







博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈: pytorch 深度学习 pyqt5图像界面 mnist数据集训练 LeNet-5深度学习卷积神经网络模型
(1)点击打开文件按钮,选择要识别的图片,然后点击识别按钮,右侧显示识别的结果
2、项目界面
(1)点击打开文件按钮,选择要识别的图片,然后点击识别按钮,右侧显示识别的结果
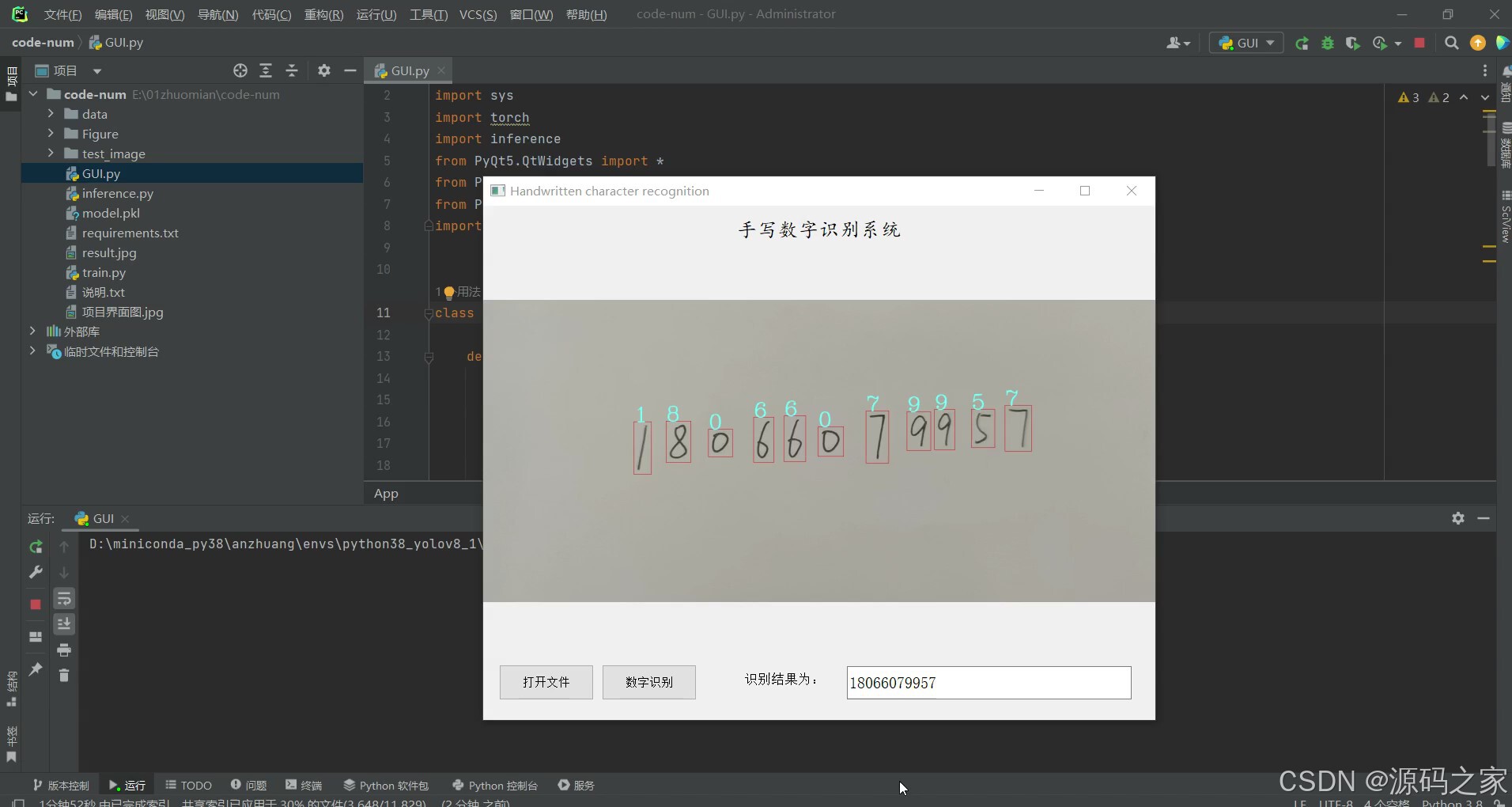
(2)点击打开文件按钮,选择要识别的图片,然后点击识别按钮,右侧显示识别的结果
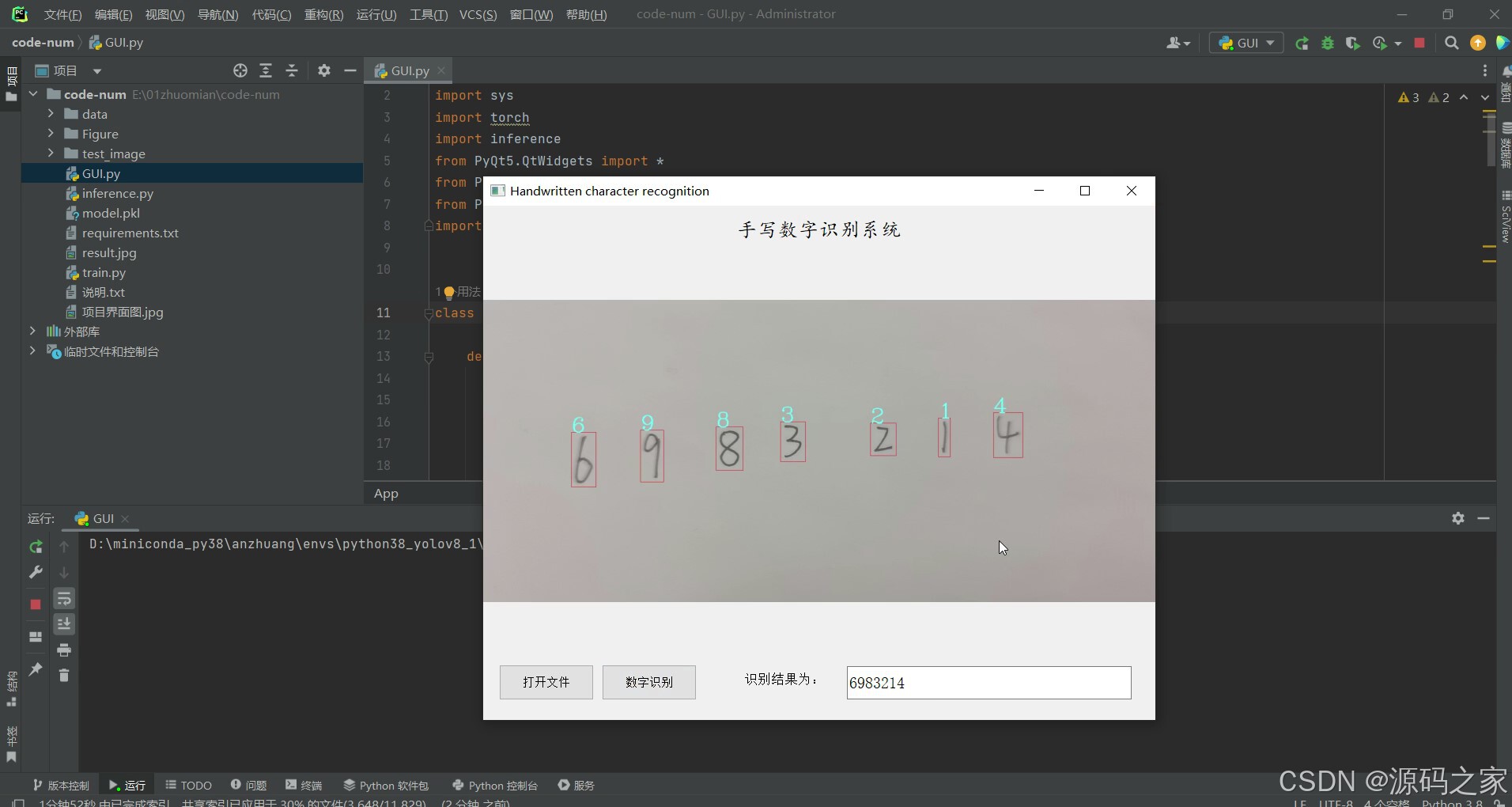
(3)点击打开文件按钮,选择要识别的图片,然后点击识别按钮,右侧显示识别的结果
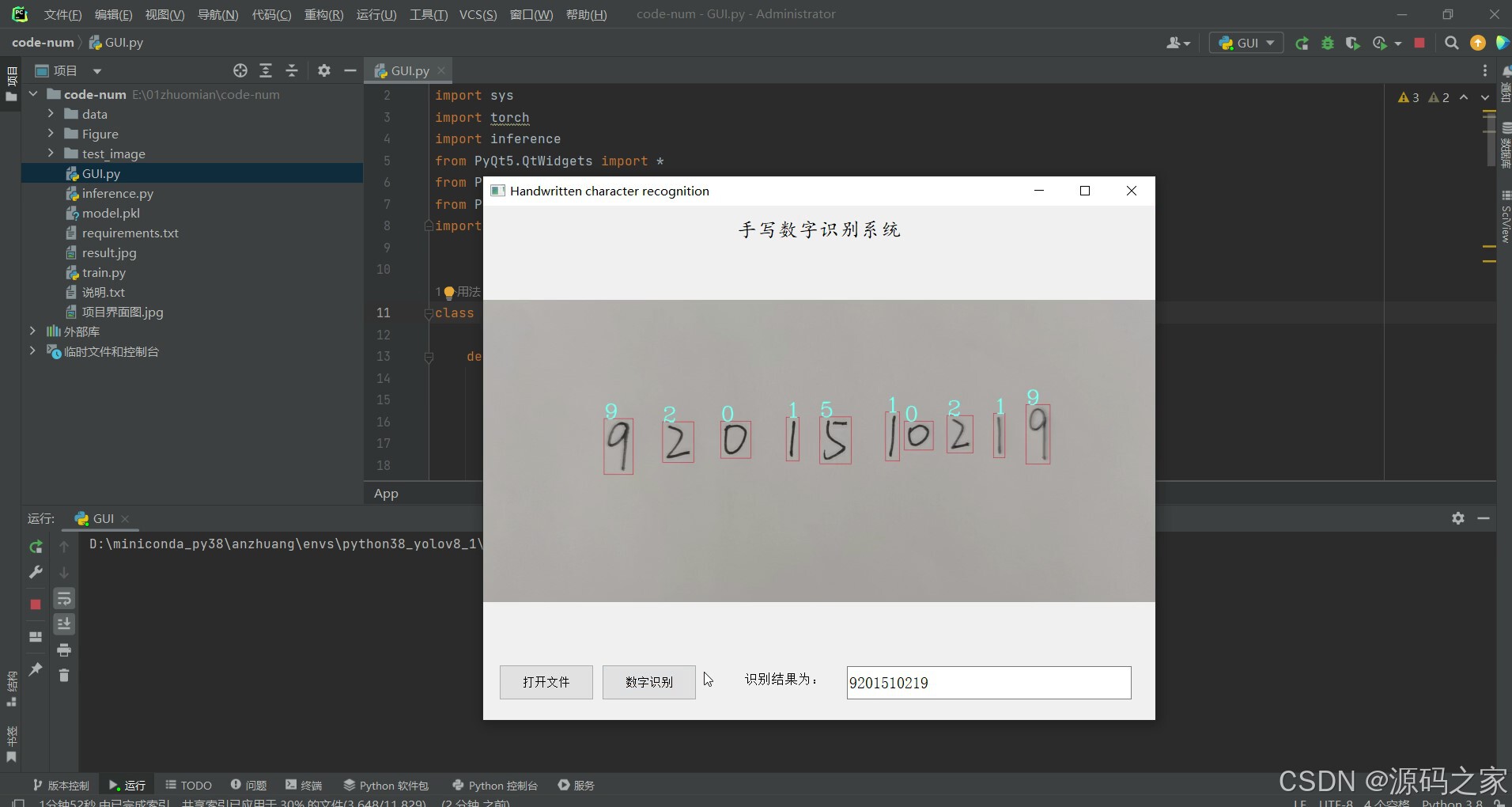
3、项目说明
本项目是基于 PyTorch 深度学习框架开发的手写识别系统,核心采用 LeNet-5 卷积神经网络模型,通过 MNIST 数据集完成模型训练,搭配 PyQt5 图像界面与 OpenCV 图像处理技术,构建 “图片导入 - 预处理 - 模型识别 - 结果展示” 的完整流程,可应用于手写数字学习辅助、简易数字文档识别等场景,解决传统手写数字人工核验效率低的问题,兼具操作便捷性与识别准确性。
技术架构上,项目形成 “数据训练 - 界面交互 - 图像处理 - 模型推理” 的闭环体系:LeNet-5 作为经典卷积神经网络模型,经 MNIST 手写数字数据集(含大量标注数字样本)训练优化,依托 PyTorch 框架实现高效推理,能精准提取数字图像的笔画、轮廓特征,保障识别精度;PyQt5 搭建直观交互界面,设计 “打开文件” 与 “识别” 核心按钮,支持用户快速导入图片并触发识别流程;OpenCV 辅助图像预处理(如灰度化、二值化),优化导入图片质量,进一步提升模型识别稳定性;整体技术栈围绕 “训练 - 应用” 场景,确保从模型构建到界面使用的连贯性。
核心功能聚焦 “图片导入识别” 关键流程:用户点击界面 “打开文件” 按钮,可在本地文件中选择待识别的手写数字图片(支持常见格式如 JPG、PNG);选定图片后点击 “识别” 按钮,系统先通过 OpenCV 对图片进行预处理,去除噪声、突出数字轮廓,再调用经 MNIST 训练好的 LeNet-5 模型执行推理,最终在界面右侧实时显示识别结果(如数字类别、识别置信度),整个流程操作简单,响应迅速,满足快速识别需求。
系统界面采用分区设计,左侧为操作区(含打开文件、识别按钮及图片预览窗口),右侧为结果展示区,布局清晰直观,非技术用户也能快速上手。LeNet-5 模型经 MNIST 数据集充分训练,对标准手写数字的识别准确率高,搭配 PyQt5 的便捷交互与 OpenCV 的图像优化,让识别流程更顺畅。项目既覆盖深度学习模型训练(LeNet-5+MNIST),又实现可视化应用开发(PyQt5 界面),是兼顾深度学习学习实践与实际应用的优质项目。
4、核心代码
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
import torch.nn.functional as F
import os
import pandas as pd
#######################################################################一些参数提前确定好
# 定义超参数
EPOCH = 5 # 训练迭代次数
BATCH_SIZE = 32 # 训练批次的大小
LR = 0.0005 # 学习率
# 模型保存名
modelName = "20221210"
optimizer_type = 'SGD' # 可以选择为 'Adam' 或者 'SGD'
##########################################################################################
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
torch.manual_seed(1) # 使用随机化种子使神经网络的初始化每次都相同
# 加载mnist手写数据集
print("加载mnist手写数据集")
train_data = torchvision.datasets.MNIST(
root='./data/', # 保存或提取的位置 会放在当前文件夹中
train=True, # true说明是用于训练的数据,false说明是用于测试的数据
transform=torchvision.transforms.ToTensor(), # 转换PIL.Image or numpy.ndarray
download=True, # 已经下载了就不需要下载了
)
test_data = torchvision.datasets.MNIST(
root='./data/',
transform=torchvision.transforms.ToTensor(),
train=False # 表明是测试集
)
# 批训练 50个samples, 1 channel,28x28 (50,1,28,28)
# Torch中的DataLoader是用来包装数据的工具,它能帮我们有效迭代数据,这样就可以进行批训练
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True # 是否打乱数据,一般都打乱
)
# 进行测试
# 为节约时间,测试时只测试前2000个
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000] / 255 # 并归一化
# torch.unsqueeze(a) 是用来对数据维度进行扩充,这样shape就从(2000,28,28)->(2000,1,28,28)
# 图像的pixel本来是0到255之间,除以255对图像进行归一化使取值范围在(0,1)
test_y = test_data.targets[:2000]
test_train_x = torch.unsqueeze(train_data.data, dim=1).type(torch.FloatTensor)[:2000] / 255 # 并归一化
# torch.unsqueeze(a) 是用来对数据维度进行扩充,这样shape就从(2000,28,28)->(2000,1,28,28)
# 图像的pixel本来是0到255之间,除以255对图像进行归一化使取值范围在(0,1)
test_train_y = train_data.targets[:2000]
# CNN模型(模仿LeNet-5)
# 第一卷积(Conv2d)-> 激励函数(ReLU) -> 池化(MaxPooling)->
# 第二卷积(Conv2d)-> 激励函数(ReLU) -> 池化(MaxPooling)->
# 第三卷积(进行卷积后随机丢弃) -> 展平多维的卷积成的特征图->
# 第一全连接层 -> 第二全连接层 -> 输出
class CNN(nn.Module):
"""3个卷积2个全连接、模仿经典的LeNet-5"""
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # 第一层卷积
self.conv2 = nn.Conv2d(10, 20, kernel_size=5) # 第二层卷积
self.conv2_drop = nn.Dropout2d() # 第三层卷积,并使用丢弃法没随机丢弃权重梯度 抑制过拟合
self.fc1 = nn.Linear(320, 64) # 第一层全连接层
self.fc2 = nn.Linear(64, 10) # 第二层全连接层
def forward(self, x): # 向前传播
x = F.relu(F.max_pool2d(self.conv1(x), 2)) # 在第一次卷积后加上激活函数、池化层,然后接上第二层卷积
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) # 在第二次卷积后加上激活函数、池化层
x = x.view(-1, 320) # 将得到的张量 展平,变成一维 类似一维数组
x = F.relu(self.fc1(x)) # 接入第一个全连接层
x = F.dropout(x, training=self.training) # 进行随机丢弃法 (训练模式下)
x = self.fc2(x) # 接入第二次全连接层
return x # 输出 图片在十个类中对应的概率
cnn = CNN() # 实例化
"""模型训练部分"""
# # 把x和y 都放入Variable中,然后放入cnn中计算output,最后再计算误差
# # 优化器选择
if optimizer_type == 'Adam':
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
else:
optimizer = torch.optim.sgd(cnn.parameters(), lr=LR)
# # 损失函数
loss_func = nn.CrossEntropyLoss()
# 开始训练
print("开始训练, 大约需要5、6分钟")
count = 0
countList = []
trainLossList = []
testLossList = []
accuracyList = []
accuracyList_train = []
# fig, ax1 = plt.subplots()
# ax2 = ax1.twinx()
# plt.show()
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # 分配batch data
output = cnn(b_x) # 先将数据放到cnn中计算output
loss = loss_func(output, b_y) # 输出和真实标签的loss,二者位置不可颠倒
optimizer.zero_grad() # 梯度归零
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新梯度
# 打印训练过程信息
if step % 100 == 0:
test_output = cnn(test_x)
test_loss = loss_func(test_output, test_y)
pred_y = torch.max(test_output, 1)[1].data.numpy()
accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))
train_output = cnn(test_train_x)
pred_train_y = torch.max(train_output, 1)[1].data.numpy()
accuracy_train = float((pred_train_y == test_train_y.data.numpy()).astype(int).sum()) / float(test_train_y.size(0))
if step % 500 == 0:
countList.append(count)
trainLossList.append(round(float(loss.data.numpy()), 2))
testLossList.append(round(float(test_loss.data.numpy()), 2))
accuracyList.append(round(accuracy, 2))
accuracyList_train.append(round(accuracy_train, 2))
print('count:', count, '| Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test loss: %.4f' % test_loss.data.numpy(),
'| test accuracy: %.2f' % accuracy, '| train accuracy: %.2f' % accuracy_train)
count += 1
torch.save(cnn.state_dict(), modelName + '.pkl') # 保存模型 保证模型的状态数据
# 可视化
fig1 = plt.figure()
plt.title('Loss') #写上图题
plt.xlabel('iteration')
plt.ylabel('loss')
plt.plot(countList, trainLossList, label="train_Loss")
plt.plot(countList, testLossList, label="test_Loss")
plt.legend(['train_Loss','test_Loss'])
plt.savefig("result_loss.png")
fig2 = plt.figure()
plt.title('accuracy') #写上图题
plt.xlabel('iteration')
plt.ylabel('accuracy')
plt.plot(countList, accuracyList_train, label="train accuracy")
plt.plot(countList, accuracyList, label="test accuracy")
plt.legend(['train accuracy','test accuracy'])
plt.savefig("result_accuracy.png")
5、源码获取方式
biyesheji0005 或 biyesheji0001 (绿色聊天软件)
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻


















计算机毕业设计(建议收藏)✅&spm=1001.2101.3001.5002&articleId=155206738&d=1&t=3&u=0d8129a8df744a7ab45147b0d1c331e1)
 3618
3618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









