






基于强化学习 DDPG 算法实现的acc 自适应巡航控制器设计
配有说明文档
基于simulink 中的强化学习工具箱,设计agent 的奖励函数,动作空间,状态空间,训练终止条件
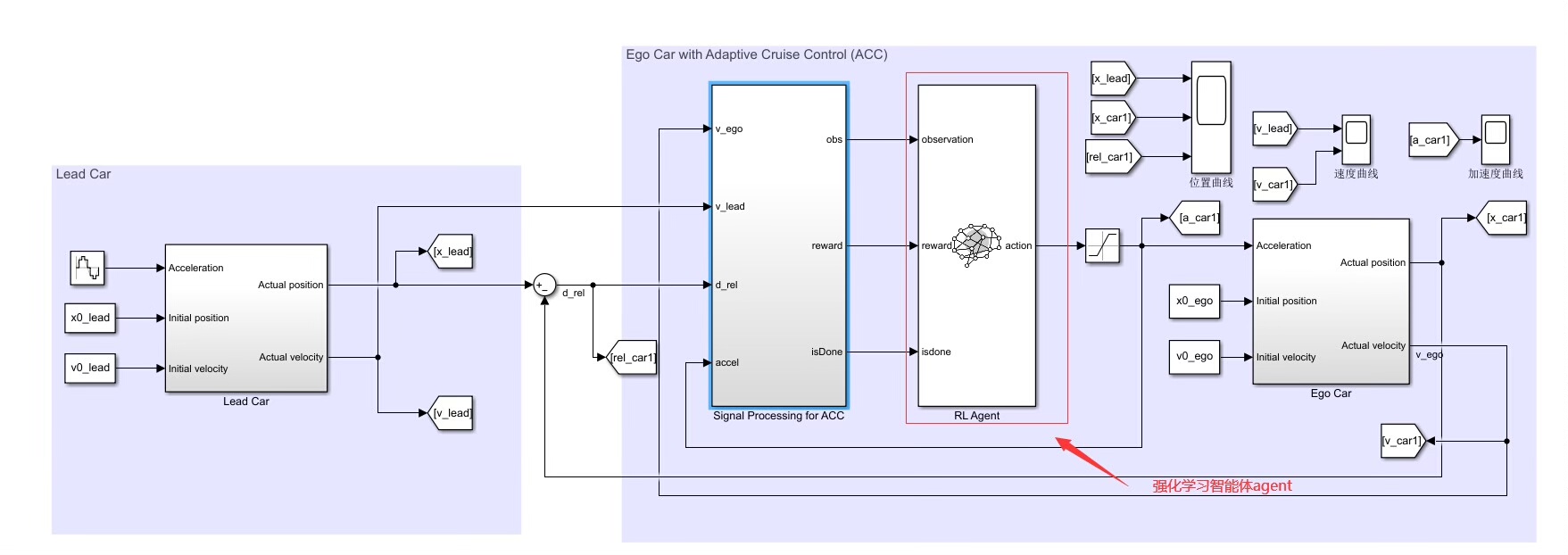
设置领航车的速度和位移曲线,然后自车的加速度基于 acc 逻辑用ddpg agent 来控制。
模型比较简单,适用于初学强化学习算法的入门资源,可改写成强化学习的车辆队列协同控制。
ID:1220740453377470
吕~小布

基于强化学习 DDPG 算法实现的自适应巡航控制器设计
引言:
自动驾驶技术的快速发展使得无人驾驶车辆成为现实,而自适应巡航控制器是其中的一个重要组成部分。本文基于强化学习 DDPG 算法,设计了一个基于acc逻辑的自适应巡航控制器。我们采用了Simulink中的强化学习工具箱,通过设置agent的奖励函数、动作空间、状态空间和训练终止条件来达到自动驾驶的目标。本文以领航车的速度和位移曲线为基础,利用DDPG算法中的agent来控制自车的加速度,实现自适应巡航控制。这个模型相对简单,适用于初学强化学习算法的入门资源,并且可以进一步改写成强化学习的车辆队列协同控制。
-
引言
自适应巡航控制器是一种智能驾驶系统,通过感知环境、学习和规划等过程,能够智能地控制车辆的加速度、制动和转向等动作,以实现自动驾驶的功能。强化学习是一种经典的人工智能技术,通过让智能体(如无人驾驶车辆)与环境进行交互学习,并通过奖励信号来指导行为的选择,从而达到优化控制策略的目的。DDPG(Deep Deterministic Policy Gradient)算法是强化学习中的一种重要算法,它结合了深度学习和策略梯度方法,能够处理连续动作空间的问题,因此非常适用于自适应巡航控制器的设计。 -
强化学习 DDPG 算法概述
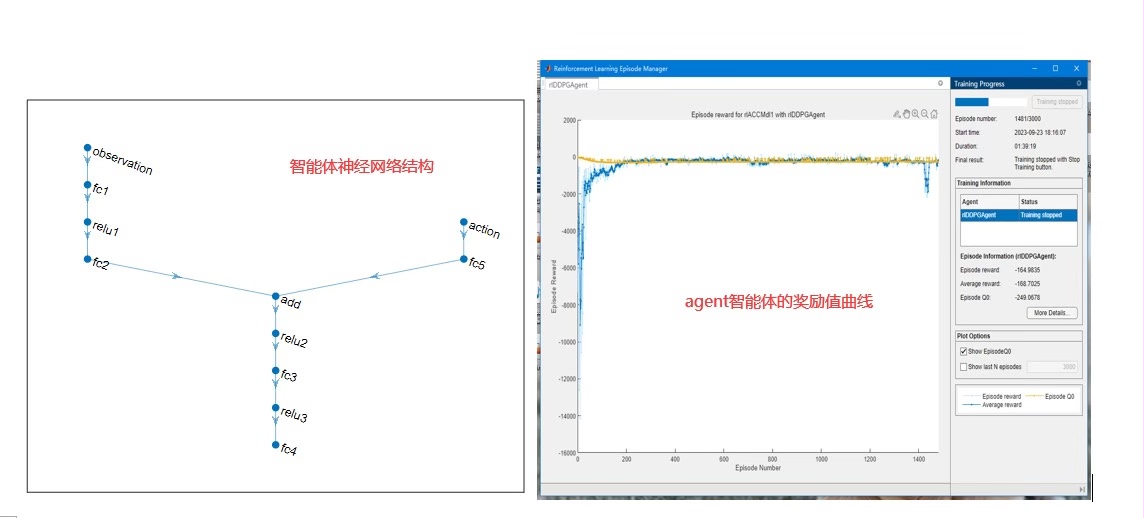
DDPG算法是由DeepMind提出的一种基于策略梯度的深度强化学习算法,它采用了一对actor网络和critic网络来近似Q函数和策略函数,并通过反向传播算法来更新网络参数。在DDPG算法中,actor网络负责选择动作,critic网络负责评估动作的价值,两个网络通过梯度下降法进行参数更新。DDPG算法的关键在于离线经验回放和目标网络的引入,它们能够提高算法的稳定性和收敛性。 -
Simulink 中的强化学习工具箱
Simulink是一款功能强大的建模和仿真软件,它集成了丰富的工具箱,包括强化学习工具箱。强化学习工具箱提供了一系列用于开发强化学习算法的函数和组件,可以方便地进行agent的设计、训练和评估。在本文中,我们利用Simulink中的强化学习工具箱来实现DDPG算法,并设计出一个自适应巡航控制器。 -
agent 的设计
在设计agent之前,我们需要确定奖励函数、动作空间、状态空间和训练终止条件。奖励函数是指给予智能体的某个动作一个评价,反映了该动作对智能体的行为目标的贡献程度。动作空间是指智能体可以选择的动作的范围,而状态空间是指智能体可以观察到的环境的状态。训练终止条件是指训练过程何时终止,通常是达到一定的训练轮数或者满足某种性能指标。 -
自适应巡航控制器的实现
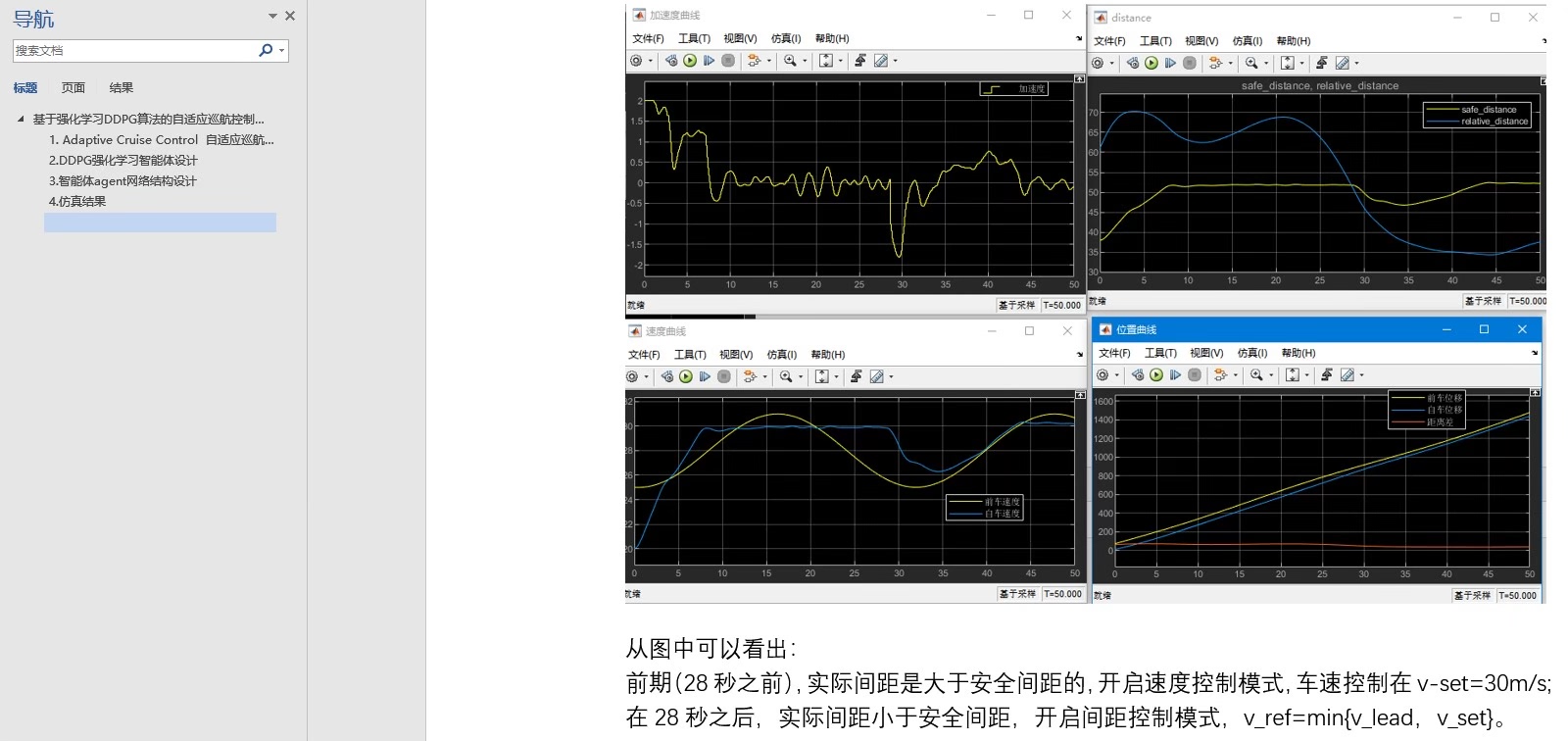
在自适应巡航控制器的实现中,我们以领航车的速度和位移曲线为基础,通过DDPG agent控制自车的加速度。具体来说,我们首先需要设置领航车的速度和位移曲线,然后根据acc逻辑来计算自车应该采取的加速度。接着,我们将这个加速度作为agent的输入,并根据agent的输出来调整自车的行为。通过不断地迭代训练和优化,最终可以得到一个能够自适应地控制巡航车速度和位移的控制器。 -
模型简化与拓展
本文设计的自适应巡航控制器模型相对简单,适用于初学强化学习算法的入门资源。然而,这个模型可以进一步改写成强化学习的车辆队列协同控制模型。在车辆队列协同控制中,多辆车之间通过智能体之间的通信和合作,实现更高效、更安全的巡航控制。通过引入协同控制算法,可以使车辆之间更好地协调行驶,减少拥堵和事故的发生。
结论:
本文基于强化学习 DDPG 算法,设计了一个基于acc逻辑的自适应巡航控制器。通过Simulink中的强化学习工具箱,我们设计了agent的奖励函数、动作空间、状态空间和训练终止条件。在自适应巡航控制器的实现中,我们以领航车的速度和位移曲线为基础,利用DDPG agent来控制自车的加速度。这个模型相对简单,适合初学强化学习算法的入门资源,并且可以进一步改写成强化学习的车辆队列协同控制模型。通过不断地迭代训练和优化,我们可以得到一个能够自适应地控制巡航车速度和位移的控制器,为自动驾驶技术的发展提供了重要的参考和借鉴。
【相关代码,程序地址】:http://fansik.cn/740453377470.html
















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









