







图像增强/ImageDataGenerator
写在最前:未经授权不得转载或直接复制使用。初学者,对于一些问题的理解可能不是很到位,请多多指教或者一起讨论~
官方文档直达
代码
# Data augmentation
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=20,
width_shift_range=0.1, # Shift picture
height_shift_range=0.1,
horizontal_flip=True, # Might has flip picture but there is no upside down thing
fill_mode='nearest') # Fill missing pixels
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
horizontal_flip=True, fill_mode='nearest')
train_gen = train_datagen.flow(X_train, y_train_cate, batch_size=256)
valid_gen = valid_datagen.flow(X_valid, y_valid_cate, batch_size=256)
print(len(train_gen))
print(len(valid_gen))
注意
使用图像增强后,数据来自生成器,在model.fit()方法中要使用steps_per_epoch而不是batch_size。model.fit()代码如下:
# Change learning_rate auto
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', patience=10, mode='auto')
# Checkpoint
checkpoint_path = "training_1/cp.ckpt"
checkpoint_dir = os.path.dirname(checkpoint_path)
# Create a callback that saves the model's weights
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1)
earlystopping = EarlyStopping(monitor='val_accuracy', verbose=1, patience=30)
# Train the model with the new callback
history = model_vgg11.fit(train_gen,
validation_data=valid_gen,
epochs=200,
# Not specify the batch_size since data is from generators (since they generate batches)
steps_per_epoch=len(train_gen), # Total number of steps (batches of samples) before a epoch finished,
# default is the number of samples (50000) divided by the batch size (32)
validation_steps=len(valid_gen),
callbacks=[cp_callback, reduce_lr, earlystopping]) # callbacks=[cp_callback] Pass callback to training
使用图像增强的原因
- 使用图像增强的原因要具体数据具体分析,考虑到CIFAR-100中每个子类只有500张图像,我们使用数据增强来增加输入图像;
- 当我们没有足够的训练图像时,这也是一个很好的方法来减少过拟合;
- 还考虑到日常生活中一些可能的输入图像,例如可能会输入翻转、旋转或移动后的图像,使用图像增强后可以提高训练集的质量。
测试ImageDataGenerator对象的flow方法中batch_size参数
在ImageDataGenerator对象的flow方法中有一个batch_size参数,batch_size越小,flow方法生成的迭代器的长度 (len(train_gen)) 就越长。
我想知道这个参数是如何影响准确率的,调整了两个参数:
- ImageDataGenerator对象的flow方法中的batch_size
train_gen = train_datagen.flow(X_train, y_train_cate, batch_size=256)
- model.fit方法中的steps_per_epoch (这里先不解释这个参数,具体在 Keras-ImageDataGenerator的flow()中的batch_size参数,Model.fit()中的batch_size和steps_per_epoch参数的关系 这篇博文中解释)
history = model_vgg19.fit(train_gen,
validation_data=valid_gen,
epochs=200,
steps_per_epoch=352,
validation_steps=40,
callbacks=[reduce_lr, earlystopping])
做了如下测试:
| 测试 | batch_size | len(train_gen) | steps_per_epoch | 测试集上的准确率 |
|---|---|---|---|---|
| 测试1 | 128 | 352 | 352 | 0.5536 |
| 测试2 | 64 | 704 | 352 | 0.5404 |
| 测试3 | 64 | 704 | 704 | 0.5626 |
| 测试4 | 32 | 1407 | 352 | 0.5045 |
| 测试5 | 32 | 1407 | 1407 | 0.5955 |
从测试1,2,4中可以看出,在steps_per_epoch固定的情况下,batch_size越大准确率越高,但是影响不是很大。从测试2,3和测试4,5这两组测试可以看出,在batch_size固定的情况下,steps_per_epoch越大准确率越高。
总的来说,递增趋势,但是影响不大,这个参数没有什么调整的价值。但是这个结果仅仅是从我的几次测试总结出来的,只适用于这个数据和这个网络模型,并无普适性。
有兴趣可以看看这篇文章,做了关于batch_size详细的实验
来源:https://www.zhihu.com/question/32673260

但是在len(train_gen)<steps_per_epoch,会有如下警告:
WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least steps_per_epoch * epochs batches (in this case, 40 batches). You may need to use the repeat() function when building your dataset.
意思就是一定要len(train_gen)>steps_per_epoch,那么如果想用更大的steps_per_epoch去提高准确率的话,就只能在ImageDataGenerator对象的flow方法中使用更小的batch_size了。
具体分析ImageDataGenerator对象的flow方法 (转载)
分析可得,ImageDataGenerator对象的flow方法,对输入数据(imgs,ylabel)打乱(默认参数,可设置)后,依次取batch_size的图片并逐一进行变换。取完后再循环。伪代码如下
————————————————
版权声明:本文为CSDN博主「lsh呵呵」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/nima1994/article/details/80625938
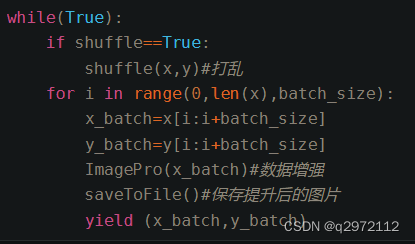
ImageDataGenerator.flow#生成的是一个迭代器,可直接用于for循环
batch_size如果小于X的第一维m,next生成的多维矩阵的第一维是为batch_size,输出是从输入中随机选取batch_size个数据
batch_size如果大于X的第一维m,next生成的多维矩阵的第一维是m,输出是m个数据,不过顺序随机 ,输出的X,Y是一一对对应的
如果要直接用于tf.placeholder(),要求生成的矩阵和要与tf.placeholder相匹配 ————————————————
版权声明:本文为CSDN博主「liming89」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liming89/article/details/110506982
只在训练集、验证集应用数据增强的原因(转载)
如何证明数据增强(Data Augmentation)有效性? - 益达的回答 - 知乎
https://www.zhihu.com/question/444425866/answer/1730208151














 3196
3196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









