






 文章围绕人基因组中的基因展开,介绍了人基因组中注释的基因数量,通过对GTF文件处理,探究人GTF中注释的基因类型及数量,还分析了蛋白编码基因产生的转录本情况,如SGCE基因可编码98条转录本,此外提到一个基因能编码多种不同类型转录本。
文章围绕人基因组中的基因展开,介绍了人基因组中注释的基因数量,通过对GTF文件处理,探究人GTF中注释的基因类型及数量,还分析了蛋白编码基因产生的转录本情况,如SGCE基因可编码98条转录本,此外提到一个基因能编码多种不同类型转录本。
从ENSEMBL的注释来看,人基因组中包含60,676个注释的基因,19968个蛋白编码基因。这些基因长度不同、位置不同、转录出的转录本不同,下面我们用几篇推文一步步去了解下基因组中的基因都有哪些令我们惊讶的地方。
GFF全称为general feature format,这种格式主要是用来注释基因组中的基因信息。在推文NGS基础 - GTF/GFF文件格式解读和转换我们对这个格式做了详细解释。
基本结构如下:

其最后一列为属性列,包含的属性信息可多可少,以ENSEMBL提供的人的GTF为例,包括基因的名字、ID和编码信息等。

那么有了这个文件 (GRCh38.gtf),我们能做些什么呢?
人GTF中注释了多少种基因类型?
首先对GTF文件做个小处理,所有的双引号"都替换为\t。
再利用下面的代码组合确定每一列具体对应什么信息,省却了人工去数的麻烦 (代码解释见Linux学习 - SED操作,awk的姊妹篇)。
# sed = 给每行加行号
# N 先读进去一行,再读一行,对2行同时进行操作
sed 's/"/\t/g' GRCh38.gtf | head -n 1 | tr '\t' '\n' | sed = | sed 'N;s/\n/\t/'
1 chr1
2 havana
3 gene
4 11869
5 14409
6 .
7 +
8 .
9 gene_id
10 ENSG00000223972
11 ; gene_version
12 5
13 ; gene_name
14 DDX11L1
15 ; gene_source
16 havana
17 ; gene_biotype
18 transcribed_unprocessed_pseudogene
19 ;转换这一步比较耗时,直接转一份存起来
sed 's/"/\t/g' GRCh38.gtf >GRCh38.tab.gtf提取并计数基因的类型
# 根据第三列选择基因行
# 第18列为基因类型,进行计数
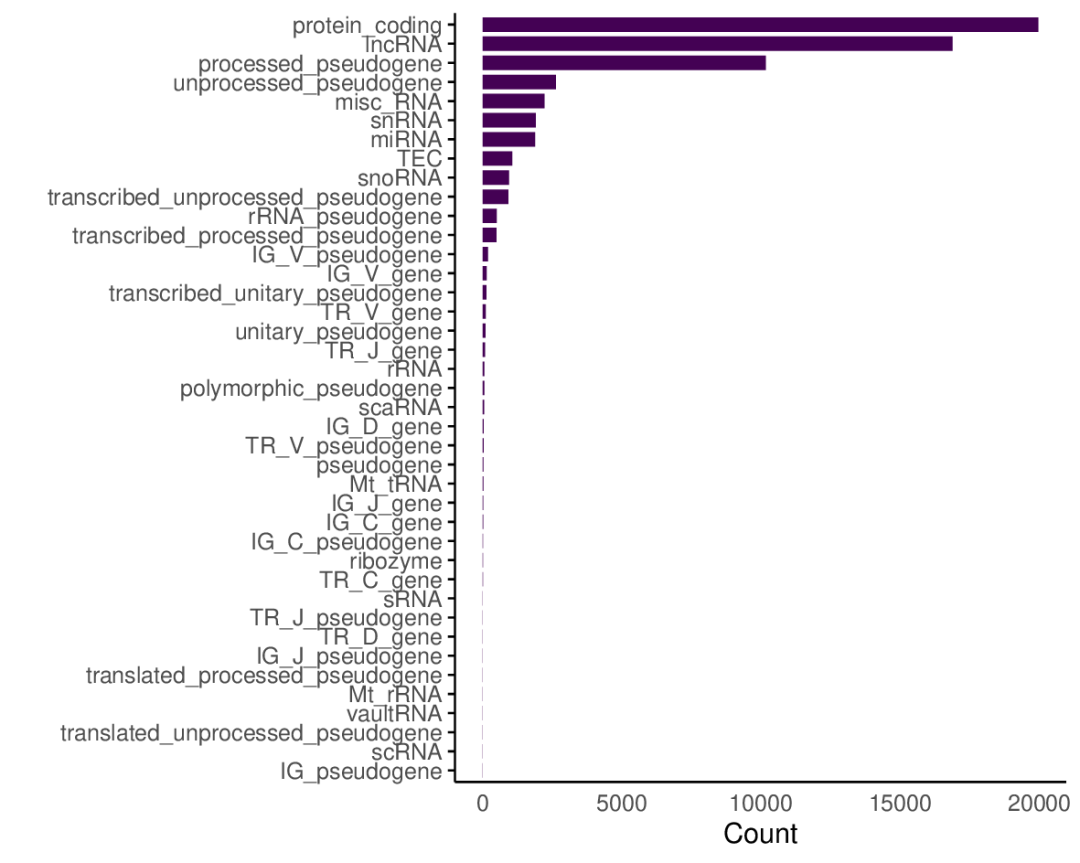
awk 'BEGIN{OFS=FS="\t"}{if($3=="gene") a[$18]+=1}END{ for(i in a) print i,a[i]}' GRCh38.tab.gtf | sort -k2,2nr | sed '1 i\Gene_type\tCount' | head最多的是蛋白编码基因近20000个,其次是lncRNA,pusudogene的数目也很多,这是有点出乎意料的。(其它类型解释见:https://m.ensembl.org/info/genome/genebuild/biotypes.html 和 https://www.gencodegenes.org/pages/biotypes.html)
Gene_type Count
protein_coding 19968
lncRNA 16880
processed_pseudogene 10168
unprocessed_pseudogene 2627
misc_RNA 2220绘个图吧,数据往高颜值免费在线绘图工具 ImageGP一放,选择Wide format,点击提交,图就出来了。
蛋白编码基因最多能产生多少已经注释的转录本?
# 根据第三列选择转录本行
# 根据类型选择蛋白编码的转录本
# 不知道哪一列是什么信息,用下面这句
# sed -n '2p' GRCh38.tab.gtf | tr '\t' '\n' | sed = | sed 'N;s/\n/\t/'
awk 'BEGIN{OFS=FS="\t"}{if($3=="transcript" && $22=="protein_coding") a[$10"\t"$18]+=1 }END{for(i in a) print i,a[i], "Gene"}' GRCh38.tab.gtf | sort -k3,3nr | sed '1 i\Gene\tSymbol\tTranscript_count\tGroup' >Protein_coding_gene_transcript_count编码转录本最多的是肢带型肌营养不良相关基因SGCE,可以编码98条转录本,这应该很重要,在不同的情况下使用不同的剪接形式。
# 最后一列只是用来作图的
Gene Symbol Transcript_count Group
ENSG00000127990 SGCE 98 Gene
ENSG00000197912 SPG7 96 Gene
ENSG00000145362 ANK2 94 Gene
ENSG00000156113 KCNMA1 93 Gene
ENSG00000196628 TCF4 91 Gene
ENSG00000126091 ST3GAL3 85 Gene
ENSG00000007372 PAX6 82 Gene
ENSG00000205336 ADGRG1 79 Gene
ENSG00000165795 NDRG2 78 Gene目前没看到哪个网站可以一起查看多个基因的功能,ImageGP可以尝试支持一下。现在还是用命令来查找下吧,看上去也没什么特别的,转录因子、G蛋白偶联受体、钙信号通路。PAX6是控制眼睛和其它感官发育的。SPG7是跨线粒体内膜的3A基因。ANK2在心肌细胞特异高表达。
grep -f <(head Protein_coding_gene_transcript_count | tail -n+2 | cut -f 1) Human.anno.withalias.ortholog2.txt | cut -f 1-4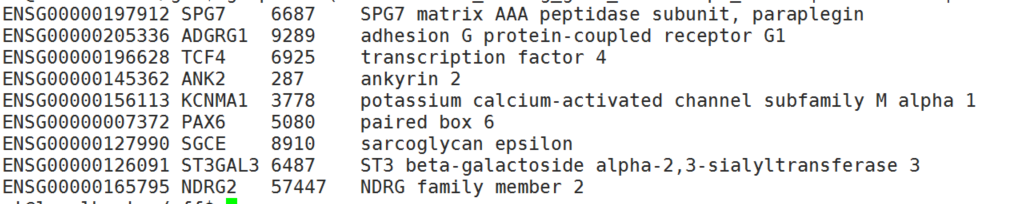
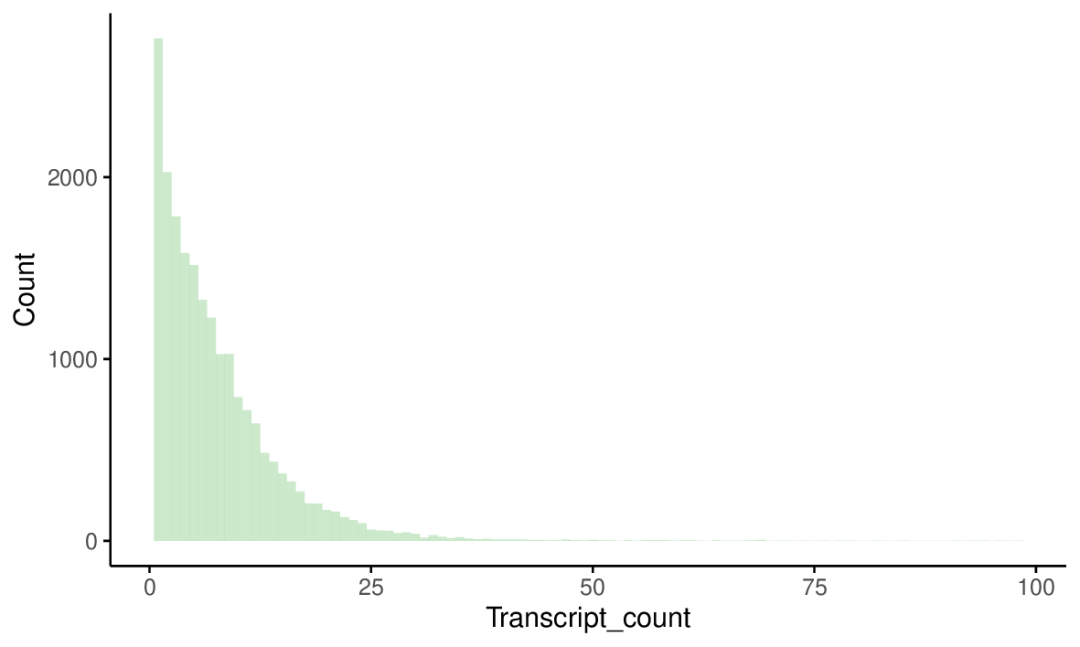
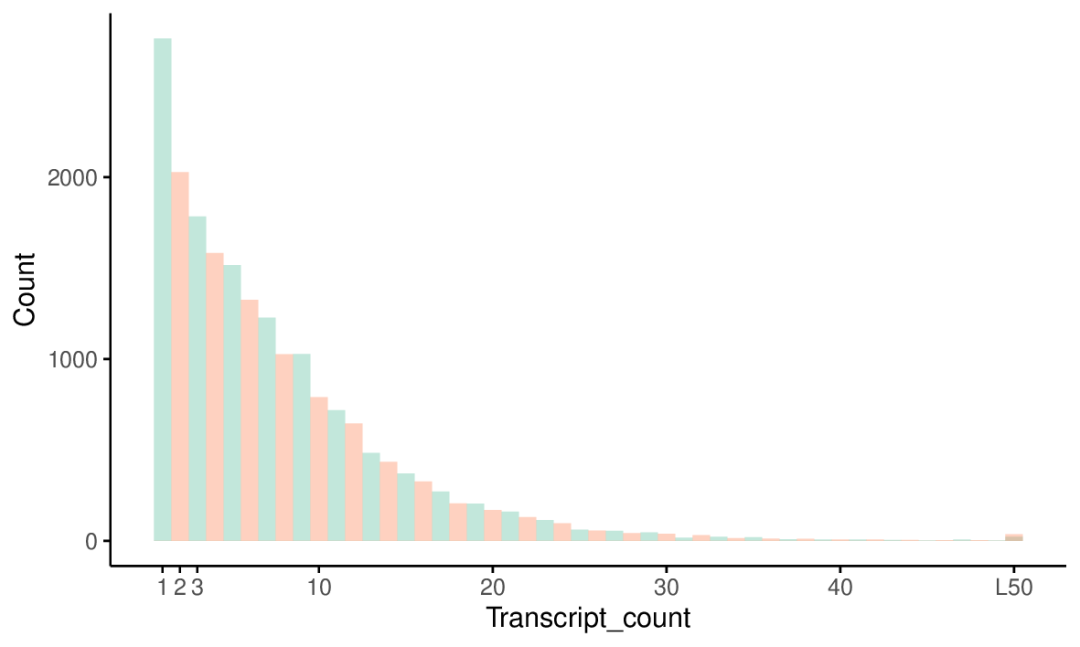
把数据拷贝到ImageGP,画一个(bin=1)的直方图 (也就是线图了,省去了排序和计数了),可以看到单个转录本的基因还是最多的。
一个颜色不好看,奇数和偶数颜色分开展示一下 (重新生成数据)
awk 'BEGIN{OFS=FS="\t"}{if($3=="transcript" && $22=="protein_coding") a[$10"\t"$18]+=1 }END{for(i in a) {cnt=a[i]; type1="odd"; if(cnt%2==0) type1="even"; print cnt, type1}}' GRCh38.tab.gtf | sed '1 i\Transcript_count\tGroup' >Protein_coding_gene_transcript_count2.plot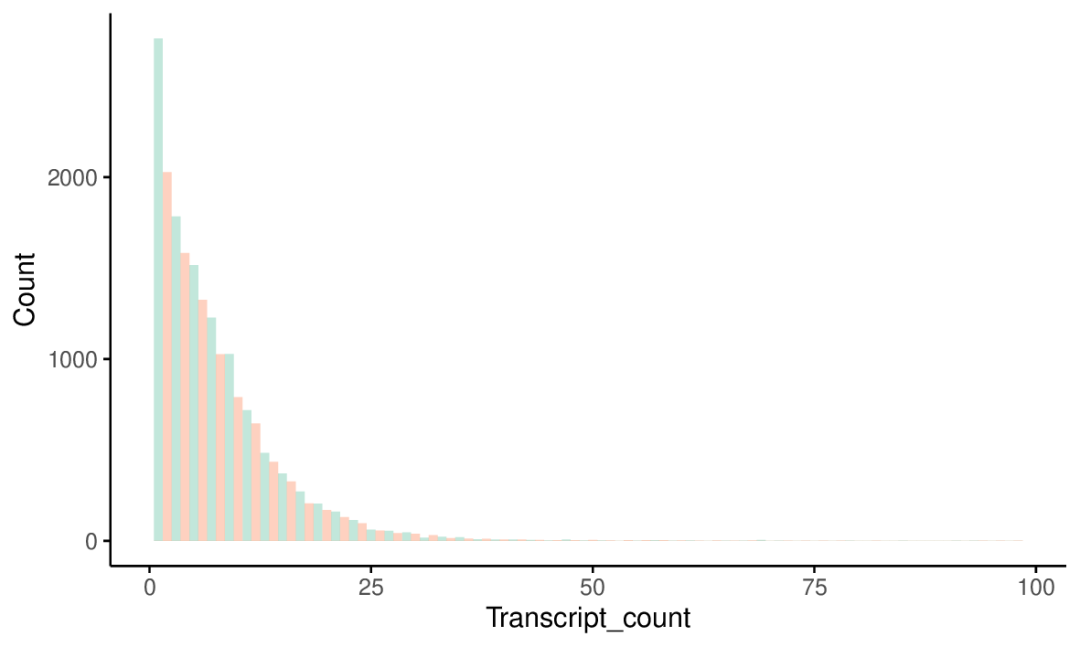
多于50个转录本的基因不多,合并下,省得看着拖尾 (直接在线修改参数)。
一个基因编码多种不同类型的转录本
以转录本最多的基因SGCE (肢带型肌营养不良相关基因)为例,其转录出4种不同类型的转录本。(processed_transcript: 总称没有开放阅读框的转录本)
grep 'ENSG00000127990' GRCh38.tab.gtf | grep -P '\ttranscript\t' | cut -f 28 | sort | uniq -c
23 nonsense_mediated_decay
5 processed_transcript
45 protein_coding
25 retained_intron今天就先探索到这,下期继续 (实际是没时间写这么多了,分开写吧,边写大家边一起交流)。
Excel改变了你的基因名,30% 相关Nature文章受影响,NCBI也受波及
猜一猜最长的基因和最短的基因分别是多少?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











