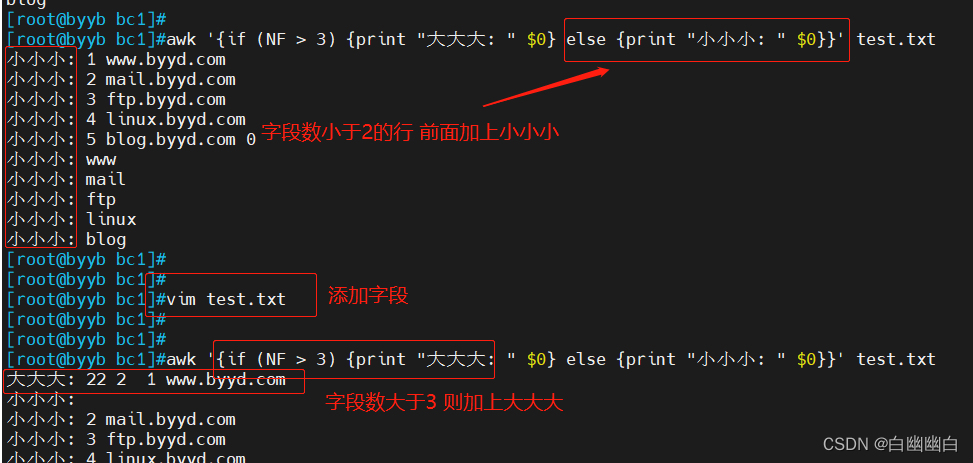
awk '{if (NF > 3) {print "大大大: " $0} else {print "小小小: " $0}}' test.txt
2.5 awk实例
2.5.1 统计/etc/fstab文件中每个文件系统类型出现的次数
cat /etc/fstab |awk '/^[^#]/{print}'|awk '{print $3}'|sort |uniq -c

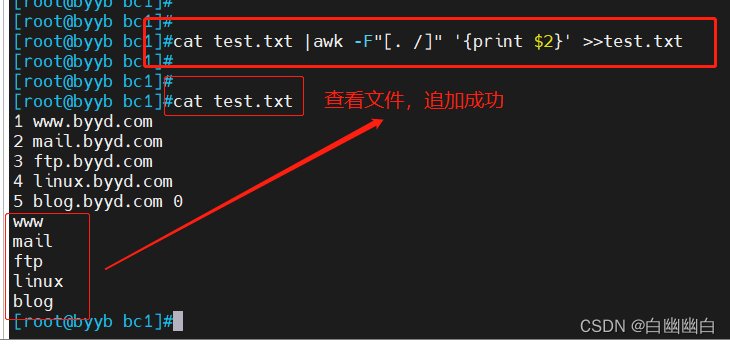
2.5.2 提取主机名并放入原文件
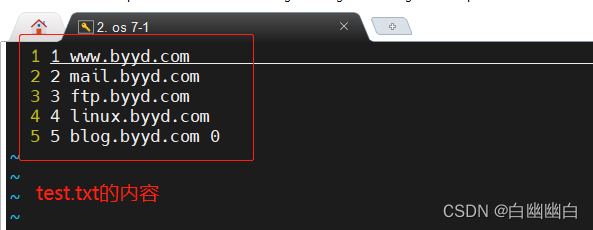
cat test.txt |awk -F"[. /]" '{print $2}' >>test.txt
















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











