






本文首发于公众号:机器感知
AudioScenic、DeepKalPose、Interactive3D、DIG3D、TI2V-Zero

AudioScenic: Audio-Driven Video Scene Editing

Audio-driven visual scene editing endeavors to manipulate the visual background while leaving the foreground content unchanged, according to the given audio signals. Unlike current efforts focusing primarily on image editing, audio-driven video scene editing has not been extensively addressed. In this paper, we introduce AudioScenic, an audio-driven framework designed for video scene editing. AudioScenic integrates audio semantics into the visual scene through a temporal-aware audio semantic injection process. As our focus is on background editing, we further introduce a SceneMasker module, which maintains the integrity of the foreground content during the editing process. AudioScenic exploits the inherent properties of audio, namely, audio magnitude and frequency, to guide the editing process, aiming to control the temporal dynamics and enhance the temporal consistency. First, we present an audio Magnitude Modulator module that adjusts the temporal dynamics of the scene in r......
Multi-Scale Representations by Varying Window Attention for Semantic Segmentation
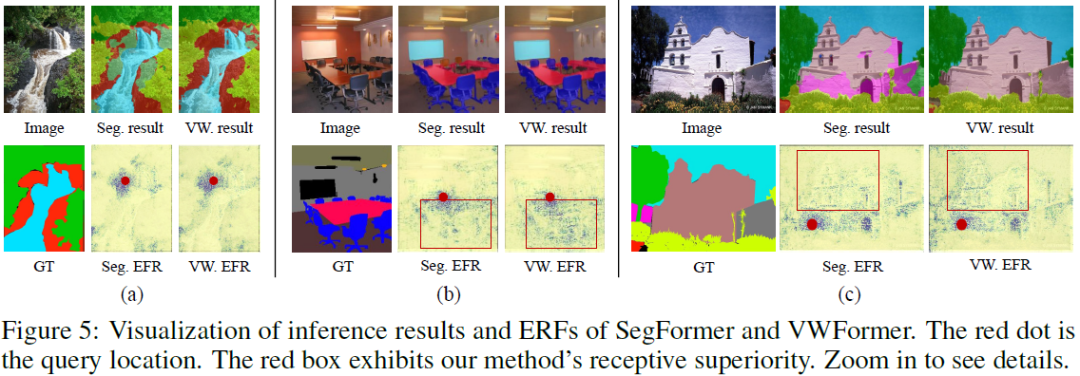
Multi-scale learning is central to semantic segmentation. We visualize the effective receptive field (ERF) of canonical multi-scale representations and point out two risks in learning them: scale inadequacy and field inactivation. A novel multi-scale learner, varying window attention (VWA), is presented to address these issues. VWA leverages the local window attention (LWA) and disentangles LWA into the query window and context window, allowing the context's scale to vary for the query to learn representations at multiple scales. However, varying the context to large-scale windows (enlarging ratio R) can significantly increase the memory footprint and computation cost (R^2 times larger than LWA). We propose a simple but professional re-scaling strategy to zero the extra induced cost without compromising performance. Consequently, VWA uses the same cost as LWA to overcome the receptive limitation of the local window. Furthermore, depending on VWA and employing various MLPs, we......
DeepKalPose: An Enhanced Deep-Learning Kalman Filter for Temporally Consistent Monocular Vehicle Pose Estimation

This paper presents DeepKalPose, a novel approach for enhancing temporal consistency in monocular vehicle pose estimation applied on video through a deep-learning-based Kalman Filter. By integrating a Bi-directional Kalman filter strategy utilizing forward and backward time-series processing, combined with a learnable motion model to represent complex motion patterns, our method significantly improves pose accuracy and robustness across various conditions, particularly for occluded or distant vehicles. Experimental validation on the KITTI dataset confirms that DeepKalPose outperforms existing methods in both pose accuracy and temporal consistency. ......
Conditional Distribution Modelling for Few-Shot Image Synthesis with Diffusion Models

Few-shot image synthesis entails generating diverse and realistic images of novel categories using only a few example images. While multiple recent efforts in this direction have achieved impressive results, the existing approaches are dependent only upon the few novel samples available at test time in order to generate new images, which restricts the diversity of the generated images. To overcome this limitation, we propose Conditional Distribution Modelling (CDM) -- a framework which effectively utilizes Diffusion models for few-shot image generation. By modelling the distribution of the latent space used to condition a Diffusion process, CDM leverages the learnt statistics of the training data to get a better approximation of the unseen class distribution, thereby removing the bias arising due to limited number of few shot samples. Simultaneously, we devise a novel inversion based optimization strategy that further improves the approximated unseen class distribution, and e......
Interactive3D: Create What You Want by Interactive 3D Generation
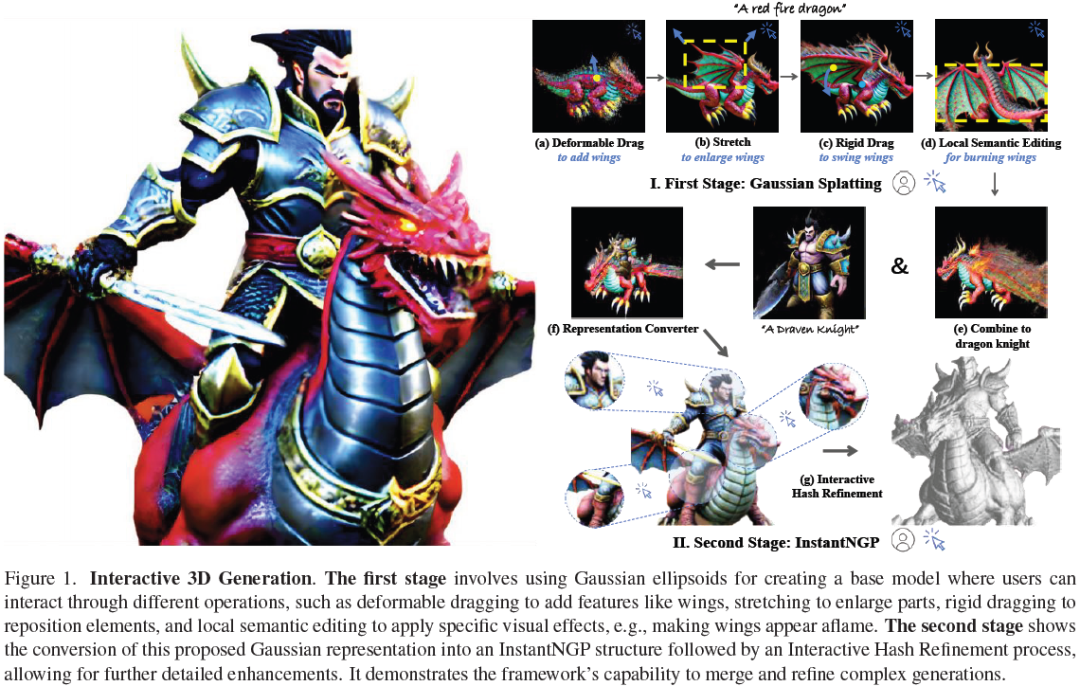
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capab......
Promoting CNNs with Cross-Architecture Knowledge Distillation for Efficient Monocular Depth Estimation
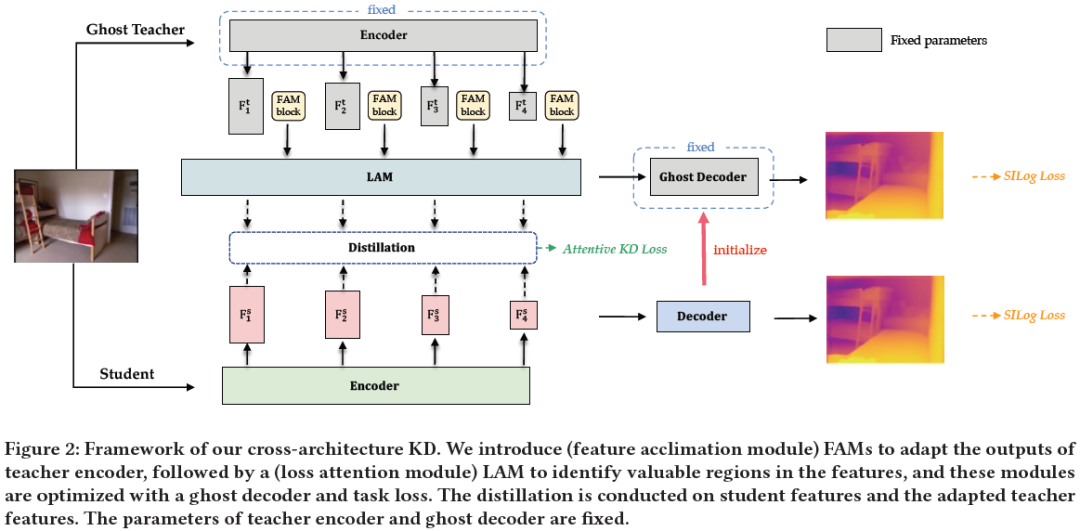
Recently, the performance of monocular depth estimation (MDE) has been significantly boosted with the integration of transformer models. However, the transformer models are usually computationally-expensive, and their effectiveness in light-weight models are limited compared to convolutions. This limitation hinders their deployment on resource-limited devices. In this paper, we propose a cross-architecture knowledge distillation method for MDE, dubbed DisDepth, to enhance efficient CNN models with the supervision of state-of-the-art transformer models. Concretely, we first build a simple framework of convolution-based MDE, which is then enhanced with a novel local-global convolution module to capture both local and global information in the image. To effectively distill valuable information from the transformer teacher and bridge the gap between convolution and transformer features, we introduce a method to acclimate the teacher with a ghost decoder. The ghost decoder is a co......
DIG3D: Marrying Gaussian Splatting with Deformable Transformer for Single Image 3D Reconstruction
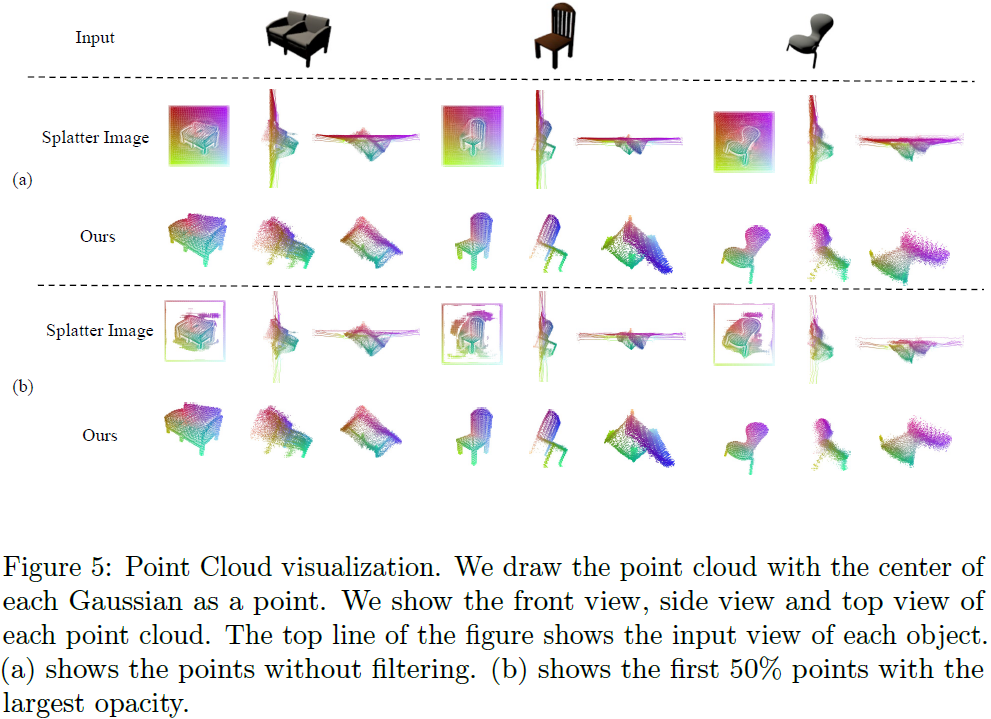
In this paper, we study the problem of 3D reconstruction from a single-view RGB image and propose a novel approach called DIG3D for 3D object reconstruction and novel view synthesis. Our method utilizes an encoder-decoder framework which generates 3D Gaussians in decoder with the guidance of depth-aware image features from encoder. In particular, we introduce the use of deformable transformer, allowing efficient and effective decoding through 3D reference point and multi-layer refinement adaptations. By harnessing the benefits of 3D Gaussians, our approach offers an efficient and accurate solution for 3D reconstruction from single-view images. We evaluate our method on the ShapeNet SRN dataset, getting PSNR of 24.21 and 24.98 in car and chair dataset, respectively. The result outperforming the recent method by around 2.25%, demonstrating the effectiveness of our method in achieving superior results. ......
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models

Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., "a woman is drinking water."). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a "repeat-and-slide" strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we emplo......
3D Human Pose Estimation with Occlusions: Introducing BlendMimic3D Dataset and GCN Refinement
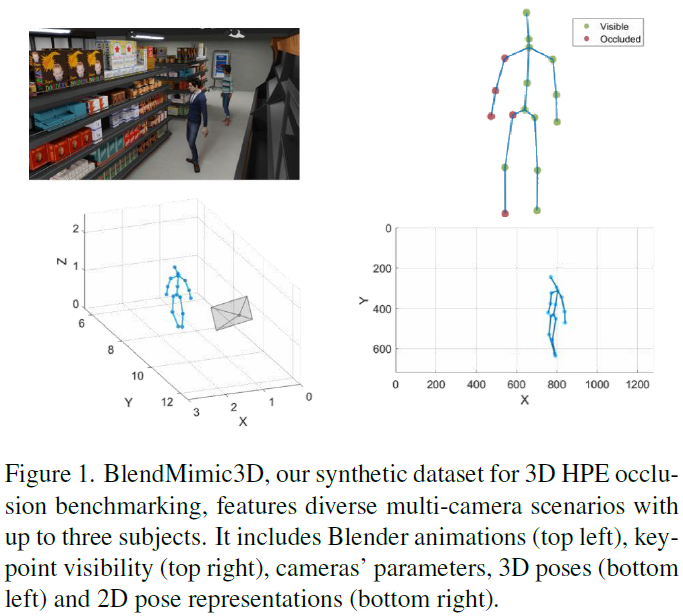
In the field of 3D Human Pose Estimation (HPE), accurately estimating human pose, especially in scenarios with occlusions, is a significant challenge. This work identifies and addresses a gap in the current state of the art in 3D HPE concerning the scarcity of data and strategies for handling occlusions. We introduce our novel BlendMimic3D dataset, designed to mimic real-world situations where occlusions occur for seamless integration in 3D HPE algorithms. Additionally, we propose a 3D pose refinement block, employing a Graph Convolutional Network (GCN) to enhance pose representation through a graph model. This GCN block acts as a plug-and-play solution, adaptable to various 3D HPE frameworks without requiring retraining them. By training the GCN with occluded data from BlendMimic3D, we demonstrate significant improvements in resolving occluded poses, with comparable results for non-occluded ones. Project web page is available at https://blendmimic3d.github.io/BlendMimic3D/. ......
Interactive Visual Learning for Stable Diffusion
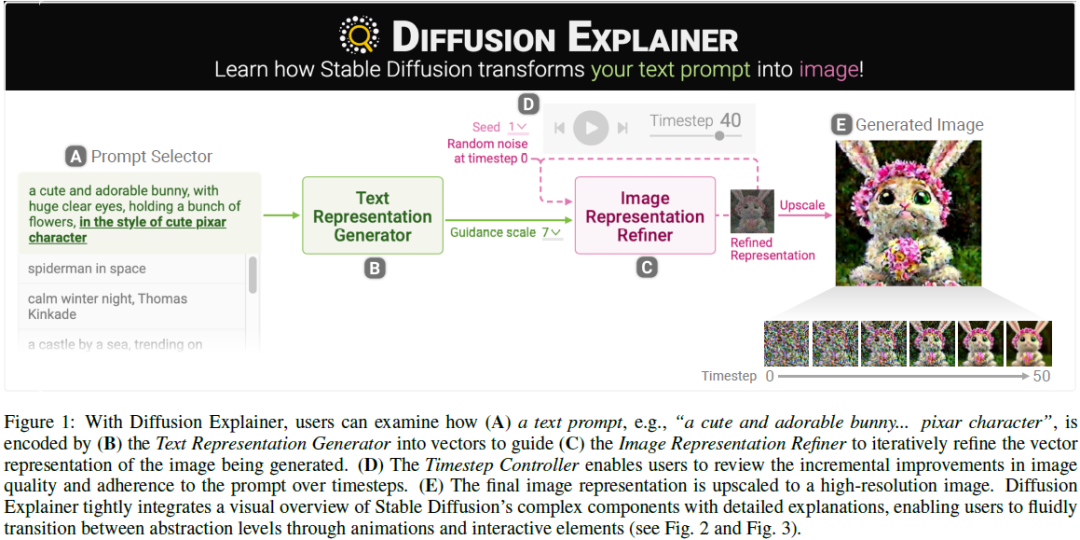
Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. ......















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









