






本文首发于公众号:机器感知
3D Dance、StyleBooth、AniClipart、6Img-to-3D、MeshLRM、Lazy DiT

Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
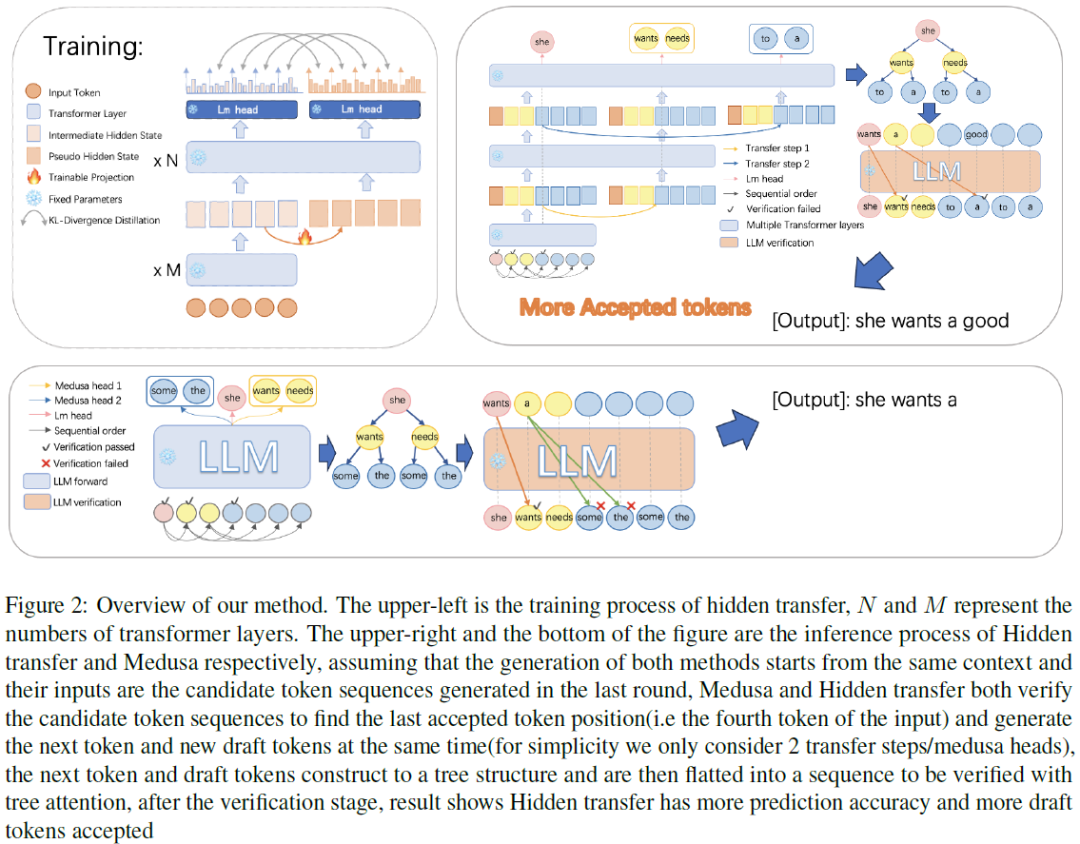
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely \textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the \textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mech......
MIDGET: Music Conditioned 3D Dance Generation
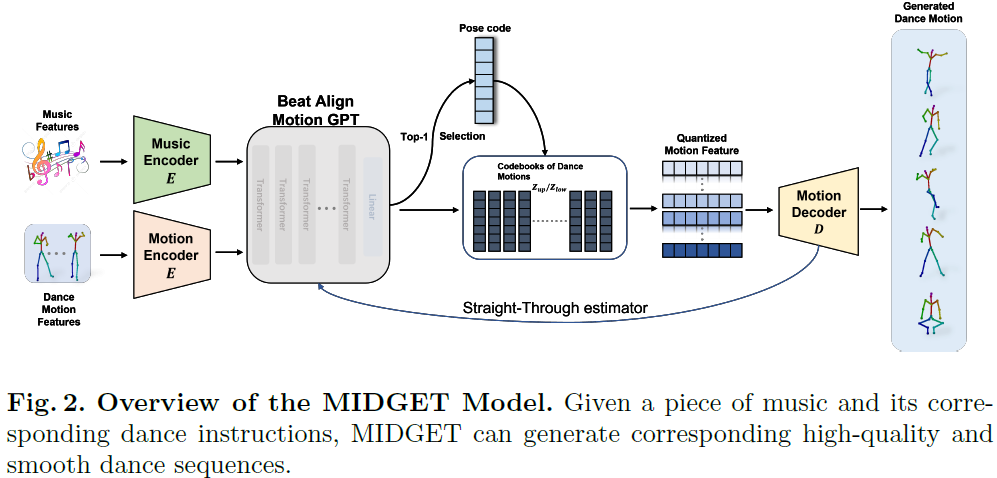
In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music. ......
StyleBooth: Image Style Editing with Multimodal Instruction

Given an original image, image editing aims to generate an image that align with the provided instruction. The challenges are to accept multimodal inputs as instructions and a scarcity of high-quality training data, including crucial triplets of source/target image pairs and multimodal (text and image) instructions. In this paper, we focus on image style editing and present StyleBooth, a method that proposes a comprehensive framework for image editing and a feasible strategy for building a high-quality style editing dataset. We integrate encoded textual instruction and image exemplar as a unified condition for diffusion model, enabling the editing of original image following multimodal instructions. Furthermore, by iterative style-destyle tuning and editing and usability filtering, the StyleBooth dataset provides content-consistent stylized/plain image pairs in various categories of styles. To show the flexibility of StyleBooth, we conduct experiments on diverse tasks, such a......
Length Generalization of Causal Transformers without Position Encoding
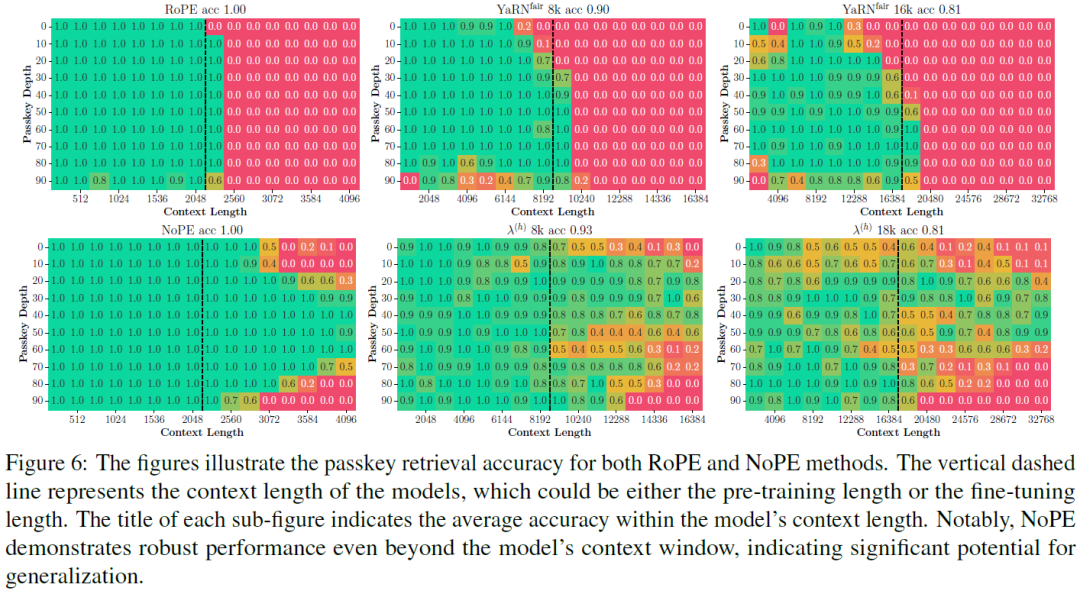
Generalizing to longer sentences is important for recent Transformer-based language models. Besides algorithms manipulating explicit position features, the success of Transformers without position encodings (NoPE) provides a new way to overcome the challenge. In this paper, we study the length generalization property of NoPE. We find that although NoPE can extend to longer sequences than the commonly used explicit position encodings, it still has a limited context length. We identify a connection between the failure of NoPE's generalization and the distraction of attention distributions. We propose a parameter-efficient tuning for searching attention heads' best temperature hyper-parameters, which substantially expands NoPE's context size. Experiments on long sequence language modeling, the synthetic passkey retrieval task and real-world long context tasks show that NoPE can achieve competitive performances with state-of-the-art length generalization algorithms. The source co......
RISE: 3D Perception Makes Real-World Robot Imitation Simple and Effective
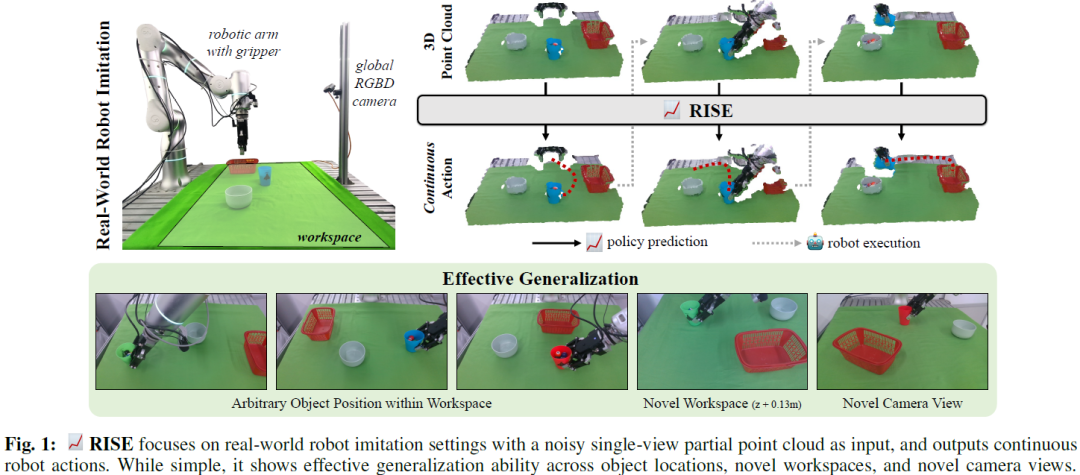
Precise robot manipulations require rich spatial information in imitation learning. Image-based policies model object positions from fixed cameras, which are sensitive to camera view changes. Policies utilizing 3D point clouds usually predict keyframes rather than continuous actions, posing difficulty in dynamic and contact-rich scenarios. To utilize 3D perception efficiently, we present RISE, an end-to-end baseline for real-world imitation learning, which predicts continuous actions directly from single-view point clouds. It compresses the point cloud to tokens with a sparse 3D encoder. After adding sparse positional encoding, the tokens are featurized using a transformer. Finally, the features are decoded into robot actions by a diffusion head. Trained with 50 demonstrations for each real-world task, RISE surpasses currently representative 2D and 3D policies by a large margin, showcasing significant advantages in both accuracy and efficiency. Experiments also demonstrate th......
Customizing Text-to-Image Diffusion with Camera Viewpoint Control

Model customization introduces new concepts to existing text-to-image models, enabling the generation of the new concept in novel contexts. However, such methods lack accurate camera view control w.r.t the object, and users must resort to prompt engineering (e.g., adding "top-view") to achieve coarse view control. In this work, we introduce a new task -- enabling explicit control of camera viewpoint for model customization. This allows us to modify object properties amongst various background scenes via text prompts, all while incorporating the target camera pose as additional control. This new task presents significant challenges in merging a 3D representation from the multi-view images of the new concept with a general, 2D text-to-image model. To bridge this gap, we propose to condition the 2D diffusion process on rendered, view-dependent features of the new object. During training, we jointly adapt the 2D diffusion modules and 3D feature predictions to reconstruct the obje......
AniClipart: Clipart Animation with Text-to-Video Priors
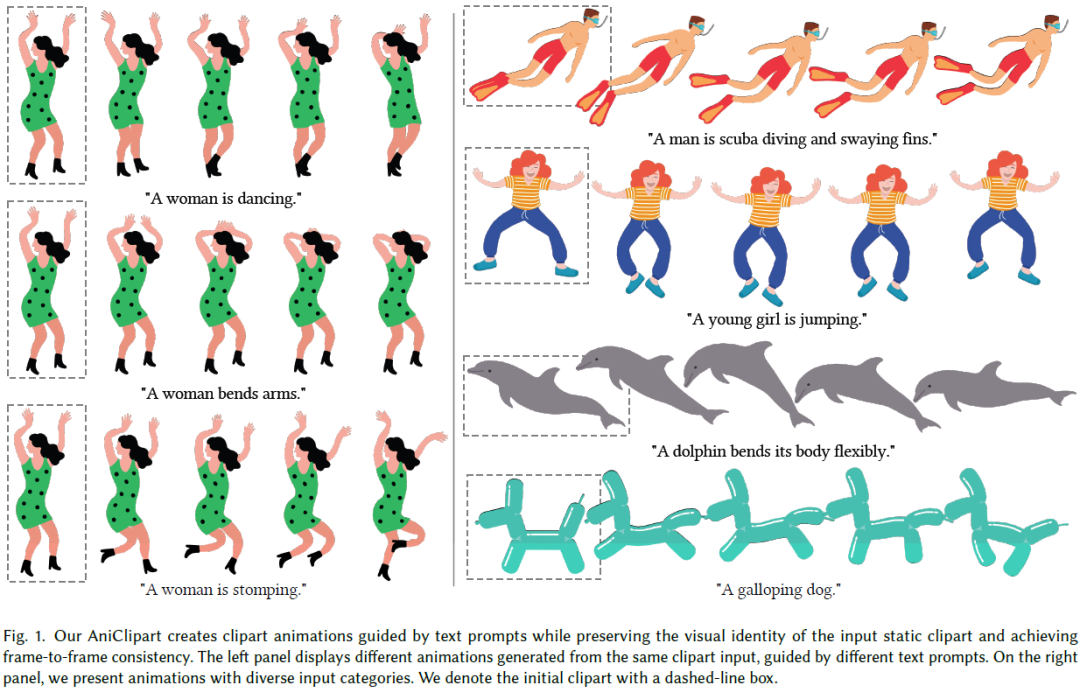
Clipart, a pre-made graphic art form, offers a convenient and efficient way of illustrating visual content. Traditional workflows to convert static clipart images into motion sequences are laborious and time-consuming, involving numerous intricate steps like rigging, key animation and in-betweening. Recent advancements in text-to-video generation hold great potential in resolving this problem. Nevertheless, direct application of text-to-video generation models often struggles to retain the visual identity of clipart images or generate cartoon-style motions, resulting in unsatisfactory animation outcomes. In this paper, we introduce AniClipart, a system that transforms static clipart images into high-quality motion sequences guided by text-to-video priors. To generate cartoon-style and smooth motion, we first define B\'{e}zier curves over keypoints of the clipart image as a form of motion regularization. We then align the motion trajectories of the keypoints with the provided ......
6Img-to-3D: Few-Image Large-Scale Outdoor Driving Scene Reconstruction

Current 3D reconstruction techniques struggle to infer unbounded scenes from a few images faithfully. Specifically, existing methods have high computational demands, require detailed pose information, and cannot reconstruct occluded regions reliably. We introduce 6Img-to-3D, an efficient, scalable transformer-based encoder-renderer method for single-shot image to 3D reconstruction. Our method outputs a 3D-consistent parameterized triplane from only six outward-facing input images for large-scale, unbounded outdoor driving scenarios. We take a step towards resolving existing shortcomings by combining contracted custom cross- and self-attention mechanisms for triplane parameterization, differentiable volume rendering, scene contraction, and image feature projection. We showcase that six surround-view vehicle images from a single timestamp without global pose information are enough to reconstruct 360$^{\circ}$ scenes during inference time, taking 395 ms. Our method allows, for e......
Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Monocular Videos

Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of structure and detail from monocular visual observations. The problem becomes even more challenging for dynamic scenes and objects. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh given a single monocular video. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from a video. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly......
Lazy Diffusion Transformer for Interactive Image Editing
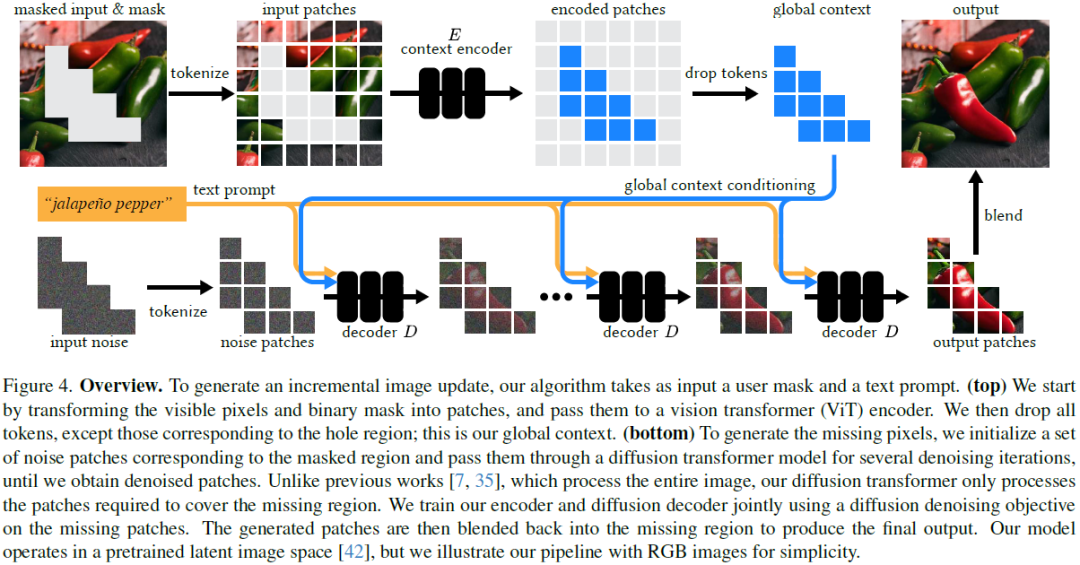
We introduce a novel diffusion transformer, LazyDiffusion, that generates partial image updates efficiently. Our approach targets interactive image editing applications in which, starting from a blank canvas or an image, a user specifies a sequence of localized image modifications using binary masks and text prompts. Our generator operates in two phases. First, a context encoder processes the current canvas and user mask to produce a compact global context tailored to the region to generate. Second, conditioned on this context, a diffusion-based transformer decoder synthesizes the masked pixels in a "lazy" fashion, i.e., it only generates the masked region. This contrasts with previous works that either regenerate the full canvas, wasting time and computation, or confine processing to a tight rectangular crop around the mask, ignoring the global image context altogether. Our decoder's runtime scales with the mask size, which is typically small, while our encoder introduces ne......
MeshLRM: Large Reconstruction Model for High-Quality Mesh

We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io......
















 4247
4247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









