一、代码部分
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
class Kmeans:
def __init__(self,k,epochs,data):
'''
:param k: 聚类族数
:param epochs: 迭代轮数
:param data: 西瓜数据集二维数组
'''
self.k = k
self.epochs = epochs
self.data = data
self.center_points = []
for i in range(self.k):
self.center_points.append(self.data[np.random.randint(0, len(self.data))])
self.center_points = np.array(self.center_points, dtype=float)
def calc_dist(self,a):
dist = (self.center_points - a)**2
mean_dists = np.mean(dist,axis=1)
return mean_dists.argmin()
def process_iter(self):
for i in range(self.epochs):
self.cluster = {}
for i in range(len(self.data)):
index = self.calc_dist(self.data[i])
if index not in self.cluster:
self.cluster[index] = [self.data[i]]
else:
self.cluster[index].append(self.data[i])
self.upgrade()
def upgrade(self):
for i in range(self.k):
self.center_points[i] = np.array(self.cluster[i]).mean(axis=0)
def get_cluster(self):
return self.cluster
def plot_scatter(self):
color = ['b','c','g','k','m','r','w','y']
for i in range(self.k):
x = np.array(self.cluster[i])[:,0]
y = np.array(self.cluster[i])[:,1]
plt.scatter(x,y,c=color[i])
print(self.center_points)
x = self.center_points[:,0]
y = self.center_points[:,1]
plt.scatter(x,y,marker='+',c='r')
plt.title('西瓜数据集4.0聚类结果'+'epoch{}'.format(self.epochs))
plt.xlabel('密度')
plt.ylabel('甜度')
plt.show()
def load_data():
data = pd.read_csv("watermelon4.0.csv")
data = pd.DataFrame(data)
print(data,data.shape)
data_t = []
len = data.shape[0]
for i in range(len):
data_t.append([data["density"][i],data["sugercontent"][i]])
return data_t
def main():
data = load_data()
kmeans = Kmeans(3,100,data)
kmeans.process_iter()
print(kmeans.get_cluster())
kmeans.plot_scatter()
if __name__ == '__main__':
main()
二、实验结果
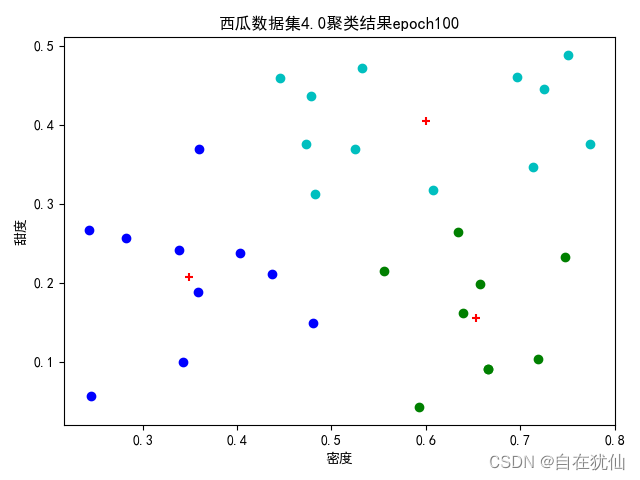
2.1 聚类(三个中心向量)
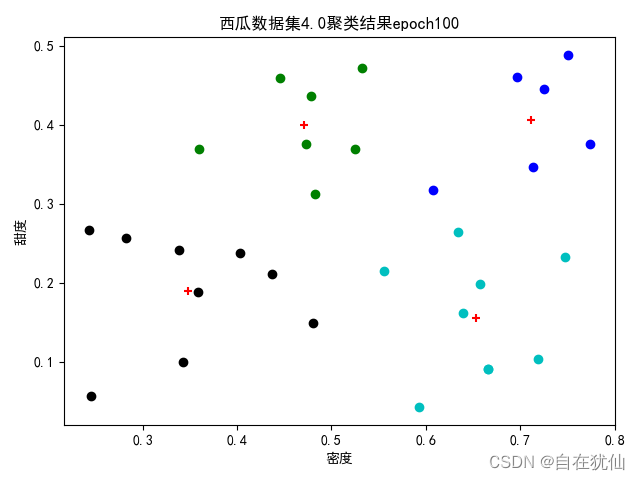
2.2 聚类(四个中心向量)























 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









